Работа с текстом в Java часто требует очистки строк от лишних символов. Один из распространённых кейсов – удаление знаков препинания. Это актуально при предварительной обработке данных для поиска, сравнения строк или анализа текста. Java предоставляет несколько инструментов, позволяющих решать эту задачу гибко и эффективно.
Простейший способ – использование регулярных выражений. Метод String.replaceAll() с шаблоном «\\p{Punct}» удаляет все символы, классифицируемые как пунктуационные по стандарту Unicode. Например, вызов str.replaceAll(«\\p{Punct}», «») уберёт запятые, точки, двоеточия, кавычки и прочие символы из строки.
Если необходимо оставить определённые символы (например, дефис в составных словах), регулярное выражение можно адаптировать: str.replaceAll(«[\\p{Punct}&&[^-]]», «»). Такой подход исключает дефис из набора удаляемых знаков.
Для больших объёмов текста или ситуаций, когда строки обрабатываются в цикле, важно учитывать производительность. Использование Pattern и Matcher вместо многократных вызовов replaceAll() может снизить нагрузку на сборщик мусора и улучшить отклик программы.
Как удалить все знаки препинания с помощью регулярных выражений
Для удаления всех знаков препинания из строки в Java целесообразно использовать метод String.replaceAll() с регулярным выражением. Под знаками препинания подразумеваются символы, входящие в класс Unicode \p{Punct}.
- Регулярное выражение
"\\p{Punct}"соответствует любому знаку препинания. - Чтобы удалить все такие символы, используйте замену на пустую строку:
str.replaceAll("\\p{Punct}", ""). - Если строка содержит специальные символы вне диапазона
\p{Punct}, например тире или кавычки других языков, используйте"[\\p{Punct}–“”«»]".
Пример:
String input = "Пример: строка, содержащая знаки – препинания!";
String cleaned = input.replaceAll("[\\p{Punct}–“”«»]", "");
System.out.println(cleaned); // Пример строка содержащая знаки препинания
- Проверяйте, удаляются ли символы вне стандартного ASCII, если текст включает экзотические знаки препинания.
- Для многоязычного текста предпочтительнее явно указать все нежелательные символы.
- Регулярные выражения чувствительны к синтаксису. Экранируйте обратный слэш двойным.
Для Unicode-aware обработки рекомендуется использовать Pattern.UNICODE_CHARACTER_CLASS или явно задавать диапазоны символов в регулярном выражении, если необходимо контролировать удаление по категориям символов.
Удаление только определённых знаков препинания из строки
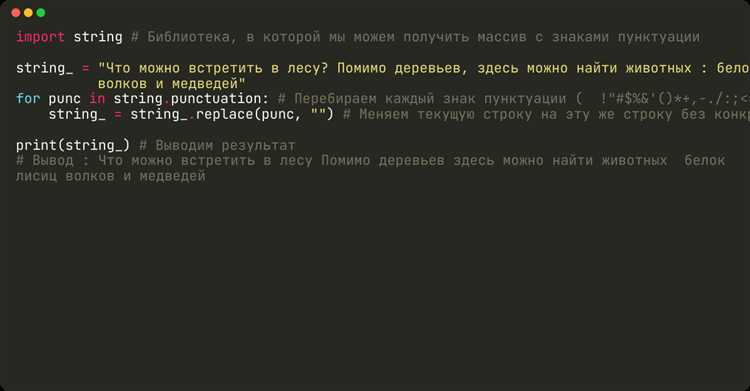
Если необходимо удалить из строки только некоторые знаки препинания, например, точки, запятые и восклицательные знаки, а остальные оставить, используйте регулярные выражения с явно заданным набором символов.
String input = "Привет, мир! Как дела? Всё хорошо.";
String cleaned = input.replaceAll("[,!.]", "");
System.out.println(cleaned);
Символы в квадратных скобках обозначают точный список удаляемых знаков. Класс символов можно адаптировать под конкретную задачу:
"[,]"– только запятые"[.!?]"– точка, восклицательный и вопросительный знаки"[:;]"– двоеточие и точка с запятой
Чтобы удалить все знаки, кроме выбранных, используйте отрицание внутри класса символов:
String input = "Это – пример: строки, с разными знаками!";
String cleaned = input.replaceAll("[^а-яА-Яa-zA-Z0-9\\s:]", "");
System.out.println(cleaned);
Допускается комбинировать фильтрацию и замену. Например, чтобы заменить только вопросительные знаки на точку:
String input = "Что это? Почему? Где?";
String modified = input.replaceAll("\\?", ".");
System.out.println(modified);
Регулярные выражения чувствительны к спецсимволам. При необходимости удалить, например, скобки, экранируйте их:
String input = "Текст (в скобках) – пример.";
String cleaned = input.replaceAll("[()]", "");
System.out.println(cleaned);
Рекомендуется явно указывать набор удаляемых знаков, избегая универсальных шаблонов, если требуется сохранить часть пунктуации.
Чем отличаются методы replace и replaceAll при удалении знаков
Метод replace работает с обычными строками и заменяет конкретные символы или последовательности символов без учета регулярных выражений. Например, str.replace(",", "") удалит все запятые, но не справится с удалением всех знаков препинания сразу.
replaceAll поддерживает регулярные выражения, что позволяет удалять весь набор знаков препинания одним выражением. Например, str.replaceAll("[\\p{Punct}]", "") удаляет любые символы пунктуации, включая точки, запятые, двоеточия, тире и другие, без необходимости перечислять каждый.
При необходимости удаления одиночных известных символов предпочтительнее использовать replace – он быстрее и не требует интерпретации шаблона. Если задача требует обобщения или динамичного списка символов, используется replaceAll с грамотно составленным регулярным выражением.
Важно: replaceAll требует экранирования спецсимволов RegEx, тогда как replace – нет. Ошибка в шаблоне приведет к PatternSyntaxException.
Оптимизация: если выражение фиксировано и используется многократно, стоит заранее скомпилировать его через Pattern и применять метод matcher().replaceAll(), чтобы избежать повторной компиляции.
Удаление знаков препинания в тексте, содержащем цифры и буквы разных алфавитов
При работе с многоязычными строками, содержащими буквы кириллицы, латиницы и цифры, необходимо учитывать, что знаки препинания могут быть различны по кодировке и типу. Простая замена символов по списку не обеспечивает надёжной очистки, особенно если текст включает специфические символы Юникода.
Для надёжного удаления знаков препинания следует использовать регулярное выражение, исключающее буквы всех алфавитов и цифры. Пример: text.replaceAll("[\\p{Punct}\\p{IsPunctuation}]", ""). Это выражение удаляет стандартные и дополнительные пунктуационные символы, включая тире, кавычки, точки, запятые, скобки, а также их аналоги в других языках.
Если в тексте присутствуют символы, не попадающие под категорию \p{Punct}, например нестандартные апострофы или тире из диапазона Unicode, используйте выражение: text.replaceAll("[\\p{P}\\p{S}&&[^\\p{L}\\p{N}]]+", ""). Оно исключает все символы, не являющиеся буквами (\p{L}) и цифрами (\p{N}), включая знаки валют, математические и технические символы.
Для нормализации текста перед фильтрацией рекомендуется привести строку к NFC-формату с помощью java.text.Normalizer, чтобы исключить влияние составных символов. Пример: Normalizer.normalize(text, Normalizer.Form.NFC).
Обработка должна учитывать возможное смешение алфавитов в одном слове. Например, «Сhеck123» может содержать как латинские, так и кириллические буквы, внешне идентичные. Для анализа используйте Character.UnicodeBlock.of(ch), чтобы при необходимости дополнительно валидировать содержимое строки.
Как исключить пробелы и спецсимволы при удалении знаков препинания

При необходимости удалить только знаки препинания, оставив пробелы и спецсимволы (например, @, #, %, *), важно правильно настроить регулярное выражение. В Java для этого используется класс String и метод replaceAll, принимающий шаблон и строку-замену.
Регулярное выражение, охватывающее исключительно знаки препинания Юникода, выглядит так: "\\p{Punct}". Однако оно также удаляет символы, не всегда относящиеся к пунктуации в широком смысле (например, слэши, кавычки и др.). Чтобы оставить спецсимволы, используется более точный набор символов или исключения через отрицательные классы.
Для сохранения пробелов и спецсимволов используйте следующее выражение:
String cleaned = input.replaceAll("[\\p{IsPunctuation}&&[^@#%*]]", "");Этот шаблон удаляет только стандартные знаки препинания, игнорируя указанные символы (@, #, %, *). Пробелы остаются без изменений, так как они не входят в класс \p{P}.
Если требуется исключить все спецсимволы, кроме пробелов, нужно задать разрешённый диапазон символов вручную:
String cleaned = input.replaceAll("[!\"#$%&'()*+,\\-./:;<=>?@[\\\\]^_`~]", "");Альтернативный подход – использовать отрицание внутри регулярного выражения и разрешать только те символы, которые должны остаться:
String cleaned = input.replaceAll("[^\\w\\s@#%*]", "");Здесь сохраняются буквы, цифры, пробелы, а также перечисленные спецсимволы. Такой метод удобен, если список разрешённых символов фиксирован и заранее известен.
Обработка текста без знаков препинания в потоке данных

Когда текст поступает в виде потока данных, задача удаления знаков препинания становится особенно актуальной для дальнейшей обработки. В Java для этого можно использовать регулярные выражения, позволяющие эффективно и быстро устранять все нежелательные символы, не влияя на содержание текста.
Для работы с потоками данных удобно использовать класс BufferedReader для чтения строк и StringBuilder для эффективной модификации строк. Это позволяет обрабатывать большие объемы данных без значительных потерь в производительности.
Пример реализации удаления знаков препинания из потока данных с помощью регулярных выражений:
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = reader.readLine()) != null) {
String cleanedLine = line.replaceAll("[^\\w\\s]", ""); // удаляем все знаки препинания
// Далее можно передать cleanedLine для дальнейшей обработки
}
Регулярное выражение [^\\w\\s] исключает все символы, не являющиеся буквами, цифрами или пробелами. Это гарантирует, что из строки будут удалены только знаки препинания, оставляя все слова и числа нетронутыми.
Если необходимо обрабатывать данные в реальном времени, полезным может быть использование InputStreamReader для чтения потока, чтобы минимизировать задержки. В таком случае регулярные выражения применяются к каждой строке сразу после ее получения, что ускоряет процесс обработки.
Для повышения гибкости можно использовать более сложные регулярные выражения, чтобы точно настроить фильтрацию, например, для удаления только определённых знаков препинания (точки, запятые и т.д.) или же, наоборот, для сохранения некоторых символов, если это требуется для задачи.
Проверка строки на наличие знаков препинания перед удалением
Перед удалением знаков препинания из строки важно убедиться, что они действительно присутствуют. Это можно сделать с помощью регулярных выражений или итерации по символам строки. Регулярное выражение позволяет быстро выявить любые символы, относящиеся к знакам препинания, таким как точка, запятая, восклицательный знак, вопросительный знак и другие.
Для простого поиска знаков препинания можно использовать шаблон, включающий все символы, которые часто выступают как знаки препинания. Пример такого регулярного выражения в Java:
String regex = "[!\"#$%&'()*+,-./:;<=>?@[\\]^_`~]";
Данное выражение находит любые символы из набора, включающего стандартные знаки препинания. Если нужно проверить строку на их наличие, достаточно выполнить поиск с помощью метода matches() или find() из класса Pattern. В случае нахождения хотя бы одного знака можно продолжить обработку строки, удаляя эти символы.
Если же задача состоит в том, чтобы точно узнать, есть ли знаки препинания, можно создать цикл, который будет перебирать каждый символ строки и проверять его на соответствие этому набору. Например:
for (char c : input.toCharArray()) {
if (Character.toString(c).matches("[!\"#$%&'()*+,-./:;<=>?@[\\]^_`~]")) {
// знак препинания найден
foundPunctuation = true;
break;
}
}
Такой подход полезен, если необходимо выполнить дополнительные действия, например, логирование или изменение поведения в зависимости от того, были ли найдены знаки препинания.
Оптимизация проверки на наличие знаков препинания зависит от задачи. Если строка может быть длинной и важно минимизировать количество операций, регулярные выражения покажут лучшую производительность, так как они обрабатывают всю строку за один шаг, в отличие от итеративного подхода, который может потребовать больше вычислений при каждом сравнении символа.
Вопрос-ответ:
Какие символы считаются знаками препинания в Java?
В Java для работы с символами препинания используется класс `Character` с категорией `Punct`, которая включает все стандартные знаки препинания, такие как: точки, запятые, восклицательные знаки, вопросительные знаки, скобки, кавычки и другие. Регулярные выражения с использованием `\\p{Punct}` охватывают большинство знаков препинания, которые можно встретить в тексте.