В языке Java тип char представляет собой 16-битное беззнаковое целое число, способное хранить один символ в формате UTF-16. Это означает, что каждый char фактически содержит кодовую единицу UTF-16, а не полноценный символ в привычном понимании. Такой подход накладывает определённые ограничения и требует понимания различий между символами, кодовыми точками и кодовыми единицами.
Диапазон значений char в Java – от 0x0000 до 0xFFFF. Этого достаточно для представления всех символов базовой многобайтной плоскости (BMP), но недостаточно для символов, находящихся за её пределами (например, эмодзи, редкие иероглифы, исторические алфавиты). Для таких символов используется пара суррогатных char-значений, называемая surrogate pair. Их корректная обработка требует применения методов класса Character, таких как codePointAt() и toChars().
Работа с символами за пределами BMP требует отказа от индексирования строки по char и перехода к работе с кодовыми точками. Использование метода String.codePoints() или Character.codePointCount() позволяет точно определять количество логических символов в строке, избегая ошибок при работе с суррогатными парами.
Для хранения текстовых данных, особенно в многоязычных приложениях, рекомендуется использовать тип String и API, ориентированные на code points, а не char. Непонимание внутренних механизмов кодирования может привести к искажению данных, особенно при чтении и записи файлов, обмене данными между системами или отображении интерфейсов с символами за пределами ASCII.
Как char хранит символы в 16-битном формате UTF-16

Тип данных char в Java представляет собой 16-битное беззнаковое целое число и используется для хранения символов в кодировке UTF-16. Каждый char способен представлять один кодовый юнит – элемент кодировки UTF-16, диапазон которого составляет от 0x0000 до 0xFFFF.
Символы из базовой многоязычной плоскости (BMP), охватывающей диапазон от U+0000 до U+FFFF, представлены одним значением char. Например, символ ‘A’ соответствует значению 0x0041, а ‘Ж’ – 0x0416.
Для символов вне BMP, то есть с кодовыми точками от U+10000 до U+10FFFF, требуется пара char – суррогатная пара. Старший суррогат (high surrogate) располагается в диапазоне от 0xD800 до 0xDBFF, младший (low surrogate) – от 0xDC00 до 0xDFFF. Эти пары интерпретируются как один символ при использовании API, поддерживающего Unicode, например Character.toCodePoint().
Работа с символами вне BMP требует осторожности: методы charAt() и length() не распознают суррогатные пары как один символ, что может привести к логическим ошибкам при анализе текста. Для корректной обработки таких символов рекомендуется использовать массивы int с кодовыми точками или методы codePoints() и codePointAt().
Поскольку char не способен хранить полный набор символов Unicode, его следует рассматривать как кодовый юнит UTF-16, а не как абстрактную единицу символа. При проектировании Unicode-совместимого ПО необходимо учитывать, что один пользовательский символ может занимать два значения char.
Чем отличается кодовая единица от кодовой точки в контексте char

В Java тип char представляет собой 16-битную кодовую единицу UTF-16. Это не символ в привычном понимании, а элемент кодировки. Понимание различий между кодовой единицей и кодовой точкой критично для корректной обработки текста, особенно за пределами базовой мультилингвальной плоскости (BMP).
- Кодовая единица – это минимальная адресуемая часть закодированного текста. В UTF-16 одна кодовая единица занимает 2 байта. Тип
charоперирует именно кодовыми единицами. - Кодовая точка – это уникальный номер символа в пространстве Unicode, например, U+0041 для латинской буквы A или U+1F600 для смайлика 😀.
Большинство символов BMP (U+0000–U+FFFF) кодируются одной кодовой единицей и укладываются в один char. Однако символы вне этого диапазона (U+10000 и выше) представлены суррогатной парой – двумя char, каждая из которых по отдельности не является полноценной кодовой точкой.
- Если
Character.isHighSurrogate(c)возвращаетtrue, это первая часть пары. - Вторая часть –
Character.isLowSurrogate(c). - Для преобразования пары в кодовую точку используйте
Character.toCodePoint(high, low).
Следует избегать работы с char и String.charAt() для анализа символов, если возможны символы вне BMP. Используйте codePoints() и Character.codePointAt() для точной обработки кодовых точек.
Ошибка: считать char = символ. Реальность: char = кодовая единица. Один символ может занимать одну или две кодовые единицы. Это критично при подсчете длины, извлечении подстрок и сравнении символов.
Что происходит при сохранении символов вне диапазона Basic Multilingual Plane
Тип char в Java представлен 16-битным беззнаковым значением и может хранить символы в диапазоне от U+0000 до U+FFFF, что охватывает только Basic Multilingual Plane (BMP). Символы за пределами BMP – например, эмодзи, древние письменности и музыкальные нотации – имеют кодовые точки от U+10000 до U+10FFFF и не могут быть представлены одним значением char.
Для представления таких символов Java использует механизм суррогатных пар. Каждая пара состоит из двух значений char: старшего суррогата (в диапазоне U+D800–U+DBFF) и младшего суррогата (в диапазоне U+DC00–U+DFFF). Вместе они кодируют один символ вне BMP.
Например, символ 𝄞 (музыкальный ключ соль, кодовая точка U+1D11E) хранится как:
- старший суррогат:
0xD834 - младший суррогат:
0xDD1E
Если попытаться сохранить символ вне BMP в переменную типа char без учёта суррогатной пары, произойдёт обрезка данных. Будет сохранён только один из двух char, что приведёт к некорректной интерпретации символа, и, как следствие, к ошибкам при отображении, сравнении или сериализации строки.
Рекомендуется использовать тип int или методы Character.toChars(int codePoint) и String.codePoints() для корректной обработки символов вне BMP. При работе со строками, содержащими такие символы, следует использовать codePointAt(), codePointCount() и другие методы, оперирующие кодовыми точками, а не отдельными char.
Как работает преобразование между char и строками в Java
Тип char в Java представляет собой 16-битное целое число без знака, соответствующее значению UTF-16 кода символа. При преобразовании char в строку используется конкатенация или методы класса String. Выражение String s = c + «»; создаёт новую строку, содержащую один символ. Метод String.valueOf(c) предпочтительнее, так как он избегает ненужной конкатенации и понятнее читается.
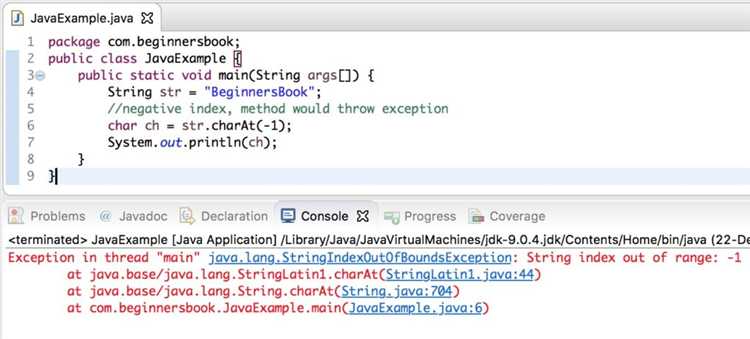
Обратное преобразование осуществляется вызовом charAt(int index) у строки. Например, char c = s.charAt(0); извлекает первый символ. Важно: метод не проверяет длину строки и выбрасывает StringIndexOutOfBoundsException при пустой строке. Поэтому перед вызовом следует проверять s.length() > 0.
Символы за пределами базовой многоязычной плоскости (BMP), такие как эмодзи, требуют внимания: они представлены суррогатной парой char-ов. Поэтому charAt() может вернуть некорректный символ. Для корректной работы используйте codePointAt() и Character.toChars(int codePoint).
Для массового преобразования char[] в String используйте конструктор new String(char[] array). Обратно – метод toCharArray(). Избегайте ручной итерации без необходимости: она менее эффективна и более подвержена ошибкам при работе с суррогатами.
Все операции с char следует рассматривать как манипуляции с кодами UTF-16, а не с символами в привычном понимании. Это особенно важно при интернационализации и поддержке Unicode-символов за пределами BMP.
Почему сравнение char может давать неожиданные результаты при работе с Unicode
В Java тип char хранит символы в кодировке UTF-16 и занимает 16 бит. Это означает, что он может представлять только кодовые точки Unicode в диапазоне от U+0000 до U+FFFF. Однако многие символы Unicode, особенно из дополнительных плоскостей (например, эмодзи, музыкальные знаки, древние письменности), имеют кодовые точки выше U+FFFF и требуют двух char для представления – так называемую суррогатную пару.
- Сравнение символов, находящихся за пределами базовой мультилингвальной плоскости (BMP), через
charне учитывает суррогатные пары и может привести к ложному результату. - Методы
char == charилиCharacter.compare()работают только с одной 16-битной единицей, не интерпретируя полную кодовую точку. - Например, символ 😃 (U+1F603) представлен двумя
char:\uD83Dи\uDE03. Сравнение любого из них по отдельности с другим символом не даст корректного результата.
Для правильного сравнения символов из любых плоскостей используйте кодовые точки:
- Метод
String.codePointAt(int index)возвращает полную 32-битную кодовую точку. String.codePoints()позволяет итерироваться по всем символам строки с учётом суррогатных пар.- Для сравнения двух символов используйте
Integer.compare(codePoint1, codePoint2), а не сравнениеchar.
Неправильное сравнение char может привести к багам при работе с международными текстами, особенно если они содержат редкие символы, эмодзи или комбинируемые знаки. При разработке рекомендуется всегда учитывать возможность присутствия символов за пределами BMP и использовать API, ориентированные на кодовые точки.
Как правильно обрабатывать символы суррогатной пары в Java

При попытке работать с суррогатными парами напрямую как с одиночными char-значениями, можно столкнуться с проблемами. Например, строка, состоящая из суррогатной пары, может быть неправильно обработана, если попытаться получить её длину или обратиться к отдельным символам через индексы. Для работы с такими символами важно учитывать, что длина строки и количество символов не всегда совпадают. Например, строка, содержащая суррогатную пару, будет иметь длину больше одного, хотя по сути представляет собой один символ.
Для правильной обработки суррогатных пар в Java следует использовать класс Character и методы, такие как isSurrogate(char ch) для проверки, является ли символ частью суррогатной пары. Если необходимо работать с суррогатной парой как с единым символом, нужно воспользоваться классом String и его методами, которые правильно обрабатывают пары. Например, метод codePointAt(int index) возвращает полный код символа, включая символы, состоящие из суррогатных пар.
Также для итерации по строкам, содержащим суррогатные пары, необходимо использовать методы, которые учитывают кодовые точки Unicode, такие как codePoints(), который возвращает поток целых чисел, представляющих кодовые точки, а не одиночные значения char. Это особенно важно при обработке строк, содержащих символы из расширенной плоскости Unicode.
Важным аспектом является корректная работа с индексацией в строках. Методы, такие как charAt(int index), могут возвращать только одиночные символы типа char, что не всегда удобно при работе с суррогатными парами. В этом случае лучше использовать codePointAt() для получения кода целого символа, независимо от того, является ли он одиночным символом или суррогатной парой.
Таким образом, чтобы корректно обрабатывать символы суррогатной пары в Java, важно учитывать специфику работы с Unicode и использовать методы, которые поддерживают кодовые точки, а не отдельные char-значения. Это позволяет избежать ошибок при обработке строк и гарантировать правильную работу с символами, выходящими за пределы базовой многобайтовой плоскости Unicode.
Вопрос-ответ:
Как в Java происходит кодировка символов типа char?
В языке Java тип данных `char` используется для представления символов. Каждый символ в этом типе кодируется с помощью стандарта Unicode. Unicode позволяет представлять более 100 тысяч символов, включая различные алфавиты, иероглифы и знаки, используемые во многих языках мира. В Java каждый символ типа `char` занимает 16 бит, что позволяет кодировать символы в пределах диапазона от 0 до 65535. Это даёт возможность работать с символами, выходящими за пределы стандартного ASCII, включая спецсимволы и символы различных языков.
Почему символы типа char в Java занимают 16 бит?
Символы типа `char` в Java занимают 16 бит, потому что Java использует стандарт Unicode, который для большинства символов требует 16 бит для кодировки. Unicode позволяет представлять символы из множества различных письменных систем. Для большинства распространённых символов этого достаточно, но существуют и символы, которым требуется больше памяти. Такие символы кодируются через дополнительные механизмы, например, с использованием так называемых «суррогатных пар», которые могут занимать 32 бита (двойной `char`).
Как Unicode влияет на работу с символами в Java?
Unicode значительно расширяет возможности работы с текстами в Java, позволяя программе обрабатывать символы, используемые в различных языках. Если раньше с помощью ASCII можно было кодировать только 128 символов (включая английские буквы и цифры), то Unicode поддерживает огромное количество символов — от символов европейских языков до иероглифов и знаков из китайского, японского и других письменных систем. Это делает Java универсальным инструментом для создания многоязычных приложений, так как позволяет работать с текстами на многих языках без потери данных.
Какие ограничения у кодировки символов типа char в Java?
Главное ограничение кодировки символов типа `char` в Java заключается в том, что каждый символ занимает фиксированные 16 бит, что ограничивает кодирование символов, требующих больше информации. Для большинства символов это не проблема, однако для некоторых знаков из расширенной части Unicode (например, символы с кодами выше 65535) требуется использовать две `char` переменные, образующие «суррогатную пару». Это добавляет дополнительную сложность при работе с такими символами, так как их необходимо правильно обрабатывать и учитывать в строках и других текстовых структурах.
Какие способы кодировки символов в Java помимо `char` существуют?
Помимо типа `char`, в Java для кодирования символов и строк также используется тип `String`. Каждая строка в Java на самом деле представляет собой последовательность символов типа `char`, но в отличие от одного символа, строка может быть длиной в несколько символов. Также для работы с кодировками, такими как UTF-8, в Java есть классы, такие как `String.getBytes()`, которые позволяют преобразовывать строки в массив байтов для хранения и передачи данных. UTF-8 кодирует каждый символ переменной длины, что позволяет эффективно использовать память для текстов на многих языках.
Какая кодировка используется для хранения символов типа char в Java?
В Java символы типа char хранятся в кодировке UTF-16. Каждый символ занимает 2 байта памяти, что позволяет представлять символы большинства языков мира. Однако стоит учитывать, что для некоторых символов, таких как редкие и древние иероглифы, Java использует два элемента типа char для представления одного символа, что называется «суррогатной парой».
Почему в Java символы типа char занимают 2 байта, и что это дает?
Символы типа char в Java занимают 2 байта из-за использования кодировки UTF-16. Эта кодировка позволяет эффективно представлять множество символов, включая символы не только латинского алфавита, но и других мировых языков, таких как китайский или арабский. 2 байта обеспечивают пространство для хранения 65,536 различных символов, что покрывает потребности большинства современных языков. Однако для символов за пределами этого диапазона (например, для определенных эмодзи или древних письменностей) используются суррогатные пары, представляющие один символ двумя 2-байтовыми элементами.