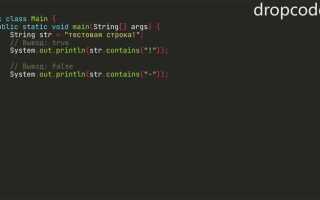
В языке программирования Java строки представлены объектами класса String, который используется для хранения последовательностей символов. Эти объекты неизменяемы, что означает, что после создания строки ее содержимое не может быть изменено. Все изменения строк создают новые объекты, что обеспечивает безопасность многозадачных приложений, исключая проблемы с доступом к данным в многопоточном окружении.
Внутри строки символы хранятся в виде массива char[], где каждый элемент массива представляет собой символ в кодировке UTF-16. Эта кодировка позволяет эффективно хранить символы как в диапазоне от 0 до 65535 (2 байта на символ), что охватывает большинство символов, используемых в мировых языках, включая символы Unicode. Для работы с кодировками в Java также часто используются классы из пакета java.nio.charset, что позволяет конвертировать строки между различными стандартами, такими как UTF-8 или ISO-8859-1.
Важно понимать, что строки в Java не являются простыми массивами байтов, так как символы могут занимать большее количество байтов в зависимости от кодировки. Например, символы, выходящие за пределы базового латинского набора, могут занимать 4 байта в UTF-16. Это стоит учитывать при работе с большими объемами данных, чтобы избежать ошибок при обработке строк в разных кодировках.
Как строки представлены в памяти Java?
Каждая строка в Java – это объект, и, следовательно, она занимает память, помимо самой строки, для хранения метаданных, таких как длина строки и ссылка на массив символов. Строки могут быть размещены в пуле строк, который хранит уникальные строки для повышения эффективности использования памяти. Это происходит благодаря механизму String Pool или String Interning. Когда строка создаётся с использованием литерала, Java проверяет, существует ли такая строка в пуле. Если существует, возвращается ссылка на неё, а если нет – строка добавляется в пул.
Важной особенностью является то, что строки в Java могут быть представлены с использованием разных кодировок в зависимости от конкретной операции. Например, строка, полученная через файл, может быть преобразована в байты с использованием кодировки UTF-8, а затем эти байты могут быть преобразованы обратно в строку с помощью той же кодировки.
Важно учитывать, что строка может занимать больше памяти, чем просто массив символов. Например, при использовании UTF-16 для представления символов, каждый символ занимает 2 байта, но некоторые символы могут занимать 4 байта, если они представлены в виде суррогатных пар, что приводит к дополнительным накладным расходам на память.
Особенности реализации строк в памяти Java также зависят от виртуальной машины (JVM). Для оптимизации работы с памятью JVM может использовать различные механизмы сжатия строк и оптимизацию доступа к строкам. Однако программисты должны помнить, что при создании множества строк с одинаковыми значениями (например, с помощью литералов) эти строки могут быть перемещены в пул строк, что приведёт к экономии памяти, но также требует дополнительных вычислительных затрат на проверку наличия строки в пуле.
Таким образом, строки в Java представлены в памяти как объекты с внутренним массивом символов и могут храниться в пуле строк, что оптимизирует использование памяти и повышает производительность работы с одинаковыми строками.
Что такое UTF-16 и как это влияет на хранение строк?
UTF-16 кодирует символы в двух форматах: базовый и расширенный. Для символов, входящих в стандартный диапазон (от 0 до 65535), используется один 16-битный блок. Для символов, выходящих за пределы этого диапазона, используются два блока, каждый по 16 бит, что приводит к использованию 4 байт для одного символа. Это объясняет, почему некоторые символы занимают больше места в памяти, чем другие.
Важно учитывать, что при хранении строк в UTF-16, каждый символ занимает либо 2 байта, либо 4 байта в зависимости от его кодировки. Это оказывает влияние на производительность и потребление памяти, особенно если в строке присутствуют символы, требующие 4 байта для представления. Например, если строка содержит символы из многих языков с редкими символами, таких как китайские иероглифы, использование UTF-16 может привести к значительному увеличению объема занимаемой памяти.
UTF-16 позволяет эффективно работать с большинством символов, но стоит помнить, что это кодирование не всегда является оптимальным с точки зрения использования памяти для текстов, в которых преобладают символы, требующие только одного 16-битного блока. В таких случаях более компактные кодировки, такие как UTF-8, могут оказаться предпочтительнее с точки зрения экономии памяти.
Для обработки строк в Java важно понимать, что каждая строка представлена как массив символов, где каждый элемент массива – это 16-битный код. Это напрямую влияет на алгоритмы работы с строками, такие как поиск, замена и манипуляции с символами, поскольку операции выполняются на уровне символов, а не байтов.
Как работает пул строк в Java?
Пул строк реализован в классе String, и его основная цель – сохранить уникальные строки, используемые в программе, в одном месте, чтобы не создавать дубликатов в памяти. Когда строка создается с использованием конструктора или метода `new String()`, она не помещается в пул, если только не будет явно добавлена с помощью метода `intern()`. Метод `intern()` проверяет, есть ли строка в пуле, и если ее там нет, добавляет. Если строка уже существует, возвращается ссылка на уже имеющийся объект.
Хранение строк в пуле осуществляется в виде хэш-таблицы, где ключами являются строковые литералы, а значениями – соответствующие им объекты String. Это позволяет быстро находить нужную строку по ключу. Строки, которые добавляются в пул с помощью `intern()`, не подлежат изменению, так как строки в Java неизменяемы. Из-за этого пул строк является важной частью оптимизации работы с памятью, особенно в больших приложениях с частым использованием одинаковых строк.
Важно отметить, что пул строк ограничен размером и может занимать значительную часть памяти, если не контролировать количество строк, попадающих в него. В некоторых случаях может быть полезно использовать метод `intern()` в сочетании с контролем за его применением, чтобы избежать ненужных строк в пуле и снизить нагрузку на систему.
Как изменяется строка в Java: неизменяемость и её последствия
Когда вы выполняете операцию над строкой, такую как добавление, удаление или замена символов, создаётся новый объект строки, а оригинальная строка остаётся неизменной. Например, если вы используете метод concat(), для соединения строк, результат будет новым объектом, содержащим объединённые строки, в то время как исходные строки не изменяются.
Неизменяемость строк в Java имеет несколько последствий для производительности и безопасности. Во-первых, благодаря этому строковые объекты могут быть безопасно использованы в многозадачных приложениях. Их состояния не изменяются, что исключает необходимость в синхронизации при работе с ними из разных потоков.
Однако неизменяемость также накладывает ограничения. Например, при частых изменениях строк в цикле создание новых объектов может приводить к большому потреблению памяти. Для этих случаев рекомендуется использовать класс StringBuilder или StringBuffer, которые позволяют изменять строку без создания нового объекта, улучшая производительность.
Кроме того, неизменяемость строк обеспечивает их неизменность в хеш-таблицах, таких как HashMap, где строки часто используются в качестве ключей. Это предотвращает изменения хеш-кода строки после её добавления в структуру данных, что могло бы нарушить корректность работы коллекции.
Таким образом, неизменяемость строк в Java играет ключевую роль в обеспечении безопасности и стабильности работы программы, но при этом важно учитывать её влияние на производительность при частых операциях с изменением строк.
Какие проблемы могут возникать при работе с кодировками в Java?
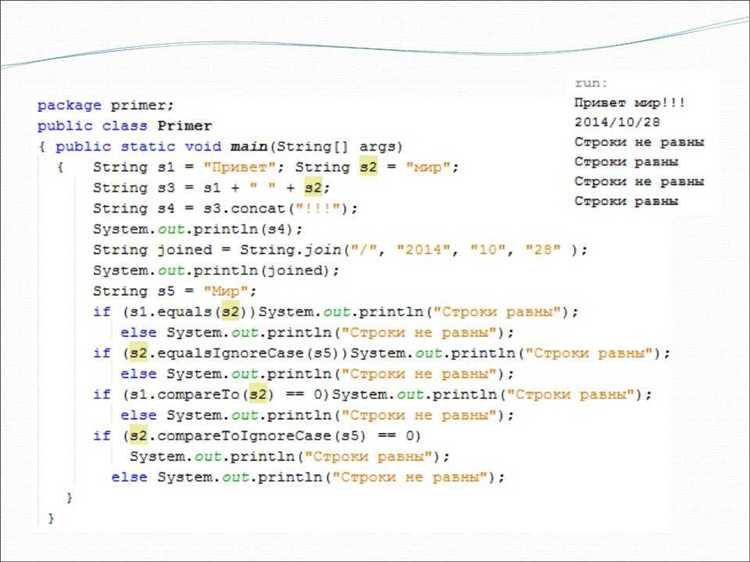
Работа с кодировками в Java может вызвать ряд проблем, связанных с неправильной интерпретацией символов, ошибками в преобразовании данных и неправильным отображением текстовой информации. Вот основные из них:
- Неправильная кодировка при чтении и записи файлов. При работе с файлами, если не указана явная кодировка, Java может по умолчанию использовать кодировку операционной системы. Это может привести к некорректному отображению символов, особенно при переносе данных между различными системами с разными настройками.
- Проблемы с BOM (Byte Order Mark). Некоторые кодировки, такие как UTF-8 и UTF-16, могут содержать BOM, который указывает порядок байтов. При неправильной обработке BOM может вызвать ошибку при интерпретации файла, особенно если программа ожидает текст без BOM.
- Ошибки при работе с базами данных. Если база данных и приложение используют разные кодировки, это может привести к потерям данных или их искажению. Важно синхронизировать кодировку между Java-приложением и базой данных, чтобы предотвратить проблемы с сохранением и извлечением данных.
- Проблемы с отображением символов в консоли. При работе с консольными приложениями важно учитывать, что консоль может использовать свою кодировку, отличную от кодировки приложения. Например, на Windows часто используется Windows-1251, а на Unix-подобных системах UTF-8. Это может привести к неправильному отображению русских или других нестандартных символов.
- Микс кодировок в одном приложении. В больших приложениях часто бывает ситуация, когда различные части системы используют разные кодировки. Например, один модуль может работать с UTF-8, а другой – с ISO-8859-1. Такой микс кодировок приводит к трудностям при обмене данными и повышает вероятность ошибок.
Чтобы минимизировать эти проблемы, рекомендуется:
- Всегда явно указывать кодировку при работе с файлами и строками, например, используя
InputStreamReaderиOutputStreamWriterс указанием кодировки. - При взаимодействии с базой данных использовать кодировку, совместимую с Java, например, UTF-8.
- Для консольных приложений убедиться, что кодировка консоли соответствует кодировке, используемой в программе.
- Использовать стандартные библиотеки Java для работы с кодировками, такие как
CharsetиStandardCharsets, чтобы избежать ошибок при преобразовании данных.
Как правильно работать с кодировками при чтении и записи файлов?
Для корректной работы с кодировками лучше использовать класс InputStreamReader и OutputStreamWriter, которые позволяют задавать кодировку при чтении и записи файлов. Например, чтобы прочитать файл в кодировке UTF-8, следует использовать следующий код:
InputStreamReader reader = new InputStreamReader(new FileInputStream("file.txt"), "UTF-8");
BufferedReader br = new BufferedReader(reader);
Аналогично, при записи в файл с указанием кодировки:
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("file.txt"), "UTF-8");
BufferedWriter bw = new BufferedWriter(writer);
Важно учитывать, что если кодировка не указана явно, Java будет использовать системную кодировку, что может привести к некорректному отображению символов при обработке файлов с нестандартной кодировкой.
Для работы с текстовыми файлами, где заранее известна кодировка, всегда указывайте её в параметрах потоков. Например, для UTF-8 это можно сделать, как показано выше. Для работы с другими кодировками, такими как ISO-8859-1, достаточно заменить «UTF-8» на нужное имя кодировки.
Не забывайте о возможных ошибках при чтении и записи файлов, связанных с несовпадением кодировок. Если файл записан в одной кодировке, а при его чтении используется другая, это приведет к искажению данных. Например, при чтении файла, записанного в UTF-8, как ISO-8859-1, символы могут быть неправильно интерпретированы.
Еще одной важной деталью является использование потоков с буферизацией, как показано в примерах. Это повышает производительность и снижает нагрузку на систему, особенно при работе с большими файлами.
При работе с файлами, в которых используются специфические кодировки, следует всегда проверять исходную кодировку перед тем, как начинать обработку, и использовать соответствующие инструменты для её распознавания, чтобы избежать ошибок при конвертации данных.
Вопрос-ответ:
Как строки хранятся в Java?
В языке Java строки хранятся в виде объектов класса String, который является неизменяемым. Это означает, что после создания строки ее содержимое нельзя изменить. Каждая строка в Java представляет собой последовательность символов, хранящихся в массиве символов типа char[]. Символы в Java представлены в кодировке UTF-16, что позволяет эффективно работать с различными языками и символами.
Как Java работает с кодировкой строк?
Java использует кодировку UTF-16 для представления строк в памяти. Это означает, что каждый символ в строке кодируется с помощью 16 бит. При работе с файлами и внешними источниками данных, Java может автоматически конвертировать строки между различными кодировками, такими как UTF-8, ISO-8859-1 и другими, с помощью классов InputStreamReader и OutputStreamWriter. Это важно для правильной обработки символов в различных языковых и операционных системах.
Почему в Java строки неизменяемы?
Неизменяемость строк в Java обеспечивается несколькими важными факторами. Во-первых, это улучшает безопасность и производительность при работе с многозадачностью, так как несколько потоков могут безопасно использовать одну и ту же строку без риска изменения ее содержимого. Во-вторых, неизменяемость позволяет использовать строки в качестве ключей в коллекциях, таких как HashMap, поскольку они гарантированно не изменяются после создания. Для модификации строк в Java используется класс StringBuilder, который позволяет создавать изменяемые строки.
Как можно изменить строку в Java?
Поскольку строки в Java неизменяемы, для их изменения используется класс StringBuilder или StringBuffer. Эти классы позволяют изменять содержимое строки с помощью методов, таких как append(), insert(), delete() и другие. StringBuilder используется в случаях, когда строки изменяются в одном потоке, а StringBuffer — если требуется поддержка многозадачности. В отличие от класса String, объекты этих классов можно изменять без создания новых экземпляров.