Коллекция Set в Java реализует структуру данных, исключающую дублирование элементов. Она основана на интерфейсе java.util.Set, и каждое добавленное значение должно быть уникальным, что делает её подходящей для задач фильтрации, хранения флагов, а также для проверки на вхождение.
Ключевая особенность реализации HashSet заключается в использовании хэш-таблицы. Элементы не упорядочены, но операции add(), remove() и contains() выполняются за амортизированное время O(1). Для правильной работы требуется переопределение методов equals() и hashCode() у добавляемых объектов.
LinkedHashSet сохраняет порядок вставки, что полезно при необходимости сохранять оригинальную последовательность данных без дубликатов. При этом производительность остается близкой к HashSet, с небольшой надбавкой по памяти.
TreeSet реализует интерфейс NavigableSet и основывается на красно-черном дереве. Элементы сортируются естественным порядком или с использованием переданного компаратора. Время выполнения операций – O(log n), что делает TreeSet предпочтительным выбором при необходимости поддерживать отсортированную коллекцию.
Set не допускает индексированный доступ, поэтому не подходит для сценариев, требующих позиционной адресации. Также стоит избегать изменения состояния объектов, уже добавленных в Set, если их hashCode() или equals() зависят от изменяемых полей – это приводит к нарушению контракта и ошибкам при поиске или удалении.
Рекомендуется использовать Set в сочетании с потоками (Streams) и лямбда-выражениями для эффективной фильтрации и трансформации данных, особенно в сочетании с методами collect(Collectors.toSet()) и distinct().
Когда использовать Set вместо List в прикладных задачах
Коллекция Set подходит для ситуаций, где критично исключение дубликатов и важна высокая производительность операций поиска. Ниже представлены прикладные случаи, в которых использование Set оправдано и эффективно.
- Хранение уникальных значений. Например, при сборе IP-адресов пользователей или email-адресов для рассылки, Set гарантирует отсутствие повторений без дополнительных проверок.
- Проверка принадлежности. Если задача сводится к частым операциям
contains(), такие как проверка, находится ли элемент в черном списке, HashSet обеспечит постоянное время выполнения. - Удаление дубликатов из списка. Конвертация List в Set – быстрый способ очистить коллекцию от повторяющихся элементов без написания дополнительной логики.
- Моделирование множеств. При реализации логики бизнес-правил, где важны математические операции над множествами (объединение, пересечение, разность), Set предоставляет прямую и эффективную поддержку этих операций.
- Оптимизация по памяти при большом количестве уникальных объектов. Set не хранит лишние ссылки на повторяющиеся элементы, в отличие от List, где каждый дубликат – отдельный объект.
Set не следует использовать, если:
- Порядок элементов имеет значение. Например, при сохранении истории событий или отображении элементов в порядке добавления.
- Необходимо наличие повторяющихся значений, например, при подсчёте частоты элементов.
- Имеет значение индексная адресация или требуется сортировка по пользовательскому порядку без реализации Comparator.
Выбор между Set и List зависит от целей: если нужна уникальность и быстрый доступ – выбирайте Set, если важна последовательность и возможность хранения дубликатов – используйте List.
Как работает проверка уникальности элементов в Set
Коллекции Set в Java используют разные механизмы для обеспечения уникальности элементов в зависимости от конкретной реализации. В HashSet применяется хеширование: при добавлении элемента вычисляется его hashCode(), затем выполняется сравнение через equals(), если хеши совпадают. Это означает, что для корректной работы HashSet объекты должны корректно переопределять оба метода – hashCode() и equals(). Несоответствие этих методов приведёт к нарушению логики уникальности.
В LinkedHashSet используется тот же механизм хеширования, но с сохранением порядка добавления. Это не влияет на проверку уникальности, но затрагивает внутреннее представление и может слегка снижать производительность по сравнению с HashSet.
Класс TreeSet использует сортировку, а не хеширование. Уникальность обеспечивается с помощью метода compareTo() (если реализуется интерфейс Comparable) или через переданный Comparator. Если compareTo(a, b) == 0, элементы считаются равными, независимо от реализации equals(). Это значит, что для TreeSet важна корректная реализация логики сравнения, иначе могут добавляться элементы с одинаковыми значениями, но разными экземплярами.
Рекомендуется:
- При использовании
HashSetиLinkedHashSet– всегда переопределятьequals()иhashCode()согласно контракту Java. - При использовании
TreeSet– реализовыватьComparableили использовать надёжныйComparator, обеспечивающий строгую транзитивность и согласованность.
Примеры некорректной реализации, особенно с нарушением контракта hashCode()/equals() или compareTo(), могут привести к дублированию элементов или их потере при поиске. Проверку уникальности необходимо рассматривать как ключевой аспект проектирования классов, используемых в Set.
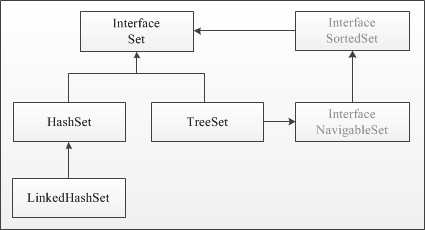
Чем отличаются реализации HashSet, LinkedHashSet и TreeSet
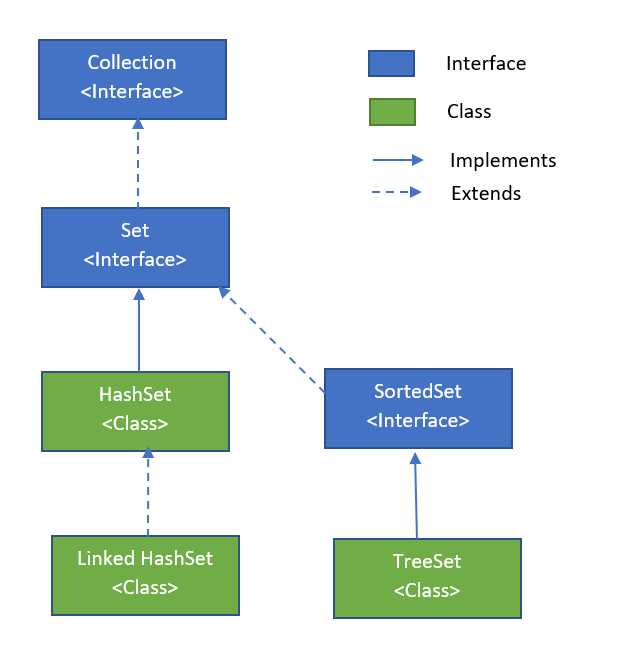
Каждая реализация Set в Java предназначена для определённых сценариев и отличается поведением в части хранения, порядка и производительности.
- HashSet – базовая реализация, не гарантирует порядок элементов. Использует хеш-таблицу. Вставка, удаление и поиск выполняются за амортизированное время
O(1). Не подходит, если нужен стабильный порядок или сортировка. Требует корректно переопределённыхequals()иhashCode()у элементов. - LinkedHashSet – расширяет HashSet, но дополнительно сохраняет порядок вставки элементов. Использует связанный список внутри хеш-таблицы. Производительность операций аналогична HashSet, но с небольшим снижением из-за поддержки порядка. Оптимален, если важен порядок обхода без необходимости сортировки.
- TreeSet – реализует интерфейс
NavigableSetи основан на красно-чёрном дереве. Элементы хранятся отсортированными согласно естественному порядку или заданному компаратору. Операции вставки, удаления и поиска выполняются заO(log n). Требует, чтобы элементы были сравнимыми либо чтобы был предоставленComparator. Используется, когда необходима сортировка и диапазонные операции.
Рекомендации по выбору:
- Используйте HashSet, если важна максимальная производительность и порядок не имеет значения.
- Применяйте LinkedHashSet, когда нужно сохранить порядок добавления без затрат на сортировку.
- Выбирайте TreeSet, если требуется упорядоченное множество или работа с диапазонами элементов.
Какие объекты можно хранить в Set и как это влияет на equals и hashCode
Set хранит только уникальные элементы, и для корректной работы с объектами пользовательских классов необходимо переопределить методы equals() и hashCode(). Без этого Set не сможет определить, какие объекты считаются одинаковыми, особенно в реализациях на основе хеширования, таких как HashSet.
В HashSet при добавлении объекта сначала вычисляется его hashCode(). Если хеш совпадает с уже существующим элементом, выполняется equals() для точного сравнения. Поэтому объекты с разной реализацией этих методов могут вести себя непредсказуемо: визуально одинаковые данные могут дублироваться.
Для корректного хранения объектов в HashSet и LinkedHashSet необходимо, чтобы equals() определял логическое равенство объектов, а hashCode() возвращал одинаковые значения для равных объектов. Нарушение контракта между этими методами приводит к дубликатам или невозможности найти элемент после добавления.
В TreeSet объекты сортируются по натуральному порядку или через Comparator, поэтому метод equals() не участвует в логике хранения. Однако объекты должны быть сопоставимыми: реализовывать интерфейс Comparable или предоставляться через Comparator. Несогласованность между compareTo() и equals() может привести к тому, что логически разные объекты будут считаться дубликатами.
В Set нельзя хранить изменяемые объекты, если их поля участвуют в вычислении hashCode() или логике equals(). После изменения такие элементы могут стать «невидимыми» для коллекции, что нарушит её целостность. Рекомендуется использовать неизменяемые объекты или гарантировать, что изменяемые поля не участвуют в сравнении и хешировании.
Как сохранить порядок добавления элементов в Set
Для сохранения порядка добавления элементов в коллекции Set следует использовать реализацию LinkedHashSet. В отличие от HashSet, который не гарантирует никакого порядка, LinkedHashSet хранит элементы в последовательности их вставки за счёт использования связного списка в дополнение к хеш-таблице.
При создании LinkedHashSet указывается начальная ёмкость и коэффициент загрузки, аналогично HashSet, но поведение при итерации отличается – элементы будут возвращаться в том порядке, в котором были добавлены:
Set<String> orderedSet = new LinkedHashSet<>();
orderedSet.add("apple");
orderedSet.add("banana");
orderedSet.add("cherry");
Итерация по orderedSet вернёт: apple, banana, cherry – именно в том порядке, как они были вставлены. Повторное добавление уже существующего элемента не изменяет порядок, так как Set не допускает дубликатов.
Использование LinkedHashSet оправдано в случаях, когда требуется предсказуемая итерация по элементам. Однако стоит учитывать, что такая структура требует больше памяти по сравнению с HashSet из-за хранения связей между элементами.
Если нужно обеспечить одновременно сохранение порядка и потокобезопасность, рекомендуется обернуть LinkedHashSet через Collections.synchronizedSet, либо использовать CopyOnWriteArraySet из пакета java.util.concurrent, хотя последняя не сохраняет порядок добавления.
Как отсортировать элементы в TreeSet с использованием Comparator
Для сортировки элементов в TreeSet в Java используется интерфейс Comparator. Он позволяет задать собственный порядок элементов, который отличается от естественного порядка (если таковой имеется). При создании TreeSet можно передать экземпляр Comparator, который будет использоваться для упорядочивания элементов. Это особенно полезно, если объекты в коллекции не реализуют интерфейс Comparable или если требуется другой порядок сортировки.
Пример использования Comparator для сортировки строк в обратном порядке:
import java.util.*;
public class Example {
public static void main(String[] args) {
Comparator reverseOrder = (s1, s2) -> s2.compareTo(s1);
TreeSet set = new TreeSet<>(reverseOrder);
set.add("banana");
set.add("apple");
set.add("cherry");
}
}
В данном примере используется лямбда-выражение для создания Comparator, который сортирует строки в обратном порядке. В результате TreeSet будет содержать элементы, отсортированные от Z к A, а не от A к Z.
Также можно использовать стандартные компараторы, такие как Comparator.reverseOrder(), если порядок сортировки нужно инвертировать для уже отсортированной коллекции:
TreeSet set = new TreeSet<>(Comparator.reverseOrder());
set.add(5);
set.add(3);
set.add(7);
Важно помнить, что TreeSet автоматически поддерживает упорядоченность элементов, и поэтому изменения порядка через Comparator касаются только той коллекции, для которой он был передан. Если необходимо изменить порядок сортировки в уже существующем TreeSet, нужно создать новый TreeSet с другим Comparator.
Кроме того, Comparator может быть комбинирован с другими компараторами с помощью методов, таких как thenComparing(). Например, для сортировки объектов по нескольким критериям:
Comparator comparator = Comparator.comparing(Person::getLastName)
.thenComparing(Person::getFirstName);
TreeSet people = new TreeSet<>(comparator);
В данном примере объекты типа Person будут сортироваться сначала по фамилии, а затем по имени. Использование Comparator в TreeSet дает гибкость и позволяет адаптировать порядок сортировки под конкретные задачи.
Как безопасно изменять Set во время итерации
Изменение коллекции Set во время итерации может привести к исключению ConcurrentModificationException, если используется итератор, созданный для этого множества. Это происходит из-за того, что итератор предполагает неизменность коллекции в процессе её обхода, и любое изменение, влияющее на структуру множества, нарушает его работу.
Для безопасного изменения Set во время итерации существует несколько подходов, каждый из которых имеет свои особенности и ограничения.
1. Использование итератора с методами remove()
Если нужно удалять элементы во время обхода множества, можно использовать метод remove() самого итератора. Этот способ безопасен, так как он поддерживает корректное обновление внутренней структуры множества и избегает исключений.
Set<String> set = new HashSet<>(Arrays.asList("A", "B", "C", "D"));
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
if (element.equals("B")) {
iterator.remove(); // Удаляем элемент через итератор
}
}
Этот метод позволяет избежать ошибок при удалении элементов во время итерации.
2. Использование коллекций, поддерживающих безопасное изменение
Коллекции из пакета java.util.concurrent, такие как CopyOnWriteArraySet, позволяют безопасно изменять структуру множества во время его обхода. Однако они имеют свои особенности: каждое изменение приводит к созданию новой копии коллекции, что может быть неэффективным при частых изменениях.
Set<String> set = new CopyOnWriteArraySet<>(Arrays.asList("A", "B", "C", "D"));
for (String element : set) {
if (element.equals("C")) {
set.remove(element); // Безопасно удалять элементы
}
}
Этот подход идеально подходит для случаев, когда изменения происходят редко или коллекция имеет небольшое количество элементов.
3. Использование дополнительных коллекций
Если необходимо добавлять или удалять элементы во время итерации, можно создать отдельную коллекцию для хранения изменений, а затем применить их после завершения обхода. Это позволяет избежать проблем с изменением коллекции во время её обхода, сохраняя при этом логику добавления или удаления элементов.
Set<String> set = new HashSet<>(Arrays.asList("A", "B", "C", "D"));
Set<String> toRemove = new HashSet<>();
for (String element : set) {
if (element.equals("B")) {
toRemove.add(element); // Добавляем элементы в временный набор
}
}
set.removeAll(toRemove); // Применяем изменения после итерации
Этот способ подходит, если количество изменений невелико и их можно обработать после завершения обхода.
4. Использование потоковых операций (Stream API)
Если необходимо выполнять сложные изменения с набором данных, можно воспользоваться потоками из Stream API. Например, можно создать новый набор, отфильтровав ненужные элементы, не изменяя оригинальную коллекцию в процессе итерации.
Set<String> set = new HashSet<>(Arrays.asList("A", "B", "C", "D"));
set = set.stream()
.filter(element -> !element.equals("B")) // Фильтрация элементов
.collect(Collectors.toSet());
Этот метод позволяет избегать ошибок при изменении коллекции, но важно помнить, что он создает новый набор, не изменяя исходный.
Каждый из перечисленных методов имеет свои преимущества и ограничения. Выбор зависит от требований к производительности, типу коллекции и специфике изменения данных в процессе итерации.
Какие операции объединения, пересечения и разности поддерживает Set
Интерфейс Set в Java предоставляет несколько операций, позволяющих работать с коллекциями данных, выполняя различные математические операции над элементами множества. Основные операции включают объединение, пересечение и разность. Рассмотрим, как их реализовать в языке Java.
Объединение (Union) – это операция, которая объединяет два множества, включая все элементы из обоих, но исключая повторения. В Java для выполнения объединения можно использовать метод addAll() коллекции Set. Пример:
Setset1 = new HashSet<>(Arrays.asList(1, 2, 3)); Set set2 = new HashSet<>(Arrays.asList(3, 4, 5)); set1.addAll(set2); // set1 теперь содержит {1, 2, 3, 4, 5}
Этот метод добавляет все элементы второго множества в первое, при этом повторяющиеся элементы не будут добавлены, так как Set гарантирует уникальность.
Пересечение (Intersection) – это операция, которая находит общие элементы между двумя множествами. В Java для этого используется метод retainAll(). Пример:
Setset1 = new HashSet<>(Arrays.asList(1, 2, 3)); Set set2 = new HashSet<>(Arrays.asList(3, 4, 5)); set1.retainAll(set2); // set1 теперь содержит {3}
После выполнения этого метода в первом множестве останутся только те элементы, которые присутствуют и во втором множестве. Остальные будут удалены.
Разность (Difference) – операция, которая удаляет из первого множества все элементы, присутствующие во втором. Для выполнения разности используется метод removeAll(). Пример:
Setset1 = new HashSet<>(Arrays.asList(1, 2, 3)); Set set2 = new HashSet<>(Arrays.asList(3, 4, 5)); set1.removeAll(set2); // set1 теперь содержит {1, 2}
Метод removeAll() удаляет все элементы, которые есть в другом множестве. В результате остается только те элементы, которые присутствуют исключительно в первом множестве.
Эти операции позволяют эффективно манипулировать данными в коллекциях, обеспечивая высокую производительность за счет использования уникальности элементов в множестве. Для работы с большими данными важно учитывать, что операции выполняются за время O(n), где n – количество элементов в коллекциях.
Вопрос-ответ:
Что такое коллекция Set в Java?
Коллекция Set в Java представляет собой структуру данных, предназначенную для хранения элементов без дублирования. Каждый элемент может встречаться в Set только один раз, и порядок элементов не гарантируется. Это позволяет использовать Set для хранения уникальных значений, когда важен только сам факт присутствия элемента, а не его количество или порядок.
Какие преимущества использования Set в Java по сравнению с другими коллекциями?
Главное преимущество Set — это его способность обеспечивать уникальность элементов. В отличие от List или других коллекций, в Set нельзя добавить одинаковые объекты. Это идеально подходит для случаев, когда нужно избежать дублирования данных. Также Set обычно имеет более быстрые операции поиска, вставки и удаления элементов по сравнению с другими коллекциями, если речь идет о HashSet, например.
Какую реализацию Set в Java выбрать для хранения элементов?
Java предоставляет несколько реализаций Set, каждая из которых имеет свои особенности. Например, HashSet — это наиболее распространенная реализация, которая использует хеширование для быстрого поиска и вставки элементов. TreeSet гарантирует хранение элементов в отсортированном порядке, а LinkedHashSet сохраняет порядок вставки. Выбор зависит от задачи: если нужно просто хранить уникальные элементы без учета порядка, выберите HashSet. Если порядок важен, стоит рассмотреть LinkedHashSet или TreeSet.
Что произойдет, если попытаться добавить дублирующийся элемент в Set?
Когда вы пытаетесь добавить элемент в Set, который уже присутствует, коллекция просто игнорирует эту операцию. Это происходит потому, что Set не допускает дублирования. Если вы добавляете элемент, который уже есть в коллекции, метод add вернет false, указывая, что элемент не был добавлен, так как он уже существует.
Как проверить, содержит ли Set определенный элемент?
Чтобы проверить, содержит ли Set определенный элемент, используется метод contains(). Он возвращает true, если элемент присутствует в коллекции, и false, если нет. Например, если у вас есть коллекция Set, вы можете написать: `set.contains(element)` для проверки наличия элемента в коллекции.
Что такое коллекция Set в Java и какие у неё особенности?
Коллекция Set в Java — это структура данных, предназначенная для хранения элементов без повторений. Это значит, что каждый элемент может встречаться в коллекции только один раз. Set реализует интерфейс Collection, но отличается от List тем, что не гарантирует сохранение порядка элементов. Среди популярных реализаций Set можно выделить HashSet, TreeSet и LinkedHashSet. HashSet не гарантирует порядок элементов, TreeSet сортирует элементы по определённому порядку, а LinkedHashSet сохраняет порядок добавления элементов. Коллекция Set полезна в тех случаях, когда важно предотвратить дублирование значений, например, при учёте уникальных пользователей или товаров.
Какие основные различия между HashSet и TreeSet в Java?
Основное различие между HashSet и TreeSet в том, как они хранят элементы и их порядок. HashSet использует хеширование для хранения элементов, что позволяет обеспечивать быструю вставку, удаление и проверку наличия элементов, но не гарантирует порядка элементов. В TreeSet элементы автоматически сортируются в естественном порядке (или по заданному компаратору), что делает его медленнее по сравнению с HashSet для операций вставки и поиска. TreeSet также не позволяет хранить элементы, которые не могут быть сравниваемыми или не удовлетворяют правилам сортировки, в отличие от HashSet, который не имеет таких ограничений. Если порядок элементов важен, предпочтительнее использовать TreeSet, в противном случае лучше выбрать HashSet для более быстрого доступа и манипуляций с данными.