При работе с массивами в Java важно понимать различные способы перебора элементов. Несмотря на то, что Java предоставляет несколько механизмов для этого, важно выбрать подходящий метод, который будет эффективен с точки зрения производительности и читабельности кода. В этом руководстве рассмотрим основные подходы и их особенности.
Первый способ – использование цикла for. Этот метод идеально подходит для работы с индексами массива. Он предоставляет прямой доступ к каждому элементу по его индексу, что позволяет легко управлять логикой перебора. Важно помнить, что цикл for работает эффективно, когда заранее известен размер массива.
Другой вариант – использование foreach цикла, который доступен с версии Java 5. Этот способ более лаконичен и избавляет от необходимости вручную управлять индексами. Использование foreach делает код чище, но он ограничен в плане гибкости, особенно если вам нужно модифицировать элементы массива в процессе обхода.
В случае, если требуется получить доступ к элементам массива и одновременно учитывать их индекс, можно использовать класс ArrayList или методы из пакета java.util.stream. Потоки позволяют обрабатывать массивы с использованием функционального подхода, предоставляя дополнительные возможности для фильтрации и трансформации данных.
Создание массива и базовая настройка

Для объявления массива используется следующая синтаксическая конструкция: тип[] имя_массива;. Например, чтобы создать массив целых чисел, можно написать: int[] numbers;.
Чтобы выделить память для массива, используется оператор new. Пример создания массива на 5 элементов: numbers = new int[5];. Это создает массив с 5 элементами, каждый из которых по умолчанию инициализируется значением 0 для типа int.
Также можно объединить объявление и создание массива в одну строку: int[] numbers = new int[5];.
Для инициализации массива значениями при его создании можно использовать литералы. Например: int[] numbers = {1, 2, 3, 4, 5};. Такой массив будет сразу содержать указанные значения.
Инициализация массива с помощью литералов доступна только при объявлении массива. После создания массива с фиксированным размером его элементы могут быть изменены, но сам размер остается неизменным.
Важно помнить, что массивы в Java индексируются с нуля. То есть первый элемент массива находится по индексу 0, второй – по индексу 1, и так далее. Попытка обратиться к элементу с индексом, превышающим размер массива, приведет к ошибке выполнения.
Использование цикла for для перебора элементов
for (инициализация; условие; шаг) {
// тело цикла
}
Для перебора массива, например, можно использовать цикл for с индексом, который будет изменяться от 0 до длины массива минус один. Рассмотрим пример:
int[] arr = {1, 2, 3, 4, 5};
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
В этом примере индекс i начинается с 0 и увеличивается до значения arr.length - 1, что позволяет пройти по всем элементам массива. Это основной и самый распространённый способ использования цикла for при работе с массивами.
Для улучшения читаемости кода и повышения эффективности, можно использовать цикл for-each. Этот цикл избавляет от необходимости работать с индексами и часто используется для итерации по элементам массива:
for (int element : arr) {
System.out.println(element);
}
Цикл for-each делает код более компактным и снижает риск ошибок, связанных с неправильным обращением к индексам массива.
Однако стоит помнить, что цикл for не всегда является наилучшим решением для работы с многомерными массивами. В таких случаях предпочтительнее использовать вложенные циклы for для корректной обработки каждого измерения массива:
int[][] matrix = {{1, 2}, {3, 4}, {5, 6}};
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[i].length; j++) {
System.out.println(matrix[i][j]);
}
}
При работе с большими массивами важно учитывать производительность, особенно если массив имеет несколько миллионов элементов. В таких случаях полезно ограничить количество итераций или использовать параллельные потоки для ускорения обработки.
Применение цикла while для обхода массива
Цикл while может быть полезен при обходе массива в Java, особенно если количество элементов массива заранее неизвестно или если требуется выполнить дополнительные действия до начала или после завершения обхода. В отличие от цикла for, в котором итерации заранее определены, while позволяет более гибко контролировать процесс обхода массива.
Для использования цикла while при обходе массива необходимо контролировать индекс элемента массива вручную. Обычно для этого создается переменная-счётчик, которая инициализируется значением 0 (первый индекс массива), и пока счётчик меньше длины массива, продолжается выполнение цикла.
Пример кода:
int[] numbers = {1, 2, 3, 4, 5};
int i = 0;
while (i < numbers.length) {
System.out.println(numbers[i]);
i++;
}
В данном примере переменная i служит индексом для массива. Цикл while продолжает выполняться, пока i меньше длины массива numbers. После каждой итерации значение i увеличивается на 1, что позволяет переходить к следующему элементу массива.
Особенности применения цикла while:
- Цикл while полезен, если количество итераций зависит от других условий или динамически изменяется в процессе выполнения программы.
- Важно следить за тем, чтобы условие выхода из цикла было корректным. Неправильно настроенное условие может привести к бесконечному циклу.
- Цикл while подходит для ситуаций, где заранее неизвестно, сколько раз необходимо выполнить итерацию, но есть чёткое условие для завершения цикла.
Применение цикла while при обходе массива помогает избежать излишней сложности, сохраняя высокую гибкость, особенно в нестандартных случаях работы с данными массива.
Итерация через foreach: когда это удобно

Цикл foreach в Java предлагает простой способ пройтись по массиву или коллекции, избегая явного использования индексов. Это делает его идеальным для случаев, когда важно только значение элемента, а не его позиция в структуре данных. Особенно полезен foreach для работы с коллекциями, где важен порядок элементов, но не их индекс.
Использование foreach оправдано, когда:
- Не требуется доступ к индексу. Когда доступ к позиции элемента в массиве или коллекции не нужен, использование
foreachснижает количество кода и предотвращает ошибки, связанные с некорректным использованием индексов. - Простота кода важнее гибкости. В отличие от традиционного цикла
for, где требуется вручную управлять индексом,foreachуменьшает количество строк кода и делает его более понятным, особенно для новичков.
Однако, несмотря на удобство, foreach имеет и свои ограничения. Например, он не позволяет изменить элементы коллекции в процессе итерации, а также не предоставляет механизма для пропуска или обратного обхода элементов. Для более сложных операций, таких как модификация данных или обратная итерация, лучше использовать традиционные циклы.
Доступ к элементам массива по индексу и обработка ошибок

В языке программирования Java доступ к элементам массива осуществляется с помощью индексации. Индексы массивов начинаются с 0, и для правильной работы с ними необходимо учитывать несколько важных аспектов.
Чтобы обратиться к элементу массива, достаточно указать его индекс в квадратных скобках после имени массива. Пример:
int[] array = {1, 2, 3, 4, 5};
int value = array[2]; // Получим значение 3
Однако при работе с массивами важно учитывать, что попытка доступа к индексу, который выходит за пределы массива, приведет к исключению. Например, если массив содержит 5 элементов, индексы могут быть от 0 до 4. Попытка доступа к индексу 5 вызовет ошибку:
int[] array = {1, 2, 3, 4, 5};
int value = array[5]; // Ошибка: ArrayIndexOutOfBoundsException
Чтобы избежать таких ошибок, можно использовать несколько подходов:
- Проверка границ индекса: перед обращением к элементу массива проверяйте, что индекс лежит в допустимом диапазоне от 0 до длины массива минус один.
int index = 5;
if (index >= 0 && index < array.length) {
int value = array[index];
} else {
System.out.println("Индекс выходит за пределы массива");
}
- Обработка исключений: можно обернуть доступ к массиву в блок try-catch, чтобы перехватывать исключение ArrayIndexOutOfBoundsException.
try {
int value = array[5];
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("Ошибка: индекс за пределами массива");
}
Для улучшения читаемости и надежности кода рекомендуется использовать проверку индексов и обработку исключений в зависимости от контекста задачи. При этом важно помнить, что избегать ошибок можно только при строгом соблюдении правил работы с массивами в Java.
Работа с многомерными массивами в Java
Многомерные массивы в Java представляют собой массивы массивов. Это позволяет хранить данные в виде таблиц, матриц и других сложных структур. Каждый элемент многомерного массива может быть также массивом, что делает работу с ним гибкой, но и более сложной по сравнению с одномерными массивами.
Для создания двумерного массива в Java используется следующий синтаксис:
тип[][] имя = new тип[размер1][размер2];
Пример: для создания массива 3x4 (3 строки и 4 столбца) тип данных будет int, а массив будет выглядеть так:
int[][] массив = new int[3][4];
Доступ к элементам массива осуществляется через индексы строк и столбцов:
массив[0][1] = 5; // Присваиваем значение 5 элементу в первой строке и втором столбце
Каждый элемент массива инициализируется значением по умолчанию для выбранного типа. Для примера с int это будет 0.
Для перебора элементов многомерного массива удобно использовать вложенные циклы. Если нужно пройтись по всем элементам двумерного массива, это будет выглядеть так:
for (int i = 0; i < массив.length; i++) {
for (int j = 0; j < массив[i].length; j++) {
System.out.println(массив[i][j]);
}
}
Для работы с массивами больших размерностей можно использовать динамическое выделение памяти. Например, для создания массива переменной длины (например, в случае использования разных строк в двумерном массиве) можно использовать следующее:
int[][] массив = new int[3][]; массив[0] = new int[4]; // Первая строка с 4 элементами массив[1] = new int[2]; // Вторая строка с 2 элементами массив[2] = new int[5]; // Третья строка с 5 элементами
В таком случае размеры внутренних массивов могут быть разными, что позволяет гибко управлять структурой данных. Для работы с более высокими измерениями (трехмерные, четырехмерные массивы и так далее) просто добавляются дополнительные индексы в объявление массива:
тип[][][] массив = new тип[размер1][размер2][размер3];
При работе с многомерными массивами важно учитывать, что доступ к элементам массива требует точного указания всех индексов, и ошибка в одном из них может привести к ArrayIndexOutOfBoundsException.
Также стоит помнить, что массивы в Java являются объектами, и если двумерный массив не инициализируется сразу, элементы внутреннего массива могут быть null. Поэтому перед использованием важно проверять их на null, чтобы избежать ошибок.
Используя эти подходы, можно эффективно работать с многомерными массивами в Java и решать задачи, требующие сложных структур данных.
Перебор массива с использованием потоков (Streams)
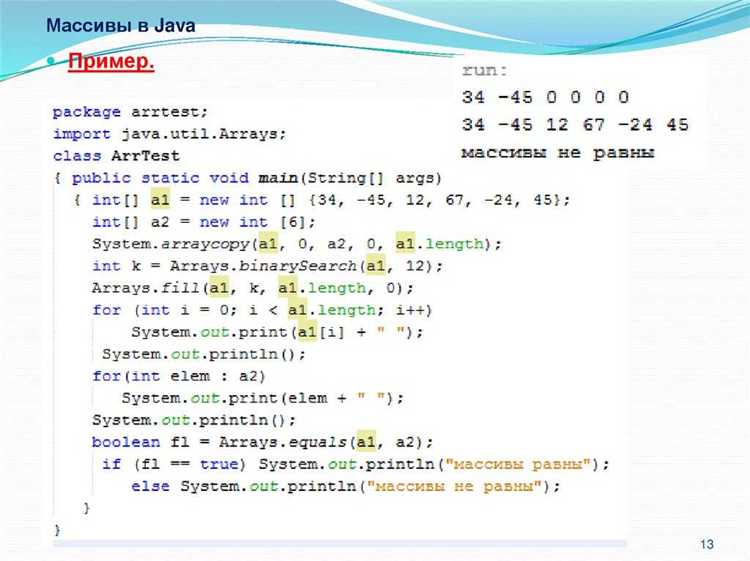
Использование потоков (Streams) в Java позволяет эффективно работать с массивами, обеспечивая компактность и высокую читаемость кода. Потоки предоставляют декларативный подход к обработке данных, заменяя традиционные циклы и позволяя использовать функциональные операции.
Для того чтобы создать поток из массива, можно использовать метод Arrays.stream(), который возвращает поток элементов массива. Пример создания потока:
int[] numbers = {1, 2, 3, 4, 5};
Arrays.stream(numbers).forEach(System.out::println);Одним из ключевых преимуществ потоков является возможность комбинировать операции для более сложных задач. Например, можно отфильтровать элементы массива, преобразовать их и затем вычислить сумму:
int sum = Arrays.stream(numbers)
.filter(n -> n % 2 == 0) // отбираем четные числа
.map(n -> n * 2) // умножаем на 2
.sum(); // суммируемВ этом примере массив сначала фильтруется, оставляя только четные числа, затем каждый элемент умножается на 2, и в конце вычисляется сумма всех элементов.
Важно помнить, что потоки в Java используют ленивую (lazy) обработку. Это значит, что операции не выполняются, пока не будет вызвана терминальная операция, такая как forEach(), collect() или sum(). Например, код с фильтрацией и преобразованием элементов не выполнит никаких операций, пока не вызвана операция суммирования.
Для оптимизации работы с большими массивами можно использовать параллельные потоки. Вместо обычного потока используется метод parallelStream(), который разбивает задачу на несколько потоков, ускоряя обработку данных на многоядерных процессорах:
int parallelSum = Arrays.stream(numbers)
.parallel() // активируем параллельную обработку
.filter(n -> n % 2 == 0)
.map(n -> n * 2)
.sum();Использование параллельных потоков может ускорить обработку при работе с большими объемами данных, но следует учитывать, что для малых массивов накладные расходы на создание дополнительных потоков могут привести к снижению производительности.
При работе с потоками важно помнить о принципе "неизменяемости". Потоки не изменяют исходный массив, а создают новые объекты для каждого шага обработки. Это помогает избежать побочных эффектов, делая код более безопасным и предсказуемым.
Оптимизация перебора массива для больших объемов данных
Перебор массивов с большими объемами данных требует особого внимания к производительности. Стандартные методы могут оказаться неэффективными, поэтому важно использовать подходы, которые минимизируют время выполнения и расход ресурсов.
- Использование параллельных потоков – в случае массивов большого размера стоит использовать возможности многозадачности. В Java это можно сделать с помощью
parallelStream(), который автоматически разбивает задачу на несколько потоков. Такой подход особенно полезен, если данные можно разделить на независимые части. - Оптимизация доступа к элементам – массивы в Java являются структурами с постоянным временем доступа. Однако, если данные лежат в больших объемах или работают с внешними источниками (например, файлами или базами данных), время доступа может значительно увеличиться. Оптимизация заключается в минимизации количества обращений к массиву и предпочтении работы с блоками данных (например, чтение больших порций данных за один раз).
- Использование индексации с шагом – если обработка элементов массива не требует последовательного доступа, можно использовать индексацию с шагом для пропуска элементов. Это уменьшит количество итераций, ускоряя выполнение.
- Избежание лишних операций – каждый цикл должен минимизировать количество выполняемых операций. Например, если вам нужно выполнить сложную вычислительную задачу для каждого элемента, лучше проводить её только один раз в конце цикла, а не каждый раз при итерации.
Для ускорения работы с массивами, которые содержат примитивные типы данных, лучше избегать использования коллекций, таких как ArrayList, поскольку они содержат лишние операции по упаковке и распаковке данных. Применяйте обычные массивы, если важна производительность.
- Использование кеширования – в случае, когда данные часто обновляются или используются повторно, имеет смысл использовать кеширование результатов промежуточных вычислений. Это особенно актуально для сложных вычислений, где один и тот же элемент массива может быть использован несколько раз.
- Распараллеливание на уровне алгоритма – иногда использование параллельных потоков недостаточно. В таких случаях можно применить алгоритмическую оптимизацию, например, сортировать данные перед обработкой или использовать специализированные структуры данных (например, кучу или дерево), чтобы ускорить поиск и обработку элементов.
Оптимизация перебора массивов для больших объемов данных требует тщательного подхода, который учитывает не только аппаратные ресурсы, но и специфику решаемой задачи. Умелое использование многозадачности, эффективная индексация и минимизация избыточных операций могут существенно улучшить производительность программы.