HashMap в Java – это структура данных, которая позволяет хранить пары ключ-значение. При добавлении элемента в HashMap, данные распределяются по бакетам с использованием хеш-функции, что обеспечивает быстрый доступ по ключу. Однако, когда количество элементов в коллекции растет, возникает необходимость в расширении этой структуры. Рассмотрим, как именно происходит процесс увеличения размера HashMap и какие механизмы стоят за этим.
По умолчанию размер HashMap равен 16, и она использует коэффициент загрузки 0.75. Это означает, что когда количество элементов достигает 75% от текущего размера, происходит расширение коллекции. Важно понимать, что увеличение происходит с увеличением емкости в два раза. Это связано с особенностями хеширования: если бакеты не могут вместить все элементы, то происходит перераспределение данных по новым бакетам, что позволяет избежать коллизий и поддерживать производительность.
Перераспределение данных при расширении требует перерасчета хешей всех существующих элементов, что может быть ресурсоемким процессом, особенно когда размер коллекции большой. После увеличения емкости HashMap создает новый массив бакетов и переносит все элементы на новые позиции в соответствии с их хеш-значениями. Этот процесс называется реорганизацией.
Ключевая особенность расширения HashMap – это баланс между производительностью и памятью. При слишком частом расширении коллекции может возникнуть значительная нагрузка на систему, а при недостаточной емкости – увеличение числа коллизий. Чтобы оптимизировать использование памяти и повысить эффективность работы с HashMap, важно правильно настроить начальную емкость и коэффициент загрузки в зависимости от предполагаемого числа элементов.
Как HashMap увеличивает размер при переполнении
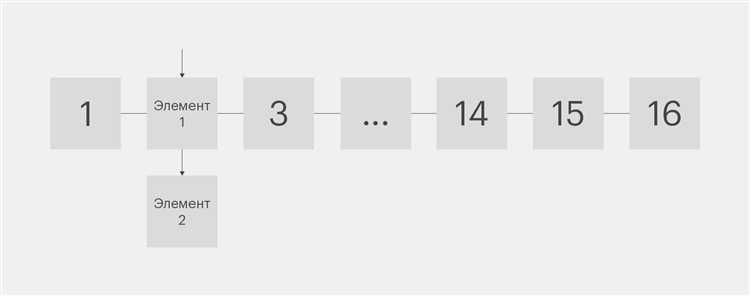
Когда количество элементов в HashMap достигает определённого порога, происходит автоматическое увеличение его размера. Этот процесс необходим для поддержания производительности при вставке новых данных. В Java стандартное расширение HashMap происходит при переполнении, когда количество элементов превышает коэффициент загрузки (load factor), который по умолчанию составляет 0.75.
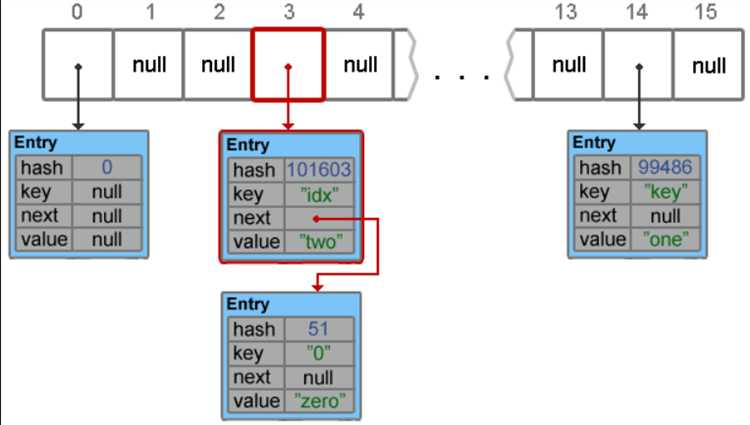
HashMap использует массив бакетов для хранения данных. Каждый элемент данных размещается в бакете, и когда количество элементов в коллекции превышает порог, происходит реорганизация данных. Размер хэш-таблицы увеличивается в два раза, и все элементы перераспределяются по новым бакетам, что позволяет сохранить эффективность доступа к данным.
Основные этапы расширения HashMap при переполнении:
- При добавлении нового элемента количество элементов в HashMap сравнивается с порогом, определяемым коэффициентом загрузки (size > capacity * load factor).
- Когда порог превышен, происходит выделение нового массива бакетов, размер которого в два раза больше предыдущего.
- Каждый элемент перераспределяется по новым бакетам в зависимости от нового размера хэш-таблицы, что гарантирует равномерное распределение элементов.
Важно отметить, что этот процесс перераспределения данных может значительно замедлить работу приложения, так как требует перерасчёта хеш-функций и копирования всех данных в новый массив. Чтобы избежать частых перераспределений, можно заранее установить размер коллекции или уменьшить коэффициент загрузки, если это необходимо.
Пример расчёта порога переполнения:
| Параметр | Значение |
|---|---|
| Начальный размер | 16 |
| Коэффициент загрузки | 0.75 |
| Порог переполнения | 12 (16 * 0.75) |
Таким образом, при достижении порога в 12 элементов в коллекции размер хэш-таблицы будет увеличен до 32 бакетов, и элементы перераспределятся по новому массиву.
Роль коэффициента загрузки в процессе расширения
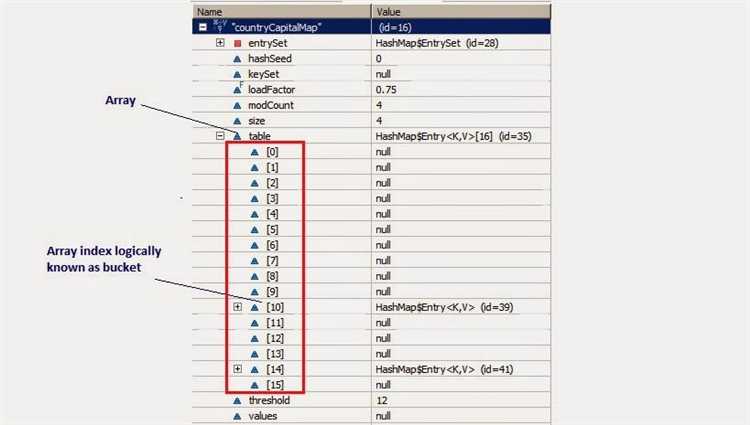
Коэффициент загрузки (load factor) в HashMap определяет, когда необходимо увеличить размер хеш-таблицы, чтобы избежать излишней коллизии. Он задает порог заполненности, при котором HashMap будет расширять свои внутренние структуры, сохраняя баланс между эффективностью поиска и использованием памяти.
Значение коэффициента загрузки влияет на частоту расширений. При высоком коэффициенте загрузки (например, 0.9) расширения происходят реже, но вероятность коллизий увеличивается. При низком коэффициенте загрузки (например, 0.5) количество расширений возрастает, но это снижает риск коллизий и ускоряет операции поиска.
По умолчанию коэффициент загрузки в Java составляет 0.75, что является компромиссом между производительностью и памятью. Однако его можно настроить при создании HashMap. Например:
HashMap map = new HashMap<>(16, 0.5f); Это создаст карту с начальным размером 16 и коэффициентом загрузки 0.5. То есть расширение произойдет, когда число элементов превысит 8 (16 * 0.5).
- Преимущества низкого коэффициента загрузки: меньше коллизий, улучшенная производительность поиска.
- Недостатки низкого коэффициента загрузки: увеличение количества расширений, что может привести к потере памяти и необходимости перераспределения.
- Преимущества высокого коэффициента загрузки: реже происходят расширения, что снижает накладные расходы.
- Недостатки высокого коэффициента загрузки: увеличение вероятности коллизий, что может замедлить операции поиска и вставки.
При выборе коэффициента загрузки важно учитывать требования к производительности и доступной памяти. Например, если вы работаете с ограниченными ресурсами, лучше установить более низкий коэффициент загрузки. В случае, когда количество элементов заранее известно и не изменяется сильно, оптимальным будет значение около 0.5.
Как происходит перераспределение элементов при расширении
При расширении HashMap в Java происходит перераспределение элементов в новую таблицу с большим количеством корзин (buckets). Это необходимо для уменьшения числа коллизий и повышения производительности. Когда текущая таблица заполняется до определённого порога (обычно 75% от её ёмкости), HashMap инициирует перераспределение.
Процесс перераспределения включает несколько шагов. Во-первых, создаётся новая таблица с ёмкостью, в два раза большей, чем у старой. Каждый элемент из старой таблицы помещается в новую, вычисляется его новый индекс с учётом новой ёмкости. Это делается через хеш-функцию, которая используется для определения места элемента в новой таблице.
Перераспределение требует повторного вычисления хеш-кодов для всех элементов. Это необходимо, так как ёмкость таблицы изменилась, а следовательно, изменяется распределение элементов по корзинам. Если два элемента с одинаковым хеш-кодом попадают в одну корзину, они будут храниться в виде связанного списка или сбалансированного дерева, в зависимости от версии Java и числа элементов в корзине.
Перераспределение требует значительных вычислительных ресурсов, поскольку необходимо пройти по всем текущим элементам и перенести их в новую таблицу. Время этого процесса пропорционально количеству элементов в HashMap, то есть сложность операции – O(n), где n – количество элементов.
Для оптимизации работы с HashMap важно контролировать размер и ёмкость таблицы. В некоторых случаях, например, если известно, что HashMap будет часто изменяться, можно заранее указать начальную ёмкость и коэффициент нагрузки (load factor), чтобы избежать частых перераспределений.
Какие проблемы могут возникнуть при расширении HashMap
Одной из проблем является увеличение времени на операции добавления и поиска. При расширении HashMap выполняется перераспределение элементов по новым ведрам, что может вызвать временные замедления, особенно если объём данных велик. В некоторых случаях эта операция может занять достаточно много времени, что негативно сказывается на производительности приложения.
Кроме того, увеличение размера HashMap приводит к увеличению потребляемой памяти. Расширение структуры данных может потребовать дополнительных ресурсов для хранения новых ведер, что увеличивает общий расход памяти. Это особенно важно при работе с большими наборами данных, где даже небольшое увеличение размера карты может привести к заметному увеличению потребления памяти.
Другой проблемой является потеря хэш-распределения, если хэш-функция плохо сбалансирована. В случае неравномерного распределения ключей по ведрам, нагрузка на ведра может увеличиться, что приведёт к большому количеству коллизий. Это замедлит операции поиска и вставки, поскольку для обработки коллизий потребуется больше времени.
Если приложение работает в многозадачной среде, расширение HashMap может создать проблемы с синхронизацией. В Java стандартный HashMap не является потокобезопасным. При одновременном доступе нескольких потоков может возникнуть состояние гонки, когда один поток модифицирует коллекцию, а другой пытается её прочитать. Это может привести к непредсказуемому поведению программы.
Для минимизации этих проблем рекомендуется заранее выбирать подходящий размер ёмкости для HashMap, чтобы избежать слишком частых расширений. Также полезно использовать альтернативы, такие как ConcurrentHashMap, в многозадачных приложениях, где требуется безопасный доступ из разных потоков.
Как контролировать процесс расширения с помощью кастомных параметров
В Java HashMap расширяется, когда количество элементов в хэш-таблице превышает определенный порог, обычно равный 75% от ёмкости. Однако можно настроить этот процесс с помощью кастомных параметров для улучшения производительности в зависимости от специфики задачи.
Основные параметры, влияющие на расширение HashMap:
- Начальная ёмкость – задаёт первоначальный размер хэш-таблицы. Выбор этого значения должен быть обусловлен предполагаемым количеством элементов, чтобы избежать лишних расширений в будущем.
- Коэффициент загрузки (load factor) – определяет, при каком уровне заполненности таблица будет расширяться. По умолчанию это значение равно 0.75, что означает расширение при достижении 75% от ёмкости. Уменьшение коэффициента может ускорить поиск, но приведет к большему потреблению памяти.
Как изменить параметры расширения:
- Для задания начальной ёмкости используйте конструктор HashMap, принимающий два аргумента:
HashMap<K, V> map = new HashMap<>(int initialCapacity, float loadFactor);
где
initialCapacity– начальная ёмкость,loadFactor– коэффициент загрузки. - Пример установки начальной ёмкости и коэффициента загрузки:
HashMap<String, Integer> map = new HashMap<>(100, 0.85f);
В данном примере, расширение произойдёт, когда количество элементов достигнет 85% от ёмкости 100.
Оптимизация параметров:
- Для коллекций с известным количеством элементов задавайте начальную ёмкость, равную или немного превышающую это количество. Это уменьшит количество расширений.
- При работе с большими объемами данных можно уменьшить коэффициент загрузки, чтобы снизить нагрузку на операции поиска и вставки.
- Если вам не важна экономия памяти, увеличьте коэффициент загрузки. Это уменьшит частоту расширений, но потребует больше памяти.
Также стоит помнить, что изменения параметров могут повлиять на производительность, как в положительную, так и в отрицательную сторону. Например, очень высокое значение коэффициента загрузки может привести к большому числу коллизий и замедлению операций.
Как избежать лишних расширений при использовании HashMap
При работе с HashMap важно минимизировать количество расширений, чтобы не потерять производительность из-за частых перераспределений элементов. Основные рекомендации включают правильное управление начальной ёмкостью и коэффициентом загрузки.
1. Выбор оптимальной начальной ёмкости. При создании HashMap важно правильно оценить, сколько элементов будет в коллекции. Каждый элемент в HashMap требует определённого объема памяти, и если начальная ёмкость задана слишком маленькой, будет происходить частое расширение структуры. В то же время слишком большая ёмкость может привести к пустым корзинам и неэффективному использованию памяти. Если заранее известно, что в HashMap будет храниться значительное количество элементов, укажите начальную ёмкость, близкую к предполагаемому объему.
2. Корректная настройка коэффициента загрузки. Коэффициент загрузки (load factor) влияет на частоту расширений. Он определяет, когда HashMap должен увеличивать свою ёмкость. Стандартное значение коэффициента загрузки равно 0.75, что является балансом между использованием памяти и производительностью. Уменьшение коэффициента загрузки (например, до 0.5) уменьшает количество расширений, но может увеличить потребление памяти. Увеличение коэффициента загрузки может снизить расходы на память, но приведет к большему числу расширений и ухудшению производительности.
3. Использование методов с определённой ёмкостью. Когда создаёте новый объект HashMap, всегда задавайте параметры начальной ёмкости и коэффициента загрузки, если это возможно. Например, вместо использования конструктора без параметров используйте конструктор с параметрами: new HashMap<>(initialCapacity, loadFactor), где initialCapacity – это предварительная оценка объёма коллекции, а loadFactor – коэффициент загрузки.
4. Минимизация операций вставки и удаления. Частые вставки и удаления элементов также приводят к увеличению количества расширений. Если нужно часто обновлять коллекцию, рассмотрите возможность использования других структур данных, например, LinkedHashMap или TreeMap, которые могут быть более эффективными в таких случаях.
5. Правильная балансировка производительности и памяти. Если ваша задача – максимальная производительность, то используйте оптимизированную ёмкость и коэффициент загрузки, которые минимизируют расширения. Для приложений с ограниченными ресурсами памяти важно найти компромисс между производительностью и потреблением памяти.
Вопрос-ответ:
Как происходит расширение HashMap в Java?
HashMap в Java использует принцип увеличения размера своего массива при достижении определенной заполняемости. Когда количество элементов в HashMap превышает определенный порог (обычно 75% от текущего размера), происходит расширение: создается новый массив, размер которого в два раза больше, и все элементы перехешируются на новые позиции. Это необходимо для поддержания эффективности поиска и добавления элементов.
Почему HashMap в Java расширяется не сразу, а только после достижения определенной заполняемости?
Расширение HashMap после достижения определенной заполняемости помогает поддерживать баланс между производительностью и использованием памяти. Без этого порога, частое расширение массива могло бы привести к значительным затратам времени и памяти, а с порогом — уменьшается количество перерасходованных ресурсов при увеличении размера.
Какой механизм используется для распределения данных при расширении HashMap?
При расширении HashMap используется механизм хеширования, где каждый элемент перераспределяется по новому массиву в зависимости от его хеш-кода. При этом изменяется не только размер массива, но и емкость корзин, в которых хранятся элементы, чтобы обеспечить эффективный доступ к данным.
Когда стоит ожидать расширение HashMap? Какие факторы влияют на этот процесс?
Расширение HashMap происходит, когда количество записей превышает порог загрузки, который по умолчанию равен 75%. Например, если начальная емкость HashMap составляет 16, расширение произойдет, когда количество элементов превысит 12. Основными факторами являются начальная емкость и коэффициент загрузки.
Как можно контролировать процесс расширения HashMap в Java?
Процесс расширения можно контролировать через два параметра: начальную емкость и коэффициент загрузки. При создании HashMap можно указать эти значения, что позволит вам настроить, как быстро и при каком количестве элементов будет происходить расширение. Например, можно установить коэффициент загрузки меньше 75%, чтобы расширение происходило при меньшем числе элементов.
Как происходит расширение HashMap в Java, когда количество элементов достигает предела?
В HashMap в Java расширение происходит автоматически, когда количество элементов в мапе превышает определённый порог, называемый *threshold* (порогом расширения). Обычно это происходит, когда размер текущей ёмкости HashMap (например, 16) заполняется более чем на 75%. В результате происходит увеличение ёмкости и перераспределение всех элементов по новым корзинам. Новый размер обычно в два раза больше предыдущего. Это необходимо для поддержания производительности, так как с увеличением ёмкости уменьшается вероятность коллизий, а значит, время поиска элементов остаётся стабильным.