В условиях постоянных изменений на рынке, использование данных для принятия обоснованных решений стало ключевым элементом успешной стратегии компании. Согласно исследованию McKinsey, компании, активно применяющие аналитику данных, на 23% более прибыльны и в два раза быстрее увеличивают свою рыночную долю. Эффективное использование данных позволяет снизить риски, улучшить прогнозирование и повысить операционную эффективность.
Важно понимать, что обработка и анализ данных не ограничиваются только сбором статистики. Чтобы извлечь реальную ценность, необходимо внедрять современные методы аналитики, такие как машинное обучение и искусственный интеллект. Использование таких технологий позволяет ускорить обработку данных, выявлять скрытые закономерности и делать более точные прогнозы для бизнеса. Примером может служить компания Amazon, которая использует аналитику для персонализации предложений и повышения уровня удовлетворенности клиентов.
Однако важно помнить, что недостаток данных не менее опасен, чем их избыток. Ключевым моментом является баланс – необходимо не только собирать данные, но и уметь эффективно их фильтровать и интерпретировать. Установление четкой цели анализа и выбор правильных инструментов помогут избежать перегрузки информацией и сделать данные действительно полезными для принятия решений.
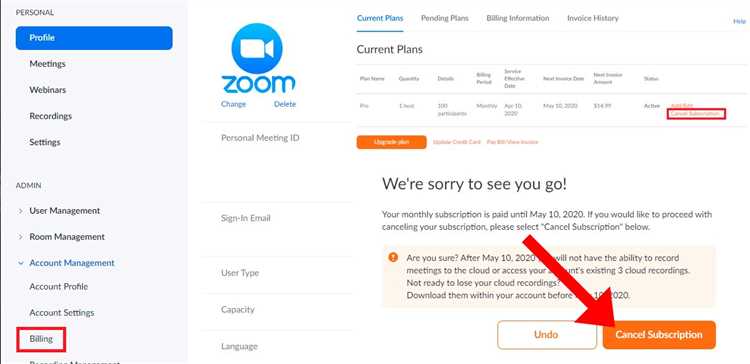
Детальный план информационной статьи

1. Выбор темы и формулировка цели статьи
Первым шагом является четкое определение темы и цели статьи. Необходимо понять, какую информацию вы хотите донести и какой вопрос решить для читателя. Это поможет избежать излишней воды и сконцентрироваться на сути.
2. Составление структуры статьи
Каждая информационная статья должна быть логически структурирована. Основные разделы, которые могут присутствовать в статье:
- Введение – краткое введение в тему, представление основного вопроса.
- Основная часть – делится на несколько подразделов, раскрывающих ключевые моменты.
3. Проведение исследования
4. Разработка содержания каждого раздела
Основная часть статьи делится на несколько подразделов. Важно в каждом из них:
- Объяснить ключевое понятие или термин.
- Привести примеры, иллюстрирующие теорию.
- Подробно разобрать основные аспекты проблемы или темы, избегая ненужных деталей.
5. Написание вступления и заключения
6. Редактирование и корректировка
После написания текста важно несколько раз перечитать статью. Обратите внимание на логику изложения, отсутствие грамматических и стилистических ошибок. Проверьте, соответствует ли материал заявленной теме и цели.
Как выбрать подходящий инструмент для анализа данных
Выбор инструмента для анализа данных зависит от множества факторов: объем данных, цели анализа, бюджет и опыт команды. Основные критерии выбора инструмента для анализа данных включают в себя следующие аспекты:
- Тип данных. Важно учитывать, с каким типом данных предстоит работать. Для структурированных данных идеально подойдут инструменты вроде SQL, для работы с неструктурированными данными – текстовыми или мультимедийными файлами – лучше использовать более специализированные инструменты, такие как Hadoop или Apache Spark.
- Масштабируемость. Если объем данных будет быстро расти, стоит выбрать инструмент, который позволяет эффективно работать с большими объемами информации. Рассмотрите возможности распределенных систем, таких как Apache Hadoop или Apache Spark, которые обеспечивают масштабируемость на уровне хранения и обработки данных.
- Интерфейс. Для работы с данными, особенно если у вас нет команды специалистов, важно учитывать удобство интерфейса. Инструменты с графическими интерфейсами (например, Power BI или Tableau) значительно упрощают создание визуализаций и отчетов. Если требуется глубокий анализ, стоит обратить внимание на Python или R, которые дают больше гибкости, но требуют программных навыков.
- Поддержка машинного обучения. Если в задачи входит построение моделей машинного обучения, стоит выбрать инструмент, который интегрирует библиотеки для этой задачи, такие как Python с библиотеками TensorFlow или PyTorch. Рекомендуется также использовать Jupyter Notebook для прототипирования моделей.
- Бюджет. Стоимость решения также имеет значение. Бесплатные или открытые инструменты, такие как R, Python и их библиотеки, могут стать хорошей альтернативой дорогим коммерческим продуктам. Однако для бизнеса, где требуется поддержка и дополнительные функции, стоит рассмотреть лицензированные решения, такие как SAS, IBM SPSS или Tableau.
При выборе инструмента для анализа данных важно понимать, что один инструмент не может быть идеальным для всех типов анализа. Комбинирование различных решений, таких как использование Python для предварительной обработки данных и Tableau для визуализации, может быть оптимальным вариантом для большинства задач.
Основные этапы подготовки данных для анализа
1. Сбор данных
На этом этапе важно определить источники данных: внутренние (например, базы данных компании) или внешние (например, открытые данные из Интернета). Необходимо удостовериться в доступности и актуальности данных, а также в правомерности их использования с точки зрения законодательства.
2. Очистка данных
Очистка – это процесс устранения из данных шума и ошибок, таких как дубли, пропуски, аномалии и некорректные значения. Используются различные методы, включая:
- Удаление дублирующихся записей;
- Заполнение пропусков средним значением или медианой;
- Исправление ошибок в данных (например, преобразование форматов дат);
- Удаление аномальных значений с использованием статистических методов (например, межквартильное расстояние).
3. Преобразование данных
Этот этап включает приведение данных к единому формату. Например, числовые данные могут быть нормализованы или стандартизированы, а категориальные данные – преобразованы в числовые с использованием методов, таких как one-hot encoding или label encoding. Также на этом этапе могут быть созданы новые признаки (фичи) путем комбинации существующих данных.
4. Разделение данных на обучающую и тестовую выборки
Для оценки модели необходимо разделить данные на обучающую и тестовую выборки. Обычно для обучения используется 70–80% всех данных, а оставшиеся 20–30% – для тестирования. Это позволяет проверить, насколько модель обобщает информацию на новых данных.
5. Анализ данных и выбор модели
На этом этапе проводится исследовательский анализ данных (EDA), чтобы понять их распределение, выявить закономерности и построить предварительные гипотезы. Важно провести визуализацию данных, используя графики и диаграммы, чтобы наглядно увидеть зависимостями между переменными. Также важно выбрать подходящий алгоритм машинного обучения или статистический метод для дальнейшего анализа.
Какие алгоритмы машинного обучения использовать для прогнозирования
Для прогнозирования в машинном обучении используются различные алгоритмы, каждый из которых имеет свои сильные и слабые стороны. Выбор метода зависит от типа данных и задачи. Рассмотрим основные алгоритмы, которые показывают хорошие результаты в задаче прогнозирования.
1. Линейная регрессия
Линейная регрессия – это базовый и интуитивно понятный метод, который применяется, когда есть зависимость между одной или несколькими независимыми переменными и целевой переменной. Алгоритм прост в реализации и интерпретации.
- Подходит для задач с непрерывной целевой переменной.
- Используется, если зависимость между признаками и целевой переменной линейна.
- Может страдать от переобучения при наличии мультиколлинеарности.
2. Деревья решений
Деревья решений являются мощным инструментом для решения задач прогнозирования, как регрессионных, так и классификационных. Алгоритм делит данные на основе значений признаков, создавая дерево с узлами и ветвями.
- Удобно использовать для задачи прогнозирования категориальных и непрерывных значений.
- Требует регуляризации, чтобы избежать переобучения.
- Преимущество – визуализация модели и интерпретируемость.
3. Случайный лес (Random Forest)
Алгоритм случайного леса – это ансамблевая модель, использующая несколько деревьев решений для создания более точных прогнозов. Он эффективно снижает ошибку за счет усреднения предсказаний отдельных деревьев.
- Устойчив к переобучению и плохо чувствителен к шуму в данных.
- Может работать с высокоразмерными данными и имеет отличные результаты при работе с малым количеством признаков.
- Модели можно обучать параллельно, что ускоряет процесс на больших данных.
4. Метод опорных векторов (SVM)
Метод опорных векторов используется для классификации и регрессии, эффективно разделяя данные с помощью гиперплоскости. SVM часто используется для задач с высокоразмерными данными, где другие методы могут терять точность.
- Подходит для сложных и нелинейных зависимостей между признаками.
- Требует правильной настройки гиперпараметров для хорошей производительности.
- Может страдать от больших вычислительных затрат на больших объемах данных.
5. Градиентный бустинг (Gradient Boosting)
Градиентный бустинг – это еще одна ансамблевая техника, где каждый новый классификатор строится с учетом ошибок предыдущего. Этот метод показывает высокую точность и стабильность, особенно для задач регрессии и классификации.
- Лучший выбор для задач, где важна высокая точность.
- Рекомендуется для работы с данными, содержащими большое количество признаков.
- Может быть чувствителен к переобучению при несоответствующих гиперпараметрах.
6. Нейронные сети
Нейронные сети хорошо подходят для сложных задач прогнозирования, таких как обработка изображений, текста или временных рядов. Они могут моделировать сложные и нелинейные зависимости, что делает их универсальным инструментом в прогнозировании.
- Могут быть использованы для задач с большими и многомерными данными.
- Требуют большого объема данных для обучения и могут быть вычислительно дорогими.
- Глубокие нейронные сети подходят для задач с очень сложными зависимостями.
7. K-ближайших соседей (K-NN)
Алгоритм K-NN является одним из самых простых методов для прогнозирования. Он основывается на сходстве данных, где прогнозируемое значение определяется на основе ближайших соседей в пространстве признаков.
- Подходит для задач классификации и регрессии.
- Прост в реализации, но может быть медленным на больших данных.
- Не требует явного обучения модели, что упрощает процесс.
Выбор алгоритма зависит от многих факторов: объема данных, сложности зависимости между признаками, времени на обучение модели и точности, которой требуется достичь. Рекомендуется тестировать несколько алгоритмов на реальных данных, чтобы выбрать наиболее подходящий метод для конкретной задачи.
Как интерпретировать результаты статистического анализа
Первое, что нужно учитывать при интерпретации p-значения – это уровень значимости (α). Обычно α устанавливается на уровне 0.05. Если p-значение меньше α, гипотеза отвергается, то есть существует статистически значимая разница или эффект. Если p-значение больше α, гипотеза не отвергается, и можно заключить, что данных недостаточно для подтверждения гипотезы. Однако важным моментом является не только само p-значение, но и его контекст. Например, при большом объеме выборки даже малые различия могут быть статистически значимыми, но с незначимым практическим эффектом.
Доверительные интервалы (CI) – это диапазоны значений, в которые, с определенной вероятностью, попадает истинное значение параметра в генеральной совокупности. Например, если 95%-й доверительный интервал для среднего значения равен от 10 до 20, это означает, что с вероятностью 95% истинное среднее значение находится в этом диапазоне. Узкий доверительный интервал свидетельствует о высокой точности оценки, а широкий – о неопределенности. Важно помнить, что доверительный интервал не является гарантией, а лишь выражает степень уверенности в результатах анализа.
Коэффициенты регрессии указывают на силу и направление связи между независимыми и зависимыми переменными. Для количественных переменных коэффициенты представляют собой изменение зависимой переменной при изменении независимой на единицу. Например, если коэффициент для переменной «возраст» равен 0.5, это означает, что при увеличении возраста на 1 год зависимая переменная увеличится на 0.5 единицы. Статистическая значимость этих коэффициентов оценивается через p-значение и доверительные интервалы. Если коэффициент значим, это указывает на наличие влияния этой переменной на результат.
Еще один важный момент – проверка предположений модели. Если данные не удовлетворяют базовым предположениям, таким как нормальность распределения или линейность, результаты могут быть искажены. В таких случаях необходимо либо трансформировать данные, либо выбрать другие статистические методы, которые подходят для нарушенных предположений.
Для полноты картины рекомендуется также учитывать эффект размера. Даже если p-значение статистически значимо, это не обязательно означает, что результат имеет существенное практическое значение. В некоторых случаях малый эффект может быть важным с точки зрения научной теории, но в других – он может быть незначительным.
Как автоматизировать процесс сбора и обработки данных
Автоматизация сбора и обработки данных позволяет значительно ускорить процесс получения информации, уменьшить количество ошибок и повысить точность анализа. Чтобы эффективно внедрить автоматизацию, важно учитывать несколько ключевых этапов и инструментов.
Основные шаги для автоматизации процесса:
- Выбор источников данных. Начать нужно с анализа источников данных. В зависимости от специфики бизнеса это могут быть внутренние базы данных, API внешних сервисов, веб-страницы или устройства IoT. Важно понимать, какие источники наиболее релевантны для вашего проекта.
- Инструменты для сбора данных. Для автоматического сбора данных можно использовать скрипты на Python с библиотеками вроде requests для работы с API или BeautifulSoup для парсинга веб-страниц. Также существуют специализированные решения, например, Apache NiFi, которые позволяют настраивать потоки данных без необходимости программирования.
- Очистка данных. Для корректной обработки данных важно обеспечить их предварительную очистку. Это включает в себя удаление дубликатов, заполнение пропусков и стандартизацию форматов. Использование библиотек Python, таких как pandas и numpy, значительно упрощает этот процесс.
- Обработка и анализ данных. Для аналитической обработки данных можно использовать платформы вроде Apache Spark или инструменты машинного обучения, такие как TensorFlow и scikit-learn. Эти инструменты позволяют обрабатывать большие объемы данных и извлекать из них полезную информацию.
- Автоматизация отчетности. После обработки данных следует настроить автоматическое формирование отчетов. Это можно реализовать с помощью таких инструментов, как Google Data Studio или Power BI, которые интегрируются с базами данных и могут автоматически генерировать отчеты по заданным шаблонам.
Дополнительно, важно настроить систему мониторинга и уведомлений, чтобы оперативно получать информацию о сбоях в процессе сбора и обработки данных. Использование таких сервисов, как Prometheus или Grafana, поможет отслеживать работоспособность системы в реальном времени.
Применение этих методов и инструментов позволяет значительно ускорить процесс работы с данными, повысить его точность и сделать его более масштабируемым.
Какие методы визуализации данных наиболее информативны
Гистограммы идеально подходят для отображения распределения данных по категориям. Они четко показывают, как часто встречаются значения в различных интервалах. Например, гистограмма возрастных групп в исследовании по потребительским предпочтениям позволит быстро выявить, какие возрастные категории наиболее активны.
Диаграммы рассеяния (scatter plots) незаменимы для анализа взаимосвязи между двумя переменными. В отличие от гистограмм, они позволяют визуализировать корреляцию и выявить тренды, а также выделить выбросы. Этот метод особенно полезен при исследовании зависимостей, таких как влияние температуры на урожайность в сельском хозяйстве.
Линейные графики часто применяются для отображения изменений показателей во времени. Например, для анализа динамики акций или роста посещаемости сайта за определенный период, линейный график позволит наглядно увидеть тренды и цикличность изменений.
Тепловые карты (heatmaps) являются эффективным инструментом для визуализации плотности данных. Они применяются, когда важно показать интенсивность или частоту определенного события в разных областях. Например, использование тепловых карт в маркетинговых исследованиях позволяет увидеть, какие области сайта или магазина наиболее посещаемы пользователями.
Составные диаграммы, такие как диаграммы «пирог» (pie charts), лучше всего использовать для отображения части целого. Однако они теряют свою информативность, когда количество категорий превышает пять-шесть. В таких случаях лучше использовать диаграммы с накоплением или столбчатые графики.
Карты для геопространственных данных, например, карты с плотностью точек или хоровые карты, идеально подходят для анализа географических распределений. Визуализация данных на карте позволяет легко понять, где сосредоточены ключевые показатели, такие как распространение болезней или плотность населения.
Что важно учесть при выборе платформы для анализа данных
Выбор платформы для анализа данных – ключевой этап в реализации аналитических решений. Чтобы не ошибиться, важно учитывать несколько факторов, напрямую влияющих на эффективность работы с данными.
1. Масштабируемость платформы – это один из главных критериев. Важно понимать, насколько система способна адаптироваться к растущим объемам данных. Если данные в вашей организации будут увеличиваться, необходима платформа, которая позволит масштабировать вычислительные ресурсы без значительных потерь в производительности.
2. Интеграция с источниками данных играет значительную роль. Платформа должна поддерживать широкую совместимость с различными источниками данных, такими как базы данных, облачные хранилища, API внешних сервисов. Чем больше вариантов интеграции, тем проще будет включить платформу в существующую инфраструктуру.
3. Поддержка аналитических инструментов зависит от специфики вашей задачи. Некоторые платформы предлагают встраиваемые аналитические функции, такие как линейная регрессия, кластеризация или обработка естественного языка. Для более сложных нужд потребуется наличие поддержки машинного обучения и нейросетей. Важно, чтобы интеграция с такими инструментами была быстрой и удобной.
4. Производительность имеет критическое значение, особенно при работе с большими объемами данных. Платформа должна обеспечивать высокую скорость обработки запросов и минимальную задержку. Это достигается за счет использования технологий параллельных вычислений, эффективных алгоритмов и возможностей для настройки оптимизации работы.
5. Пользовательский интерфейс и удобство работы с ним также важны. Современные платформы предлагают интерфейсы с визуальными инструментами для построения отчетов и графиков. Однако для более глубокого анализа часто требуется наличие командной строки или возможности написания пользовательских скриптов. Важно выбрать платформу, которая подойдет как для опытных аналитиков, так и для пользователей без специальных знаний в области программирования.
6. Стоимость – немаловажный фактор. Платформы могут иметь различные схемы оплаты: лицензия, подписка, модель «плати за использование». Для малых и средних предприятий важно учитывать долгосрочные расходы и возможные скрытые платежи, такие как стоимость дополнительных вычислительных мощностей или премиум-функций.
7. Безопасность – обеспечение конфиденциальности и защиты данных. Платформа должна соответствовать стандартам безопасности, таким как шифрование данных, защита от утечек и контроль доступа. Особенно это актуально для организаций, работающих с чувствительной информацией, как в области здравоохранения или финансов.
8. Поддержка и сообщество также играют важную роль. Активное сообщество и наличие поддержки от разработчиков помогают оперативно решать возникающие проблемы. Платформа с развитым сообществом пользователей и готовыми решениями для часто возникающих задач позволит быстрее внедрить ее в рабочие процессы.
Как оценить качество и достоверность данных
Оценка качества данных начинается с проверки их источников. Важно убедиться, что данные поступают от авторитетных и проверенных источников. Например, если данные о медицинских исследованиях взяты из рецензируемых журналов, вероятность их достоверности значительно выше, чем в случае информации с сомнительных сайтов. Также полезно проверять дату получения данных – актуальность информации играет ключевую роль.
Качество данных можно оценить с помощью нескольких ключевых характеристик: точность, полнота, согласованность и актуальность. Точность означает, насколько данные соответствуют реальности. Для проверки точности можно использовать сопоставление с другими источниками. Полнота данных отражает, насколько информация охватывает все необходимые аспекты, без значительных пропусков. Если в наборе данных отсутствуют важные элементы, это может существенно снизить его ценность.
Согласованность проверяется путем анализа логики и структуры данных. Если данные собраны из разных источников, важно, чтобы они не противоречили друг другу. Актуальность данных означает, что информация не устарела и применима к текущей ситуации. Например, старые данные о тенденциях в IT-отрасли могут быть мало полезными в быстро меняющемся мире технологий.
Важным аспектом является также методология сбора данных. Данные, собранные с использованием научных методов и статистических инструментов, имеют большую ценность по сравнению с данными, собранными случайным или неподтвержденным образом. Чтобы повысить достоверность данных, стоит опираться на проверенные и стандартизированные методы сбора и обработки информации.
Для оценки достоверности данных важно учитывать возможные ошибки, такие как смещение выборки или искажение информации в процессе обработки. Это можно минимизировать, используя методики случайной выборки и проверку данных на наличие аномалий и выбросов.
Вопрос-ответ:
Какие ключевые факторы влияют на успех в бизнесе?
Основные факторы успеха в бизнесе включают стратегическое планирование, эффективное управление временем, налаживание хороших отношений с клиентами и партнерами, а также способность быстро адаптироваться к изменениям на рынке. Важно постоянно следить за потребностями аудитории и вовремя реагировать на вызовы, чтобы не отставать от конкурентов.
Каковы основные ошибки, которые совершают начинающие предприниматели?
Одной из распространенных ошибок является недостаточная подготовка и анализ рынка перед запуском бизнеса. Также многие начинающие предприниматели недооценяют важность управления финансами и рисками, что может привести к финансовым проблемам в будущем. Часто они также слишком сильно полагаются на интуицию, игнорируя данные и факты.
Что нужно учитывать при выборе стратегии для своего бизнеса?
При выборе стратегии важно учитывать несколько факторов: специфики продукта или услуги, целевую аудиторию, конкурентную среду и доступные ресурсы. Кроме того, нужно учитывать текущие экономические условия и потенциальные риски. Стратегия должна быть гибкой, чтобы в случае изменений на рынке можно было оперативно ее скорректировать.
Какие методы управления рисками подходят для малого бизнеса?
Для малого бизнеса можно использовать несколько методов управления рисками. Например, диверсификация — это распределение рисков между различными проектами или направлениями. Еще один метод — страхование, которое может покрывать риски, связанные с утратой имущества или финансовыми потерями. Важно также иметь четкий план действий на случай непредвиденных обстоятельств.
Как повысить продуктивность команды?
Для повышения продуктивности команды необходимо создать ясные цели и задачи, а также обеспечить прозрачное общение. Важно, чтобы каждый сотрудник понимал свою роль в общем процессе и чувствовал свою значимость. Также полезно проводить регулярные тренинги и поддерживать мотивированную атмосферу. Не стоит забывать о правильной организации рабочего процесса и оптимизации рабочих процессов.
Что влияет на развитие технологий в современной экономике?
Развитие технологий в современной экономике зависит от множества факторов, среди которых важнейшими являются инвестиции в научные исследования, развитие образования, а также поддержка стартапов и инновационных проектов. Одним из ключевых факторов является сотрудничество между государственным и частным секторами, что способствует быстрому внедрению новых технологий в различные отрасли. Влияние оказывают также глобальные тенденции, такие как повышение устойчивости и энергоэффективности, а также потребность в цифровых решениях для бизнеса.
Как новые технологии изменяют повседневную жизнь людей?
Новые технологии значительно изменяют повседневную жизнь, улучшая доступ к информации, упрощая коммуникацию и повышая уровень комфорта. Например, смартфоны и мобильные приложения позволяют людям работать, учиться и отдыхать, не выходя из дома. Также инновации в области медицины и здравоохранения дают возможность для диагностики и лечения заболеваний на более высоком уровне, а технологии умного дома позволяют автоматизировать многие процессы в быту. Это, в свою очередь, сокращает время на рутинные задачи и повышает качество жизни людей.