

Тип str в Python представляет собой неизменяемую последовательность символов. Работа с ним включает множество аспектов, от простых операций, таких как конкатенация строк, до более сложных, как регулярные выражения или кодирование/декодирование данных. Чтобы эффективно использовать str в своих проектах, важно понимать как методы строк могут улучшить производительность и облегчить решение различных задач.
Одной из ключевых особенностей строк в Python является их неизменяемость. Это означает, что любой метод, который кажется изменяющим строку, на самом деле возвращает новую строку. Например, метод replace() заменяет подстроки, но не изменяет саму строку. Важно учитывать это при работе с большими объемами данных, так как частые операции с копированием строк могут повлиять на производительность.
Для оптимальной работы с типом str стоит использовать встроенные методы Python, такие как join(), split(), strip(), которые позволяют эффективно манипулировать строками. Например, использование join() для объединения списка строк предпочтительнее, чем конкатенация через оператор +, поскольку в первом случае создается меньше промежуточных объектов.
Когда требуется обработка строк с учетом регистра, методы lower(), upper(), capitalize() и другие дают возможность гибко управлять форматированием данных. Также стоит обратить внимание на работу с кодировками, например, на использование encode() и decode() для преобразования строк в байтовые представления и обратно, что важно при работе с текстами в разных кодировках.
Как создать строку и использовать её в Python
Создание строки начинается с присваивания значения переменной. Например, строку можно создать так:
text = "Пример строки"Для строк с апострофом внутри, удобнее использовать двойные кавычки:
quote = "It's a nice day"Многострочные строки оформляются с использованием тройных кавычек (''' ''' или """ """). Они полезны для создания длинных текстов или комментариев:
multiline_text = """Это текст,
который занимает несколько строк."""Чтобы создать строку, содержащую специальные символы, такие как новый абзац или табуляцию, используются escape-последовательности. Например, для новой строки (\n) или табуляции (\t>).
escaped_text = "Первая строка\nВторая строка"Работа с длиной строки осуществляется с помощью встроенной функции len(). Она возвращает количество символов в строке:
text_length = len("Пример") # Результат: 6Объединение строк выполняется через оператор +, а повторение – с помощью оператора *. Например:
greeting = "Привет" + " мир"
repeat_text = "Python " * 3 # Результат: 'Python Python Python 'Для сложных манипуляций со строками полезен метод join(), который объединяет элементы списка в строку. Это предпочтительнее, чем использование оператора + для множества элементов:
words = ['Привет', 'мир']
joined_text = " ".join(words) # Результат: 'Привет мир'Получение подстрок в Python осуществляется через срезы (slice). Синтаксис: строка[начало:конец]. Индексация начинается с нуля, а отрицательные индексы отсчитываются с конца строки.
substring = "Пример"[1:4] # Результат: 'рим'Проверка наличия подстроки в строке выполняется с помощью оператора in:
"рим" in "Пример" # Результат: TrueЗамена подстрок в строках делается с помощью метода replace(). Он позволяет заменить все вхождения подстроки на новую:
new_text = "Пример".replace("Пр", "Те") # Результат: 'Теимер'Строки в Python являются неизменяемыми (immutable), что означает, что нельзя изменить содержимое строки напрямую. Однако можно создать новые строки с изменённым содержимым, например, через срезы или методы.
Как манипулировать строками: методы str
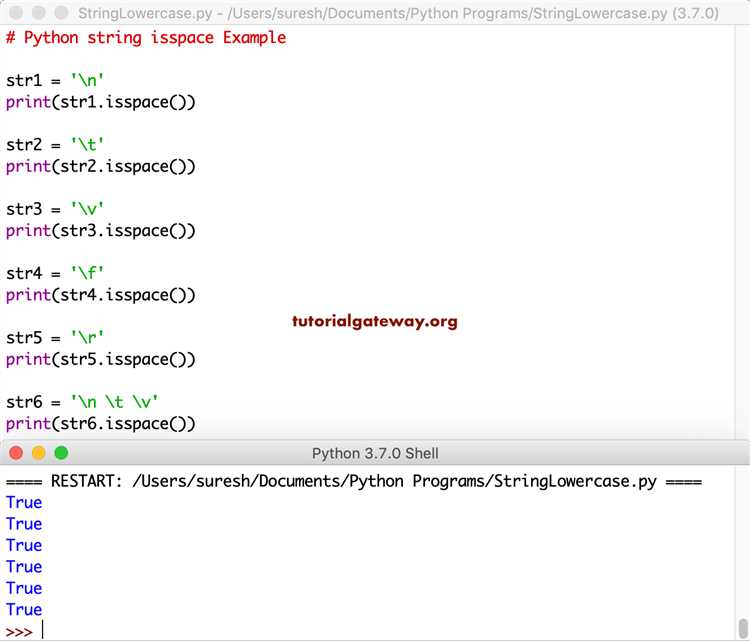
В Python тип str имеет множество встроенных методов для работы с текстовыми данными. Каждый из этих методов позволяет эффективно изменять строку или извлекать из нее полезную информацию. Рассмотрим самые полезные из них.
Метод strip() удаляет пробелы (или другие символы) с начала и конца строки. Это удобно, когда необходимо избавиться от лишних пробелов после ввода данных.
text = " Пример текста "
text = text.strip() # Результат: "Пример текста"
Метод lower() преобразует все символы строки в нижний регистр, что полезно для нормализации данных перед сравнением.
text = "Пример Текста"
text = text.lower() # Результат: "пример текста"
Метод upper() делает все символы строки заглавными. Это часто используется для форматирования или создания акцентов в тексте.
text = "Пример Текста"
text = text.upper() # Результат: "ПРИМЕР ТЕКСТА"
Метод replace() позволяет заменять подстроки на другие строки. Это полезно, когда нужно изменить определенные части текста.
text = "Привет, мир!"
text = text.replace("мир", "Python") # Результат: "Привет, Python!"
Метод split() разделяет строку на список подстрок по заданному разделителю. Часто используется для обработки данных, полученных из разных источников.
text = "apple,orange,banana"
text = text.split(",") # Результат: ['apple', 'orange', 'banana']
Метод join() выполняет обратную операцию – соединяет элементы списка в одну строку, используя указанный разделитель.
words = ['apple', 'orange', 'banana']
text = ", ".join(words) # Результат: "apple, orange, banana"
Метод find() ищет подстроку и возвращает индекс первого ее появления. Если подстрока не найдена, возвращается -1.
text = "Привет, мир!"
index = text.find("мир") # Результат: 8
Метод startswith() проверяет, начинается ли строка с указанной подстроки, и возвращает True, если да, и False, если нет.
text = "Привет, мир!"
result = text.startswith("Привет") # Результат: True
Метод endswith() проверяет, заканчивается ли строка на указанную подстроку.
text = "Привет, мир!"
result = text.endswith("мир!") # Результат: True
Метод count() подсчитывает количество вхождений подстроки в строку.
text = "Привет, мир! Привет, Python!"
count = text.count("Привет") # Результат: 2
Метод zfill() заполняет строку нулями слева до указанной длины. Используется, например, для форматирования чисел в строках.
text = "42"
text = text.zfill(5) # Результат: "00042"
Знание этих методов поможет эффективно манипулировать строками и обрабатывать текстовые данные в Python, делая код компактным и читаемым.
Как работать с индексацией и срезами строк
Индексация строк в Python начинается с нуля. Это означает, что первый символ строки имеет индекс 0, второй – индекс 1 и так далее. Строки также поддерживают отрицательную индексацию, где индекс -1 соответствует последнему символу, -2 – предпоследнему и так далее.
Пример индексации строки:
s = "Привет" print(s[0]) # П print(s[-1]) # т
Срезы (или слайсинг) позволяют извлекать подстроки из строки. Для этого используется следующий синтаксис: s[start:end:step], где start – индекс начала, end – индекс окончания (не включительно), step – шаг, то есть количество символов между извлекаемыми элементами. Если start или end не указаны, Python по умолчанию использует начало или конец строки соответственно.
Пример срезов:
s = "Привет" print(s[1:4]) # рив print(s[:3]) # При print(s[::2]) # Пи
Если шаг отрицательный, срез будет выполняться в обратном направлении. Важно помнить, что срезы не изменяют оригинальную строку, а возвращают новый объект.
Примеры срезов с отрицательным шагом:
s = "Привет" print(s[4:1:-1]) # ве print(s[::-1]) # тевирП
Чтобы избежать ошибок, следует внимательно следить за индексами и границами срезов. Например, если start больше, чем end, срез вернет пустую строку.
Также стоит помнить, что строки в Python неизменяемы (immutable), то есть срез не изменяет оригинальную строку, а создает новый объект. Если нужно изменить строку, можно использовать методы, такие как replace().
Как преобразовывать строку в другие типы данных

В Python преобразование строки в другие типы данных выполняется с помощью встроенных функций. Для преобразования строки в числовые типы (целые числа или числа с плавающей запятой) используется функция int() для целых чисел и float() для чисел с плавающей запятой.
Пример преобразования строки в целое число:
str_number = "123"
number = int(str_number) # результат: 123Для строк, которые не могут быть преобразованы в число, будет выброшено исключение ValueError.
Преобразование в тип float работает аналогично:
str_float = "12.34"
floating_number = float(str_float) # результат: 12.34При работе с датами часто нужно преобразовать строку в тип datetime. Для этого используется модуль datetime и его функция strptime(), которая принимает строку и формат даты. Пример:
from datetime import datetime
date_str = "2025-05-08"
date_obj = datetime.strptime(date_str, "%Y-%m-%d") # результат: 2025-05-08 00:00:00Когда строка представляет собой логическое значение, преобразование осуществляется с помощью функции bool(). Любая непустая строка преобразуется в True, а пустая строка – в False.
str_true = "True"
bool_value = bool(str_true) # результат: TrueДля обработки строковых данных, представляющих сложные структуры, такие как списки или словари, можно использовать функцию eval(), однако она требует осторожности из-за возможности выполнения нежелательного кода. Более безопасной альтернативой является использование json.loads() для строк в формате JSON.
import json
str_json = '{"name": "John", "age": 30}'
data = json.loads(str_json) # результат: {'name': 'John', 'age': 30}При преобразовании строки в типы данных важно помнить о возможных ошибках и корректно обрабатывать исключения, чтобы избежать сбоя программы. Пример использования обработки ошибок:
try:
num = int("abc")
except ValueError:
print("Ошибка преобразования строки в число")Как найти подстроку и использовать регулярные выражения
Для поиска подстроки в строке в Python можно использовать метод in, а также мощные инструменты, предоставляемые модулем re для работы с регулярными выражениями.
Метод in позволяет проверить, содержится ли одна строка в другой:
substring = "пример"
text = "Это просто пример текста"
print(substring in text) # Выведет: True
Однако для более сложных задач, например, для поиска по шаблону, вам понадобится модуль re. Рассмотрим его использование.
Поиск с использованием регулярных выражений

Основная функция для поиска в регулярных выражениях – это re.search(). Она ищет первый найденный шаблон в строке. Если шаблон найден, возвращается объект типа match, в противном случае – None.
import re
pattern = r"\d+" # Шаблон для поиска чисел
text = "В тексте 123 и 4567 числа"
match = re.search(pattern, text)
if match:
print("Найдено:", match.group()) # Выведет: 123
Для поиска всех вхождений можно использовать функцию re.findall(). Она возвращает список всех совпадений:
matches = re.findall(pattern, text)
print(matches) # Выведет: ['123', '4567']
Использование более сложных шаблонов
Регулярные выражения поддерживают различные метасимволы и конструкции:
\d– любая цифра.\w– любой символ, который является буквой или цифрой (или подчеркиванием).\s– пробельный символ (пробел, табуляция, новая строка).[a-z]– символы в диапазоне от a до z (для поиска букв по алфавиту).^– начало строки.$– конец строки.
Пример: поиск всех слов, начинающихся с заглавной буквы:
pattern = r"\b[A-ZА-Я][a-zа-я]*\b"
text = "Сегодня Я вижу Большое количество идей"
matches = re.findall(pattern, text)
print(matches) # Выведет: ['Сегодня', 'Я', 'Большое']
Поиск с использованием флагов
Регулярные выражения поддерживают флаги, которые могут изменять поведение поиска:
re.IGNORECASE– игнорирует регистр символов.re.MULTILINE– позволяет работать с многострочными текстами.re.DOTALL– позволяет точке (.) соответствовать любому символу, включая символ новой строки.
Пример использования флага re.IGNORECASE для поиска без учета регистра:
pattern = r"python"
text = "I love Python"
match = re.search(pattern, text, re.IGNORECASE)
if match:
print("Найдено:", match.group()) # Выведет: Python
Замена текста с использованием регулярных выражений
Функция re.sub() позволяет заменять части строки, которые соответствуют шаблону:
pattern = r"\d+"
replacement = "[число]"
text = "В тексте есть числа 123 и 456."
new_text = re.sub(pattern, replacement, text)
print(new_text) # Выведет: В тексте есть числа [число] и [число].
Советы по использованию регулярных выражений
- Не используйте регулярные выражения для простых задач поиска подстрок, если достаточно метода
in. - Регулярные выражения могут быть мощными, но сложными для понимания. Начинайте с простых шаблонов и постепенно усложняйте их.
- Тестируйте регулярные выражения на различных строках для избегания неожиданных ошибок. Для этого можно использовать онлайн-инструменты, такие как regex101.com.
Как эффективно работать с многозначными строками
При необходимости удаления лишних пробелов в элементах используйте генераторы списков совместно с strip(): [x.strip() for x in s.split(',')]. Это особенно полезно при обработке пользовательского ввода или CSV-данных.
Если нужно провести преобразование типов – например, перевести строковые числа в целые – комбинируйте map() с нужной функцией: list(map(int, s.split(','))).
Для обратного преобразования списка в строку используйте join(): ','.join(map(str, [10, 20, 30])) даст строку '10,20,30'.
Если строка содержит вложенные структуры, например, пары значений через «:», предварительно используйте split() дважды: [pair.split(':') for pair in s.split(',')].
Для обработки строк с переменным числом значений и возможными пустыми элементами применяйте фильтрацию: [x for x in s.split(',') if x] – это устранит пустые подстроки, возникшие из-за двойных разделителей.
Чтобы эффективно анализировать многозначные строки, включающие числовые диапазоны, используйте регулярные выражения из модуля re. Например, re.findall(r'\d+', s) извлечёт все числа, игнорируя символы-разделители.
Избегайте повторной обработки строк в цикле. Выносите логику в отдельные функции и используйте list comprehension или функции высшего порядка для повышения читаемости и производительности.





