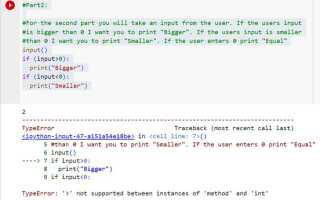
Ошибки в коде Python – неизбежная часть разработки, но умение эффективно их устранять может значительно ускорить процесс программирования. Каждый программист сталкивается с ними, и важной задачей является не только их нахождение, но и корректировка с минимальными затратами времени и усилий. Для этого важно понимать, какие типы ошибок встречаются наиболее часто и как их можно диагностировать.
Первым шагом является использование встроенного механизма исключений. Python предоставляет разнообразные типы ошибок, такие как SyntaxError, IndexError, ValueError и другие. Знание этих исключений и правильная обработка ошибок с помощью try-except блоков позволяет не только предотвратить сбои программы, но и дать разработчику четкие указания о том, где произошла ошибка.
Еще одной важной практикой является использование инструментов для статического анализа кода, таких как pylint или flake8. Эти инструменты помогают находить потенциальные ошибки до того, как код будет запущен, предупреждая о проблемах в структуре кода, несоответствии стандартам и нарушении принципов хорошего кода. Часто такие инструменты могут обнаружить ошибки, которые трудно заметить вручную.
Наконец, хорошей привычкой является написание тестов с использованием фреймворков, таких как unittest или pytest. Тестирование помогает автоматизировать процесс поиска ошибок, устраняя человеческий фактор. Составив тесты для ключевых частей кода, можно своевременно выявлять и устранять ошибки в логике программы, что способствует повышению надежности и стабильности проекта.
Поиск синтаксических ошибок с использованием Python интерпретатора
Python интерпретатор предоставляет несколько эффективных способов для поиска синтаксических ошибок. Эти методы полезны как для начинающих, так и для опытных разработчиков, поскольку позволяют быстро обнаружить и исправить проблемы в коде. Рассмотрим основные подходы.
Первым шагом в поиске синтаксических ошибок является выполнение кода. Когда интерпретатор сталкивается с ошибкой синтаксиса, он сразу сообщает об этом, указав строку и тип ошибки.
Наиболее часто встречающиеся синтаксические ошибки:
- Пропущенные или лишние скобки.
- Неправильное использование отступов.
- Опечатки в ключевых словах или именах переменных.
- Невыполнимые конструкции, такие как случайный символ в коде.
Чтобы выполнить проверку на наличие синтаксических ошибок, достаточно запустить код с помощью интерпретатора. Для этого можно использовать команду:
python -m py_compile имя_файла.py
Также можно использовать режим интерактивного интерпретатора Python (REPL) для выявления ошибок. В режиме интерпретатора ошибки будут отображаться немедленно после ввода строки с ошибкой, что позволяет быстро локализовать и исправить проблему.
В случае работы с большими проектами, когда поиск ошибок вручную может занять много времени, полезно использовать статические анализаторы кода, такие как pylint или flake8. Эти инструменты позволяют заранее выявить потенциальные синтаксические ошибки и предупредить разработчика о возможных проблемах.
Пример использования pylint для проверки файла:
pylint имя_файла.py
Этот инструмент анализирует код и предоставляет подробный отчет с рекомендациями, что позволяет быстрее выявить и устранить синтаксические ошибки.
Также полезно помнить, что в случае синтаксических ошибок важно не только исправить ошибку, но и проверить контекст, в котором она возникла. Иногда ошибка может быть следствием неправильного использования других частей кода или логических проблем.
Как использовать отладчик pdb для пошагового анализа кода
Чтобы начать использовать pdb, достаточно вставить вызов import pdb в нужном месте кода и использовать pdb.set_trace(), чтобы остановить выполнение программы и войти в режим отладки. Например:
import pdb
def example_function(x):
result = x + 10
pdb.set_trace() # Программа остановится здесь
return result
example_function(5)
После выполнения программы выполнение остановится в точке, где был вызван set_trace(). В этот момент можно использовать команды pdb для анализа:
n– шагнуть на следующую строку в текущей функции.s– войти в функцию, если выполнение достигает вызова функции.c– продолжить выполнение до следующей точки останова.q– выйти из отладчика.p– напечатать значение переменной или выражения. Например,p resultнапечатает значение переменнойresult.
l
С помощью команды where можно вывести стек вызовов, что поможет понять, как программа добралась до текущей точки выполнения.
Пример использования отладчика для пошагового анализа:
import pdb
def add(x, y):
result = x + y
pdb.set_trace() # Отладка после выполнения сложения
return result
add(3, 4)
Особенности использования pdb включают возможность работать с большим количеством команд отладки, таких как:
jump– позволяет переместиться в указанную строку кода.break– устанавливает точку останова в указанной строке кода.clear– удаляет точку останова.
Таким образом, pdb является мощным инструментом для анализа и устранения ошибок, позволяя работать с кодом на уровне выполнения и проверять его логику в реальном времени. Использование отладчика pdb помогает не только находить баги, но и улучшать понимание работы программы в целом.
Использование логирования для выявления проблем в коде

Для начала стоит использовать встроенный модуль Python logging, который предоставляет гибкие настройки для логирования. Он позволяет настраивать уровни логирования (например, DEBUG, INFO, WARNING, ERROR, CRITICAL) в зависимости от важности сообщения. Например, уровень DEBUG подходит для записи подробных сведений о ходе выполнения программы, а ERROR – для сообщений о критичных ошибках, которые требуют немедленного внимания.
Лучше всего начать с установки базовой конфигурации для логирования. Простой пример настройки:
import logging
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
file_handler = logging.FileHandler('app.log')
console_handler = logging.StreamHandler()
logging.basicConfig(level=logging.DEBUG, handlers=[file_handler, console_handler])
Каждое сообщение в логе должно быть информативным. Вместо общих фраз, как «Ошибка произошла», следует добавлять контекст. Например, «Ошибка при обработке файла {filename}, ошибка {error_message}». Это поможет быстрее понять суть проблемы и определить путь к решению.
Для эффективного поиска проблем важно не только логировать ошибки, но и другие ключевые события. Например, успешное выполнение важных операций, изменение состояния или выполнение условий. Это помогает отслеживать поведение программы на всех этапах и легче выявлять, на каком этапе возникает сбой.
Не забывайте, что логи должны быть не только информативными, но и безопасными. Не стоит записывать в логи данные, содержащие личную информацию или пароли. Для этого можно использовать фильтрацию данных перед записью в лог.
Как работать с исключениями и обрабатывать их правильно
Основная структура обработки исключений выглядит так:
try: # код, который может вызвать исключение except SomeException as e: # код обработки исключения
Каждое исключение связано с конкретным классом, например, ValueError, IndexError, TypeError. Поэтому важно перехватывать именно те исключения, которые могут возникнуть в определенной части кода, чтобы не пропускать ошибки и не ловить ненужные исключения.
Использование общего except без указания типа исключения – это плохая практика. Такой код может скрывать ошибки и затруднять диагностику проблем. Лучше явно указывать, с каким исключением вы хотите работать:
try:
result = int(input("Введите число: "))
except ValueError as e:
print(f"Ошибка: {e}")
Если необходимо обработать несколько типов исключений, их можно перечислить через запятую:
try:
number = int(input("Введите число: "))
print(10 / number)
except (ValueError, ZeroDivisionError) as e:
print(f"Ошибка: {e}")
Важным элементом является блок else, который выполняется, если исключение не произошло:
try:
result = 10 / 2
except ZeroDivisionError as e:
print(f"Ошибка: {e}")
else:
print("Операция выполнена успешно.")
Также стоит использовать блок finally, который выполняется независимо от того, произошло ли исключение. Это полезно для освобождения ресурсов, таких как файлы или соединения с базой данных:
try:
file = open("file.txt", "r")
except FileNotFoundError as e:
print(f"Файл не найден: {e}")
finally:
if file:
file.close()
Не следует злоупотреблять обработкой исключений. Например, избегайте слишком широких блоков try-except, которые могут скрыть ошибки. Исключения должны использоваться только там, где они логически необходимы, например, при работе с внешними ресурсами или пользовательским вводом.
Для улучшения отладки и диагностики ошибок полезно добавлять в обработку исключений информацию о контексте, например, с помощью функции logging, чтобы сохранять подробные сообщения об ошибках в логах:
import logging
try:
result = 10 / 0
except ZeroDivisionError as e:
logging.error(f"Ошибка деления на ноль: {e}")
Правильная обработка исключений помогает писать более надежные и предсказуемые программы. Главное – не скрывать ошибки, а грамотно их обрабатывать, обеспечивая информативные сообщения и минимизируя возможность некорректного завершения работы программы.
Использование тестирования для предотвращения ошибок в коде
Тестирование – важный инструмент для предотвращения ошибок в коде Python. Использование тестов позволяет не только проверять функциональность программы, но и гарантировать стабильность системы в будущем. Это помогает обнаруживать ошибки на ранних этапах разработки, уменьшая количество дефектов в конечном продукте.
Для начала следует различать два типа тестирования: юнит-тестирование и интеграционное тестирование. Юнит-тесты проверяют отдельные компоненты системы, а интеграционные – взаимодействие этих компонентов между собой. Юнит-тестирование помогает убедиться, что каждая часть кода работает как ожидалось, что предотвращает потенциальные ошибки на уровне отдельных функций или методов.
Основной инструмент для юнит-тестирования в Python – библиотека unittest. Она предоставляет возможности для создания тестов, проверки их выполнения и получения отчетов. Важно создавать тесты для каждой критической функции, особенно тех, которые обрабатывают данные или выполняют важные вычисления. Например, проверка граничных значений, исключений и ошибок в расчетах позволяет исключить большинство типичных проблем на стадии разработки.
Тесты не должны быть разовыми. Регулярное выполнение тестов в рамках CI/CD (непрерывной интеграции и доставки) помогает быстро выявить ошибки при добавлении новых функций или изменении существующего кода. Автоматизация тестов ускоряет процесс разработки и уменьшает вероятность возникновения новых ошибок, связанных с изменениями в коде.
Для сложных проектов важно учитывать и тестирование на нагрузку. Это помогает выявить проблемы, связанные с производительностью, прежде чем они станут критичными для пользователей. Инструменты вроде pytest или nose2 позволяют расширить функционал тестирования и ускорить процесс разработки, поддерживая высокий уровень качества кода.
Также стоит обратить внимание на покрытие кода тестами. Чем больше строк кода покрыты тестами, тем меньше вероятность возникновения неожиданных ошибок. Использование покрытия кода, таких как coverage.py, поможет выявить части программы, которые не тестируются, и дополнить их необходимыми проверками.
Важным аспектом является написание тестов с учетом принципов TDD (разработка через тестирование). Это подход, при котором тесты пишутся до написания кода. Такой подход гарантирует, что каждый компонент системы будет протестирован на всех этапах разработки, что минимизирует риск появления багов в будущем.
В целом, внедрение тестирования в процесс разработки Python-кода позволяет значительно повысить его надежность и упростить процесс поиска и устранения ошибок. Тестирование не только уменьшает количество багов, но и повышает уверенность разработчиков в стабильности своей программы, что в конечном итоге влияет на улучшение качества продукта.
Решение проблем с зависимостями и версиями библиотек

Ошибки, связанные с зависимостями и версиями библиотек, часто становятся причиной нестабильной работы кода. Чтобы эффективно решать эти проблемы, важно контролировать версии используемых пакетов и следить за их совместимостью.
Первым шагом является использование виртуальных окружений. Это позволяет изолировать зависимости для каждого проекта, предотвращая конфликты между различными версиями библиотек. Для создания виртуального окружения в Python используется команда:
python -m venv venvДалее активируйте окружение командой:
source venv/bin/activate (для Linux/Mac)venv\Scripts\activate (для Windows)После активации можно устанавливать необходимые библиотеки через pip, а их версии фиксировать в файле requirements.txt с помощью команды:
pip freeze > requirements.txtЭтот файл затем можно использовать для установки точно таких же версий библиотек в другом окружении командой:
pip install -r requirements.txtЕсли возникает ошибка из-за несовместимости версий, стоит проверить документацию библиотек и определить, какие версии совместимы между собой. Некоторые пакеты могут требовать определённых версий других библиотек. В таких случаях полезно воспользоваться инструментами для разрешения зависимостей, такими как Poetry или pipenv.
Poetry позволяет легко управлять зависимостями и версиями, автоматически обновляя их в соответствии с требованиями проекта. Для установки Poetry используйте команду:
pip install poetryЗатем создайте новый проект:
poetry new my_projectПо мере добавления зависимостей, Poetry будет автоматически управлять их версиями, избегая конфликтов. Кроме того, можно использовать команду:
poetry updateЭто обновит все библиотеки до совместимых версий. Важно также следить за проблемами с версиями Python. Некоторые пакеты могут требовать определённой версии интерпретатора. В таком случае может потребоваться использование pyenv для управления несколькими версиями Python.
Если ошибка сохраняется, несмотря на соблюдение всех рекомендаций, стоит использовать команды для диагностики, такие как:
pip checkЭта команда выявит несоответствия в зависимостях и подскажет, какие пакеты нуждаются в обновлении или удалении. В случае использования старых или малообновляемых библиотек, можно рассмотреть возможность замены их на более современные аналоги, поддерживающие актуальные версии Python.
Вопрос-ответ:
Как найти и исправить ошибку в коде Python?
Для начала стоит внимательно прочитать сообщение об ошибке, которое выводит интерпретатор Python. Оно обычно указывает на строку кода, в которой возникла ошибка, и тип ошибки. Это может быть синтаксическая ошибка, неправильное использование переменных или вызов функций. После этого проверьте код на наличие опечаток, неправильных отступов или неправильных типов данных. Если проблема не очевидна, можно использовать отладчик или вставить в код дополнительные выводы с помощью функции `print()`, чтобы лучше понять, где именно происходит сбой.
Что делать, если ошибка в коде Python не даёт точной информации о причине?
Если ошибка не даёт ясного указания на проблему, попробуйте следующее. Первое — это изолировать код, который вызывает ошибку. Вы можете закомментировать части программы и поочередно их активировать, чтобы увидеть, где именно возникает сбой. Используйте простые примеры данных, чтобы убедиться, что ваша логика работает корректно. Также не забывайте проверять типы данных и их соответствие ожидаемым в каждой функции или операции. Это может помочь найти ошибку, которая не очевидна сразу.
Как исправить ошибку индексации в Python?
Ошибка индексации в Python чаще всего возникает при попытке обратиться к элементу списка или строки с неправильным индексом. Индексы начинаются с 0, и если вы пытаетесь обратиться к элементу за пределами существующих индексов, получите ошибку. Чтобы избежать таких ошибок, проверьте, что индекс находится в пределах допустимых значений. Можно использовать функцию `len()` для проверки размера списка или строки перед попыткой доступа к элементу. Также полезно добавлять условия, проверяющие корректность индекса.
Как решить проблему с неправильным импортом модулей в Python?
Если модуль не импортируется или возникает ошибка, проверьте несколько вещей. Во-первых, убедитесь, что модуль установлен. Для этого используйте команду `pip list` или `pip freeze` в терминале. Если модуль не установлен, установите его командой `pip install <название_модуля>`. Если модуль установлен, но ошибка сохраняется, проверьте путь до файла, чтобы убедиться, что Python может найти модуль. Также стоит обратить внимание на возможные проблемы с версией Python, особенно если модуль не совместим с используемой версией.
Что делать, если программа Python неожиданно выходит с ошибкой «IndexError»?
Ошибка «IndexError» в Python возникает, когда вы пытаетесь обратиться к элементу списка, строки или другого индексируемого объекта с недопустимым индексом. Чтобы устранить эту ошибку, внимательно проверьте, что индекс, который вы используете, не выходит за пределы допустимого диапазона. Например, для списка с 5 элементами индексы могут быть от 0 до 4. Используйте функцию `len()`, чтобы узнать длину объекта перед доступом к его элементу. Также может помочь добавление проверок перед обращением к элементу, чтобы избежать выхода за границы.