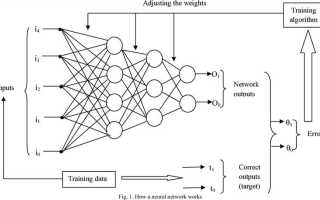
Создание нейросети на Python начинается с понимания базовых принципов машинного обучения и глубокого обучения. В отличие от традиционных программ, нейросети обучаются на данных, что позволяет им адаптироваться и улучшать свои результаты со временем. В этой статье мы рассмотрим пошаговый процесс создания нейросети с использованием Python, без применения сторонних высокоуровневых фреймворков, таких как TensorFlow или PyTorch. Это поможет лучше понять, как работают алгоритмы и как настроить модель для решения конкретных задач.
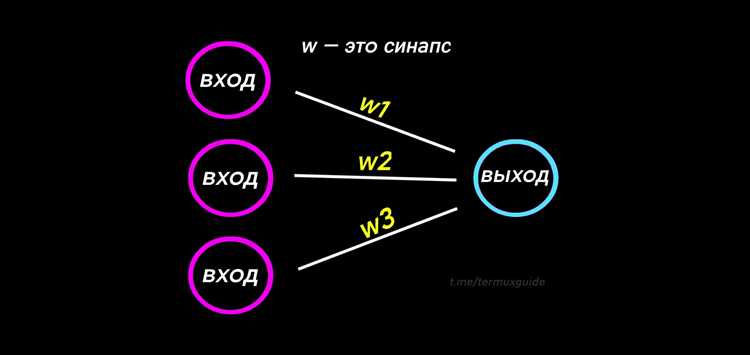
Для начала нам понадобится библиотека NumPy, которая будет основой для математических операций. Именно с помощью этой библиотеки мы будем работать с матрицами, векторными операциями и вычислениями, необходимыми для обучения нейросети. В отличие от готовых решений, такой подход дает полное представление о том, как работают базовые компоненты нейросети: слои, веса, активации и ошибки.
Основной элемент нейросети – это слои нейронов, которые обрабатывают входные данные. Каждый нейрон в слое выполняет вычисления на основе входных значений, умноженных на веса и пропущенных через активационную функцию. Активационная функция нужна для того, чтобы модель могла аппроксимировать любые сложные зависимости. Важно выбрать правильную функцию активации, так как она влияет на скорость обучения и общую эффективность модели.
После того как модель построена, наступает этап обучения. Для этого нужно правильно настроить процесс обратного распространения ошибки, что требует понимания градиентного спуска. Он используется для минимизации функции потерь, что позволяет модели постепенно улучшать свои предсказания. Этот процесс может занять некоторое время, особенно при больших объемах данных, но он критически важен для достижения хороших результатов.
В ходе разработки нейросети необходимо тщательно следить за переобучением и недообучением модели. Оценка качества работы нейросети на тестовых данных позволяет понять, как она будет вести себя при реальных задачах. На этом этапе часто используется метод кросс-валидации для оценки стабильности модели и выбора гиперпараметров.
Выбор библиотеки для создания нейросети
При разработке нейросети на Python выбор библиотеки определяет как скорость разработки, так и производительность модели. На сегодняшний день существует несколько популярных инструментов, каждый из которых подходит для разных задач. Рассмотрим основные из них.
TensorFlow – одна из самых известных библиотек для машинного обучения и нейросетей. Она разработана Google и поддерживает как низкоуровневое, так и высокоуровневое программирование. TensorFlow идеально подходит для создания масштабируемых моделей и работы с большими данными. Однако она может быть избыточной для простых задач и требует больше времени для изучения.
PyTorch от Facebook имеет простоту использования и динамическую вычислительную графику, что делает её удобной для быстрого прототипирования и научных исследований. PyTorch активно используется в академической среде благодаря своей гибкости и возможности отладки на лету. Однако для масштабируемых решений TensorFlow может оказаться предпочтительней.
Keras является высокоуровневым интерфейсом для TensorFlow. Он упрощает создание и обучение нейросетей, обеспечивая удобный API и быструю настройку моделей. Keras идеально подходит для начинающих, так как его синтаксис интуитивно понятен, а возможности расширяются за счет TensorFlow.
MXNet – библиотека с открытым исходным кодом, поддерживающая как глубокое обучение, так и обычное машинное обучение. MXNet отличается хорошей производительностью и поддержкой распределённого обучения. Она популярна в таких компаниях, как Amazon, но требует большего времени на освоение и настройки по сравнению с TensorFlow и PyTorch.
Caffe – оптимизированная для скорости библиотека, подходящая для разработки моделей глубокого обучения в области компьютерного зрения. Caffe менее гибка в сравнении с PyTorch или TensorFlow, но если задача требует высокой производительности в обработке изображений, это может быть хорошим выбором.
JAX – библиотека от Google для численных вычислений, которая сочетает в себе удобство работы с NumPy с возможностями автоматической дифференциации. Она используется в научных задачах и часто применяется для разработки новых архитектур нейросетей. JAX идеально подходит для исследователей, но может быть сложной для новичков.
При выборе библиотеки важно учитывать не только ваши текущие задачи, но и перспективы роста проекта. Для прототипирования и быстрого тестирования моделей идеально подойдут PyTorch и Keras, в то время как для масштабируемых решений и оптимизации производительности TensorFlow и MXNet будут более предпочтительными. Важно помнить, что каждая библиотека имеет свою специфику, и нет универсального решения для всех типов проектов.
Подготовка данных для обучения модели
Подготовка данных – ключевая стадия в создании нейросети. На этом этапе важно учесть несколько факторов, от которых зависит качество обучения модели и её способности обрабатывать реальные данные.
Первым шагом является сбор данных. Необходимо убедиться, что данные репрезентативны и содержат все необходимые признаки. Например, если задача – классификация изображений, важно, чтобы каждый класс был представлен достаточным количеством примеров, избегая чрезмерного перекоса в данных.
Далее следует этап очистки данных. Часто исходные данные содержат шум или пропуски, которые могут существенно повлиять на обучение. Для числовых данных следует использовать методы заполнения пропусков, такие как среднее или медиану, в зависимости от распределения. Для категориальных признаков можно использовать частотное заполнение или более сложные методы, например, с использованием моделей машинного обучения для предсказания пропусков.
Нормализация и стандартизация данных – ещё один важный этап. Для числовых данных рекомендуется привести их к единому масштабу, чтобы избежать доминирования одного признака над другими. Для этого используются методы, такие как Min-Max нормализация или стандартизация с приведением к нулю среднего и единичному стандартному отклонению.
Категориальные признаки должны быть преобразованы в числовые значения с помощью кодирования. Наиболее распространённые методы: one-hot encoding, когда каждый уникальный признак преобразуется в отдельный столбец, и label encoding, где каждому уникальному значению присваивается числовой код. Выбор метода зависит от особенностей задачи и модели.
Данные для обучения необходимо разделить на тренировочную и тестовую выборки. Обычно разделение происходит в пропорции 80% на 20%, но в случае небольших наборов данных можно использовать кросс-валидацию. Разделение важно для того, чтобы избежать переобучения модели на тренировочных данных и оценить её обобщающие способности на новых данных.
Если задача включает работу с текстовыми данными, важным шагом является токенизация – процесс разделения текста на отдельные слова или фразы, которые затем могут быть преобразованы в числовые вектора. Также стоит обратить внимание на удаление стоп-слов и лемматизацию, чтобы минимизировать количество лишней информации в данных.
После выполнения всех этапов подготовки данных, важно провести визуальный и статистический анализ, чтобы убедиться, что данные адекватны и нет явных ошибок. Визуализация данных помогает выявить скрытые зависимости и аномалии, которые могут потребовать дополнительной обработки.
Создание и настройка слоёв нейросети
В нейросети слои играют ключевую роль в обработке и преобразовании данных. Каждый слой выполняет специфическую операцию, обеспечивая преобразование входных данных в выходной результат. Для создания нейросети на Python важно правильно настроить архитектуру слоёв с учётом типа задачи и характеристик данных.
Основные типы слоёв нейросети включают полносвязные (Dense), свёрточные (Convolutional), рекуррентные (Recurrent) и нормализации (BatchNormalization). Каждый тип слоя имеет свои особенности, которые должны быть учтены при проектировании сети.
Для создания полносвязного слоя с помощью библиотеки Keras можно использовать класс Dense. Пример его создания:
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(64, input_dim=100, activation='relu'))Здесь 64 – это количество нейронов в слое, input_dim=100 – размерность входных данных, а activation=’relu’ указывает на использование функции активации ReLU, которая помогает избежать проблемы исчезающего градиента.
Для свёрточных слоёв, которые применяются в задачах компьютерного зрения, используется класс Conv2D. Пример настройки свёрточного слоя:
from keras.layers import Conv2D
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))Здесь 32 – количество фильтров (ядер), а (3, 3) – размер каждого фильтра. Параметр input_shape=(64, 64, 3) указывает на размер входных данных (в данном случае изображение размером 64×64 с 3 цветами канала).
Рекуррентные слои, такие как LSTM или GRU, используются для обработки последовательных данных. Пример создания LSTM слоя:
from keras.layers import LSTM
model.add(LSTM(50, input_shape=(10, 64)))Здесь 50 – количество нейронов в LSTM слое, а input_shape=(10, 64) указывает на размерность входных данных, где 10 – количество временных шагов, а 64 – размерность признаков на каждом шаге.
Нормализация слоёв, например, с помощью BatchNormalization, улучшает обучение модели, ускоряя сходимость и повышая стабильность:
from keras.layers import BatchNormalization
model.add(BatchNormalization())Параметры слоёв, такие как количество нейронов, функция активации и размер фильтра, следует подбирать в зависимости от сложности задачи. Важно учитывать, что увеличение количества слоёв и нейронов не всегда улучшает результат. Модели с большим количеством параметров могут переобучаться на небольших данных.
Таким образом, для каждой задачи важно точно настроить типы слоёв и их параметры, что обеспечит максимальную эффективность нейросети.
Определение функции потерь и оптимизатора
Для задач регрессии часто используется функция MSE (Mean Squared Error), которая вычисляет среднеквадратичное отклонение предсказаний от реальных значений:
MSE = (1/n) * Σ(y_pred - y_true)^2
Для задач классификации используется кросс-энтропия. В бинарной классификации это выглядит так:
Binary Cross-Entropy = - [y * log(y_pred) + (1 - y) * log(1 - y_pred)]
После того как выбрана функция потерь, необходимо подобрать оптимизатор – метод, который будет минимизировать ошибку. В нейросетях для этого часто используют алгоритмы, основанные на градиентном спуске.
Основные типы оптимизаторов:
- SGD (Stochastic Gradient Descent) – классический градиентный спуск, который обновляет параметры модели по одному примеру за раз. Он прост, но может быть медленным и нестабильным.
- Momentum – улучшенная версия SGD, которая использует «импульс» предыдущих шагов для ускорения сходимости и сглаживания колебаний.
- Adam – один из самых популярных оптимизаторов, сочетающий преимущества Momentum и адаптивных методов, таких как RMSprop. Он использует два параметра: моментум и адаптивную скорость обучения.
При использовании Adam оптимизатор адаптирует скорость обучения для каждого параметра в зависимости от величины градиента, что позволяет добиться хороших результатов с меньшими усилиями по настройке.
Рекомендации по выбору оптимизатора:
- Для простых задач можно начать с SGD, но если модель не обучается стабильно или сходит на плато, переходите к Adam.
- Adam подходит для большинства задач и работает без дополнительной настройки гиперпараметров, что делает его удобным выбором.
- Если задача очень сложная или сеть глубокая, попробуйте оптимизаторы с моментумом или другие адаптивные методы.
Важно помнить, что оптимизатор влияет на скорость сходимости, но также важно следить за правильностью выбора функции потерь в зависимости от задачи. Неверный выбор может привести к тому, что обучение не будет прогрессировать, несмотря на усилия по настройке оптимизатора.
Обучение нейросети на выбранных данных

Для эффективного обучения нейросети на выбранных данных необходимо учесть несколько ключевых аспектов, включая подготовку данных, выбор модели и настройку параметров обучения. Каждый из этих шагов существенно влияет на результаты работы нейросети.
1. Подготовка данных: Данные должны быть очищены и отформатированы таким образом, чтобы они соответствовали входу модели. Это включает удаление пропущенных значений, нормализацию признаков и приведение данных к нужному формату (например, массивам numpy или тензорам). Часто используется нормализация, чтобы масштаб признаков был в одном диапазоне, что помогает ускорить обучение и повысить точность модели. В случае изображений, например, можно нормализовать пиксели в диапазон [0, 1], деля значения на 255.
2. Разделение данных: Для того чтобы нейросеть могла обобщать, данные необходимо разделить на тренировочную и тестовую выборки. Рекомендуется использовать примерно 80% данных для тренировки и 20% для тестирования, хотя для более сложных моделей может быть полезным добавить валидационный набор данных.
3. Выбор модели: В зависимости от задачи (классификация, регрессия, сегментация) необходимо выбрать соответствующую архитектуру нейросети. Для задачи классификации хорошо подходят полносвязные сети (MLP), для работы с изображениями – сверточные нейросети (CNN), а для анализа последовательностей – рекуррентные нейросети (RNN).
4. Настройка гиперпараметров: Важными гиперпараметрами являются скорость обучения (learning rate), количество эпох, размер пакета (batch size) и функция активации. Например, для задач классификации часто используется функция активации ReLU в скрытых слоях, а для последнего слоя – softmax для многоклассовой классификации или sigmoid для бинарной.
5. Обучение нейросети: Обучение нейросети включает многократное обновление весов с использованием алгоритма оптимизации, чаще всего это градиентный спуск. Важно контролировать процесс обучения, чтобы избежать переобучения. Это можно сделать с помощью методов регуляризации, таких как Dropout или L2-регуляризация. Для выбора лучшей модели в процессе обучения можно использовать валидационные данные и отслеживать метрики, такие как точность или ошибка.
6. Оценка модели: После завершения обучения модель проверяется на тестовых данных. Рекомендуется использовать метрики, такие как точность, F1-меру или ROC-AUC, в зависимости от типа задачи. Важно не полагаться исключительно на одну метрику, чтобы получить более полное представление о качестве модели.
7. Тонкая настройка: Для достижения лучших результатов можно провести тонкую настройку модели, меняя гиперпараметры или добавляя дополнительные слои. Это может включать использование предварительно обученных моделей, что значительно ускоряет процесс обучения и повышает точность.
После выполнения всех этих шагов нейросеть готова к использованию на реальных данных.
Тестирование модели на новых данных
После обучения нейросети на тренировочных данных необходимо провести тестирование на новых данных, которые не использовались в процессе обучения. Это позволяет проверить, как модель будет работать в реальных условиях, и оценить её способность обобщать знания. Важно, чтобы тестовые данные не пересекались с обучающими, иначе модель будет показывать завышенные результаты из-за переобучения.
Основной метрикой для оценки работы модели является точность предсказания. Однако в зависимости от задачи, могут использоваться и другие метрики, такие как полнота (recall), точность (precision) или F1-мера. Например, если модель решает задачу классификации, важно учитывать, насколько хорошо она различает разные классы на тестовых данных.
Для начала нужно разделить исходные данные на два набора: тренировочный и тестовый. Это можно сделать с помощью библиотеки train_test_split из sklearn.model_selection. Например, для разделения данных в пропорции 80/20:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Здесь X – признаки, а y – целевая переменная. Важно, чтобы данные для тестирования не содержали утечек информации из тренировочного набора, так как это искажает результаты тестирования.
После разделения данных, можно применить модель для предсказания на тестовом наборе. Например, для модели классификации:
y_pred = model.predict(X_test)
Следующим шагом будет оценка производительности модели. Для этого можно использовать несколько метрик:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='weighted') recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted')
Метрика accuracy_score дает общее представление о точности модели, но в задачах с несбалансированными классами она может быть неинформативной. В таких случаях стоит опираться на precision, recall и f1_score.
Если результаты на тестовом наборе данных значительно хуже, чем на обучающем, это может свидетельствовать о переобучении. В таком случае стоит попробовать следующие методы:
- Уменьшить сложность модели (например, уменьшить количество слоев или нейронов в нейросети).
- Использовать регуляризацию, например, L2-регуляризацию или Dropout, чтобы предотвратить переобучение.
- Увеличить количество данных для обучения, используя техники, такие как аугментация данных.
Для визуализации результатов можно построить кривые ошибок, такие как кривую ROC или Precision-Recall. Это даст лучшее представление о том, как модель работает в различных порогах вероятности. Для построения кривой ROC используется метод roc_curve:
from sklearn.metrics import roc_curve fpr, tpr, thresholds = roc_curve(y_test, y_pred)
Построив график, можно оценить, как модель справляется с различными порогами для классификации.
Наконец, важно помнить, что тестирование на новых данных – это не разовый процесс. Модель нужно регулярно проверять на новых тестовых наборах, особенно если она будет работать в условиях изменяющихся данных.
Корректировка гиперпараметров для улучшения результата
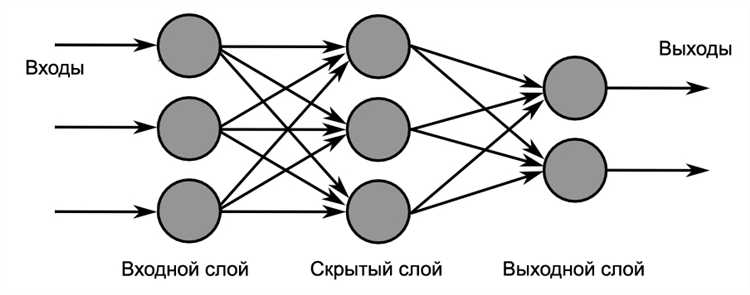
Другим важным гиперпараметром является размер батча (batch size). Малые батчи могут привести к большему шуму в градиентных расчетах, что поможет избежать переобучения, но при этом замедлит процесс обучения. Большие батчи обеспечивают более стабильные оценки градиента, но могут затруднить обобщение модели. Обычно размер батча варьируется от 16 до 128, и его выбор зависит от объема данных и мощности вычислительных ресурсов.
Также стоит обратить внимание на количество слоев и нейронов в каждом слое. Увеличение числа слоев может позволить сети захватывать более сложные зависимости в данных, но при этом возникает риск переобучения. Оптимизация структуры сети может быть выполнена с помощью регуляризационных методов, таких как Dropout, или с помощью методов, ограничивающих количество параметров, например, через архитектуры с сжатием (например, с использованием сверточных слоев в случае изображений).
Методы оптимизации, такие как Adam, RMSprop и SGD, влияют на скорость и качество сходимости. Adam обычно хорошо работает с большим количеством данных, так как адаптивно регулирует скорости обучения для каждого параметра. Однако в некоторых случаях SGD с моментумом может дать более предсказуемые результаты, особенно если настраивать скорость обучения вручную с помощью таких техник, как циклическое изменение или экспоненциальное затухание.
Для улучшения результата важна не только настройка гиперпараметров, но и выбор функций активации. Например, ReLU хорошо работает на большинстве задач, но для задач с обратной связью может понадобиться использование более сложных функций, таких как ELU или Swish, которые помогают избежать проблемы исчезающего градиента и ускоряют сходимость модели.
Каждое изменение гиперпараметров должно быть тщательно протестировано на валидационных данных, чтобы избежать переобучения. Использование кросс-валидации помогает понять, как модель будет вести себя на новых данных, и выбрать оптимальные значения гиперпараметров для дальнейшего использования.
Экспорт модели для использования в реальных приложениях
Экспорт модели нейросети для использования в реальных приложениях требует обеспечения совместимости с различными средами и оптимизации производительности. В зависимости от целевого приложения и требований к производительности можно выбрать различные подходы к экспорту модели.
Для большинства приложений существуют стандартные форматы сохранения и экспорта моделей. Наиболее популярными являются:
- ONNX (Open Neural Network Exchange) – формат, поддерживающий многие фреймворки, такие как PyTorch, TensorFlow, MXNet. Он обеспечивает совместимость моделей между различными библиотеками и ускоряет интеграцию в многослойные системы.
- TensorFlow SavedModel – формат, оптимизированный для использования в TensorFlow. Этот формат сохраняет как модель, так и метаданные, такие как оптимизаторы и графы.
- PyTorch TorchScript – формат для экспорта моделей, обученных в PyTorch. TorchScript позволяет конвертировать модель в формат, который может работать в C++ или других языках, что делает её пригодной для встраивания в приложения.
- Core ML – формат, предназначенный для использования в iOS-приложениях. Он позволяет оптимизировать модели для работы на устройствах Apple, обеспечивая высокую производительность на мобильных устройствах.
После выбора подходящего формата следует выполнить экспорт модели. Рассмотрим пример с использованием библиотеки PyTorch:
- Для конвертации модели в формат TorchScript используется функция
torch.jit.script()илиtorch.jit.trace()для моделей с фиксированной архитектурой. - Пример кода для экспортирования модели в формат TorchScript:
import torch
model = YourModel()
model.load_state_dict(torch.load('model.pth'))
model.eval()
# Экспорт в формат TorchScript
scripted_model = torch.jit.script(model)
scripted_model.save('model_scripted.pt')
Для TensorFlow сохранение модели происходит следующим образом:
import tensorflow as tf
model = YourModel()
# Сохранение в формат SavedModel
model.save('saved_model/')
После экспорта модели важно также учитывать её оптимизацию. Для этого можно использовать различные подходы:
- Quantization – уменьшение точности представления чисел (например, из 32-битного в 8-битное), что ускоряет выполнение и снижает требования к памяти без значительных потерь в точности.
- Pruning – удаление менее значимых весов в модели, что позволяет уменьшить её размер и ускорить выполнение.
- TensorRT – для моделей, экспортированных в TensorFlow или ONNX, можно использовать TensorRT для ускорения инференса на GPU.
В реальных приложениях модели часто интегрируются с backend-частями, где необходима поддержка REST API или gRPC. Для этого можно использовать такие фреймворки, как:
- Flask – для простого создания REST API, через которое модель может получать данные для обработки.
- FastAPI – более производительный фреймворк для создания API с асинхронной обработкой запросов.
- TensorFlow Serving – специализированный сервис для экспорта и обслуживания моделей, созданных с использованием TensorFlow.
Пример создания API для модели с использованием FastAPI:
from fastapi import FastAPI
import torch
app = FastAPI()
model = torch.jit.load('model_scripted.pt')
@app.post("/predict/")
async def predict(data: dict):
input_data = torch.tensor(data["input"])
output = model(input_data)
return {"prediction": output.tolist()}
Для использования модели в мобильных приложениях, например, в iOS, следует конвертировать модель в формат, поддерживаемый Core ML. Это можно сделать с помощью инструмента coremltools:
import coremltools as ct
import tensorflow as tf
model = tf.keras.models.load_model('saved_model/')
coreml_model = ct.convert(model)
coreml_model.save('model.mlmodel')
Для интеграции модели в мобильное приложение необходимо импортировать скомпилированную модель и использовать соответствующие библиотеки для инференса, такие как Core ML для iOS или TensorFlow Lite для Android.
Важно также тестировать производительность модели в реальных условиях, так как на практике могут возникать проблемы с памятью, скоростью обработки или другими параметрами, которые необходимо оптимизировать для конкретных устройств или инфраструктуры.
Вопрос-ответ:
Какие библиотеки нужны для создания нейросети на Python?
Для создания нейросети на Python обычно используют несколько популярных библиотек. Самыми известными являются TensorFlow и Keras, которые позволяют легко строить и обучать нейросети. Также широко используется PyTorch — это мощная библиотека с гибким интерфейсом, которая активно применяется в научных исследованиях. Для работы с данными часто используют Pandas и NumPy, которые позволяют обрабатывать и преобразовывать данные в удобном формате перед подачей в модель. Matplotlib и Seaborn могут быть полезны для визуализации результатов работы нейросети.
Какой алгоритм обучения нейросети лучше выбрать?
Выбор алгоритма обучения зависит от задачи и типа нейросети. Для обычных многослойных нейронных сетей часто используется алгоритм обратного распространения ошибки (Backpropagation) в сочетании с методом градиентного спуска. В PyTorch и TensorFlow можно настроить различные оптимизаторы, такие как Adam, SGD или RMSProp. Adam чаще всего рекомендуют для задач с большими данными, так как он сочетает преимущества методов градиентного спуска и моментума. Выбор алгоритма зависит от сложности задачи, а также от скорости и точности, которых вы хотите достичь при обучении модели.
Как подготовить данные для обучения нейросети?
Подготовка данных является важной частью процесса создания нейросети. Первым шагом всегда идет сбор данных, которые должны быть качественными и разнообразными. Затем данные нужно нормализовать или стандартизировать, чтобы нейросеть могла эффективно обучаться. Это может включать приведение значений признаков к единому диапазону, например, от 0 до 1, или вычитание среднего значения и деление на стандартное отклонение для каждого признака. После этого данные могут быть разделены на обучающую и тестовую выборки. Также важно обработать пропуски в данных и категориальные переменные, преобразовав их в числовой формат с помощью кодирования (например, one-hot encoding).
Что такое переобучение, и как с ним бороться при создании нейросети?
Переобучение (overfitting) — это ситуация, когда нейросеть слишком хорошо запоминает обучающие данные, но плохо обобщает их на новые, ранее не виденные данные. Это приводит к низкой точности модели на тестовой выборке, несмотря на высокие результаты на обучающей. Чтобы избежать переобучения, применяют несколько методов. Одним из них является регуляризация, которая добавляет штраф за слишком большие значения весов нейросети. Также используется метод Dropout, который случайным образом отключает нейроны в процессе обучения, что помогает модели не слишком "запоминать" данные. Разделение данных на обучающую и тестовую выборки также помогает в контроле переобучения, как и использование более простых моделей, если данных недостаточно для обучения сложных сетей.