Работа с капчей на платформе VK является важной задачей для автоматизации различных процессов, таких как сбор данных или тестирование. Несмотря на то, что капча защищает от ботов, она также создает трудности для разработчиков, которым нужно взаимодействовать с сервисом на большом масштабе. В этом контексте, использование Python для обхода капчи становится актуальным решением.
Первоначальный этап заключается в понимании структуры капчи VK. На текущий момент VK использует несколько типов капч, включая текстовую и графическую, каждая из которых требует специфических подходов для обхода. Важным моментом является то, что капча появляется в ответ на подозрительную активность, что связано с запросами, поступающими с одного IP-адреса или аккаунта.
Использование библиотек Python предоставляет разработчикам мощные инструменты для работы с капчей. Одним из популярных решений является библиотека requests для отправки HTTP-запросов и обработки ответа с изображением капчи. Для расшифровки текста с изображений можно использовать Pillow или другие библиотеки для обработки изображений, а для решения капчи на основе текста – популярные API, такие как 2Captcha или AntiCaptcha.
Однако обход капчи VK требует осторожности. Применение автоматических решений может привести к блокировке аккаунта или IP-адреса, поэтому важно соблюдать меры предосторожности: использование прокси, соблюдение темпа запросов и ограничение нагрузки на сервер VK.
Использование библиотеки requests для обхода капчи
Для обхода капчи на сайте ВКонтакте с помощью Python и библиотеки requests необходимо учитывать несколько факторов. Капча на сайте VK защищает от автоматических запросов, и для её обхода требуется правильно взаимодействовать с механизмом HTTP-запросов, обрабатывать изображения и передавать необходимые данные.
Первым шагом является выполнение запроса к странице, на которой отображается капча. В ответе сервера, скорее всего, будет содержаться изображение капчи или её параметры, которые нужно будет распознать. Для работы с запросами используйте метод requests.get, чтобы получить страницу с капчей.
После получения страницы с капчей, необходимо извлечь ссылку на изображение капчи. Это можно сделать через парсинг HTML-ответа с использованием библиотек, таких как BeautifulSoup. Важно, чтобы на этом этапе запросы обрабатывались корректно, включая все необходимые cookies и заголовки, которые могут быть необходимы для успешного взаимодействия с сервером.
Когда ссылка на изображение капчи получена, её нужно скачать. Для этого можно использовать функцию requests.get с передачей URL изображения. После скачивания изображения его необходимо передать в модель для распознавания текста. Для решения капчи можно воспользоваться библиотеками, такими как Pytesseract, которая позволяет распознавать текст с изображений. Важно помнить, что качество распознавания напрямую зависит от качества изображения и сложности капчи.
После распознавания текста капчи, необходимо отправить POST-запрос с полученным ответом на сервер. Это делается через requests.post, в котором отправляются данные формы с ответом на капчу. Важно корректно передать все параметры запроса, включая cookies и session ID, чтобы сервер правильно обработал ответ и допустил дальнейшие действия.
Обратите внимание, что ВКонтакте активно обновляет методы защиты от ботов. В некоторых случаях капча может быть связана с дополнительными проверками, такими как JavaScript-анализ или проверка сессий. Для решения таких капч потребуется более сложное взаимодействие с браузером через selenium или аналогичные инструменты, но при наличии стандартной капчи requests остаётся одним из самых быстрых решений.
Как автоматизировать ввод капчи с помощью распознавания изображений
Процесс начинается с захвата изображения капчи. Для этого используют библиотеки, такие как requests для скачивания изображения или selenium для его захвата прямо с веб-страницы. Далее, полученное изображение можно обработать с помощью библиотеки Pillow, чтобы улучшить качество распознавания. Это может включать конвертацию изображения в чёрно-белое, увеличение контраста и удаление шума.
После обработки изображения применяется pytesseract, который извлекает текст из изображения. Важно учесть, что для некоторых типов капчи, таких как искажения символов или наличие фона с шумом, обычный OCR может не дать точных результатов. В этом случае может потребоваться более сложная обработка изображения или использование нейросетевых решений, например, моделей глубокого обучения, обученных на распознавании таких капч.
Пример кода для распознавания текста с капчи с использованием pytesseract:
from PIL import Image
import pytesseract
# Открытие изображения
img = Image.open("captcha_image.png")
# Преобразование изображения в чёрно-белое
img = img.convert('L')
# Применение OCR
captcha_text = pytesseract.image_to_string(img)
print(captcha_text)
Если капча содержит искажённые символы или фон с шумом, можно попробовать улучшить изображение с помощью дополнительных методов, таких как фильтрация или морфологическая обработка. Библиотека OpenCV предоставляет богатые возможности для работы с изображениями, включая улучшение контрастности, удаление шума и нахождение контуров.
Для более сложных типов капчи, которые требуют решения задач распознавания объектов (например, выбор определённых изображений из набора), можно использовать модели глубокого обучения, такие как TensorFlow или Keras. Эти модели могут быть обучены на распознавание изображений, что значительно улучшает точность при обработке сложных капч.
Тем не менее, важно учитывать, что автоматическое обхождение капч противоречит правилам использования большинства сервисов, таких как VK, и может привести к блокировке аккаунта. Поэтому перед применением подобных методов стоит внимательно изучить правила использования сайта.
Интеграция с сервисами для распознавания капчи в Python

Для автоматизации обхода капчи на платформах, таких как ВКонтакте, можно использовать внешние сервисы для распознавания изображений капчи. Это позволяет ускорить процесс, однако важно учитывать, что не все сервисы одинаково эффективны, и выбор зависит от специфики капчи и задач. Рассмотрим несколько популярных решений для интеграции с Python.
1. 2Captcha
2Captcha – один из самых популярных сервисов для решения капчи. Он поддерживает различные типы капч, включая текстовые, reCAPTCHA и изображения с числами.
- Регистрация на сервисе дает API-ключ для интеграции с Python.
- Для работы с сервисом используется библиотека
requests. - Каждое изображение капчи отправляется на сервер 2Captcha, где оно решается, и решение возвращается обратно в виде текста или токена.
Пример использования 2Captcha:
import requests
API_KEY = 'your_api_key'
CAPTCHA_IMAGE_URL = 'url_to_captcha_image'
def solve_captcha():
# Запрос на отправку капчи
response = requests.post('http://2captcha.com/in.php', data={
'key': API_KEY,
'method': 'post',
'body': open('captcha.jpg', 'rb')
})
captcha_id = response.text.split('|')[1]
# Запрос на получение решения
solution_response = requests.get(f'http://2captcha.com/res.php?key={API_KEY}&action=get&id={captcha_id}')
return solution_response.text.split('|')[1]
2. Anti-Captcha
Anti-Captcha – еще один сервис с возможностью решения большинства типов капч. Он предлагает дополнительные возможности, такие как работа с Google reCAPTCHA v2 и v3, а также с изображениями с объектами, которые нужно распознать.
- Для работы с Anti-Captcha также необходим API-ключ.
- Основной метод – отправка изображения или ссылки на капчу через API для получения решения.
Пример кода для интеграции с Anti-Captcha:
import requests
API_KEY = 'your_api_key'
CAPTCHA_IMAGE_URL = 'url_to_captcha_image'
def solve_captcha():
# Запрос на отправку капчи
response = requests.post('https://api.anti-captcha.com/createTask', json={
'clientKey': API_KEY,
'task': {
'type': 'ImageToTextTask',
'body': CAPTCHA_IMAGE_URL
}
})
task_id = response.json()['taskId']
# Запрос на получение решения
solution_response = requests.post('https://api.anti-captcha.com/getTaskResult', json={
'clientKey': API_KEY,
'taskId': task_id
})
return solution_response.json()['solution']['text']
3. DeathByCaptcha
DeathByCaptcha – сервис, ориентированный на автоматическое решение различных типов капч. Он обеспечивает высокую скорость обработки запросов и поддерживает работу с текстовыми, математическими и графическими капчами.
- Для взаимодействия используется HTTP API с возможностью отправки изображений капчи и получения решений.
- Есть поддержка различных типов капч, включая Google reCAPTCHA и hCaptcha.
Пример использования DeathByCaptcha:
import requests
API_KEY = 'your_api_key'
CAPTCHA_IMAGE_PATH = 'captcha.jpg'
def solve_captcha():
# Загрузка изображения и отправка на сервер
with open(CAPTCHA_IMAGE_PATH, 'rb') as image:
response = requests.post('http://api.deathbycaptcha.com', data={
'username': 'your_username',
'password': 'your_password',
'captchafile': image
})
return response.json()['text']
4. OCR.space
OCR.space – сервис для распознавания текста на изображениях с помощью технологий оптического распознавания символов (OCR). Он также может быть использован для распознавания капчи, если она не содержит сложных графических элементов.
- Для работы с сервисом достаточно получить API-ключ.
- OCR.space эффективно распознает текст на изображениях с простой капчей.
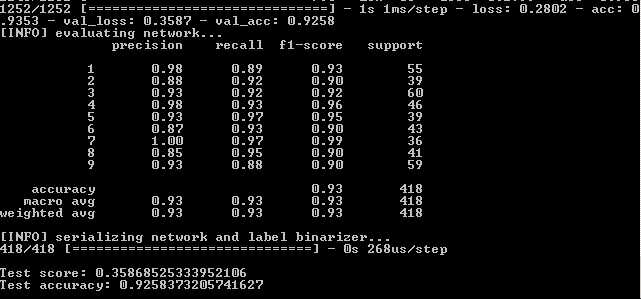
Пример интеграции с OCR.space:
import requests
API_KEY = 'your_api_key'
CAPTCHA_IMAGE_URL = 'url_to_captcha_image'
def solve_captcha():
response = requests.post('https://api.ocr.space/parse/image', data={
'apikey': API_KEY,
'url': CAPTCHA_IMAGE_URL
})
result = response.json()
return result['ParsedResults'][0]['ParsedText']
Использование внешних сервисов позволяет автоматизировать процессы, требующие распознавания капчи. Однако, при разработке таких решений важно учитывать возможные ограничения, например, скорость обработки запросов и их стоимость, а также адаптировать решение под различные типы капчи.
Обработка и анализ сетевых запросов для обхода капчи
Для обхода капчи на платформе VK важно понять, как работает механизм защиты от ботов, и как можно анализировать сетевые запросы, которые используются при взаимодействии с сайтом. Это поможет выявить возможные уязвимости и выстроить корректное решение для автоматизации.
Первым шагом будет анализ трафика, который генерируется при заходе на страницу с капчей. Для этого можно использовать инструменты, такие как Fiddler или Wireshark, чтобы отследить запросы, которые отправляются браузером при попытке загрузить страницу с капчей.
После того как вы зафиксируете необходимые запросы, следует обратить внимание на следующие моменты:
- Запросы к серверу VK, содержащие параметры, связанные с капчей. Обычно они имеют уникальные идентификаторы или токены, которые требуются для успешного взаимодействия с API.
- Заголовки HTTP-запросов. Иногда в них могут быть скрыты дополнительные параметры, такие как временные метки, которые используются для предотвращения автоматических запросов.
- Методы аутентификации. Некоторые капчи могут требовать дополнительных шагов для подтверждения реальности пользователя, например, с использованием cookies или заголовков с сессией.
Для автоматического обхода капчи важно воспроизвести все эти действия в своем Python-скрипте. Это можно сделать с использованием библиотеки requests для отправки HTTP-запросов и обработки ответов сервера.
Пример скрипта для работы с запросами:
import requests
url = 'https://vk.com/captcha'
headers = {
'User-Agent': 'Mozilla/5.0',
'Cookie': 'sessionid=your_session_id',
}
response = requests.get(url, headers=headers)
captcha_data = response.json()
# Дальнейшая обработка ответа для выполнения обхода
При анализе ответов важно учитывать следующие моменты:
- Некоторые капчи могут использовать скрытые параметры, которые не отображаются явно в интерфейсе. Для их получения нужно внимательно изучить все запросы, связанные с загрузкой капчи.
- Ответ сервера может содержать дополнительные ключи или токены, которые необходимо передавать в последующих запросах для выполнения действий, таких как ввод капчи или отправка подтверждения.
- Для обхода капчи можно использовать сторонние сервисы распознавания изображений, такие как 2Captcha, которые предоставляют API для отправки изображений капчи и получения решений.
Понимание логики работы с сетевыми запросами позволяет не только обойти капчу, но и оптимизировать процесс взаимодействия с сайтом, делая его более быстрым и надежным. Ключевым моментом является внимательность при работе с сетевыми запросами и обработка всех этапов взаимодействия с сервером.
Использование прокси для обхода защиты от ботов в VK
Важным аспектом является выбор прокси-серверов. Они могут быть разными: резидентные (из реальных домашних сетей) и дата-центрические (с размещением на серверах). Резидентные прокси имеют меньше шансов быть заблокированными, так как они имитируют поведение реальных пользователей, но стоят дороже. Дата-центрические прокси дешевле, но их использование может быть более рискованным, так как сервисы защиты могут их сразу распознать.
Для работы с прокси в Python можно использовать популярные библиотеки, такие как requests или aiohttp. Важно правильно настроить обработку ошибок и автоматическое переключение между прокси при их блокировке.
Пример использования прокси в запросах с библиотекой requests:
import requests
proxies = {
'http': 'http://your_proxy:port',
'https': 'https://your_proxy:port',
}
response = requests.get('https://vk.com', proxies=proxies)
print(response.text)
Кроме того, стоит учитывать, что VK может использовать дополнительные методы защиты, такие как определение поведения пользователя (например, частота запросов и задержки). Поэтому важно использовать прокси в сочетании с техникой имитации человеческого поведения, например, вставлять случайные задержки между запросами.
Для реализации такой системы можно использовать библиотеки, такие как time и random для генерации случайных интервалов между запросами:
import time import random # Генерация случайных задержек time.sleep(random.uniform(1, 3)) # Задержка от 1 до 3 секунд
Важно регулярно обновлять список прокси и использовать их пул, чтобы уменьшить вероятность их блокировки. Также стоит периодически проверять работоспособность прокси, так как некоторые могут стать неактивными или заблокированными.
Не стоит забывать, что использование прокси для обхода капчи может нарушать условия использования сайта, поэтому перед применением такого подхода рекомендуется внимательно изучить правила платформы.
Ошибки и ограничения при обходе капчи на платформе VK
Другой важной проблемой является использование неподтвержденных или старых токенов. VK активно отслеживает использование API и может заблокировать доступ при подозрении на автоматическое вмешательство. Это также может привести к выдаче капчи даже при минимальной активности на платформе.
Платформа использует алгоритмы, которые постоянно обновляются, что усложняет задачу обхода капчи. Это значит, что методы, которые могут работать на определённый момент, со временем могут стать неэффективными. Поэтому важно отслеживать изменения в API и методах защиты VK для своевременной корректировки подходов к обходу капчи.
Важно учитывать, что использование автоматических инструментов для обхода капчи может нарушать условия использования платформы. VK активно работает над защитой от таких действий и может принять меры по ограничению или блокировке аккаунтов, которые используют подобные методы обхода. Поэтому для минимизации рисков стоит прибегать к методам обхода капчи в рамках допустимого использования API.
К тому же, при применении сторонних сервисов для решения капчи важно понимать, что они могут не всегда быть эффективными из-за уникальности и сложности алгоритмов VK. Некоторые сервисы не могут справиться с динамическими изображениями и интерактивными элементами капчи, что ведет к ошибкам в обработке запросов.
Вопрос-ответ:
Можно ли обойти капчу ВКонтакте с помощью Python?
Да, с помощью Python можно попытаться обойти капчу ВКонтакте, но это не всегда возможно и часто нарушает правила сайта. ВКонтакте использует сложные системы защиты, такие как reCAPTCHA и собственные методы, чтобы предотвратить автоматическое решение капчи. Несмотря на это, существуют библиотеки, такие как `requests` и `selenium`, которые могут помочь имитировать действия пользователя, но решение капчи часто требует использования внешних сервисов или API для распознавания изображений.
Какие библиотеки Python можно использовать для обхода капчи ВКонтакте?
Для обхода капчи ВКонтакте можно использовать несколько библиотек. Например, с помощью `selenium` можно имитировать действия пользователя, автоматически заполняя поля формы. Однако для решения капчи вам понадобятся сторонние сервисы, такие как `2captcha` или `anticaptcha`, которые предоставляют API для автоматического распознавания текста или изображений капчи. Эти сервисы требуют, чтобы вы отправляли изображение капчи на их серверы, а затем они возвращают решение.
Как решить проблему с капчей, используя сервисы для распознавания?
Для решения капчи с помощью сервисов распознавания, таких как `2captcha` или `anticaptcha`, нужно зарегистрироваться на этих платформах и получить API-ключ. После этого, с помощью Python, можно отправить изображение капчи через API запроса и получить решение. Эти сервисы обеспечивают платный доступ к услугам распознавания, и их использование позволяет автоматизировать решение капчи в скриптах. Однако стоит учитывать, что такие подходы могут нарушать правила использования сайта, и капча может быть усилена в ответ на частые попытки обхода.
Что делать, если капча на ВКонтакте не решается автоматически?
Если капча не решается автоматически, можно попробовать несколько вариантов. Один из них — использование других сервисов для распознавания капчи, которые могут иметь более высокую точность. Важно также учитывать, что ВКонтакте периодически обновляет методы защиты, и старые решения могут перестать работать. В таких случаях можно вручную решить капчу или использовать внешнюю службу для распознавания. Также рекомендуется следить за обновлениями библиотек и API, которые могут улучшить взаимодействие с капчей.
Есть ли законные способы обхода капчи ВКонтакте для автоматических задач?
Законных способов обхода капчи ВКонтакте не существует, так как капча предназначена для защиты от ботов и автоматизированных действий. ВКонтакте активно борется с использованием автоматических скриптов, которые нарушают правила использования платформы. Если вам необходимо автоматизировать задачи на ВКонтакте, рекомендуется использовать официальные API и следовать их правилам. Это не только безопаснее, но и позволит избежать возможных блокировок или санкций со стороны сайта.
Как можно обойти капчу ВКонтакте с помощью Python?
Для обхода капчи ВКонтакте с помощью Python можно использовать различные подходы. Одним из них является автоматизация решения капчи через использование сервисов для распознавания изображений, таких как 2Captcha или Anti-Captcha. Чтобы реализовать это, нужно настроить работу с API этих сервисов и передавать им изображение капчи, полученное с сайта ВКонтакте. После того как капча будет решена, результат можно отправить обратно на сервер ВКонтакте для завершения процесса. Также стоит помнить, что использование таких методов может нарушать политику безопасности ВКонтакте, поэтому важно учитывать риски при разработке и применении такого решения.