Правильная обработка ошибок – это не просто способ предотвратить падение программы, но и важный инструмент для создания стабильных и предсказуемых приложений. В Python исключения используются для того, чтобы выделить ошибки, с которыми может столкнуться программа в процессе выполнения. Важно понимать, как и когда их обрабатывать, чтобы избежать ненужных сбоев и минимизировать потенциальные проблемы в будущем.
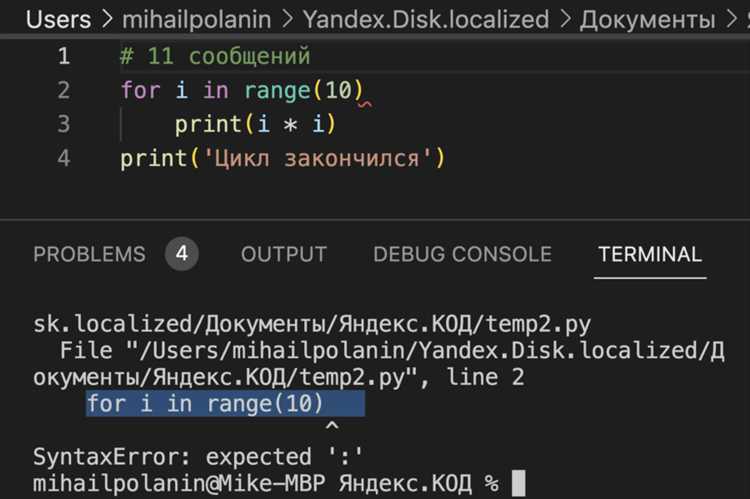
Первое правило – не перехватывать все исключения подряд. Использование общего исключения except Exception нарушает принцип «чистоты» обработки ошибок и может скрыть реальные проблемы в коде. Лучше ориентироваться на конкретные исключения, которые могут возникнуть в определённом участке программы. Например, для работы с файлами разумно использовать FileNotFoundError, а не «поймать» все исключения одним блоком.
Второй момент – обработка ошибок должна быть максимально локализованной. Если ошибка происходит в определённой части кода, лучше всего обработать её именно там, где это возможно. Переносить обработку в основной блок программы (например, в основной цикл) – это риск скрыть важную информацию о том, что именно пошло не так. Важным аспектом является также логирование ошибок. Регулярно фиксируя ошибки, можно быстрее выявить закономерности и улучшить код.
Третье правило – никогда не используйте пустые блоки except. Пропуск ошибок без их обработки или хотя бы логирования может привести к тому, что программист не заметит важных сбоев, которые могли бы повлиять на работу всей программы. Вместо пустого except указывайте конкретные действия, например, логирование ошибки или сообщение пользователю.
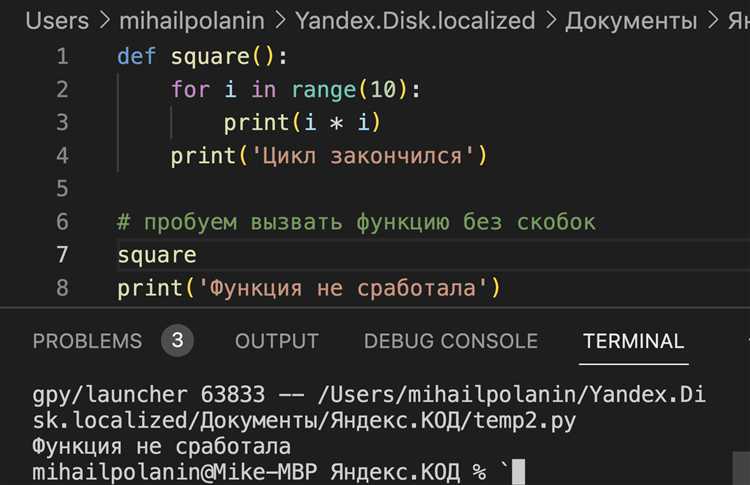
Использование конструкции try-except для перехвата ошибок

Структура использования выглядит следующим образом:
try:
# код, который может вызвать исключение
except ExceptionType as e:
# обработка ошибки
Где:
try– блок, в котором выполняется код, который потенциально может вызвать ошибку.except– блок, где перехватывается исключение и выполняется обработка ошибки.
Пример обработки деления на ноль:
try:
result = 10 / 0
except ZeroDivisionError as e:
print("Ошибка деления на ноль:", e)
Обработка нескольких типов исключений
Можно перехватывать несколько типов ошибок с помощью нескольких блоков except.
try:
x = int(input("Введите число: "))
y = 10 / x
except ValueError:
print("Введено не число.")
except ZeroDivisionError:
print("Нельзя делить на ноль.")
Если в блоке try произойдет ошибка ввода (не число), будет выведено сообщение об ошибке преобразования в целое число. Если введенное значение будет равно нулю, сработает блок except ZeroDivisionError.
Перехват всех исключений
Если необходимо перехватить любые исключения, можно использовать конструкцию без указания типа ошибки:
try:
# код, который может вызвать ошибку
except Exception as e:
print(f"Произошла ошибка: {e}")
Однако, такой подход стоит использовать осторожно, поскольку это затрудняет диагностику конкретных ошибок и может скрыть серьезные проблемы в коде.
Использование блока else
Блок else выполняется, если в блоке try не произошло исключений. Он используется для кода, который должен выполниться только в случае успешного завершения блока try.
try:
x = int(input("Введите число: "))
result = 10 / x
except (ValueError, ZeroDivisionError) as e:
print(f"Ошибка: {e}")
else:
print(f"Результат: {result}")
В случае успешного выполнения кода без ошибок, результат деления будет выведен в блоке else.
Использование блока finally

В данном примере, независимо от того, была ли ошибка при открытии файла, блок finally гарантирует его закрытие.
Типы исключений: как выбрать подходящий для каждой ошибки
В Python существует множество типов исключений, и правильный выбор зависит от конкретной ситуации. Выбор подходящего исключения помогает улучшить читаемость кода и сделать обработку ошибок более точной и эффективной.
Основные категории исключений включают стандартные, связанные с системными ошибками (например, FileNotFoundError), ошибки, связанные с типами данных (например, TypeError), и ошибки, вызванные логическими или пользовательскими ошибками (например, ValueError).
При обработке ошибок всегда выбирайте исключение, которое максимально точно отражает природу проблемы. Например, если программа пытается разделить число на ноль, используйте ZeroDivisionError, а не общее Exception, чтобы отразить конкретную причину сбоя. Это позволяет сразу понять, что за ошибка произошла, и быстрее устранить её в процессе отладки.
Для ошибок, связанных с неверным типом данных, используйте TypeError. Например, если вы пытаетесь добавить строку и число, это именно тот случай, когда следует использовать этот тип исключения. В случае получения неподобающих значений для функции (например, текст вместо числа), более уместно использовать ValueError.
Когда ожидается, что код может столкнуться с ошибками, которые не требуют немедленного вмешательства, можно использовать более общие исключения. Однако такие исключения следует использовать в ограниченных случаях, чтобы избежать перехвата ошибок, которые не должны игнорироваться, например, ошибок в логике программы.
При проектировании программы всегда ставьте цель выбирать тип исключения, который максимально точно описывает возникшую ошибку. Это улучшает читаемость кода и снижает вероятность неправильной обработки ошибок в будущем.
Как работать с несколькими блоками except в одном try
В Python можно использовать несколько блоков except для обработки разных типов ошибок в одном try. Это позволяет более гибко и точно управлять исключениями, а также улучшает читаемость кода. Однако важно соблюдать определенные принципы, чтобы избежать излишней сложности и путаницы.
1. Спецификация типов ошибок
Каждый блок except должен обрабатывать конкретный тип ошибки. Для этого в блоке except указывается тип исключения. Например:
try:
x = 1 / 0
except ZeroDivisionError:
print("Деление на ноль!")
except ValueError:
print("Некорректное значение!") Этот код перехватывает ZeroDivisionError, но не затронет другие исключения, такие как ValueError, которые будут обработаны в другом блоке.
2. Обработка нескольких исключений в одном блоке except
Если вы хотите обработать несколько типов исключений одинаковым образом, можно указать их в скобках через запятую. Это будет полезно, когда действия для разных исключений идентичны.
try:
some_function()
except (TypeError, ValueError) as e:
print(f"Ошибка: {e}")Такой подход упрощает код и позволяет избежать дублирования.
3. Последовательность блоков except
Важно помнить, что блоки except должны следовать от более специфичных типов исключений к более общим. Если блок с более общим исключением (например, Exception) идет раньше, чем специфичные ошибки, то специфичные блоки никогда не будут обработаны.
try:
x = 10 / 0
except Exception:
print("Общая ошибка")
except ZeroDivisionError:
print("Деление на ноль!") # Не будет выполнено4. Обработка исключений с помощью конструкции else
Иногда полезно использовать блок else для выполнения кода, если в try не возникло ошибок. Это позволяет отделить «нормальную» логику от обработки ошибок.
try:
result = some_function()
except ValueError:
print("Некорректное значение")
else:
print("Функция выполнена успешно:", result)Этот способ помогает сделать код более чистым и понятным.
5. Использование блока finally
Если необходимо выполнить код вне зависимости от того, произошла ошибка или нет, используйте блок finally. Это полезно для закрытия ресурсов или выполнения обязательных операций.
try:
file = open("data.txt", "r")
except FileNotFoundError:
print("Файл не найден!")
finally:
file.close() # Этот код будет выполнен всегдаИспользование нескольких блоков except в одном try – это мощный инструмент, который помогает писать более надежный и поддерживаемый код. Главное – не перегружать его лишними условиями и соблюдать порядок обработки исключений.
Обработка исключений с помощью оператора else
Оператор else в блоках try-except используется для выполнения кода, если исключение не было вызвано в блоке try. Этот механизм позволяет обработать сценарий, когда программа выполняется без ошибок, улучшая читаемость кода и структуру обработки различных случаев.
При правильном использовании else код становится более очевидным: блок else гарантирует, что выполняемый код будет выполняться только в случае успешного завершения блока try, без возникновения исключений. Это позволяет разделить логику обработки исключений и обычный рабочий процесс.
Пример использования оператора else:
try:
result = 10 / 2
except ZeroDivisionError:
print("Деление на ноль!")
else:
print("Результат вычислений:", result)
В этом примере, если деление не вызывает исключение, будет выведено сообщение о результате вычислений. Если же возникает ошибка (например, деление на ноль), то блок except обработает ошибку, и код в else не выполнится.
Также стоит отметить, что блок else используется для ситуации, когда требуется выполнить код после успешного завершения блока try, но не для обработки самих исключений. Это важное различие в отличие от блока except, который напрямую связан с перехватом исключений.
Использование else делает код более чистым и упрощает дальнейшую поддержку, так как исключения и обычная логика четко разделяются. Это особенно важно в крупных проектах с множеством обработчиков ошибок, где каждый блок имеет свою конкретную цель.
Не стоит злоупотреблять else в каждом блоке try-except. Если в блоке try могут быть несколько исключений, необходимо внимательно обдумывать, когда следует использовать else, а когда лучше ограничиться только обработкой исключений через except.
Как правильно использовать блок finally для очистки ресурсов
Блок `finally` в Python применяется для гарантированного выполнения кода, который должен быть выполнен независимо от того, возникла ли ошибка в блоках `try` или `except`. Это особенно важно для очистки ресурсов, таких как файлы, соединения с базами данных или сетевые подключения. Правильное использование `finally` помогает избежать утечек ресурсов и обеспечить корректное завершение работы программы.
Когда вы открываете файл с помощью `open()`, используете соединение с базой данных или устанавливаете сетевое соединение, важно всегда закрывать эти ресурсы, чтобы они не оставались открытыми. Если ресурс не будет освобожден, это может привести к снижению производительности или даже к сбоям в системе. Блок `finally` гарантирует, что ресурс будет освобожден, даже если в процессе работы возникнут ошибки.
Пример с использованием `finally` для закрытия файла:
try:
file = open('data.txt', 'r')
# работа с файлом
finally:
file.close()
В этом примере блок `finally` гарантирует, что файл будет закрыт, даже если в процессе работы с ним возникнет ошибка. Без использования `finally` можно было бы столкнуться с ситуацией, когда файл не закрывается, если ошибка произошла до того, как вызвался метод `close()`.
Кроме того, использование блока `finally` полезно для освобождения других ресурсов, таких как сетевые соединения или сеансы работы с базой данных. Например, если вы открыли соединение с базой данных, его нужно закрывать, чтобы избежать утечек памяти и других проблем.
Пример с использованием `finally` для закрытия соединения с базой данных:
try: connection = db.connect() # работа с базой данных finally: connection.close()
В этом случае `finally` обеспечит закрытие соединения даже в случае ошибки в блоке `try`. Это критично для долгосрочных приложений, работающих с ресурсами, которые должны быть освобождены для предотвращения блокировки и других негативных эффектов.
Важно понимать, что блок `finally` выполняется всегда, вне зависимости от того, был ли поймано исключение в блоке `try`. Это делает его идеальным местом для кода очистки ресурсов. Если вы хотите гарантировать, что какой-либо ресурс будет очищен независимо от обстоятельств, используйте `finally`.
Таким образом, блок `finally` является важным инструментом для безопасного управления ресурсами в Python, обеспечивая их своевременную очистку и предотвращая утечки.
Создание собственных исключений в Python
Для создания собственных исключений в Python необходимо унаследовать новый класс от стандартного класса Exception или одного из его подклассов. Это позволяет создать исключение, которое будет специфично для вашей программы или задачи, и поможет эффективно обрабатывать ошибки, которые не покрываются стандартными исключениями.
Пример создания простого исключения:
class MyCustomError(Exception):
pass
В этом примере MyCustomError является пустым классом, унаследованным от Exception. Он не добавляет новой функциональности, но может быть использован для обозначения специфической ошибки в программе.
Можно добавить дополнительные атрибуты и методы, если это необходимо для обработки ошибок. Например, если нужно передать информацию об ошибке, можно определить инициализатор:
class MyCustomError(Exception):
def __init__(self, message, code):
self.message = message
self.code = code
super().__init__(self.message)
Здесь message – текстовое описание ошибки, а code – код ошибки, который может быть полезен для дальнейшей обработки. Важно вызывать super().__init__(self.message), чтобы правильно инициализировать родительский класс Exception.
class MyCustomError(Exception):
def __init__(self, message, code):
self.message = message
self.code = code
super().__init__(self.message)
def __str__(self):
return f"[{self.code}] {self.message}"
Рекомендации по созданию собственных исключений:
- Используйте исключения, когда необходимо четко определить, что произошло нечто, требующее вмешательства, а не просто возврат ошибки.
- Создавайте собственные исключения для специфических ошибок, характерных только для вашего приложения или библиотеки.
- Не злоупотребляйте созданием собственных исключений, если стандартных достаточно для решения задачи. Это может затруднить поддержку кода в будущем.
- При добавлении дополнительных атрибутов в исключение, используйте их только для тех данных, которые действительно помогут при обработке ошибки (например, код ошибки, дополнительные сообщения).
- Переопределение метода
__str__улучшает восприятие ошибок, особенно если ваше исключение содержит важную информацию.
Пример использования:
try:
raise MyCustomError("Что-то пошло не так", 500)
except MyCustomError as e:
print(e)
Таким образом, создание собственных исключений позволяет сделать код более понятным и улучшить диагностику ошибок, что особенно важно в больших и сложных проектах.
Как логировать ошибки и исключения для диагностики
Для начала нужно настроить базовую конфигурацию логирования. Это можно сделать с помощью logging.basicConfig(), где можно указать уровень логирования, формат сообщений и место их сохранения. Например:
import logging
logging.basicConfig(level=logging.ERROR, format='%(asctime)s - %(levelname)s - %(message)s', filename='app.log')
В данном примере ошибки уровня ERROR и выше будут записываться в файл app.log, а формат сообщений будет включать дату, уровень логирования и саму ошибку.
Чтобы логировать исключения, используется метод logging.exception(), который автоматически добавляет стек вызовов в журнал. Это полезно для получения подробной информации о контексте ошибки:
try:
1 / 0
except ZeroDivisionError as e:
logging.exception('Произошла ошибка при делении на ноль')
Метод exception() записывает подробности исключения, включая трассировку стека, что значительно упрощает анализ ошибки. При необходимости можно использовать другие уровни логирования: DEBUG, INFO, WARNING, CRITICAL.
error_handler = logging.FileHandler('errors.log')
error_handler.setLevel(logging.ERROR)
logging.getLogger().addHandler(error_handler)
Также стоит обращать внимание на форматирование логов. Удобно использовать структуру, включающую время, уровень логирования и описание ошибки. Для этого применяются форматтеры:
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
error_handler.setFormatter(formatter)
Важно также учесть безопасность логируемых данных. Не рекомендуется записывать в логи конфиденциальную информацию (например, пароли или личные данные пользователей). Для этого можно использовать фильтры, которые исключают такие данные из сообщений.
Кроме того, стоит настроить ротацию логов, чтобы файлы не занимали слишком много места. Модуль logging.handlers предоставляет удобные инструменты, например, RotatingFileHandler, который автоматически создает новый файл, когда текущий достигает заданного размера:
from logging.handlers import RotatingFileHandler
handler = RotatingFileHandler('app.log', maxBytes=1000000, backupCount=5)
logging.getLogger().addHandler(handler)
Использование ротации помогает поддерживать порядок в логах и ограничивает их объем, что удобно для долгосрочного мониторинга.
Таким образом, правильная настройка логирования в Python – это ключевой аспект для успешной диагностики и устранения ошибок в приложениях. С помощью logging можно не только выявлять проблемы, но и собирать данные для последующего анализа, что позволяет значительно улучшить качество кода и его поддержку в дальнейшем.
Лучшие практики обработки ошибок в многозадачных приложениях
Многозадачные приложения в Python сталкиваются с уникальными проблемами при обработке ошибок, связанных с конкурентным выполнением потоков или процессов. Правильная стратегия обработки ошибок позволяет избежать неожиданных сбоев, улучшить производительность и повысить стабильность системы. Рассмотрим несколько ключевых рекомендаций, которые помогут эффективно обрабатывать ошибки в многозадачных приложениях.
1. Использование отдельной обработки ошибок для каждого потока
Каждый поток должен иметь собственную стратегию обработки ошибок, чтобы сбои в одном потоке не приводили к остановке других. Рекомендуется оборачивать критические участки кода в конструкции try-except, которые изолируют ошибки в пределах потока. Например, ошибки, возникающие в одном потоке, могут быть логированы или переданы в основной поток через очередь (queue), не прерывая работу остальных потоков.
2. Передача исключений между потоками через очереди
Многозадачные приложения должны быть способны передавать ошибки между потоками. Для этого можно использовать модуль queue из стандартной библиотеки Python. Вместо того чтобы ловить ошибки внутри каждого потока, лучше передавать их через очередь в основной поток, где они будут обработаны централизованно. Такой подход позволяет избежать излишней сложности в каждом потоке и сосредоточиться на решении ошибок в одном месте.
3. Использование блокировок (Locks) при обработке ошибок в многозадачных приложениях
При работе с разделяемыми ресурсами важно правильно синхронизировать доступ к ним, чтобы предотвратить возникновение ошибок, связанных с гонками данных. Для этого можно использовать блокировки (Locks) и другие синхронизирующие механизмы, такие как RLock, Semaphore или Event, которые помогут избежать ошибок при параллельном доступе к данным. Каждое исключение, возникающее из-за ошибок синхронизации, должно быть тщательно обработано для предотвращения состояний гонки.
4. Группировка ошибок и их централизованное логирование
Лучшей практикой является централизованное логирование ошибок всех потоков. Для этого используйте стандартный модуль logging, который позволяет собрать все ошибки в одном месте и обеспечить подробные отчёты. Логирование должно включать информацию о контексте выполнения, идентификаторе потока и типе ошибки, чтобы упростить диагностику и устранение причин сбоя.
5. Планирование и повторное выполнение задач с ошибками
В случае сбоя задачи необходимо предусмотреть механизм повторных попыток. Используйте библиотеки, такие как tenacity, которые позволяют настроить повтор выполнения задач с экспоненциальной задержкой или максимальным числом попыток. Это поможет снизить вероятность отказов при временных неполадках, таких как проблемы с сетевым подключением или доступом к базе данных.
6. Гибкость в выборе стратегии обработки ошибок для разных типов задач
Для задач с разными уровнями критичности стоит разрабатывать различные стратегии обработки ошибок. Например, для длительных операций, таких как обработка больших файлов или сетевых запросов, имеет смысл использовать отдельные процессы, а не потоки, чтобы изолировать их от других задач. В случае ошибок можно использовать стратегии восстановления с повтором или отказом с уведомлением пользователя. Для краткосрочных задач обработка ошибок может быть более простой и прямолинейной, с возвратом ошибок в основное приложение.
7. Правильное использование исключений в асинхронных приложениях
В асинхронных приложениях важно правильно обрабатывать ошибки, возникающие в сопрограммах (coroutines). Исключения, возникшие в асинхронных функциях, не могут быть обработаны традиционным способом с использованием try-except. Вместо этого используйте методы, такие как asyncio.create_task, которые позволяют обрабатывать исключения в фоновом режиме, не прерывая выполнение основного потока.
8. Использование систем мониторинга и алертов
Для успешной работы многозадачного приложения необходимо иметь систему мониторинга, которая будет отслеживать ошибки в реальном времени. Модуль psutil и другие инструменты мониторинга позволяют отслеживать использование ресурсов и потенциальные сбои. Важно также настроить алерты, чтобы своевременно реагировать на проблемы, такие как переполнение памяти или длительные операции.
9. Реализация единого интерфейса для обработки ошибок
Для того чтобы облегчить управление ошибками в сложных многозадачных системах, следует реализовать единый интерфейс для обработки ошибок, который будет использоваться всеми потоками и процессами. Это может быть абстракция на основе паттернов проектирования, например, Observer, где каждый поток будет подписан на события и уведомлять систему об ошибках.
Вопрос-ответ:
Что такое обработка ошибок в Python?
Обработка ошибок в Python — это механизм, который позволяет программе реагировать на неожиданные ситуации или сбои, возникающие во время выполнения. Основной инструмент для этого — конструкции try, except, которые помогают «поймать» ошибку и обработать её, не прерывая выполнение программы. Так можно предотвратить её аварийное завершение и предоставить пользователю более понятные сообщения об ошибках.
Когда нужно использовать конструкцию try-except?
Конструкцию try-except следует использовать, когда вы ожидаете, что код может вызвать ошибку, например, при работе с файлами, сетевыми запросами или вводом данных от пользователя. Вместо того чтобы позволить программе аварийно завершиться при ошибке, можно перехватить её и обработать в блоке except. Например, при попытке открыть файл, который не существует, Python сгенерирует ошибку, и тогда можно уведомить пользователя о проблеме или выполнить другое действие.
Что такое блок finally и когда его использовать?
Блок finally в Python используется для выполнения кода, который должен быть выполнен в любом случае, независимо от того, произошла ли ошибка в блоке try или нет. Это удобно для освобождения ресурсов, таких как закрытие файлов или соединений с базами данных. Например, даже если возникнет ошибка при чтении файла, код в блоке finally гарантированно выполнится и файл будет закрыт.