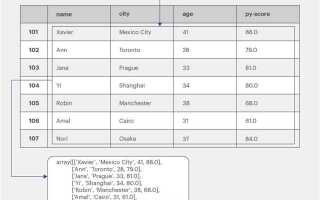
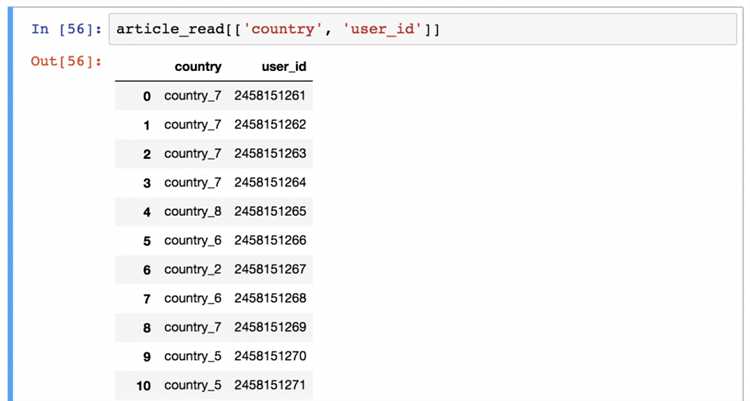
Работа с DataFrame в библиотеке Pandas – это один из основных этапов анализа данных в Python. DataFrame представляет собой двумерную структуру данных, которая идеально подходит для хранения и обработки больших объемов данных. Важно понимать, как эффективно манипулировать столбцами, строками и ячейками DataFrame, чтобы извлекать нужную информацию и проводить её анализ с максимальной производительностью.
Основным способом взаимодействия с данными в DataFrame является использование индексации. Строки и столбцы можно извлекать с помощью индексации по меткам или позициям. Для этого удобно использовать методы loc и iloc, которые позволяют обращаться к данным по названию столбца или по индексу строки. Например, для получения значения в определённой ячейке можно использовать синтаксис df.loc[индекс, столбец] для меток или df.iloc[номер_строки, номер_столбца] для позиционной индексации.
При работе с DataFrame часто возникает необходимость изменять данные или структуру таблицы. Для добавления или удаления столбцов и строк можно использовать методы insert(), drop() или прямую индексацию. Например, чтобы удалить столбец, можно использовать df.drop('название_столбца', axis=1), где axis=1 указывает, что удаляется столбец, а не строка. Важно помнить, что многие операции над DataFrame могут быть выполнены «на месте» или с возвратом нового объекта, в зависимости от того, стоит ли параметр inplace=True.
Кроме того, стоит обратить внимание на работу с пропущенными значениями. Pandas предоставляет набор функций для заполнения или удаления пропусков, таких как fillna() и dropna(). Использование этих методов позволяет избежать ошибок при дальнейшем анализе и обеспечит корректность результатов. Заполнение пропусков может быть выполнено разными способами: с использованием среднего значения, медианы или методов, учитывающих соседние данные.
Как выбрать строки по индексу в DataFrame
Для выбора строк по индексу в DataFrame используется метод iloc[], который позволяет работать с данными по их позициям. Индексы в iloc начинаются с 0, и можно указать как отдельные индексы, так и диапазоны.
Для выборки одной строки по индексу передайте в iloc единственное число. Например, чтобы получить строку с индексом 2:
df.iloc[2]Для получения нескольких строк используйте диапазоны, задавая начальный и конечный индекс через двоеточие. При этом конечный индекс не включается в результат. Пример для выбора строк с индексами от 1 до 3:
df.iloc[1:4]Чтобы выбрать строки с конкретными индексами, можно передать список чисел. Например, чтобы получить строки с индексами 0, 2 и 4:
df.iloc[[0, 2, 4]]Если необходимо извлечь строки с определенным шагом, используйте синтаксис с третьим параметром, который задает шаг. Например, для получения строк с шагом 2:
df.iloc[::2]Метод iloc[] работает исключительно с числовыми позициями, и для использования поименованных индексов следует применить метод loc[], который работает с метками индексов.
Как фильтровать данные с помощью условий в DataFrame
Для фильтрации данных используется синтаксис, основанный на логических выражениях, которые применяются к столбцам DataFrame. Рассмотрим несколько примеров использования условий для фильтрации данных.
Основной способ фильтрации – это использование булевых выражений, которые применяются к столбцам. Например, чтобы выбрать строки, где значение в столбце «Возраст» больше 30, нужно выполнить следующее:
df[df['Возраст'] > 30]
Здесь df['Возраст'] > 30 создаёт булевый массив, который указывает, где условие выполняется. В результате мы получаем только те строки, где возраст больше 30.
Важным моментом является то, что такие условия могут быть объединены с помощью логических операторов & (и), | (или), и ~ (не). Пример:
df[(df['Возраст'] > 30) & (df['Пол'] == 'Мужчина')]
Этот запрос выберет все строки, где возраст больше 30 и пол мужчины. Не забудьте использовать скобки вокруг каждого условия, так как логические операторы имеют приоритет.
Кроме того, можно использовать методы для работы с текстовыми данными. Например, чтобы выбрать строки, где в столбце «Город» содержится слово «Москва», можно применить метод str.contains():
df[df['Город'].str.contains('Москва', na=False)]
Опция na=False необходима для исключения строк с пропущенными значениями, иначе метод вернёт ошибку при попытке обработки NaN.
Для фильтрации по множеству значений можно использовать метод isin(). Например, если нужно выбрать строки, где город находится в списке нескольких значений:
df[df['Город'].isin(['Москва', 'Санкт-Петербург', 'Казань'])]
Если нужно исключить строки с определёнными значениями, достаточно добавить отрицание с помощью ~:
df[~df['Город'].isin(['Москва', 'Санкт-Петербург'])]
Иногда данные содержат пропущенные значения, и для их фильтрации используется метод isna() или notna() для выбора строк с или без пропусков. Например, чтобы выбрать строки с пропущенными значениями в столбце «Возраст»:
df[df['Возраст'].isna()]
Для комбинированной фильтрации часто используется метод query(), который позволяет записывать условия в виде строки. Например:
df.query('Возраст > 30 and Пол == "Мужчина"')
Метод query() предоставляет более читаемый синтаксис, особенно при работе с несколькими условиями.
Наконец, для фильтрации данных на основе индексов можно использовать метод iloc, который позволяет выбирать строки и столбцы по индексам:
df.iloc[0:5]
Этот код вернёт первые пять строк DataFrame.
Сложные фильтры часто требуют предварительной подготовки данных и внимательного подхода, но это один из самых эффективных методов обработки больших наборов данных в Pandas.
Как добавить новые столбцы в DataFrame
Для добавления новых столбцов в DataFrame в библиотеке pandas достаточно присвоить новое значение существующему столбцу или создать новый столбец с помощью индексации. Существует несколько способов добавления столбцов, каждый из которых подходит для разных случаев.
1. Добавление столбца с постоянным значением
Чтобы создать новый столбец с одинаковыми значениями для всех строк, можно просто присвоить значение новому столбцу. Например, чтобы добавить столбец «new_col» со значением 0:
df['new_col'] = 0Теперь каждый элемент в столбце «new_col» будет равен 0.
2. Добавление столбца на основе других столбцов
Если новый столбец зависит от значений других столбцов, можно использовать арифметические операции или функции. Например, для создания столбца «total», который является суммой столбцов «price» и «quantity»:
df['total'] = df['price'] * df['quantity']Этот метод позволяет вычислять значения на лету, используя данные других столбцов.
3. Добавление столбца с помощью метода assign()
Метод assign() позволяет добавить новый столбец, при этом возвращая новый DataFrame, не изменяя оригинальный. Этот способ полезен, если необходимо сохранить исходную таблицу:
df = df.assign(new_col=df['price'] * 0.9)Таким образом, столбец «new_col» будет содержать результат применения скидки 10% к столбцу «price».
4. Добавление столбца с использованием insert()
Метод insert() позволяет добавить новый столбец в указанную позицию, а не в конец DataFrame. Например, чтобы добавить столбец «id» в начало DataFrame:
df.insert(0, 'id', range(1, len(df)+1))Теперь столбец «id» будет добавлен как первый, и его значения будут уникальными числами от 1 до количества строк в DataFrame.
5. Добавление столбца на основе условия
Для добавления столбца, значения которого зависят от условий, можно использовать np.where() или apply(). Например, чтобы создать столбец «discount», который будет равен 10% для товаров, цена которых больше 100, а для остальных – 5%:
import numpy as np
df['discount'] = np.where(df['price'] > 100, 0.1, 0.05)Этот способ полезен, когда требуется выполнить более сложные условия для вычислений.
6. Добавление столбца с использованием lambda функции
Можно также использовать apply() с lambda функцией для добавления столбцов на основе вычислений, применяемых к строкам. Например, если нужно создать новый столбец, в котором будут значения на основе первых букв из другого столбца:
df['first_letter'] = df['product_name'].apply(lambda x: x[0])Этот способ полезен, когда нужно применить более сложную логику для вычислений.
Каждый из этих методов позволяет эффективно добавлять новые столбцы в DataFrame в зависимости от конкретных нужд анализа данных. Выбор подхода зависит от того, хотите ли вы изменить исходный DataFrame, добавить столбец в определенную позицию или вычислить значения на основе других данных.
Как изменять значения в ячейках DataFrame
Для изменения значений в ячейках DataFrame в Python с использованием библиотеки pandas существует несколько эффективных методов. Рассмотрим их на примерах.
1. Использование индексации по строкам и столбцам. Если нужно изменить значение конкретной ячейки, можно использовать метод .loc[] или .iloc[]. .loc[] принимает метки строк и столбцов, а .iloc[] – индексы. Например, чтобы изменить значение на пересечении строки с меткой ‘row1’ и столбца ‘col2’, используем:
df.loc['row1', 'col2'] = новое_значениеАналогично можно использовать .iloc[] для индексов:
df.iloc[0, 1] = новое_значение2. Изменение нескольких значений. Чтобы изменить несколько значений за раз, можно передать массив значений. Например, чтобы обновить все значения в столбце ‘col1’, можно сделать так:
df['col1'] = новые_значения3. Использование условия для изменения значений. Для выбора строк, удовлетворяющих некоторому условию, можно использовать метод .loc[] с условием. Например, чтобы заменить все значения в столбце ‘col1’, где значение больше 10, на 0, пишем:
df.loc[df['col1'] > 10, 'col1'] = 04. Изменение нескольких ячеек с разными условиями. В случаях, когда нужно изменить значения в зависимости от нескольких условий, используйте логические операторы. Например, если вы хотите заменить значения в ‘col1’ на 0, когда значение в ‘col2’ больше 5 и меньше 15, используйте:
df.loc[(df['col2'] > 5) & (df['col2'] < 15), 'col1'] = 05. Использование метода .at[] для изменения одной ячейки. Если требуется обновить единственное значение в DataFrame, метод .at[] будет более эффективным, чем .loc[], поскольку работает быстрее при изменении одного элемента:
df.at['row1', 'col2'] = новое_значение6. Изменение значений с использованием apply. Метод apply() позволяет применять функцию ко всем значениям столбца или строк. Если нужно преобразовать все значения в столбце, например, сделать их больше на 10, используйте:
df['col1'] = df['col1'].apply(lambda x: x + 10)7. Изменение значений на основе других столбцов. Для более сложных изменений можно использовать данные из других столбцов. Например, если нужно заменить значения в 'col1' на разницу между значениями в 'col2' и 'col3', напишем:
df['col1'] = df['col2'] - df['col3']8. Применение функции с условием для замены значений. Когда нужно заменить значения по условию, можно использовать np.where(). Например, заменим все значения в 'col1' на 0, если значение в 'col2' больше 10:
import numpy as np
df['col1'] = np.where(df['col2'] > 10, 0, df['col1'])Как объединить несколько DataFrame по столбцам и строкам
При объединении DataFrame по столбцам используется метод concat(). Этот метод позволяет объединять несколько таблиц горизонтально или вертикально. Например, для объединения двух DataFrame по строкам (т.е. добавление новых строк) можно применить следующий код:
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
result = pd.concat([df1, df2], axis=0, ignore_index=True)
print(result)Этот код объединит DataFrame df1 и df2 по строкам, индекс будет перенумерован. Параметр axis=0 указывает, что объединение должно происходить по строкам. Если требуется объединить по столбцам, используется axis=1.
Для объединения DataFrame по столбцам можно также использовать concat(), но важно убедиться, что столбцы в обеих таблицах совпадают по именам. В противном случае будут добавлены новые столбцы с NaN-значениями для отсутствующих данных:
df1 = pd.DataFrame({'A': [1, 2]})
df2 = pd.DataFrame({'B': [3, 4]})
result = pd.concat([df1, df2], axis=1)
print(result)При объединении таблиц важно контролировать индексы. Если индексы совпадают, pandas будет использовать их для выравнивания данных, что может привести к ошибкам. В таких случаях можно использовать параметр ignore_index=True, чтобы индекс был перенумерован.
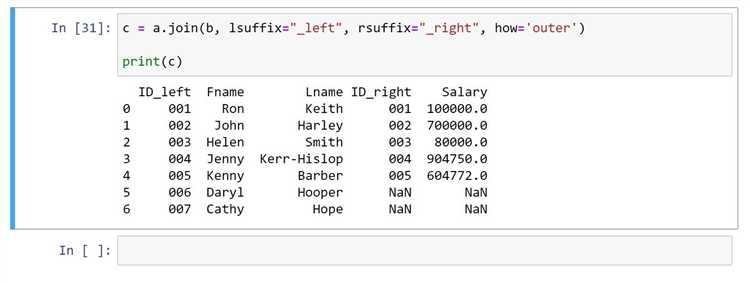
Если требуется более сложная логика объединения, например, по ключевым столбцам, для этого подходит метод merge(). Он работает аналогично SQL-операции JOIN и позволяет объединить два DataFrame по одному или нескольким ключевым столбцам. Например:
df1 = pd.DataFrame({'key': ['A', 'B'], 'value': [1, 2]})
df2 = pd.DataFrame({'key': ['A', 'C'], 'value': [3, 4]})
result = pd.merge(df1, df2, on='key', how='inner')
print(result)Этот пример объединяет два DataFrame по столбцу key с использованием внутреннего объединения how='inner', то есть в результат попадут только те строки, у которых есть совпадения в обоих DataFrame.
Для выполнения внешнего объединения (outer join) используется how='outer', что позволяет сохранить все данные из обоих DataFrame, заполнив отсутствующие значения NaN:
result = pd.merge(df1, df2, on='key', how='outer')
print(result)Если нужно объединить данные по нескольким столбцам, можно передать список столбцов в параметр on:
df1 = pd.DataFrame({'key1': ['A', 'B'], 'key2': [1, 2], 'value': [1, 2]})
df2 = pd.DataFrame({'key1': ['A', 'B'], 'key2': [1, 3], 'value': [3, 4]})
result = pd.merge(df1, df2, on=['key1', 'key2'], how='outer')
print(result)Метод merge() предоставляет гибкие возможности для объединения данных с различными типами объединений, что делает его удобным инструментом для более сложных случаев.
Для эффективной работы с данными важно выбирать подходящий метод объединения в зависимости от структуры и целей анализа. Использование concat() хорошо подходит для простых случаев, когда важно добавить данные в конец или по бокам, а merge() идеально подходит для объединений, требующих более тонкой настройки, особенно при работе с ключевыми столбцами.
Как использовать методы groupby и агрегации в DataFrame
Метод groupby() в pandas позволяет группировать данные по одному или нескольким признакам, что облегчает выполнение различных операций агрегации. С его помощью можно эффективно обрабатывать большие наборы данных, разделяя их на группы по значению одного или нескольких столбцов, а затем применяя функции агрегации для получения сводной информации.
Основной синтаксис метода следующий: df.groupby(by), где by – это столбцы, по которым осуществляется группировка. Например, если у вас есть DataFrame с данными о продажах по магазинам и датам, и вы хотите агрегировать сумму продаж по каждому магазину, используйте такой код:
df.groupby('store')['sales'].sum()Этот вызов вернёт сумму продаж по каждому магазину. Однако groupby() также позволяет работать с несколькими столбцами. Например, чтобы получить сумму продаж по комбинации магазина и даты:
df.groupby(['store', 'date'])['sales'].sum()Группировка по нескольким столбцам возвращает многоуровневый индекс, что позволяет более детально анализировать данные.
После группировки можно применять различные агрегирующие функции, такие как sum(), mean(), count(), min(), max(), и другие. Однако pandas также позволяет использовать более сложные агрегирующие функции, например, через метод agg().
Пример использования agg(): если нужно одновременно получить сумму и среднее значение по продажам для каждого магазина:
df.groupby('store')['sales'].agg(['sum', 'mean'])Этот код возвращает DataFrame с двумя колонками – суммой и средним значением для каждого магазина.
Метод groupby() также поддерживает более сложные операции. Например, если нужно агрегировать по нескольким столбцам и применить разные функции для разных столбцов, можно использовать agg() с передачей словаря функций:
df.groupby('store').agg({
'sales': 'sum',
'date': 'min'
})В этом примере для каждого магазина вычисляется сумма по столбцу sales и минимальная дата по столбцу date.
Для упрощения анализа можно также использовать метод transform(), который позволяет применять агрегацию без изменения размера DataFrame. Например, если вам нужно добавить столбец, который будет содержать среднее значение по группе:
df['average_sales'] = df.groupby('store')['sales'].transform('mean')Этот код создаёт новый столбец average_sales, где для каждого магазина будет указано среднее значение продаж.
Таким образом, методы groupby() и агрегации предоставляют мощные инструменты для группировки и обработки данных. Важно выбирать правильные функции агрегации в зависимости от типа анализа, который требуется провести, и учитывать, что pandas предоставляет гибкость в применении нескольких функций одновременно для разных столбцов.
Как работать с пропущенными значениями в DataFrame
Работа с пропущенными значениями (NaN) в DataFrame – важный этап при обработке данных. В pandas для этого предусмотрены несколько методов, которые позволяют эффективно управлять отсутствующими данными.
Для начала, чтобы выявить пропущенные значения в DataFrame, можно использовать метод isnull(). Он возвращает DataFrame того же размера с булевыми значениями, где True означает наличие пропуска. Пример:
df.isnull()Чтобы получить количество пропущенных значений в каждом столбце, используйте метод sum():
df.isnull().sum()Если нужно удалить строки или столбцы с пропущенными значениями, применяйте метод dropna(). Для удаления строк с NaN значениями:
df.dropna()Чтобы удалить столбцы, содержащие хотя бы одно пропущенное значение, используйте параметр axis=1:
df.dropna(axis=1)Когда пропуски не критичны, вместо их удаления можно заполнить их значениями. Для этого используется метод fillna(). Например, для заполнения пропусков медианой столбца:
df['column'].fillna(df['column'].median())Если требуется заполнить пропуски определённым значением, укажите его как аргумент:
df.fillna(0)Для более сложных случаев заполнения пропусков можно использовать методы интерполяции с interpolate(). Это позволяет заполнить пропуски на основе значений соседних элементов. Пример интерполяции по умолчанию:
df.interpolate()Если необходимо использовать более специфичные методы интерполяции (например, линейную или полиномиальную), передайте соответствующий параметр в функцию:
df.interpolate(method='linear')Помимо стандартных методов, стоит учитывать, что удаление или заполнение пропусков может изменить статистику данных. Перед принятием решений о том, как работать с пропусками, важно оценить последствия для модели или анализа, с которым предстоит работать.
Как экспортировать DataFrame в CSV или Excel файл
В библиотеке pandas экспортировать данные в различные форматы очень просто. Для сохранения DataFrame в файл CSV или Excel можно использовать соответствующие методы. Рассмотрим, как это сделать в Python.
Для начала создадим DataFrame, чтобы показать на примере, как выполняется экспорт:
import pandas as pd
data = {'Имя': ['Иван', 'Алексей', 'Мария'],
'Возраст': [28, 34, 22],
'Город': ['Москва', 'Петербург', 'Новосибирск']}
df = pd.DataFrame(data)
Экспорт в CSV
Для того чтобы сохранить DataFrame в файл формата CSV, используйте метод to_csv(). Он позволяет гибко настроить параметры записи, такие как разделитель, кодировка и другие опции:
df.to_csv('output.csv', index=False, encoding='utf-8')
index=False– не записывать индекс в файл.encoding='utf-8'– указание кодировки для корректного отображения символов.sep– позволяет изменить разделитель (по умолчанию используется запятая).
Если вам нужно сохранить только определённые столбцы, можно указать их в параметре columns:
df.to_csv('output.csv', index=False, columns=['Имя', 'Возраст'])
Экспорт в Excel
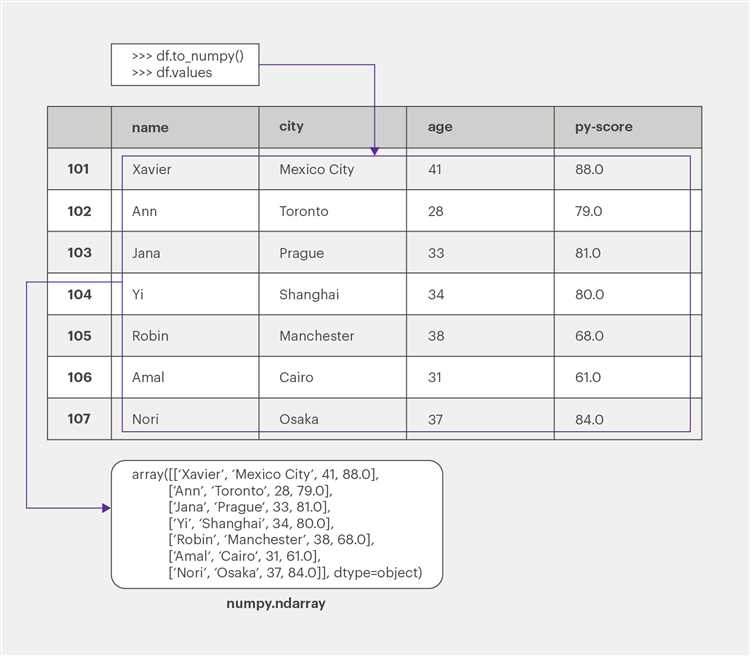
Для записи DataFrame в Excel файл используйте метод to_excel(). Этот метод требует установки дополнительной библиотеки openpyxl, если она ещё не установлена:
pip install openpyxl
Экспортировать данные в Excel можно следующим образом:
df.to_excel('output.xlsx', index=False)
sheet_name– задаёт имя листа (по умолчанию используется "Sheet1").engine='openpyxl'– указывает, какой движок использовать для работы с Excel файлами.- Можно сохранить несколько DataFrame в одном Excel файле, указав параметр
sheet_nameдля каждого.
Если необходимо настроить форматирование или добавить стили, можно использовать более сложные библиотеки, такие как xlsxwriter, но базовые операции можно выполнить с помощью openpyxl.
Рекомендации
- Если ваши данные содержат символы с акцентами или другие спецсимволы, всегда указывайте кодировку
utf-8, чтобы избежать ошибок при чтении файла в других системах. - Для больших DataFrame подумайте о добавлении параметра
chunksize, чтобы разбить экспорт на несколько частей, что поможет сэкономить память. - Если нужно хранить данные в нескольких листах Excel, рассмотрите использование
ExcelWriterдля записи данных в несколько листов в одном файле.
Экспорт данных в CSV и Excel – это простой и эффективный способ сохранить или передать данные для дальнейшей обработки или анализа.