Поиск слова в тексте – одна из базовых задач при обработке данных в Python. Существуют различные способы решения этой проблемы в зависимости от конкретных требований. Простой подход заключается в использовании встроенных методов строк, таких как find() и in. Эти инструменты позволяют быстро определить наличие слова в тексте или найти его позицию.
Метод find() возвращает индекс первого вхождения слова или -1, если слово не найдено. Это полезно, когда нужно не только проверить наличие слова, но и узнать его расположение в строке. Например:
text = "Привет, как дела?"
index = text.find("как") # Возвращает 7Если требуется проверить, содержится ли слово в строке, метод in будет более удобным. Он возвращает True, если слово есть в тексте, и False, если нет:
text = "Привет, как дела?"
result = "как" in text # Возвращает TrueДля более сложных случаев, например, когда нужно учесть регистр или найти все вхождения слова, можно использовать регулярные выражения с помощью модуля re. Регулярные выражения дают гибкость в поиске, позволяя использовать шаблоны для нахождения различных вариантов слова или его части:
import re
text = "Python – лучший язык для разработки. Python прост и мощный."
matches = re.findall(r"\bPython\b", text) # Возвращает ['Python', 'Python']Таким образом, выбор метода зависит от конкретных целей. Для базового поиска достаточно стандартных функций, но для более сложных и гибких запросов лучше использовать регулярные выражения.
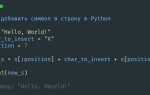
Использование оператора in для поиска слова в строке

Оператор in в Python позволяет легко проверить, содержится ли подстрока в строке. Это один из самых простых и быстрых методов поиска слова в тексте, который не требует использования дополнительных библиотек.
Синтаксис использования оператора in следующий:
слово в строке = слово in строкаОператор возвращает True, если слово найдено, и False, если его нет в строке. Пример:
текст = "Привет, как дела?"
результат = "как" in текст
print(результат) # TrueЕсли необходимо найти точное совпадение слова (например, «привет», а не «приветствие»), можно предварительно преобразовать строки в нижний регистр с помощью метода lower():
текст = "Привет, как дела?"
результат = "привет" in текст.lower()
print(результат) # TrueЭтот метод хорош для быстрого поиска, но если нужно учитывать границы слов или искать слово в разных формах (например, «друг» и «друга»), рекомендуется использовать регулярные выражения.
Оператор in не чувствителен к регистру, что делает его удобным при поиске слов в различных форматах текста. Однако он не позволяет детально настраивать поиск, например, находить полные слова, исключая части других слов. Для таких случаев лучше использовать регулярные выражения через модуль re.
Поиск с учётом регистра с помощью метода lower()

Метод lower() в Python используется для преобразования строк в нижний регистр. Это особенно полезно при поиске слова в тексте, если необходимо игнорировать различия в регистрах символов.
Для поиска слова с учётом регистра, можно применить метод lower() к строкам, что обеспечит единообразие символов, устраняя различия между заглавными и строчными буквами. Преобразуя обе строки в нижний регистр, можно безопасно выполнять поиск, не заботясь о том, как написано слово.
Пример использования метода lower() для поиска слова в тексте:
text = "Программирование на Python – это увлекательно."
search_word = "python"
if search_word.lower() in text.lower():
print("Слово найдено!")
else:
print("Слово не найдено.")
В этом примере мы сначала преобразуем обе строки – и текст, и искомое слово – в нижний регистр. Это исключает возможные ошибки, связанные с тем, что «Python» может быть записано с разными регистровыми комбинациями (например, «python», «Python», «PYTHON»).
Метод lower() эффективен для небольших текстов, однако для больших объёмов данных может быть менее оптимален, так как для каждой строки выполняется дополнительная операция преобразования. В таких случаях стоит использовать более сложные методы, такие как регулярные выражения.
- Метод
lower()не изменяет исходную строку, а возвращает новую строку в нижнем регистре. - Если поиск должен учитывать точный регистр, метод
lower()не будет полезен. В этом случае, можно использовать обычное сравнение без преобразования строк. - Для поиска нескольких слов в тексте с учётом регистра можно использовать цикл и применять метод
lower()к каждому слову.
Пример поиска нескольких слов:
words = ["python", "programming", "code"]
text = "Программирование на Python – это увлекательно."
for word in words:
if word.lower() in text.lower():
print(f"Слово '{word}' найдено.")
else:
print(f"Слово '{word}' не найдено.")
Такой подход помогает быстро находить все заданные слова, игнорируя различия в их написании с заглавными и строчными буквами.
Регулярные выражения для более сложных паттернов

Регулярные выражения предоставляют мощные средства для работы с текстом, позволяя находить, заменять и проверять соответствие сложным паттернам. Когда стандартных методов поиска недостаточно, регулярные выражения помогут решать задачи, включающие сложные критерии и различные вариации входных данных.
В Python для работы с регулярными выражениями используется модуль re. Важно понимать, как правильно строить регулярные выражения, чтобы эффективно находить нужные фрагменты текста.
Некоторые часто используемые элементы регулярных выражений:
\d– находит любую цифру (эквивалентно [0-9]).\w– находит любой буквенно-цифровой символ (буквы и цифры). Также эквивалентно[a-zA-Z0-9_].\s– находит пробельные символы (пробел, табуляция, новая строка и т.д.).^– якорь, который указывает на начало строки.$– якорь, который указывает на конец строки.
Для создания более сложных паттернов, когда требуется учитывать различные комбинации символов, можно комбинировать эти элементы с другими конструкциями.
Пример использования регулярных выражений для поиска всех чисел в тексте:
import re
text = "В этом тексте 123 числа и 4567 других."
pattern = r'\d+'
result = re.findall(pattern, text)
print(result) # Выведет: ['123', '4567']
Регулярные выражения могут быть также использованы для поиска текстовых шаблонов с ограничениями. Например, если необходимо найти все слова, начинающиеся с большой буквы, можно использовать следующий паттерн:
pattern = r'\b[A-Z][a-z]*\b'
Этот паттерн ищет слова, которые начинаются с заглавной буквы, за которой следуют строчные буквы. Для поиска слов с различной длиной или начальной буквой можно адаптировать паттерн, добавляя дополнительные условия.
Регулярные выражения также позволяют работать с группами символов. Это удобно для извлечения конкретных фрагментов данных из строки. Например, чтобы извлечь номер телефона, который состоит из кода региона, кода оператора и самого номера, можно использовать паттерн:
pattern = r'(\+\d{1,2})\s?(\(\d{3}\))?\s?(\d{3}-\d{4})'
Этот паттерн позволяет находить номера в различных форматах, включая с кодом страны и оператора.
Для сложных паттернов также можно использовать re.sub() для замены текста. Например, заменив все даты в формате «день.месяц.год» на формат «год-месяц-день», можно использовать следующий код:
pattern = r'(\d{2})\.(\d{2})\.(\d{4})'
replacement = r'\3-\2-\1'
result = re.sub(pattern, replacement, "25.12.2025")
print(result) # Выведет: 2025-12-25
Регулярные выражения становятся особенно полезными при необходимости работы с большими объемами данных, где традиционные методы поиска и манипуляции текстом оказываются менее эффективными.
Основные рекомендации для работы с регулярными выражениями:
- Применяйте скобки для создания групп, чтобы захватывать части строки.
- Используйте
^и$для ограничения поиска на начало и конец строки соответственно. - Регулярные выражения могут быть чувствительными к регистру. Для игнорирования регистра добавьте флаг
re.IGNORECASE. - Оптимизируйте выражения для работы с большими объемами данных, избегая излишней сложности паттернов.
Как искать все вхождения слова в тексте

Для поиска всех вхождений слова в тексте в Python можно использовать регулярные выражения. Модуль re предоставляет мощные инструменты для работы с текстовыми данными и поиска совпадений. Чтобы найти все вхождения слова, используется функция findall(), которая возвращает все найденные совпадения в виде списка.
Пример кода для поиска всех вхождений слова «python» в строке:
import re
text = "Python – это популярный язык программирования. Python используется в разных областях."
word = "python"
matches = re.findall(r"\b" + re.escape(word) + r"\b", text, flags=re.IGNORECASE)
print(matches)
В этом примере:
\b– это границы слова, что гарантирует, что поиск будет происходить именно по целым словам.re.escape()используется для экранирования специальных символов, если они есть в искомом слове.re.IGNORECASEпозволяет игнорировать регистр символов при поиске.
Результатом выполнения этого кода будет список всех вхождений слова «python» в тексте, независимо от регистра.
Если нужно искать не точное совпадение, а, например, все слова, начинающиеся на «py», можно использовать модификацию регулярного выражения:
matches = re.findall(r"\bpy\w*", text, flags=re.IGNORECASE)
print(matches)
Этот код найдет все слова, начинающиеся на «py», такие как «Python», «pythonic» и другие.
Таким образом, регулярные выражения позволяют гибко и эффективно искать все вхождения слов в тексте, а также легко настраивать поиск под конкретные нужды.
Поиск с учётом целых слов: использование \b в регулярных выражениях

Метасимвол \b обозначает границу слова. Это не символ, а условие, которое определяет, где начинается или заканчивается слово. Важно понимать, что \b срабатывает в местах, где происходит изменение от символа слова (буквы, цифры) к не-слову (пробел, пунктуация, начало или конец строки).
Пример использования \b:
import re text = "Python – это популярный язык программирования. Я люблю Python!" pattern = r'\bPython\b' matches = re.findall(pattern, text) print(matches)
В этом примере поиск будет успешным только для слова «Python», не найдя части слов, например «Pythonism» или «mypython». Это даёт точность в поиске, особенно если нужно убедиться, что найдено именно отдельное слово, а не его часть.
Если вы используете \b для поиска, важно помнить, что он будет работать только для слов, состоящих из букв, цифр и подчеркиваний. Символы, такие как дефисы или апострофы, могут быть восприняты как не-слово, что повлияет на результаты поиска.
Пример с апострофом:
text = "Это Джо'с машина." pattern = r'\bДжо\'с\b' matches = re.findall(pattern, text) print(matches)
Таким образом, \b позволяет точно находить отдельные слова в тексте, предотвращая случайные совпадения частей слов. Это полезно в разных задачах, таких как фильтрация текста или анализ контента, где требуется точность в определении границ слов.
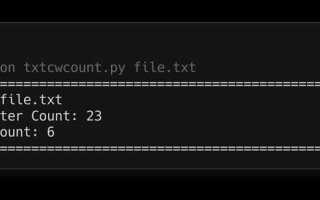
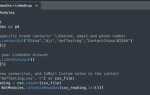
Поиск слова в большом файле с использованием Python
При работе с большими файлами важно выбрать оптимальный способ поиска. Простые методы чтения файла в память могут быть неэффективны при обработке больших объемов данных, так как это требует значительных ресурсов. В Python существует несколько подходов для поиска слова в большом файле, не загружая его целиком в память.
Одним из распространенных методов является построчное чтение файла с помощью функции open() и итерации по строкам. Этот метод позволяет обрабатывать файл по частям, снижая нагрузку на память. Пример кода для поиска слова:
def search_word_in_file(file_path, word):
with open(file_path, 'r') as file:
for line_number, line in enumerate(file, start=1):
if word in line:
print(f"Слово найдено в строке {line_number}")
Для оптимизации поиска можно использовать регулярные выражения. Модуль re позволяет более гибко настраивать поиск, например, для учета регистра или поиска всех вхождений слова в строке:
import re
def search_word_with_regex(file_path, word):
pattern = re.compile(r'\b' + re.escape(word) + r'\b')
with open(file_path, 'r') as file:
for line_number, line in enumerate(file, start=1):
if pattern.search(line):
print(f"Слово найдено в строке {line_number}")
Использование регулярных выражений позволяет искать слово с учетом границ слова и избегать ложных срабатываний. Функция re.escape() обеспечивает правильное экранирование символов, если слово содержит специальные символы регулярных выражений.
Для еще большего ускорения поиска можно воспользоваться многозадачностью с помощью библиотеки concurrent.futures. Эта библиотека позволяет обрабатывать несколько частей файла параллельно, что особенно полезно при работе с очень большими файлами.
from concurrent.futures import ThreadPoolExecutor
def search_in_file_parallel(file_path, word):
def search_chunk(start, end):
with open(file_path, 'r') as file:
file.seek(start)
chunk = file.read(end - start)
if word in chunk:
print(f"Слово найдено в пределах байтов {start}-{end}")
with open(file_path, 'r') as file:
file_size = len(file.read())
chunk_size = file_size // 4 # Разделим на 4 части для многозадачности
with ThreadPoolExecutor() as executor:
for start in range(0, file_size, chunk_size):
end = min(start + chunk_size, file_size)
executor.submit(search_chunk, start, end)
Для больших текстовых файлов полезно также индексировать данные, особенно если поиск будет выполняться многократно. Индексирование позволяет заранее разбить файл на части, что уменьшает время на поиск в дальнейшем.
Вопрос-ответ:
Как найти слово в тексте с помощью Python?
Для того чтобы найти слово в тексте на Python, можно воспользоваться функцией `find()` или операцией `in`. Например, если нужно узнать, содержится ли слово «Python» в строке, то можно использовать конструкцию: `»Python» in text`, которая вернёт `True`, если слово присутствует в тексте. Если требуется получить позицию, на которой встречается это слово, можно использовать метод `find()`. Этот метод вернёт индекс первого вхождения слова, либо `-1`, если слово не найдено.
Что делать, если мне нужно найти все вхождения слова в тексте, а не только первое?
Если необходимо найти все вхождения слова в тексте, то можно использовать регулярные выражения. Для этого в Python есть модуль `re`. Пример: `re.findall(r’слово’, text)` — это вернёт список всех мест, где встречается искомое слово в тексте. Метод `findall()` ищет все совпадения и возвращает их в виде списка. Если нужно получить позиции вхождений, можно использовать `re.finditer()`, который вернёт итератор с объектами, содержащими информацию о позиции каждого совпадения.
Что делать, если слово нужно искать с учётом определённых условий, например, только в начале или в конце строки?
Для поиска с учётом определённых условий, можно использовать методы `startswith()` или `endswith()`, которые проверяют, начинается ли строка с заданного слова или заканчивается на него. Если же требуется более гибкая фильтрация, можно использовать регулярные выражения. Например, для поиска слова, которое встречается в начале строки, можно использовать: `re.match(r’^слово’, text)`, а для поиска на конце строки — `re.search(r’слово$’, text)`. Эти методы позволят точно контролировать, где в строке должно находиться слово.