Если требуется разбивать список по количеству элементов, например, по 3, можно использовать срезы в цикле или генераторы. Конструкция [lst[i:i + n] for i in range(0, len(lst), n)] позволяет быстро создать вложенный список, где каждый подсписок содержит n элементов. Такой подход прост, не требует сторонних библиотек и работает для любых итерируемых объектов, если предварительно привести их к списку.
Для группировки по содержимому используют функции из модуля itertools. groupby() позволяет объединить последовательные элементы, имеющие одинаковое значение ключа. Однако важно помнить: предварительно нужно отсортировать список по этому ключу, иначе результат окажется непредсказуемым. Например, groupby(sorted(data, key=func), key=func) создаёт подсписки, каждый из которых соответствует одной группе по заданному критерию.
Также применим defaultdict из модуля collections, если нужно сгруппировать элементы без требования сохранения порядка. В этом случае ключ – результат функции, применённой к элементу, а значение – список всех элементов с таким ключом. Этот способ удобен, если нужна полная независимость от порядка и требуется итоговая структура в виде словаря списков.
Выбор метода зависит от задачи: фиксированная длина – срезы; группировка по ключу с учётом порядка – groupby; по ключу без порядка – defaultdict. Универсального способа нет, но понимание ограничений каждого подхода помогает избежать ошибок и лишней сложности.
Группировка по фиксированному размеру блока
Для разбиения списка на подсписки фиксированной длины используют срезы в цикле или функции из стандартной библиотеки. При известной длине блока можно обойтись обычным циклом:
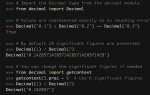
def chunk_by_size(lst, size):
return [lst[i:i + size] for i in range(0, len(lst), size)]
данные = [1, 2, 3, 4, 5, 6, 7]
результат = chunk_by_size(данные, 3)
# [[1, 2, 3], [4, 5, 6], [7]]
Если важна скорость и не требуется копирование данных, можно использовать итераторы:
from itertools import islice
def chunk_iterator(iterable, size):
it = iter(iterable)
while True:
блок = list(islice(it, size))
if not блок:
break
yield блок
данные = range(10)
результат = list(chunk_iterator(данные, 4))
# [[0, 1, 2, 3], [4, 5, 6, 7], [8, 9]]
При работе с файлами или потоками лучше использовать генераторы – они не загружают всё содержимое в память. Для равномерного деления на части одинаковой длины, когда размер списка кратен длине блока, можно применить модуль more_itertools:
from more_itertools import chunked
результат = list(chunked([10, 20, 30, 40, 50, 60], 2))
# [[10, 20], [30, 40], [50, 60]]
Если размер списка не делится нацело, последний блок будет короче. Для выравнивания можно заполнить его вручную или использовать fillvalue из функции zip_longest:
from itertools import zip_longest
def chunk_fill(lst, size, fill=None):
args = [iter(lst)] * size
return list(zip_longest(*args, fillvalue=fill))
результат = chunk_fill([1, 2, 3, 4, 5], 2, 0)
# [(1, 2), (3, 4), (5, 0)]
Формирование вложенных списков по признаку значения
Для группировки элементов по значению используют структуры данных, где ключом служит само значение или его производное. Часто применяют словарь, в котором ключи – уникальные значения, а значения – списки, содержащие все совпадающие элементы. После заполнения словаря можно извлечь вложенные списки с помощью dict.values().
Пример группировки списка строк по первой букве:
from collections import defaultdict
данные = ['apple', 'apricot', 'banana', 'blueberry', 'avocado', 'blackberry']
группы = defaultdict(list)
for элемент in данные:
ключ = элемент[0]
группы[ключ].append(элемент)
результат = list(группы.values())
print(результат)
Результат: [['apple', 'apricot', 'avocado'], ['banana', 'blueberry', 'blackberry']]
Группировку по диапазону значений удобно реализовать с использованием пользовательской функции, возвращающей метку группы. Пример: распределение чисел по десяткам.
числа = [3, 14, 17, 22, 27, 31, 35, 41]
группы = defaultdict(list)
for число in числа:
ключ = (число // 10) * 10
группы[ключ].append(число)
результат = list(группы.values())
print(результат)
Результат: [[3], [14, 17], [22, 27], [31, 35], [41]]
Если список содержит словари, ключом группировки может быть значение определённого поля. Пример: группировка пользователей по возрасту.
пользователи = [
{'имя': 'Анна', 'возраст': 30},
{'имя': 'Иван', 'возраст': 25},
{'имя': 'Ольга', 'возраст': 30}
]
группы = defaultdict(list)
for пользователь in пользователи:
ключ = пользователь['возраст']
группы[ключ].append(пользователь)
результат = list(группы.values())
print(результат)
Результат: [[{'имя': 'Анна', 'возраст': 30}, {'имя': 'Ольга', 'возраст': 30}], [{'имя': 'Иван', 'возраст': 25}]]
Для сортировки элементов внутри групп применяют sorted() с передачей функции сортировки. Это позволяет контролировать порядок значений в каждой вложенной группе.
Разбиение списка по индексам с заданным шагом

Для получения вложенных списков с равномерным шагом между элементами используется срез с указанием шага. Пример: есть список data = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]. Чтобы сгруппировать элементы с шагом 3 по индексам, можно воспользоваться генератором:
result = [data[i::3] for i in range(3)]
Выход: [[0, 3, 6, 9], [1, 4, 7], [2, 5, 8]]. Элементы распределяются по остаткам от деления индекса на шаг. Такой подход удобен, если требуется чередование значений по группам.
Если нужно получить последовательные подсписки фиксированной длины, используется другой метод: [data[i:i+3] for i in range(0, len(data), 3)]. Результат: [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]. Последний вложенный список может содержать меньше элементов, если длина исходного списка не делится на шаг без остатка.
Для строгого контроля длины вложенных списков и удаления неполной группы в конце применяется фильтрация: [data[i:i+3] for i in range(0, len(data), 3) if len(data[i:i+3]) == 3].
Модуль itertools не даёт встроенной функции для такого разбиения, но можно использовать zip с распаковкой срезов: list(zip(*[data[i::3] for i in range(3)])) для равномерного распределения по группам.
Оптимальный способ зависит от цели: равномерное распределение по индексам или группировка подряд идущих элементов. Важно учитывать, что срезы не создают копии вложенных списков, а ссылаются на части исходного, что влияет на производительность и изменения данных.
Группировка элементов с использованием itertools.groupby

Модуль itertools содержит функцию groupby, предназначенную для последовательной группировки элементов по ключу. Перед использованием необходимо отсортировать данные по тому же критерию, иначе результат будет непредсказуем.
Пример группировки чисел по чётности:
from itertools import groupby
data = [5, 1, 2, 4, 3, 6, 8]
data.sort(key=lambda x: x % 2)
grouped = [
list(group)
for key, group in groupby(data, key=lambda x: x % 2)
]
print(grouped) # [[2, 4, 6, 8], [5, 1, 3]]
data.sort(key=lambda x: x % 2)– обязательная предварительная сортировка по ключу.groupby(..., key=...)– итератор, возвращающий кортежи (ключ, группа).list(group)– материализация группы, иначе итератор будет исчерпан при первом проходе.
Для группировки строк по первой букве:
words = ['apple', 'apricot', 'banana', 'avocado', 'blueberry']
words.sort(key=lambda word: word[0])
grouped = {
key: list(group)
for key, group in groupby(words, key=lambda word: word[0])
}
print(grouped) # {'a': ['apple', 'apricot', 'avocado'], 'b': ['banana', 'blueberry']}
- Группы можно сохранять как списки, словари или вложенные структуры, в зависимости от задачи.
- При работе с вложенными ключами используйте
itemgetterили вложенныеlambda.
groupby подходит для линейных, уже отсортированных по нужному признаку коллекций. Для неблоковой группировки применяйте defaultdict.
Создание вложенных списков на основе условия

Вложенные списки часто формируются при группировке элементов по признаку. Пример – разбиение чисел на чётные и нечётные:
numbers = [1, 2, 3, 4, 5, 6]
grouped = [[], []]
for num in numbers:
grouped[num % 2].append(num)
grouped: [[2, 4, 6], [1, 3, 5]]
Для сложных условий используют словари с последующей конвертацией значений в список:
from collections import defaultdict
words = ['apple', 'ant', 'banana', 'boat', 'cat']
groups = defaultdict(list)
for word in words:
groups[word[0]].append(word)
nested = list(groups.values())
nested: [['apple', 'ant'], ['banana', 'boat'], ['cat']]
Если нужно разбить список на группы фиксированного размера, используется срез:
items = list(range(10))
size = 3
nested = [items[i:i + size] for i in range(0, len(items), size)]
nested: [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
Фильтрация по предикату и объединение результатов:
data = [15, 22, 7, 10, 33, 42]
below_20 = [x for x in data if x < 20]
at_least_20 = [x for x in data if x >= 20]
nested = [below_20, at_least_20]
nested: [[15, 7, 10], [22, 33, 42]]
Если требуется динамическое количество групп, то используют функцию-группировщик. Пример – по длине строки:
strings = ['hi', 'hello', 'hey', 'hola']
groups = defaultdict(list)
for s in strings:
groups[len(s)].append(s)
nested = list(groups.values())
nested: [['hi'], ['hey'], ['hola'], ['hello']]
Группировка элементов по ключу из словаря или функции
Для группировки по ключу из словаря можно воспользоваться функцией `defaultdict` из модуля `collections`. Этот подход позволяет автоматически создавать новые группы, если ключ отсутствует в словаре. Пример:
from collections import defaultdict
data = [('apple', 3), ('banana', 2), ('apple', 5), ('banana', 4)]
grouped = defaultdict(list)
for key, value in data:
grouped[key].append(value)
print(dict(grouped))
Результат:
{'apple': [3, 5], 'banana': [2, 4]}
В этом примере каждый элемент списка представляет собой кортеж, где первый элемент – это ключ, а второй – значение. Мы группируем значения по ключу, сохраняя их в списках.
Если необходимо сгруппировать элементы с помощью произвольной функции, можно использовать `groupby` в сочетании с функцией сортировки. Пример, где мы группируем числа по четности:
from itertools import groupby
data = [1, 2, 3, 4, 5, 6]
data.sort(key=lambda x: x % 2)
grouped = {k: list(g) for k, g in groupby(data, key=lambda x: x % 2)}
print(grouped)
Результат:
{1: [1, 3, 5], 0: [2, 4, 6]}
Здесь мы группируем числа по ключу, определяемому функцией `lambda x: x % 2`, которая определяет четность. Сначала список сортируется по этому ключу, затем элементы группируются с помощью `groupby`.
Группировка по ключу позволяет эффективно агрегировать данные, что полезно при анализе больших наборов данных. Важно помнить, что сортировка данных перед использованием `groupby` является необходимым шагом для правильной работы алгоритма.