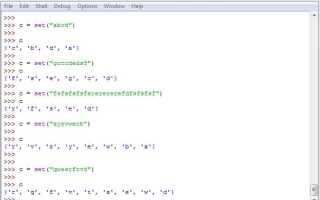
Задача нахождения одинаковых символов в строке на Python может возникнуть в самых разных контекстах: от простых текстовых анализов до более сложных алгоритмических задач. Однако в отличие от поверхностного подхода, задача поиска одинаковых символов требует внимательности к деталям. Важно понимать, как правильно использовать встроенные возможности Python для достижения нужного результата с минимальной затратой времени и ресурсов.
Для эффективного поиска одинаковых символов в строке стоит обратить внимание на использование структур данных, таких как множества и словаря, которые позволяют быстро выявлять повторяющиеся элементы. В Python существуют инструменты, которые позволяют решить эту задачу без явных циклов и дополнительных вычислений, а также минимизировать вероятность ошибок при обработке больших объемов данных.
Одним из самых эффективных решений является использование метода collections.Counter, который предоставляет простое средство для подсчета частоты каждого символа в строке. Это решение не только компактно, но и позволяет легко адаптировать код для дальнейших задач, таких как подсчет и сортировка одинаковых символов в строках различной длины.
В этой статье мы рассмотрим несколько подходов для нахождения одинаковых символов в строке, оценим их производительность и подберем оптимальные методы для решения различных задач на Python. Применяя эти техники, вы сможете не только улучшить понимание языка, но и повысить эффективность своих программных решений.
Как найти дубликаты символов с помощью словаря
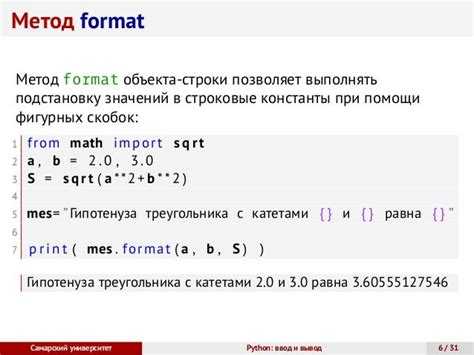
Чтобы найти дубликаты символов в строке с помощью словаря, важно понять, что словарь идеально подходит для хранения пар «ключ-значение», где ключи уникальны. Используя этот принцип, можно легко отслеживать, сколько раз встречается каждый символ в строке.
Первый шаг – пройти по строке и для каждого символа проверять, встречался ли он ранее. Для этого создадим пустой словарь, в котором будем хранить символы в качестве ключей, а их количество – в качестве значений. Если символ уже есть в словаре, увеличиваем его счетчик.
Пример кода:
text = "example string"
duplicates = {}
for char in text:
if char in duplicates:
duplicates[char] += 1
else:
duplicates[char] = 1
# Фильтруем только символы, которые встречаются больше одного раза
result = {char: count for char, count in duplicates.items() if count > 1}
print(result)
В этом примере для строки «example string» мы создаем словарь, где каждый символ – это ключ, а его количество появления в строке – значение. После прохождения по всей строке мы отфильтровываем только те символы, которые встречаются больше одного раза.
Этот метод эффективен благодаря тому, что операции добавления и поиска элементов в словарь имеют среднюю временную сложность O(1). Таким образом, решение работает быстро, даже если строка большая.
Если вам нужно получить только символы без их количества, можно воспользоваться простым условием:
duplicates_only = [char for char, count in duplicates.items() if count > 1] print(duplicates_only)
Такой подход минимизирует сложность и позволяет легко идентифицировать повторяющиеся символы без лишних вычислений. Словарь помогает четко и быстро организовать поиск дубликатов, что делает его отличным инструментом для таких задач.
Использование коллекции Counter для поиска одинаковых символов
Коллекция Counter из модуля collections представляет собой удобный инструмент для подсчета повторяющихся элементов в коллекциях, таких как строки, списки или кортежи. В случае поиска одинаковых символов в строке Counter автоматически подчитывает количество каждого символа и позволяет эффективно выявить повторяющиеся элементы.
Для начала работы с Counter, достаточно импортировать его и передать строку как аргумент. Например:
from collections import Counter
строка = "aabbccddeeff"
counter = Counter(строка)
print(counter)Counter({'a': 2, 'b': 2, 'c': 2, 'd': 2, 'e': 2, 'f': 2})С помощью Counter легко найти символы, которые встречаются больше одного раза. Для этого достаточно фильтровать результат по значениям, превышающим 1:
повторяющиеся = {символ: count for символ, count in counter.items() if count > 1}
print(повторяющиеся)В данном случае результатом будет:
{'a': 2, 'b': 2, 'c': 2, 'd': 2, 'e': 2, 'f': 2}Для более сложных операций, таких как поиск самых часто встречающихся символов, можно использовать метод most_common(). Этот метод возвращает список кортежей, где каждый кортеж состоит из символа и его частоты. Например:
часто_встречающиеся = counter.most_common(3)
print(часто_встречающиеся)Если строка состоит из множества различных символов, это поможет выявить, какие из них встречаются наиболее часто. Counter делает эту задачу намного проще, чем использование стандартных циклов и условий.
Таким образом, использование Counter в Python позволяет значительно упростить процесс поиска одинаковых символов в строках и других коллекциях. Этот инструмент идеально подходит для задач, связанных с подсчетом частоты элементов, и может быть легко адаптирован для более сложных задач обработки данных.
Как найти повторяющиеся символы без дополнительных библиотек
Метод 1: Использование словаря. Словарь позволяет эффективно подсчитать количество каждого символа. Если символ встречается более одного раза, он будет добавлен в список повторяющихся символов.
string = "programming"
repeated_chars = {}
for char in string:
if char in repeated_chars:
repeated_chars[char] += 1
else:
repeated_chars[char] = 1
result = [char for char, count in repeated_chars.items() if count > 1]
print(result)
Этот код создает словарь, где ключом является символ, а значением – количество его вхождений. После того как строка обработана, повторяющиеся символы фильтруются с помощью list comprehension.
Метод 2: Использование множества. Множество удобно для отслеживания уникальных символов. В данном случае мы будем собирать уже встреченные символы в одном множестве, а повторяющиеся добавлять в другое.
string = "programming" seen = set() repeated = set() for char in string: if char in seen: repeated.add(char) else: seen.add(char) print(repeated)
В этом случае два множества помогают эффективно решать задачу: одно отслеживает все уникальные символы, а второе – символы, которые появляются несколько раз. Это решение быстро работает, так как операции с множествами выполняются за время O(1).
Оба метода не требуют внешних библиотек и являются эффективными. Выбор зависит от ваших предпочтений: если нужно сохранить количество повторений, лучше использовать словарь. Если важно только выявить повторяющиеся символы, удобнее работать с множествами.
Алгоритм поиска одинаковых символов с использованием множества
Для нахождения одинаковых символов в строке можно эффективно использовать множество (set). Множество предоставляет удобный способ выявления уникальных элементов, благодаря чему проверка на дублирование символов в строке становится быстрой и с минимальными затратами памяти.
Пример реализации:
def find_duplicates(s): seen = set() duplicates = set() for char in s: if char in seen: duplicates.add(char) else: seen.add(char) return duplicates
В этом коде переменная seen отвечает за хранение уже встреченных символов, а duplicates – за хранение повторяющихся. При переборе строки добавляем символы в seen, и если символ уже есть, добавляем его в duplicates.
Алгоритм имеет линейную сложность O(n), где n – длина строки, что делает его быстрым и масштабируемым для работы с большими данными.
Кроме того, использование множества позволяет избежать проблем с дублированием данных и улучшить производительность по сравнению с более сложными алгоритмами, использующими дополнительные структуры данных или циклы для поиска повторов.
Поиск одинаковых символов с сохранением их позиций в строке
Для поиска одинаковых символов в строке и сохранения их позиций можно использовать различные подходы. Рассмотрим один из наиболее эффективных способов с помощью словаря, который позволит сохранить индексы каждого символа.
Основная цель – не просто найти повторяющиеся символы, а сохранить информацию о том, где именно в строке эти символы встречаются. Это особенно полезно при анализе текста, где важны не только сами символы, но и их расположение.
Примерный алгоритм:
- Итерация по каждому символу строки.
- Использование словаря для сохранения позиций символов.
- Если символ встречается снова, добавление его индекса в список позиций.
Пример кода на Python:
def find_duplicates_with_positions(s):
positions = {}
for index, char in enumerate(s):
if char in positions:
positions[char].append(index)
else:
positions[char] = [index]
return {char: pos for char, pos in positions.items() if len(pos) > 1}
string = "programming"
result = find_duplicates_with_positions(string)
print(result)
В данном примере функция find_duplicates_with_positions возвращает словарь, где ключ – это символ, а значение – список индексов его вхождений в строку.
На выходе можно получить, например, такой результат:
{'r': [2, 3], 'g': [6, 9], 'm': [4, 7]}
Этот результат означает, что символ ‘r’ встречается на позициях 2 и 3, символ ‘g’ – на позициях 6 и 9, а символ ‘m’ – на позициях 4 и 7.
Для улучшения работы с большим объемом данных можно использовать коллекцию defaultdict из модуля collections, которая автоматически создаёт список для каждого нового ключа, тем самым избавляя от необходимости проверять наличие ключа в словаре:
from collections import defaultdict
def find_duplicates_with_positions(s):
positions = defaultdict(list)
for index, char in enumerate(s):
positions[char].append(index)
return {char: pos for char, pos in positions.items() if len(pos) > 1}
Этот вариант кода будет работать так же, но с чуть более чистым и коротким синтаксисом.
Такие методы поиска и хранения позиций символов полезны, когда необходимо анализировать частоту появления символов или отслеживать их расположение в строках, например, при решении задач по обработке текста, верификации данных или анализе кодов.
Как отсортировать строку для упрощения поиска одинаковых символов
Для поиска одинаковых символов в строке можно применить сортировку. Это упрощает задачу, так как одинаковые символы будут расположены рядом, и их можно будет быстро выявить. Вот несколько способов, как отсортировать строку в Python и оптимизировать процесс поиска.
Для начала можно использовать встроенную функцию sorted(), которая возвращает отсортированный список символов строки. Для дальнейшей работы строку можно преобразовать обратно в строку с помощью метода join().
- Пример сортировки строки с использованием
sorted():
input_string = "example"
sorted_string = ''.join(sorted(input_string))
print(sorted_string) # "aeelmpx"После сортировки символы строки будут расположены в алфавитном порядке. Теперь, чтобы найти одинаковые символы, достаточно пройти по строке и сравнить соседние символы.
- Для поиска одинаковых символов можно использовать следующий алгоритм:
input_string = "example"
sorted_string = ''.join(sorted(input_string))
for i in range(1, len(sorted_string)):
if sorted_string[i] == sorted_string[i - 1]:
print(f"Повторяющийся символ: {sorted_string[i]}")- Сортировка строки помогает ускорить поиск одинаковых символов, так как после упорядочивания все одинаковые символы будут стоять рядом, что сокращает количество необходимых сравнений.
- Если строка большая, сортировка с помощью
sorted()имеет сложность O(n log n), что является эффективным решением для большинства случаев. - Для дополнительной оптимизации можно использовать структуру данных, такую как словарь или коллекцию
Counterдля подсчета вхождений символов в строке.
Таким образом, сортировка строки – это простой и эффективный способ упорядочить данные, что делает дальнейший поиск одинаковых символов более быстрым и наглядным.
Поиск повторяющихся символов с учетом регистра
Для поиска повторяющихся символов в строке с учетом регистра важно помнить, что символы, отличающиеся только регистром, считаются разными. Например, символы «A» и «a» будут восприниматься как два разных символа. Чтобы эффективно найти такие символы, можно использовать различные подходы с учетом чувствительности к регистру.
Один из распространенных методов – использование словаря для подсчета частоты появления каждого символа в строке. Словарь позволяет быстро проверять, сколько раз встречается тот или иной символ. Важно помнить, что при учете регистра мы должны обрабатывать строку без изменений, то есть символы «A» и «a» не должны быть приведены к одному виду.
Пример кода:
text = "aAbBcCaa"
frequency = {}
for char in text:
if char in frequency:
frequency[char] += 1
else:
frequency[char] = 1
repeated_chars = {char: count for char, count in frequency.items() if count > 1}
print(repeated_chars)
Этот код создает словарь, в котором ключами являются символы строки, а значениями – их частота. После чего мы фильтруем те символы, которые встречаются больше одного раза. В данном примере результат будет следующим: {‘a’: 3, ‘A’: 1, ‘b’: 1, ‘c’: 1}, что говорит о том, что символ «a» встречается 3 раза, а остальные – по одному разу.
Для улучшения читаемости кода и производительности также можно воспользоваться встроенными средствами Python, такими как collections.Counter, который сразу возвращает частоту символов в строке в виде словаря.
from collections import Counter
text = "aAbBcCaa"
counter = Counter(text)
repeated_chars = {char: count for char, count in counter.items() if count > 1}
print(repeated_chars)
Этот вариант более лаконичен и также позволяет легко отфильтровывать повторяющиеся символы. Важно, что использование таких методов позволяет легко и быстро обрабатывать строки любой длины и правильно учитывать регистр символов.
Оптимизация поиска одинаковых символов для больших строк
При работе с большими строками в Python поиск одинаковых символов может стать затратной операцией, особенно если строка содержит миллионы символов. Для эффективного решения этой задачи важно минимизировать количество проверок и снизить временные затраты.
Один из самых простых способов оптимизации – использование структуры данных, таких как множества или словарь, которые обеспечивают быстрый доступ к элементам. Множества, в отличие от списков, обеспечивают среднее время доступа O(1), что значительно ускоряет поиск одинаковых символов по сравнению с проверкой каждого символа на каждом шаге.
Рассмотрим пример использования множества для поиска одинаковых символов:
def find_duplicates(string):
seen = set()
duplicates = set()
for char in string:
if char in seen:
duplicates.add(char)
seen.add(char)
return duplicates
Этот алгоритм имеет сложность O(n), где n – это длина строки. Мы проходим по строке один раз, при этом добавление и проверка наличия элемента в множестве выполняется за постоянное время.
Если важна не только скорость, но и экономия памяти, можно использовать подход, который комбинирует несколько структур данных. Например, можно использовать словарь для подсчета частоты символов, что позволит одновременно находить одинаковые символы и учитывать их количество в строке.
from collections import defaultdict
def find_duplicates_with_count(string):
count = defaultdict(int)
for char in string:
count[char] += 1
return {char: count[char] for char in count if count[char] > 1}
Этот метод также имеет сложность O(n), но помимо дублированных символов, он позволяет получить информацию о количестве их вхождений, что может быть полезно в некоторых сценариях.
Для еще большей оптимизации в случаях, когда строка огромна, можно применить подходы с использованием потоковой обработки данных, такие как сортировка с дальнейшим поиском подряд идущих одинаковых символов или использование алгоритмов с фиксированным количеством памяти, например, алгоритмы типа кратного прохода, которые минимизируют использование памяти на больших объемах данных.
Важно помнить, что оптимизация всегда зависит от контекста задачи. Если требуется минимизировать время работы, то предпочтительнее использовать множества или словари. Однако если задача требует учета частоты вхождений, словарь окажется более полезным инструментом, несмотря на небольшое увеличение потребления памяти.
Вопрос-ответ:
Как найти одинаковые символы в строке на Python?
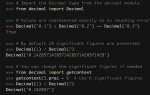
Чтобы найти одинаковые символы в строке, можно использовать различные методы. Один из них — это использование словаря для подсчета количества каждого символа в строке. Например, с помощью встроенной функции `collections.Counter` можно быстро посчитать все символы и найти те, которые встречаются более одного раза.
Как можно найти все повторяющиеся символы в строке Python?
Для поиска всех повторяющихся символов в строке, можно создать счетчик с использованием модуля `collections`. После того как мы подсчитаем количество каждого символа, можно пройтись по этому счетчику и выбрать только те символы, которые встречаются больше одного раза. Пример кода:
Как избавиться от повторяющихся символов в строке на Python?
Для удаления повторяющихся символов в строке можно использовать множество (set), которое автоматически исключает дубли. Например, преобразуем строку в множество, а затем обратно в строку: `».join(set(строка))`. Однако такой способ не сохраняет порядок символов. Если порядок важен, можно использовать цикл и проверку на присутствие символа в новом списке.
Каким образом можно посчитать количество одинаковых символов в строке Python?
Для подсчета количества одинаковых символов в строке удобно использовать модуль `collections` и его класс `Counter`. Этот класс создает словарь, в котором ключами будут символы строки, а значениями — количество их появлений. Например, `from collections import Counter; result = Counter(‘строка’)`, и результатом будет словарь, в котором указано, сколько раз встречается каждый символ.
Как в Python найти символы, которые встречаются больше одного раза в строке?
Чтобы найти символы, встречающиеся более одного раза в строке, можно использовать модуль `collections.Counter`. После подсчета символов можно отфильтровать те, у которых значение больше 1. Пример кода: