Оконные функции в SQL позволяют выполнять агрегирование без потери детализации строк. Они открывают доступ к таким операциям, как ранжирование, накопление, скользящие суммы и вычисление долей от общего значения, без необходимости в подзапросах или объединениях. Это особенно актуально при построении аналитических отчетов и работе с временными рядами.
В отличие от агрегатных функций, оконные сохраняют видимость всех строк в результирующем наборе. Например, с помощью ROW_NUMBER() можно пронумеровать строки внутри каждой группы, заданной через PARTITION BY, а функция SUM() OVER позволяет получить кумулятивную сумму без объединения таблицы с собой.
Для оптимальной производительности критично правильно определить окно – PARTITION BY и ORDER BY влияют как на результат, так и на ресурсоемкость выполнения запроса. В случае больших выборок рекомендуется использовать оконные функции совместно с индексами на поля сортировки и группировки, а также избегать ненужного пересчёта оконных выражений.
Оконные функции поддерживаются в PostgreSQL, SQL Server, Oracle, MySQL (с версии 8.0) и других СУБД. Однако синтаксис и поведение некоторых функций может отличаться, особенно при работе с FRAME – диапазоном, в пределах которого вычисляется результат. Точное понимание границ кадров – ключ к корректным и эффективным аналитическим запросам.
Сравнение оконных функций с агрегатными: когда и что использовать
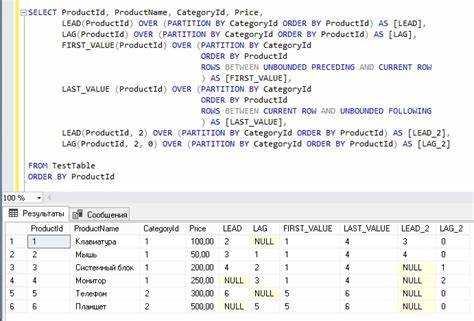
Агрегатные функции и оконные используются для анализа данных, но различаются по области применения и результату. Агрегатные функции группируют строки, возвращая одну строку на группу. Оконные сохраняют строку и добавляют вычисленное значение на её основе.
- Используйте агрегатные функции, если необходимо получить обобщённые значения: сумму, среднее, максимум, минимум или количество по группам. Пример – подсчёт заказов на клиента.
- Используйте оконные функции, если нужно сравнить строку с другими в пределах набора: определить место в рейтинге, найти предыдущие или последующие значения, подсчитать накопительный итог.
Примеры применения:
- Агрегатная функция:
SELECT customer_id, COUNT(*) FROM orders GROUP BY customer_id– вернёт одну строку на каждого клиента. - Оконная функция:
SELECT order_id, customer_id, COUNT(*) OVER (PARTITION BY customer_id) FROM orders– добавит количество заказов клиента в каждую строку.
Оконные функции предпочтительны, когда нужно:
- Сравнить строки внутри группы (например, рейтинг продаж)
- Сохранить все строки, добавляя агрегированные значения без группировки
- Рассчитать скользящее среднее или накопительную сумму
Избегайте оконных функций, если задача – простая агрегация без необходимости отображения всех строк. Они менее эффективны при большом объёме данных, если используется без индексов и фильтров.
Как вычислить скользящее среднее с помощью оконной функции

Для расчёта скользящего среднего по числовому столбцу используется оконная функция AVG() в сочетании с конструкцией OVER(ROWS BETWEEN ...). Это позволяет получить среднее значение в пределах заданного окна строк без необходимости объединения таблицы с самой собой.
Пример: вычисление 7-дневного скользящего среднего продаж по дате:
SELECT
date,
sales,
AVG(sales) OVER (
ORDER BY date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS moving_avg_7d
FROM sales_data;Окно ROWS BETWEEN 6 PRECEDING AND CURRENT ROW определяет диапазон из текущей строки и шести предыдущих. Это строгое определение окна по количеству строк, что важно в случае, если данные имеют пропуски в датах.
Для учета только предыдущих значений без текущего можно использовать ROWS BETWEEN 6 PRECEDING AND 1 PRECEDING. Это полезно при прогнозировании, где значение текущего дня исключается.
Если необходимо сглаживание по конкретному интервалу времени, а не по числу строк, вместо ROWS используется RANGE, но только если тип сортируемого столбца позволяет интерпретировать значения как диапазон (например, DATE или TIMESTAMP).
Важно: при наличии повторяющихся значений сортируемого столбца RANGE включает все строки с тем же значением, тогда как ROWS – только указанное количество. Это влияет на точность сглаживания, особенно при группировке по дате с множественными записями на один день.
Для повышения читаемости запроса и повторного использования можно вынести окно в отдельное имя:
WINDOW w AS (
ORDER BY date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
)И использовать так:
AVG(sales) OVER w AS moving_avgСкользящее среднее, вычисленное таким способом, эффективно и масштабируемо, особенно при анализе больших объемов временных рядов.
Пронумеровка строк с использованием ROW_NUMBER и порядок сортировки

Пример использования:
SELECT ROW_NUMBER() OVER (ORDER BY salary DESC) AS rank, employee_name FROM employees
Этот запрос назначает первичный номер строкам в порядке убывания зарплаты. Самая высокая зарплата получает ранг 1. Наличие ORDER BY в OVER() критично: именно он определяет логику нумерации.
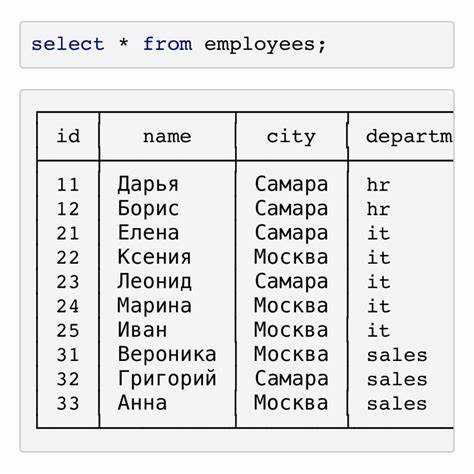
Если необходимо сбросить нумерацию внутри групп, используется PARTITION BY. Например:
SELECT ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY hire_date ASC) AS row_num, employee_name FROM employees
В этом случае нумерация начинается заново для каждого департамента, сортируясь по дате найма. Сортировка должна быть определена однозначно. Если порядок не уникален (например, одинаковые даты), добавляйте дополнительные поля: ORDER BY hire_date, employee_id.
ROW_NUMBER() полезна для пагинации. Например, выборка строк с 11 по 20:
SELECT * FROM (SELECT ROW_NUMBER() OVER (ORDER BY id) AS rn, * FROM products) AS t WHERE rn BETWEEN 11 AND 20
Четкая сортировка гарантирует предсказуемость результатов. Изменение порядка в ORDER BY немедленно меняет нумерацию. Всегда определяйте, по какому критерию происходит ранжирование, иначе возможны непоследовательные итоги при повторном выполнении запроса.
Фильтрация по результатам оконной функции: подводные камни
Главная сложность при фильтрации по результатам оконных функций заключается в порядке выполнения SQL-запроса. Оконные функции обрабатываются после оператора WHERE, поэтому фильтровать по их результатам напрямую невозможно. Попытка использовать оконную функцию в WHERE вызовет ошибку синтаксиса.
Правильный подход – использование оконной функции в подзапросе или CTE. Например, если требуется отфильтровать строки с максимальным значением по группе, сначала необходимо рассчитать значение с помощью оконной функции MAX() OVER (PARTITION BY ...) во вложенном запросе, а затем применить фильтрацию во внешнем слое.
Избегайте дублирования логики оконной функции в разных частях запроса. Лучше сохранять результат в подзапросе с говорящим псевдонимом – это облегчает отладку и улучшает читаемость.
Фильтрация в HAVING не является альтернативой – этот оператор применяется после GROUP BY, а не после оконных функций. Аналогично, QUALIFY, доступный в некоторых СУБД (например, Snowflake, BigQuery), позволяет фильтровать сразу по оконным функциям, но это не стандарт SQL и не поддерживается, например, в PostgreSQL или SQL Server.
Особое внимание уделяйте производительности: из-за необходимости материализовать подзапросы, содержащие оконные функции, может резко вырасти нагрузка на память и диск. Всегда проверяйте планы выполнения запросов.
Использование оконных функций для нахождения разницы между строками

Оконные функции в SQL предоставляют мощный способ для вычисления разницы между значениями, расположенными в разных строках. Это может быть полезно при анализе временных рядов, подсчете изменений и других задачах, где необходимо сравнивать текущие и предыдущие строки данных.
Для нахождения разницы между строками используется функция LAG() или LEAD(), которые позволяют обратиться к значениям предыдущей или следующей строки в пределах текущего окна. Например, чтобы вычислить разницу между значениями в последовательных строках, можно воспользоваться функцией LAG() с последующим вычитанием.
Пример запроса для нахождения разницы между значениями в столбце value с использованием LAG():
SELECT id, value, value - LAG(value) OVER (ORDER BY id) AS difference FROM data;
В этом примере для каждой строки вычисляется разница между текущим значением в столбце value и значением в предыдущей строке, определенной через ORDER BY id. Если предыдущей строки нет, результат будет NULL.
Аналогично, функция LEAD() позволяет вычислить разницу с будущими значениями. Например, для нахождения разницы с последующим значением в столбце:
SELECT id, value, LEAD(value) OVER (ORDER BY id) - value AS difference FROM data;
Это решение особенно полезно, если необходимо анализировать изменения в данных с временной зависимостью, например, для вычисления изменений между текущими и следующими значениями.
Чтобы избежать NULL значений в результате, можно использовать COALESCE() для замены NULL на 0 или другое значение, что обеспечит более корректные результаты в вычислениях:
SELECT id, value, COALESCE(value - LAG(value) OVER (ORDER BY id), 0) AS difference FROM data;
Таким образом, использование оконных функций для нахождения разницы между строками предоставляет гибкие инструменты для анализа данных, позволяя легко учитывать как прошлые, так и будущие значения, а также управлять исключениями и невалидными результатами.
Применение PARTITION BY для группировки в пределах окна
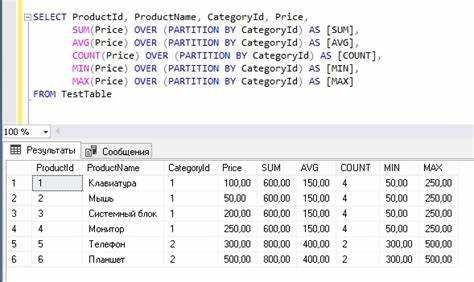
Оконная функция PARTITION BY позволяет разделить результаты запроса на логические группы, не изменяя структуру данных, что важно для выполнения аналитических операций. Это особенно полезно, когда необходимо выполнять вычисления в пределах каждой группы без применения явных подзапросов или агрегаций.
Когда используется PARTITION BY, данные делятся на сегменты, в пределах которых вычисляются оконные функции. Каждая группа данных обрабатывается независимо, а результат возвращается с сохранением исходной строки, что открывает возможности для детализированных аналитических расчетов, таких как вычисление рангов, сумм или средней величины по каждой группе.
Пример: в запросе ниже используется оконная функция ROW_NUMBER() с PARTITION BY для нумерации сотрудников в каждой департаменте по их зарплате, начиная с самой высокой:
SELECT employee_id, department_id, salary, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) AS salary_rank FROM employees;
В этом запросе PARTITION BY department_id разделяет данные на группы по каждому департаменту. Результат функции ROW_NUMBER() показывает порядковый номер сотрудника внутри департамента, где на первом месте окажется сотрудник с самой высокой зарплатой.
Важное преимущество использования PARTITION BY заключается в том, что оно позволяет работать с большими объемами данных, разделяя их на более мелкие и логически связанные группы. Например, при анализе продаж по регионам можно использовать PARTITION BY для вычисления суммарных продаж или среднего дохода по каждому региону, не выполняя агрегацию на уровне всего набора данных.
Другим примером может быть вычисление скользящего среднего для продаж по каждому продукту. При этом, используя PARTITION BY, мы можем рассчитать средние значения, не затрагивая другие товары:
SELECT product_id, sales_date, sales_amount, AVG(sales_amount) OVER (PARTITION BY product_id ORDER BY sales_date ROWS BETWEEN 4 PRECEDING AND CURRENT ROW) AS moving_avg FROM sales;
Здесь PARTITION BY product_id гарантирует, что скользящее среднее будет рассчитываться для каждого продукта отдельно. Функция AVG() с указанным окном возвращает среднее значение продаж за последние 5 дней, включая текущий день, для каждого продукта.
Внедрение PARTITION BY в запросы помогает избегать сложных подзапросов, упрощая логику и улучшая производительность. При этом можно обрабатывать большое количество данных, сохраняя гибкость и точность вычислений, что критично для аналитических и отчетных систем.
Вопрос-ответ:
Что такое оконные функции в SQL и как они работают?
Оконные функции в SQL — это функции, которые выполняются над группой строк, определяемой в окне (разделе) данных. В отличие от агрегатных функций, таких как `SUM()` или `AVG()`, которые сводят несколько строк в одну, оконные функции могут работать с набором строк, сохраняя их индивидуальность. Окно определяется с помощью предложения `OVER()`, в котором можно указать параметры, такие как `PARTITION BY` (разделение на группы) и `ORDER BY` (порядок строк). Это позволяет применять функции, такие как вычисление скользящих средних, рангов и т.д., не теряя контекста строк.
Как используется оконная функция RANK() и в чем ее отличие от функции ROW_NUMBER()?
Функция `RANK()` используется для присвоения строкам ранга в пределах группы, определенной в окне. Ранги могут повторяться, если значения одинаковые. Например, если два человека имеют одинаковые баллы, оба получат одинаковый ранг, а следующий ранг будет пропущен. В отличие от этого, функция `ROW_NUMBER()` всегда присваивает уникальный номер строкам, даже если значения в строках одинаковые. Это означает, что с `ROW_NUMBER()` не будет повторяющихся номеров. Выбор между этими функциями зависит от того, нужно ли вам учитывать одинаковые значения в расчетах.
Какие примеры задач можно решить с помощью оконных функций?
Оконные функции полезны для решения различных задач, таких как подсчет скользящих средних, вычисление рангов, анализ временных рядов, вычисление кумулятивных сумм и многое другое. Например, с помощью функции `SUM() OVER()` можно вычислить кумулятивную сумму продаж по месяцам. Также с помощью `ROW_NUMBER()` можно выбрать уникальные строки в таблице, игнорируя повторяющиеся значения, что полезно при работе с отчетами и списками. Аналогично, для вычисления разницы между текущей строкой и предыдущей часто используется функция `LAG()`.
Как правильно использовать PARTITION BY в оконных функциях?
Использование `PARTITION BY` позволяет разделить набор строк на несколько групп для применения оконной функции в каждой группе отдельно. Например, если нужно посчитать рейтинг студентов по предметам, то можно использовать `PARTITION BY subject` в функции `RANK()`, чтобы ранжировать студентов по каждому предмету, а не по всем сразу. Это ключевая возможность оконных функций, так как она помогает более точно организовать обработку данных, сохраняя контекст каждой группы.
Можно ли использовать несколько оконных функций в одном запросе?
Да, в одном запросе можно использовать несколько оконных функций, каждая из которых может иметь свое собственное окно. Например, можно вычислить кумулятивную сумму и ранжировать строки одновременно. Для этого необходимо указать разные оконные функции с предложением `OVER()` и при необходимости использовать разные `PARTITION BY` и `ORDER BY` для каждого окна. Это позволяет создавать сложные аналитические запросы без необходимости многократного повторения данных или использования подзапросов.