Извлечение PDF документов из SQL базы данных – это частая задача, с которой сталкиваются разработчики и администраторы баз данных. Этот процесс включает в себя извлечение бинарных данных, хранящихся в базе данных в формате BLOB (Binary Large Object), и преобразование их обратно в документ, доступный для просмотра или дальнейшего использования. Для эффективного выполнения этой задачи важно правильно выбрать методы работы с базой данных и обеспечить корректное извлечение данных.
Существует несколько способов хранения PDF файлов в базе данных, однако наиболее распространённый – это использование типа данных BLOB. Важным аспектом является правильная настройка структуры базы данных, так как работа с большими файлами может существенно повлиять на производительность. Для извлечения документа из SQL базы данных необходимо использовать SQL-запросы, которые извлекают бинарные данные и передают их в нужный формат, такой как файл на сервере или в приложении.
Основной вызов при извлечении PDF документов заключается в корректной обработке бинарных данных. Необходимо обеспечить точность и целостность данных, а также учитывать возможные ошибки при извлечении, такие как повреждение данных или проблемы с кодировкой. Также важно учитывать особенности работы с транзакциями и их влияние на целостность данных при извлечении документов в реальном времени.
Для упрощения задачи, можно использовать библиотеку, которая позволяет автоматизировать процесс извлечения и преобразования данных из BLOB в файл. Важно помнить, что размер извлекаемого PDF файла также может стать проблемой, особенно в случае хранения больших документов. Рекомендуется предварительно настроить лимиты на размер данных, извлекаемых за один запрос, чтобы избежать возможных перегрузок системы.
Как сохранить PDF в базу данных: выбор формата и методов
Выбор между сохранением файла в виде строки или бинарного потока данных зависит от специфики приложения и объема данных. Когда речь идет о больших объемах информации или сложных файлах, бинарное представление предпочтительнее. Это связано с более эффективным использованием ресурсов, поскольку исключается необходимость кодирования и декодирования данных, что экономит время и снижает нагрузку на систему.
Однако, если необходимо сделать данные доступными для быстрого чтения без извлечения файла, стоит рассмотреть возможность сохранения PDF как строку в формате base64. Этот подход удобен для хранения документов в JSON-объектах и передачи их через веб-сервисы, но он увеличивает размер данных примерно на 33%, что делает его менее эффективным для хранения больших файлов в базе данных.
При реализации хранения PDF важно учитывать следующие аспекты:
- Размер файла: Для крупных PDF-документов (более 10-20 МБ) использование базы данных для хранения таких данных может повлиять на производительность системы. В таких случаях рекомендуется использовать файловую систему для хранения PDF с указанием пути к файлу в базе данных.
- Частота доступа: Если к файлам часто обращаются, стоит оптимизировать индексацию и структуру таблиц, чтобы ускорить извлечение документов.
- Безопасность: Для повышения уровня безопасности можно использовать шифрование PDF-документов перед их сохранением в базе данных, что поможет защитить чувствительные данные от несанкционированного доступа.
- Целостность данных: Хранение больших файлов в базе данных требует обеспечения высокой надежности при сохранении и извлечении данных. Регулярное резервное копирование и мониторинг базы данных помогут избежать потерь.
Практическим примером сохранения PDF в базу данных является следующий процесс. Для MySQL это может выглядеть так:
CREATE TABLE documents (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255),
file_data LONGBLOB
);
-- Сохранение PDF
INSERT INTO documents (name, file_data)
VALUES ('document.pdf', LOAD_FILE('/path/to/document.pdf'));
Этот пример демонстрирует использование функции LOAD_FILE, которая загружает PDF в столбец типа LONGBLOB. При необходимости можно интегрировать такие механизмы с веб-приложениями через API для загрузки и извлечения данных.
Для PostgreSQL аналогичный процесс будет требовать использования типа данных BYTEA:
CREATE TABLE documents ( id SERIAL PRIMARY KEY, name VARCHAR(255), file_data BYTEA ); -- Сохранение PDF COPY documents(name, file_data) FROM '/path/to/document.pdf' WITH (FORMAT binary);
Использование BLOB или BYTEA – это универсальный способ, но важно помнить, что базы данных не предназначены для хранения больших медиафайлов. В случае больших объемов данных лучше использовать внешнее хранилище, а в базе данных сохранять лишь ссылки на файлы, что позволит избежать перегрузки системы.
Настройка соединения с базой данных для извлечения PDF
Для эффективного извлечения PDF документов из SQL базы данных важно правильно настроить соединение. В качестве примера рассмотрим использование библиотеки для работы с MySQL, такой как MySQL Connector для Python. Первым шагом будет установка необходимых пакетов. Используйте команду pip install mysql-connector-python, чтобы установить библиотеку.
Далее, для установления соединения с базой данных, вам нужно предоставить данные для подключения: хост, имя базы данных, пользователь и пароль. Пример кода на Python для создания соединения:
import mysql.connector connection = mysql.connector.connect( host="localhost", user="your_username", password="your_password", database="your_database" )
После успешного соединения, вам необходимо проверить, что база данных доступна, и есть ли в ней нужные таблицы и столбцы, содержащие PDF документы. Это можно сделать с помощью простого запроса:
cursor = connection.cursor()
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
for table in tables:
print(table)
В случае с PDF документами, обычно данные хранятся в бинарном формате в одном из столбцов таблицы. Для извлечения данных из такого столбца используйте SQL запрос, который извлечет BLOB (Binary Large Object) данные. Пример запроса для извлечения PDF:
cursor.execute("SELECT pdf_column FROM pdf_table WHERE id = %s", (pdf_id,))
pdf_data = cursor.fetchone()[0]
Где pdf_column – это название столбца, в котором хранится PDF, а pdf_table – таблица с документами. Далее, извлеченные бинарные данные можно сохранить в файл на диске или обработать соответствующим образом. Например, для сохранения файла:
with open("output.pdf", "wb") as file:
file.write(pdf_data)
Завершающим шагом будет закрытие соединения с базой данных. Для этого используйте метод close():
cursor.close() connection.close()
Таким образом, настройка соединения с базой данных для извлечения PDF документов включает установку соединения, выполнение SQL запросов для извлечения бинарных данных и сохранение результата в файл. Все эти этапы позволяют эффективно работать с документами, хранящимися в SQL базе данных.
Извлечение PDF документа из поля BLOB или VARBINARY
Для извлечения PDF документа из поля типа BLOB или VARBINARY в SQL базе данных необходимо правильно настроить взаимодействие между базой данных и приложением, используя соответствующие средства доступа и обработки данных. Важно понимать, что BLOB (Binary Large Object) и VARBINARY используются для хранения двоичных данных, включая файлы, изображения и документы, такие как PDF.
Процесс извлечения данных из этих типов полей включает несколько этапов. Первым шагом является выбор данных из базы данных. Например, можно использовать SQL-запрос вида:
SELECT pdf_data FROM documents WHERE doc_id = 1;Здесь pdf_data – это поле типа BLOB или VARBINARY, где хранится PDF файл, а doc_id – идентификатор документа. Запрос вернет двоичные данные, которые необходимо корректно обработать в приложении.
Для работы с данными в приложении, обычно используется язык программирования, поддерживающий работу с базами данных и двоичными данными. Например, в языке Python можно использовать библиотеку pymysql или pyodbc для работы с MySQL или MS SQL Server. Пример извлечения PDF документа с использованием Python:
import pymysql
connection = pymysql.connect(host='localhost', user='user', password='password', database='database')
cursor = connection.cursor()
cursor.execute("SELECT pdf_data FROM documents WHERE doc_id = 1")
pdf_data = cursor.fetchone()[0]
with open('output.pdf', 'wb') as file:
file.write(pdf_data)
cursor.close()
connection.close()В данном примере из базы данных извлекается двоичный поток PDF файла и сохраняется в локальный файл с расширением .pdf.
При извлечении данных важно учитывать размер файла. В случае работы с большими PDF документами могут возникнуть проблемы с производительностью и ограничениями на размер данных. В таких ситуациях рекомендуется использовать потоковую обработку данных, извлекая файл по частям, что предотвращает перегрузку памяти.
Также стоит помнить о безопасности: перед извлечением и обработкой данных из BLOB или VARBINARY необходимо убедиться в их подлинности, чтобы избежать рисков выполнения вредоносного кода, особенно если база данных была подвергнута атаке.
Использование SQL-запросов для получения данных PDF
Для извлечения PDF-документов из базы данных SQL, данные обычно сохраняются в поле типа BLOB (Binary Large Object). Этот тип данных позволяет хранить двоичные данные, включая PDF-файлы. Для получения и обработки таких данных используется несколько методов SQL-запросов, в зависимости от структуры базы данных и используемой СУБД.
Основной запрос для извлечения PDF-файла из базы данных включает выборку данных из поля типа BLOB. Например, запрос для извлечения PDF-файла может выглядеть так:
SELECT pdf_file_column FROM documents WHERE document_id = 123;Здесь pdf_file_column – это колонка типа BLOB, в которой хранится сам PDF-файл, а document_id – это уникальный идентификатор записи. Для успешного извлечения важно убедиться, что размер поля BLOB достаточно велик, чтобы вместить весь документ.
В некоторых случаях SQL-запросы могут также включать преобразования, если необходимо извлечь данные в определённом формате. Например, при использовании MySQL, для работы с BLOB данными часто используют функции, такие как HEX() или CAST(), чтобы преобразовать двоичные данные в читаемый формат.
SELECT HEX(pdf_file_column) FROM documents WHERE document_id = 123;Это позволяет получить данные в виде строки шестнадцатеричного кода, который затем можно расшифровать и преобразовать в исходный PDF-файл при помощи соответствующего приложения.
Для работы с большими файлами можно использовать механизмы извлечения данных по частям, так как SQL-запросы могут быть ограничены размером передаваемых данных. Например, можно использовать операторы LIMIT или OFFSET, чтобы разделить извлечение на несколько этапов и эффективно обрабатывать большие объемы данных.
Также стоит отметить важность безопасности при извлечении файлов из базы данных. Для предотвращения атак, связанных с загрузкой и извлечением файлов, рекомендуется использовать проверку типа файла и размера, а также ограничить доступ к данным только авторизованным пользователям.
После извлечения данных через SQL-запрос, полученные двоичные данные можно сохранить в файл на локальном диске или сразу передать пользователю через веб-интерфейс. В случае с веб-приложениями, для передачи PDF-файла часто используется механизм Content-Disposition для загрузки файла:
Content-Disposition: attachment; filename="document.pdf"Таким образом, использование SQL-запросов для извлечения PDF-документов из базы данных требует точного понимания структуры данных и правильной работы с двоичными объектами, что позволяет эффективно управлять и передавать файлы в приложениях.
Конвертация бинарных данных в PDF файл на стороне сервера
Для извлечения PDF-документа из базы данных необходимо использовать подходящие средства работы с бинарными данными в SQL. Примером может быть использование SQL-запроса, который извлекает поле с типом данных BLOB. Важно, чтобы код сервера был готов правильно интерпретировать эти данные и передавать их в нужном формате.
Один из распространённых подходов для конвертации заключается в использовании языков программирования, таких как Python, Java или C#, которые предоставляют библиотеки для работы с бинарными данными и файловыми форматами. Например, в Python можно использовать библиотеку `PyPDF2` или `reportlab`, которые позволяют работать с PDF-документами на высоком уровне. Для извлечения и записи данных можно применить библиотеку `sqlite3` для Python, чтобы извлечь BLOB из базы данных, а затем преобразовать в полноценный файл PDF.
В случае Java стоит обратить внимание на библиотеку iText. Эта библиотека предоставляет функционал для работы с PDF, включая создание, чтение и преобразование документов. Для извлечения данных из базы данных используется JDBC (Java Database Connectivity), и полученные бинарные данные передаются в соответствующий PDF-формат.
После извлечения данных из базы важно учитывать корректную работу с кодировками и возможные проблемы с ошибками в процессе конвертации. Проблемы могут возникать из-за неполных или повреждённых данных, что может повлиять на целостность финального файла. Также стоит обратить внимание на размер PDF-файла, так как при большом объёме данных может потребоваться дополнительная оптимизация процесса для предотвращения переполнения памяти или превышения лимита времени на выполнение запросов.
Для улучшения производительности и безопасности рекомендуется использовать потоковую обработку данных при конвертации. Это позволяет эффективно работать с большими объёмами данных, избегая загрузки всего файла в память, что критично для серверных решений с ограниченными ресурсами. Важно также обеспечить надёжное завершение операций с файлами, чтобы исключить потерю данных при ошибках или сбоях системы.
Таким образом, конвертация бинарных данных в PDF файл на серверной стороне требует внимания к деталям на всех этапах процесса – от извлечения данных из базы до записи окончательного документа. Выбор подходящих инструментов и правильное управление ресурсами помогает обеспечить стабильную и эффективную работу сервера с PDF-документами.
Обработка ошибок при извлечении PDF из базы данных
Одной из частых ошибок является неверная кодировка данных, особенно если PDF сохранён в базе данных как BLOB. В таких случаях необходимо использовать корректные функции для декодирования данных перед их восстановлением в исходный формат. Проблемы с кодировкой могут привести к повреждению файла или его некорректному отображению.
Для предотвращения ошибок при извлечении важно контролировать типы данных, хранимых в базе. Например, использование параметрических запросов с проверкой типов данных помогает избежать ошибок, связанных с несовпадением типа столбца и фактических данных. Если тип данных в запросе не совпадает с типом столбца, может возникнуть ошибка, связанная с неправильной десериализацией данных.
Ошибка может также возникнуть в случае повреждения данных при вставке PDF в базу. Это возможно, если процесс загрузки данных был прерван или не завершён корректно. Чтобы снизить риски, следует использовать транзакции для выполнения операций вставки и извлечения данных. В случае сбоя транзакция откатывается, и данные остаются целыми.
Другим распространённым случаем является превышение лимита памяти при извлечении большого файла. Базы данных и приложения имеют ограничения по объёму данных, которые можно извлечь за один запрос. Чтобы избежать ошибок, связанных с памятью, стоит использовать потоковое извлечение данных, позволяя загружать файл частями и избегать излишней загрузки оперативной памяти.
Не менее важной проблемой является обработка ситуаций, когда запрашиваемый PDF не существует в базе данных. Для таких случаев следует предусмотреть проверку наличия документа до попытки его извлечения. Простое условие на проверку наличия записи в базе данных перед запросом предотвратит ошибки, вызванные отсутствием данных.
Для обеспечения стабильности системы необходимо вести логи ошибок. Это поможет оперативно выявить и исправить возникшие проблемы. Логирование важно на всех этапах извлечения данных: от отправки запроса к базе до обработки самого документа. В логах должны фиксироваться не только ошибки, но и успешные операции, чтобы можно было проанализировать работу системы в целом.
Оптимизация процесса извлечения PDF для больших объемов данных
Извлечение PDF-документов из SQL баз данных с большими объемами информации требует применения эффективных методов для снижения нагрузки на систему и ускорения обработки данных. Рассмотрим ключевые подходы для оптимизации этого процесса.
- Использование потоковой передачи данных – для работы с большими PDF-документами, сохраненными в базе данных, рекомендуется использовать потоковое извлечение. Это позволяет извлекать данные по частям, не загружая весь документ в память сразу. Потоковая обработка снижает потребление памяти и позволяет работать с документами даже большого размера без риска переполнения памяти.
- Индексация и кеширование – создание индексированных столбцов для хранения метаданных PDF-документов ускоряет поиск и извлечение. Индексация по таким полям, как дата создания, автор или идентификатор, может значительно сократить время извлечения. Дополнительно использование кеша для хранения часто запрашиваемых документов снижает нагрузку на сервер и ускоряет доступ к данным.
- Хранение PDF в файловой системе – вместо хранения больших PDF-документов напрямую в базе данных можно сохранять их на файловом сервере, а в базе данных хранить только пути к этим файлам. Такой подход разгружает базу данных и уменьшает время извлечения, поскольку файловые системы могут обрабатывать данные быстрее, чем базы данных при работе с большими бинарными объектами.
- Использование асинхронных запросов – для извлечения данных без блокировки основного потока можно применить асинхронные запросы. Это позволяет системе продолжать выполнение других операций, пока идет извлечение PDF, а также улучшает масштабируемость системы.
- Параллельная обработка – для извлечения нескольких документов одновременно можно использовать многозадачность или параллельные потоки. Это особенно полезно в случаях, когда требуется извлечь данные из нескольких таблиц или по множеству идентификаторов, сокращая время ожидания.
- Сжатие данных – сохранение PDF в сжатом формате (например, с использованием алгоритмов типа gzip) позволяет значительно уменьшить размер файла в базе данных. Это снижает время извлечения, так как меньше данных нужно передать и обработать.
Внедрение этих методов позволяет значительно повысить производительность при работе с большими объемами PDF-документов в SQL базе данных. Выбор подхода зависит от конкретных условий эксплуатации и объема данных, однако комбинация этих стратегий гарантирует эффективную работу системы даже при интенсивных нагрузках.
Вопрос-ответ:
Как можно извлечь PDF документ, который хранится в SQL базе данных?
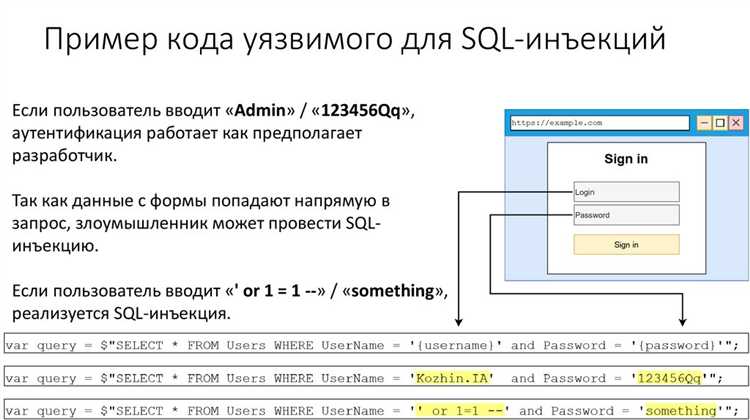
Для извлечения PDF документа из SQL базы данных, необходимо выполнить несколько шагов. Во-первых, нужно получить данные из соответствующей таблицы, где PDF хранится в бинарном формате. Обычно такие файлы сохраняются в столбцах типа BLOB (Binary Large Object). Затем можно использовать программное обеспечение или язык программирования (например, Python или Java), чтобы извлечь эти данные и сохранить их как PDF файл. На стороне базы данных можно использовать SELECT-запрос, чтобы извлечь данные из столбца BLOB. В коде программы нужно будет выполнить декодирование бинарных данных в файл с расширением .pdf.
Какие трудности могут возникнуть при извлечении PDF файлов из SQL базы данных?
Одной из главных трудностей является правильное извлечение данных в бинарном формате. Иногда кодировка или форматирование данных может быть повреждено, что приведет к невозможности восстановления файла. Также могут возникнуть проблемы с производительностью, если база данных содержит большое количество файлов или если запросы не оптимизированы. Другой момент — это безопасность, так как работа с бинарными данными требует аккуратности, чтобы избежать утечек или повреждения данных. Важно правильно настроить разрешения для доступа к таким данным.
Можно ли извлечь PDF файл с помощью SQL запросов без использования внешних программ?
SQL запросы сами по себе не позволяют напрямую сохранять файлы в формате PDF. Однако, с помощью SQL можно извлечь бинарные данные из столбца BLOB и передать их в приложение или скрипт, который будет ответственен за сохранение этих данных в файл. Таким образом, SQL будет использоваться для получения данных, но сохранение PDF требует программного кода, который обработает эти данные и запишет их в файл на диске.
Какие базы данных лучше подходят для хранения PDF файлов?
Для хранения PDF файлов в базе данных лучше всего подходят те, которые поддерживают тип данных BLOB, так как он предназначен для хранения больших двоичных объектов, включая изображения и документы. Популярные базы данных, такие как MySQL, PostgreSQL, Oracle и SQL Server, хорошо справляются с этим. Однако важно учитывать, что хранение больших файлов в базе данных может повлиять на производительность, поэтому в некоторых случаях лучше рассмотреть хранение файлов в файловой системе, а в базе данных только их метаданные.