Вычисление среднего значения в SQL запросах является одной из базовых операций при работе с данными. В SQL для этой задачи используется агрегатная функция AVG(), которая вычисляет среднее арифметическое для числовых данных в выбранном столбце. Однако, для корректного применения этой функции важно понимать, какие данные могут быть учтены, а какие будут исключены из расчёта.
Когда необходимо вычислить среднее значение, стоит учитывать несколько факторов. Во-первых, AVG() игнорирует NULL значения, что может значительно повлиять на результат, если в столбце есть пропуски. Во-вторых, для корректности вычислений важно применять функцию к нужному набору данных, например, с использованием GROUP BY, если требуется разделить вычисление по определённым категориям.
Кроме того, стоит учитывать тип данных, который используется в столбце. Например, если столбец имеет тип INTEGER, результат может быть округлён, если используется старый стиль округления, или при необходимости можно выполнить приведение типов для более точных вычислений с плавающей запятой.
В данной статье мы рассмотрим несколько примеров применения функции AVG() в различных ситуациях и дадим рекомендации по оптимизации запросов для получения точных и быстрых результатов.
Как использовать функцию AVG() для вычисления среднего значения
Основной синтаксис функции следующий:
SELECT AVG(имя_столбца) FROM имя_таблицы;
Вместо имя_столбца указывается поле, по которому нужно вычислить среднее значение. Результат работы функции будет одно число – среднее значение по всем строкам.
Пример запроса для вычисления среднего значения зарплаты всех сотрудников:
SELECT AVG(salary) FROM employees;
Этот запрос возвращает среднее значение из столбца salary в таблице employees.
Можно также применить AVG() с дополнительными условиями, используя оператор WHERE. Например, чтобы вычислить среднюю зарплату только для сотрудников старше 30 лет, запрос будет следующим:
SELECT AVG(salary) FROM employees WHERE age > 30;
Для группировки данных по определенным критериям используется оператор GROUP BY. Это позволяет вычислять среднее значение для каждого из подмножеств данных. Пример запроса для вычисления средней зарплаты по отделам:
SELECT department_id, AVG(salary) FROM employees GROUP BY department_id;
Этот запрос вернет среднюю зарплату по каждому отделу в организации.
При использовании функции AVG() следует помнить, что она игнорирует значения NULL. Если в столбце присутствуют пустые значения, они не будут учитываться при вычислении среднего. Однако если столбец содержит только значения NULL, результатом будет NULL.
Кроме того, для оптимизации производительности запросов с использованием AVG() важно правильно индексировать числовые столбцы, так как это ускоряет вычисления для больших объемов данных.
Вычисление среднего значения с учётом фильтрации данных через WHERE
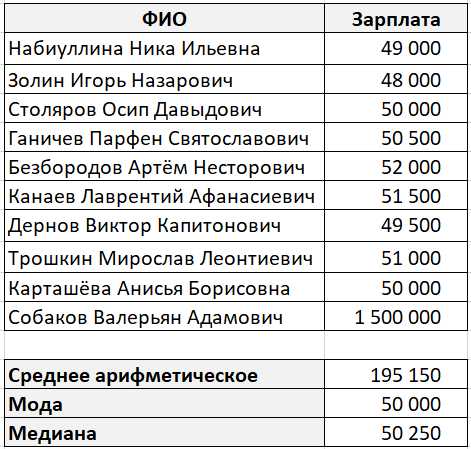
В SQL запросах фильтрация данных с помощью оператора WHERE позволяет вычислять средние значения только по тем записям, которые удовлетворяют заданным условиям. Это полезно в ситуациях, когда необходимо исключить определённые записи из вычислений.
Простейший пример – вычисление среднего значения для конкретной категории товаров в базе данных. Для этого можно использовать запрос, который сначала отфильтровывает нужные записи, а затем вычисляет среднее.
SELECT AVG(price)
FROM products
WHERE category = 'Electronics';
В данном запросе применяется условие WHERE category = 'Electronics', которое ограничивает выборку товарами из категории «Электроника». Функция AVG() затем вычисляет среднее значение по оставшимся записям.
Фильтрация через WHERE может быть более сложной. Например, можно использовать несколько условий для уточнения выборки:
SELECT AVG(salary)
FROM employees
WHERE department = 'Sales' AND hire_date > '2020-01-01';
Здесь вычисляется средняя зарплата сотрудников отдела продаж, которые были наняты после 1 января 2020 года. Таким образом, с помощью оператора AND можно комбинировать несколько фильтров для более точных выборок.
В случае необходимости вычисления среднего значения по разным категориям или группам, стоит использовать GROUP BY в сочетании с фильтрацией:
SELECT department, AVG(salary)
FROM employees
WHERE hire_date > '2019-01-01'
GROUP BY department;
Этот запрос вычисляет среднюю зарплату по каждому отделу среди сотрудников, принятых после 1 января 2019 года. Важно помнить, что в таких запросах фильтрация происходит до группировки данных, что обеспечивает корректные вычисления.
Можно комбинировать фильтрацию с различными операторами, например, IN, BETWEEN или LIKE. Например, для нахождения среднего значения цен товаров, относящихся к нескольким категориям:
SELECT AVG(price)
FROM products
WHERE category IN ('Electronics', 'Appliances');
Здесь используется оператор IN, который позволяет выбрать товары из нескольких категорий одновременно. Это упрощает написание запросов для широких выборок данных.
При использовании фильтрации важно помнить о производительности. Сложные условия могут замедлять выполнение запросов, особенно если база данных содержит большое количество записей. В таких случаях можно создать индексы по полям, которые активно используются в фильтрации, чтобы ускорить вычисления.
Как вычислить среднее значение по группам с помощью GROUP BY

Для вычисления среднего значения по группам в SQL используется агрегатная функция AVG() совместно с оператором GROUP BY. Оператор GROUP BY позволяет разбить данные на группы по указанным столбцам, а функция AVG() вычисляет среднее значение для каждой группы.
Пример запроса для вычисления среднего значения зарплат сотрудников в каждой должности:
SELECT job_title, AVG(salary)
FROM employees
GROUP BY job_title;В этом запросе данные из таблицы employees группируются по полю job_title, а для каждой группы вычисляется средняя зарплата с помощью AVG(salary).
Важно помнить, что при использовании GROUP BY все поля, не включенные в агрегатные функции, должны быть указаны в списке группировки. Если этого не сделать, SQL-сервер вернёт ошибку.
Для вычисления среднего значения по нескольким группам, например, по категориям товаров и годам, запрос может выглядеть так:
SELECT category, YEAR(order_date), AVG(amount)
FROM orders
GROUP BY category, YEAR(order_date);Здесь данные группируются по категориям товаров и годам заказов, и для каждой группы вычисляется средняя сумма заказов.
Использование GROUP BY с AVG() также позволяет учитывать только те строки, которые соответствуют определённым критериям. Например, можно добавить фильтр с помощью HAVING, чтобы вычислять среднее значение только для тех групп, где количество строк превышает заданный порог:
SELECT category, AVG(amount)
FROM orders
GROUP BY category
HAVING COUNT(*) > 10;Этот запрос вычисляет среднее значение суммы заказов для категорий, в которых количество заказов больше 10.
Среднее значение в подзапросах: как применять в сложных запросах
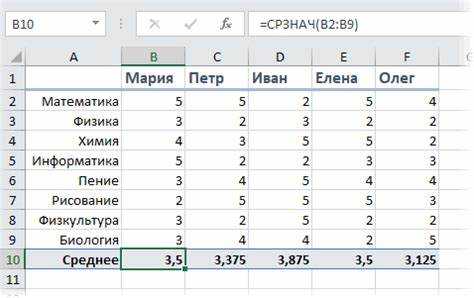
Подзапрос с агрегатной функцией AVG() позволяет вычислять средние значения в ограниченных выборках, применяя их в условиях основного запроса. Это особенно эффективно при анализе данных по категориям, фильтрации и сравнении с общими или группированными метриками.
Рассмотрим пример: необходимо выбрать сотрудников, чья зарплата выше средней по их отделу.
SELECT имя, зарплата, отдел_id
FROM сотрудники s
WHERE зарплата > (
SELECT AVG(зарплата)
FROM сотрудники
WHERE отдел_id = s.отдел_id
);
Подзапрос рассчитывает среднюю зарплату для конкретного отдела, используя коррелированный подзапрос – ссылка на внешний запрос через s.отдел_id обеспечивает индивидуальный расчет для каждой строки. Это позволяет точечно сравнивать значения без предварительного группирования.
При необходимости использовать средние значения в SELECT-части, удобно применять подзапрос в выражении:
SELECT имя,
зарплата,
(SELECT AVG(зарплата)
FROM сотрудники
WHERE отдел_id = s.отдел_id) AS средняя_зарплата_по_отделу
FROM сотрудники s;
Такой подход помогает добавить в результат контекстную метрику без группировки основного запроса. Если требуется агрегировать сразу по нескольким уровням, используйте CTE (with-запросы):
WITH средние_зарплаты AS (
SELECT отдел_id, AVG(зарплата) AS ср_зарплата
FROM сотрудники
GROUP BY отдел_id
)
SELECT s.имя, s.зарплата, sz.ср_зарплата
FROM сотрудники s
JOIN средние_зарплаты sz ON s.отдел_id = sz.отдел_id;
Это повышает читаемость и масштабируемость запроса, особенно при работе с вложенными расчетами. Используйте подзапросы с AVG() осознанно – они могут влиять на производительность при больших объемах данных, особенно при отсутствии индексов по фильтруемым полям.
Рассчитываем среднее значение по нескольким столбцам одновременно
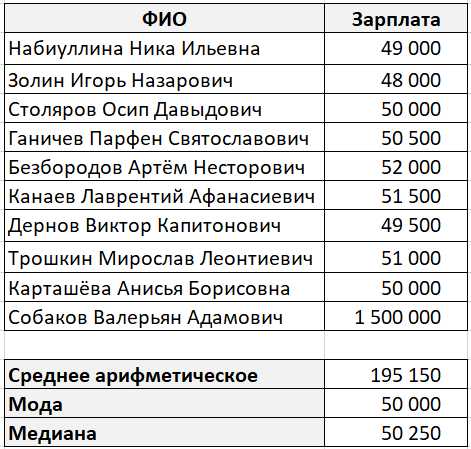
Если требуется вычислить среднее значение сразу по нескольким числовым столбцам в одной строке, стандартная функция AVG() не подходит – она работает только с одним столбцом. Вместо этого используется выражение с арифметикой и преобразованием типов.
Пример: нужно найти среднее значение по трем столбцам score1, score2, score3 в каждой строке:
SELECT id,
(score1 + score2 + score3) / 3.0 AS average_score
FROM students;Чтобы избежать целочисленного деления, хотя бы одно число в делении должно быть с плавающей точкой – например, 3.0, а не 3.
Если значения в некоторых столбцах могут быть NULL, они исключаются из расчета, но сумма и деление должны быть адаптированы вручную:
SELECT id,
(COALESCE(score1, 0) + COALESCE(score2, 0) + COALESCE(score3, 0)) /
NULLIF((CASE WHEN score1 IS NOT NULL THEN 1 ELSE 0 END +
CASE WHEN score2 IS NOT NULL THEN 1 ELSE 0 END +
CASE WHEN score3 IS NOT NULL THEN 1 ELSE 0 END), 0)::float AS average_score
FROM students;COALESCE заменяет NULL на 0 для суммы, а NULLIF предотвращает деление на ноль. Преобразование результата в float обеспечивается через ::float.
Такой подход позволяет точно рассчитывать среднее значение по нескольким столбцам даже при наличии пропущенных данных.
Как вычислить среднее значение без NULL значений в SQL запросах
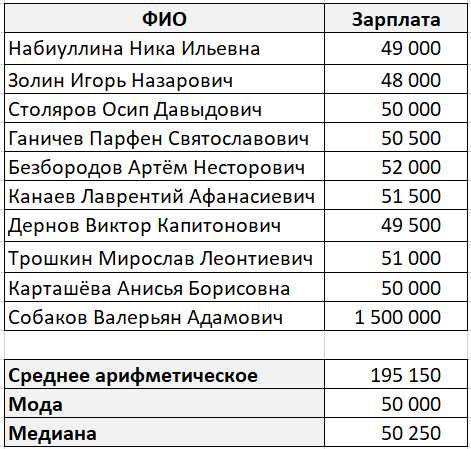
Функция AVG() по умолчанию игнорирует NULL значения, однако важно контролировать источники данных, чтобы исключить влияние этих значений на бизнес-логику запроса. Ниже представлены рекомендации и примеры для точного вычисления среднего без учета NULL.
- Используйте
WHEREдля фильтрацииNULLзначений перед агрегацией. Это важно при наличии дополнительных фильтров, которые могут изменить выборку.
SELECT AVG(salary)
FROM employees
WHERE salary IS NOT NULL;
- При использовании
CASEвнутриAVG()обязательно указывайте условие, исключающееNULL.
SELECT AVG(CASE WHEN salary IS NOT NULL THEN salary END)
FROM employees;
- При соединении таблиц используйте
INNER JOINвместоLEFT JOIN, если поля с числовыми значениями могут бытьNULLна присоединяемой стороне. Это снижает вероятность попаданияNULLв итоговую выборку.
SELECT AVG(o.amount)
FROM orders o
INNER JOIN customers c ON o.customer_id = c.id
WHERE o.amount IS NOT NULL;
- Если
NULLмогут появляться из-за вычислений (например, деление на ноль), обрабатывайте это с помощьюNULLIF.
SELECT AVG(total / NULLIF(count, 0))
FROM statistics;
- Для диагностики используйте
COUNT()иCOUNT(field)параллельно, чтобы понимать, сколько строк исключается из-заNULL.
SELECT COUNT(*), COUNT(salary)
FROM employees;
Точное понимание, откуда появляются NULL, и предварительная фильтрация данных – ключ к корректным агрегатным расчетам в SQL.
Определение средней цены за период с использованием оконных функций
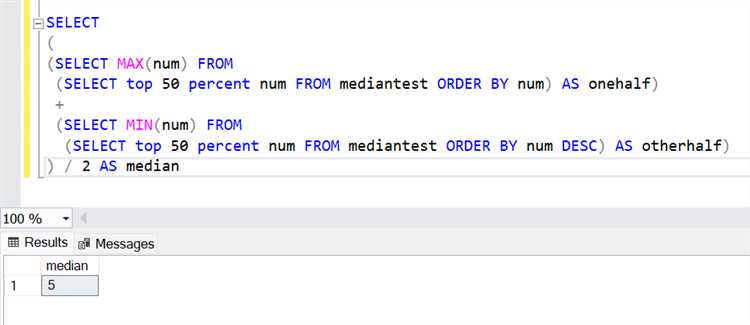
Для точного расчета средней цены за скользящий период в SQL используется оконная функция AVG() с предложением OVER(). Это позволяет выполнять агрегирование без потери детализации по строкам. Пример запроса для расчета средней цены за последние 7 дней по каждой дате транзакции:
SELECT
дата_продажи,
цена,
AVG(цена) OVER (PARTITION BY товар ORDER BY дата_продажи ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS средняя_цена_7_дней
FROM продажи
Ключевой момент – использование ROWS BETWEEN, обеспечивающего контроль над числом строк в окне, а не над диапазоном значений. Это особенно важно при неполной представленности данных по дням. Если необходимо учитывать календарные дни, используется RANGE BETWEEN, но это требует приведения форматов и может работать некорректно с типами DATE без интервалов.
Фильтрация по товару через PARTITION BY позволяет изолировать расчеты внутри каждой группы, что критично для мультипродуктовых таблиц. Для больших объемов данных следует учитывать, что оконные функции требуют сортировки, поэтому важно наличие индекса по полям товар и дата_продажи.
В случае отсутствия покупок в отдельные дни лучше использовать календарную таблицу с внешним соединением, чтобы избежать искажения средних значений из-за пропущенных дат.