Microsoft SQL Server Express – это бесплатная редакция популярной СУБД, предназначенная для разработки, тестирования и небольших проектов. Однако её функциональность ограничена: максимальный размер базы данных – 10 ГБ на один файл данных, использование только одного процессора, ограничение в 1410 МБ оперативной памяти для буфера. Эти рамки делают Express-редакцию неприменимой для большинства высоконагруженных систем.
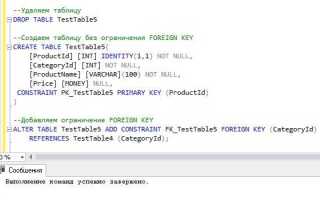
Тем не менее, существует ряд технических подходов, позволяющих обойти ограничения без перехода на платную версию. Один из распространённых методов – разбиение данных по нескольким базам, каждая из которых не превышает 10 ГБ. Сложность заключается в необходимости реализовать уровень абстракции для объединения данных на уровне приложения.
Другой способ – горизонтальное шардирование. Базы данных размещаются на нескольких экземплярах SQL Server Express, что позволяет распределить нагрузку и объём хранения. Запросы необходимо маршрутизировать вручную или с помощью прокси-решений, таких как Pgpool-II или собственных API.
Чтобы минимизировать использование оперативной памяти, рекомендуется оптимизировать запросы, отключить ненужные индексы и избегать избыточных соединений. Также полезно регулярно выполнять DBCC SHRINKDATABASE и DBCC CLEANBUFFER для управления размером буфера и дискового пространства.
При интенсивном использовании рекомендуется перенести логи транзакций на отдельный диск, что позволяет сократить нагрузку на основной файл данных и избежать чрезмерного роста журнала. Важно также настроить автоматическое резервное копирование с архивированием старых файлов, чтобы не переполнить хранилище.
Разделение базы данных на несколько экземпляров SQL Server Express
Ограничение в 10 ГБ на одну базу данных в SQL Server Express можно обойти, распределив данные по нескольким экземплярам сервера. Каждый экземпляр предоставляет собственный набор системных баз данных и изолированное хранилище, позволяя использовать по 10 ГБ на каждую базу в каждом экземпляре.
Для реализации подхода требуется установить несколько экземпляров SQL Server Express на одном сервере. Это возможно благодаря поддержке многократной инсталляции с разными именами экземпляров. Рекомендуется использовать наименования, соответствующие сегментам данных, например SQLExpress_Clients, SQLExpress_Orders и т.д.
Каждому экземпляру следует выделить уникальные порты и каталоги данных, чтобы исключить конфликты. Настройка портов выполняется через SQL Server Configuration Manager, а пути к данным – в процессе установки или позже через свойства экземпляра.
Для взаимодействия между экземплярами можно настроить связные серверы (linked servers). Это позволяет выполнять распределённые запросы и синхронизировать данные при необходимости. Однако из-за накладных расходов на межэкземплярные соединения следует минимизировать кросс-экземплярные транзакции.
Важно контролировать нагрузку на системные ресурсы. При росте числа экземпляров увеличивается использование оперативной памяти и процессора. Рекомендуется ограничивать потребление ресурсов через параметр max server memory для каждого экземпляра, чтобы избежать конкуренции за память.
Этот подход особенно эффективен, когда данные можно логически разделить – например, по регионам, клиентским группам или видам информации. При правильной архитектуре можно масштабировать систему без перехода на платную редакцию SQL Server.
Вынесение редко используемых данных в отдельные архивные базы
Ограничение объема базы данных в SQL Server Express (10 ГБ на базу в актуальных версиях) требует точного контроля за хранимыми данными. Один из эффективных подходов – перенос устаревшей или неактуальной информации в отдельные архивные базы. Это позволяет освободить место в основной БД, сохранив доступ к данным при необходимости.
Архивные базы создаются на том же сервере или на другом экземпляре SQL Server Express, если используется горизонтальное масштабирование. Важно обеспечить минимальный объем изменений в бизнес-логике приложений. Это достигается за счет создания представлений или использования объединенных запросов с функцией UNION ALL для отображения как текущих, так и архивных данных.
Рекомендуется предварительная классификация данных по частоте использования. Для этого выполняется анализ по времени последнего обращения, дате изменения или другим ключевым метаданным. Например, в системе учета заказов можно архивировать заказы старше 3 лет, если они не используются в отчетности или расчетах.
Реализация может включать следующие этапы:
- Создание отдельной базы данных
ArchiveDBсо структурой, идентичной основной - Выделение критериев архивирования (дата создания, статус, пользовательская активность)
- Регулярный перенос данных с помощью пакетных заданий (
SQL Agent Jobили сторонних планировщиков) - Удаление перенесенных записей из основной базы после валидации
Для обеспечения целостности рекомендуется использовать внешний ключ с параметром NOT FOR REPLICATION или временное отключение ограничений во время миграции. Также следует индексировать ключевые поля в архивной базе, чтобы сохранить производительность запросов.
Пример запроса на перенос:
INSERT INTO ArchiveDB.dbo.Orders
SELECT * FROM MainDB.dbo.Orders
WHERE OrderDate < DATEADD(YEAR, -3, GETDATE());Архивирование позволяет поддерживать производительность, не превышая лимиты SQL Server Express. Ключевой момент – автоматизация процесса и прозрачная интеграция архивных данных в отчетность.
Перенос части бизнес-логики из SQL Server Express в приложение
Ограничение по объему базы данных в SQL Server Express (10 ГБ) может стать препятствием для сложных приложений, где требуется хранение больших объемов данных и выполнение ресурсоемких операций. Один из способов оптимизации – перенос части бизнес-логики из SQL Server Express в приложение. Этот подход позволяет разгрузить сервер базы данных и эффективно использовать ресурсы серверной и клиентской части.
Основные причины для переноса логики в приложение:
- Снижение нагрузки на сервер базы данных: Выполнение тяжелых вычислений на стороне приложения позволяет разгрузить сервер и повысить его производительность.
- Уменьшение использования ресурсов базы данных: Логика, которая не требует хранения в базе данных, может быть выполнена в памяти приложения, что ускоряет обработку.
- Гибкость в реализации бизнес-логики: В приложении можно использовать более сложные алгоритмы и механизмы, которые ограничены в SQL Server Express.
Ключевые этапы переноса бизнес-логики:
- Идентификация бизнес-логики для переноса: Определите, какие операции в текущей базе данных занимают значительную часть ресурсов и могут быть эффективно реализованы на стороне приложения. Например, сложные вычисления, фильтрация и агрегация данных.
- Определение точек интеграции: Убедитесь, что переносимая логика не нарушает целостность данных. Для этого используйте механизм транзакций на уровне приложения для синхронизации данных с базой.
- Преобразование запросов в код: Перепишите SQL-запросы и функции, которые выполняют вычисления, на язык программирования, используемый в вашем приложении (например, C#, Python, Java). Это может включать реализацию алгоритмов обработки данных и логику фильтрации.
- Оптимизация работы с данными: Перенос логики в приложение не означает, что нужно отказаться от работы с базой данных. Используйте подходы кеширования, предвыборки и обработки данных в пакетах, чтобы снизить количество обращений к базе.
- Тестирование и мониторинг: После переноса важно провести тестирование производительности приложения и базы данных. Оцените, насколько снизилась нагрузка на SQL Server Express, и как повлиял перенос на общее время отклика системы.
Важным аспектом является правильная балансировка нагрузки между сервером и приложением. Приложение должно быть достаточно мощным, чтобы обрабатывать сложные вычисления, но при этом не перегружать сервер. Правильный подход к разделению обязанностей позволяет существенно повысить производительность и снизить нагрузку на SQL Server Express.
Использование синхронизации с другими СУБД для масштабирования
Для преодоления ограничений Microsoft SQL Server Express можно использовать синхронизацию с другими системами управления базами данных (СУБД). Это позволяет масштабировать решения без необходимости перехода на более дорогие редакции SQL Server. Рассмотрим несколько подходов к синхронизации.
Одним из распространенных методов является использование репликации. Это технология, которая позволяет синхронизировать данные между несколькими СУБД, включая MS SQL Server Express. С помощью репликации можно настроить Master-Slave архитектуру, где основные данные хранятся на сервере Express, а запросы на чтение выполняются на репликах, что снимает нагрузку с основного сервера.
Другим вариантом является использование промежуточных хранилищ, таких как NoSQL базы данных. Например, интеграция с MongoDB или Elasticsearch позволяет разнести данные по более гибким и масштабируемым системам, сохраняя в SQL Server Express только критичные данные. Это снижает общую нагрузку на Express и улучшает время отклика для операций чтения.
Также можно использовать решения на основе очередей сообщений, например, RabbitMQ или Apache Kafka, для синхронизации данных между SQL Server Express и другими СУБД. С помощью таких систем можно эффективно обрабатывать большие потоки данных, отправляя их в другие базы данных для дальнейшей обработки и хранения, не перегружая основную СУБД.
Реализация синхронизации данных с другими СУБД требует тщательной настройки и контроля за процессами передачи данных, так как несоответствия или потеря данных могут повлиять на целостность всей системы. Для этого можно использовать специализированные инструменты для мониторинга и логирования процессов синхронизации, такие как SQL Profiler или сторонние системы мониторинга.
Организация распределённого хранения с помощью связных серверов
Настройка связных серверов позволяет одному SQL Server взаимодействовать с другими серверами, получая доступ к данным, хранящимся на удалённых экземплярах SQL Server или других СУБД, таких как Oracle или MySQL. Данный способ идеально подходит для распределённых архитектур и приложений, где данные могут быть логически разделены по нескольким базам данных.
Основные этапы организации распределённого хранения с использованием связных серверов:
- Создание связанного сервера: На главном сервере создаётся связанный сервер с указанием типа удалённой системы и параметров подключения (адрес, учётные данные). Это делается через SQL Server Management Studio или с использованием T-SQL.
- Конфигурация безопасности: Для обеспечения надёжного соединения нужно настроить аутентификацию и права доступа на связанный сервер. Выбор метода аутентификации зависит от требований безопасности: это может быть использование SQL Server Authentication или Windows Authentication.
- Определение источников данных: Связанный сервер должен быть настроен для работы с конкретной базой данных или таблицей на удалённом сервере. Это даёт возможность обращаться к данным как к локальным, но при этом они физически хранятся на удалённом сервере.
- Работа с удалёнными данными: Запросы к данным на связном сервере могут выполняться с помощью распределённых запросов, где данные, хранящиеся на удалённых серверах, становятся доступными через локальные SQL-запросы.
Для эффективного использования связных серверов при организации распределённого хранения следует учитывать несколько аспектов:
- Производительность: Запросы к данным на удалённых серверах могут иметь большую задержку. Поэтому стоит минимизировать их количество и использовать методы кэширования, если это возможно.
- Безопасность: Следует внимательно относиться к безопасности связанного сервера, особенно если используется удалённое подключение через интернет. Обязательно настройте шифрование для передачи данных и используйте сильные методы аутентификации.
- Управление ошибками: При работе с распределённым хранилищем могут возникать сетевые ошибки или проблемы с доступом к удалённым серверам. Используйте обработку ошибок, чтобы минимизировать влияние таких ситуаций на работу системы.
Использование связных серверов в контексте ограничений SQL Server Express позволяет эффективно разделять и масштабировать данные, оптимизируя использование доступных ресурсов и увеличивая гибкость системы хранения данных. Важно помнить, что в таких случаях необходимо продумать архитектуру с учётом возможных сетевых задержек и сложности управления распределёнными данными.
Мониторинг использования ресурсов и автоматизация переключения
Для эффективного управления ресурсами в Microsoft SQL Server Express необходимо регулярно отслеживать использование процессора, памяти и дискового пространства. Важно понимать, что версия Express имеет жесткие ограничения на ресурсы, такие как 1 ГБ оперативной памяти и 10 ГБ на базу данных. Превышение этих лимитов может привести к снижению производительности или сбоям в работе сервера.
Для мониторинга использования ресурсов можно настроить различные средства, такие как SQL Server Management Studio (SSMS) или сторонние инструменты. В SSMS можно использовать системные представления, такие как sys.dm_exec_sessions и sys.dm_exec_requests, для получения информации о текущей активности в системе. Также полезны отчеты производительности, например, Performance Monitor, который позволяет следить за ключевыми показателями нагрузки.
Автоматизация процесса переключения между версиями SQL Server – это важный этап для минимизации простоев и переноса нагрузки на более мощные серверы, когда ограничения Express становятся препятствием. Для этого можно настроить процессы на основе монитора состояния сервера. Один из подходов – использование скриптов, которые автоматически проверяют текущие параметры использования памяти и процессора. Например, если использование памяти превышает 80%, можно автоматически инициировать процесс переключения на более высокую версию SQL Server.
Для автоматизации такого процесса можно использовать SQL Server Agent или сторонние инструменты для создания сценариев на основе мониторинга. Важно, чтобы система оповещала администратора заранее о потенциальном превышении лимитов, чтобы он мог вовремя принять меры. Важно настроить регулярные бэкапы и проверку целостности данных перед выполнением миграции, чтобы избежать потерь.
Также стоит учитывать, что после перехода на более мощную версию SQL Server могут потребоваться дополнительные настройки для оптимизации производительности, такие как конфигурация памяти и процессора, а также изменение параметров индексов и запросов для лучшего использования ресурсов новой платформы.
Вопрос-ответ:
Какие основные ограничения Microsoft SQL Server Express?
Microsoft SQL Server Express имеет несколько ключевых ограничений. Среди них: максимальный размер базы данных — 10 ГБ, ограничение на использование одного процессора (или одного ядра процессора) и ограничение по объему оперативной памяти — 1 ГБ. Эти лимиты могут быть проблемой для более крупных приложений или баз данных с большим объемом данных.
Как можно обойти ограничение по размеру базы данных в SQL Server Express?
Одним из способов обойти ограничение по размеру базы данных в SQL Server Express является использование нескольких баз данных. Для этого можно разделить данные на несколько частей, каждая из которых не будет превышать лимит в 10 ГБ. Этот метод подходит для приложений, которые могут эффективно работать с несколькими базами данных. Также можно настроить архивацию старых данных и удаление ненужных записей, чтобы освободить место.
Можно ли использовать более одного процессора в SQL Server Express?
В Microsoft SQL Server Express ограничение на использование только одного процессора или одного ядра процессора может быть проблемой для ресурсоемких приложений. Чтобы обойти это ограничение, можно использовать другие версии SQL Server, например, Standard или Enterprise, которые не имеют такого лимита. Также возможно использовать несколько экземпляров SQL Server Express на разных машинах или виртуальных машинах, распределяя нагрузку между ними.
Какие есть альтернативы для обхода ограничений по памяти в SQL Server Express?
SQL Server Express ограничен 1 ГБ оперативной памяти. Чтобы обойти это ограничение, можно использовать несколько экземпляров SQL Server Express, распределяя нагрузку между ними. Еще одним способом является оптимизация запросов и индексов, чтобы уменьшить потребление памяти. Также можно использовать кэширование данных в памяти на уровне приложения, чтобы снизить нагрузку на сервер.
Есть ли способы улучшить производительность SQL Server Express при ограничениях?
Для улучшения производительности в условиях ограничений SQL Server Express рекомендуется несколько подходов. Во-первых, важно оптимизировать запросы и индексы для ускорения работы с данными. Во-вторых, можно настроить масштабируемость за счет использования нескольких экземпляров SQL Server Express на разных серверах или виртуальных машинах. Также можно использовать технику разделения данных и баз, чтобы избежать превышения лимитов. Важно также учитывать настройки конфигурации, такие как параметр MAXDOP (максимальное количество потоков обработки запросов), который позволяет улучшить работу с многозадачностью.