SQL запросы могут значительно увеличивать нагрузку на сервер, особенно когда речь идет о сложных операциях с большими объемами данных. Когда система не ограничивает потребление памяти, может произойти исчерпание доступных ресурсов, что приведет к снижению производительности и даже к сбоям в работе базы данных. Важно понимать, как правильно настроить ограничения на использование памяти в SQL запросах, чтобы минимизировать риски перегрузки и поддерживать стабильную работу системы.
Один из способов контроля потребления памяти – использование параметров настройки базы данных, таких как work_mem в PostgreSQL или sort_buffer_size в MySQL. Эти параметры позволяют задать пределы на использование памяти для операций сортировки и хэширования. Например, в PostgreSQL параметр work_mem определяет максимальный размер памяти, который может быть использован для сортировки или хэширования данных в процессе выполнения запроса. Установка слишком высокого значения может привести к излишнему потреблению памяти, в то время как низкие значения увеличат время выполнения запросов.
Кроме того, для более сложных запросов можно ограничить количество памяти, выделяемое для выполнения каждого запроса, с помощью таких инструментов, как Resource Governor в SQL Server. Этот механизм позволяет задать максимальные пределы по памяти и процессорному времени для каждого сеанса, что помогает распределять ресурсы между различными запросами и пользователями. Применение этих технологий требует тщательной настройки и мониторинга нагрузки на сервер, чтобы предотвратить перегрузки.
Не менее важным аспектом является оптимизация самих SQL запросов. Уменьшение объема обрабатываемых данных с помощью правильных индексов, фильтров и агрегаций позволяет значительно снизить нагрузку на память. Например, использование JOIN операций без индексов на соединяемых столбцах или выборка ненужных данных может привести к значительному увеличению потребляемой памяти. Поэтому регулярный анализ и оптимизация запросов – ключевой момент для эффективного контроля потребления памяти.
Мониторинг использования памяти в SQL запросах
Для эффективного управления использованием памяти SQL запросами необходимо интегрировать специализированные методы мониторинга, которые позволяют отслеживать и ограничивать память, расходуемую в процессе выполнения запросов. Использование встроенных инструментов СУБД, таких как EXPLAIN или SHOW STATUS, помогает получить детализированные данные о расходах памяти на разных этапах обработки запросов.
Одним из ключевых аспектов является настройка параметров памяти на уровне сервера. Например, в MySQL можно использовать переменные innodb_buffer_pool_size и max_connections, которые напрямую влияют на количество памяти, доступной для обработки запросов. Параметр sort_buffer_size влияет на память, выделенную для сортировки данных, а read_buffer_size – на память, используемую для чтения данных. Постоянный контроль за этими параметрами позволяет избежать перегрузки системы.
Кроме того, для мониторинга в реальном времени можно использовать средства профилирования, такие как MySQL Enterprise Monitor или pg_stat_statements в PostgreSQL. Эти инструменты позволяют получать информацию о запросах, которые используют наибольшее количество ресурсов. Регулярный анализ данных профилирования помогает выявлять узкие места, оптимизировать запросы и, при необходимости, корректировать настройки памяти для улучшения производительности.
Наконец, стоит помнить о важности оптимизации запросов. Сложные запросы с большим количеством соединений, подзапросов или операций сортировки могут значительно увеличивать потребление памяти. Применение индексов и использование подходящих типов данных для минимизации объема обрабатываемых данных – важные шаги в процессе оптимизации, которые напрямую влияют на использование памяти.
Как определить высокое потребление памяти запросом
1. Использование EXPLAIN
С помощью команды EXPLAIN можно получить информацию о том, как SQL-запрос будет выполняться. Важные моменты, на которые стоит обратить внимание:
- Типы соединений (JOIN). Сложные соединения могут значительно увеличить использование памяти.
- Используемые индексы. Отсутствие индексов или их неправильное использование может привести к большому объему обрабатываемых данных.
- Фильтрация данных. Применение сложных условий может увеличить память, необходимую для выполнения запроса.
2. Анализ работы с буферами
Большое потребление памяти может быть связано с обработкой данных в буферах сервера. Мониторинг состояния буферов с помощью системных представлений или инструментов (например, pg_stat_activity для PostgreSQL или sys.dm_exec_requests для SQL Server) позволяет отслеживать запросы с высоким использованием оперативной памяти. Если запросы используют слишком большие буферы, это указывает на возможные проблемы с производительностью.
3. Мониторинг с помощью системных представлений
Для выявления запросов с высоким потреблением памяти можно использовать системные представления. Например, в MySQL это можно сделать через команду:
- SHOW STATUS LIKE ‘Handler%’;
- SHOW ENGINE INNODB STATUS;
В SQL Server можно использовать:
- sys.dm_exec_requests;
- sys.dm_exec_query_memory_grants;
4. Использование инструментов для мониторинга
Системы мониторинга, такие как Prometheus с Grafana или New Relic, могут предоставлять визуализацию метрик, включая потребление памяти запросами. Эти инструменты позволяют легко отслеживать пик потребления памяти в режиме реального времени и выявлять проблемные запросы.
5. Время выполнения запроса
Длительные запросы, особенно с агрегацией данных, могут потреблять много памяти. Важно отслеживать время выполнения запросов и сопоставлять его с объемом используемой памяти. Если время выполнения значительно превышает норму, стоит исследовать запрос и индексирование.
6. Использование временных таблиц и сортировки
Запросы, которые активно используют временные таблицы или выполняют сортировку больших объемов данных, могут вызвать увеличение потребления памяти. Определите, какие запросы создают временные таблицы, и проанализируйте их структуру, чтобы минимизировать потребление памяти.
7. Графики и временные зависимости
Использование графиков, которые отображают изменения в потреблении памяти по времени, позволяет выявить тенденции. Это поможет не только определить запросы, вызывающие высокий расход памяти, но и их временные зависимости, что важно для планирования масштабирования системы.
Таким образом, правильный мониторинг, анализ выполнения запросов и использование системных инструментов позволяют точно выявить и оптимизировать запросы, потребляющие чрезмерное количество памяти.
Использование индексов для снижения использования памяти
Индексы в SQL играют ключевую роль в оптимизации запросов, но также могут значительно повлиять на потребление памяти. Правильное использование индексов позволяет снизить нагрузку на память при обработке запросов, минимизируя избыточное использование ресурсов и ускоряя поиск данных. Однако неэффективное создание индексов может привести к обратному эффекту, увеличив потребление памяти и снизив производительность.
Во-первых, индексы ускоряют выполнение SELECT-запросов, но они также занимают пространство на диске и в памяти. Поэтому важно тщательно подходить к выбору столбцов для индексации. Создание индексов только для часто запрашиваемых столбцов или столбцов, используемых в условиях WHERE или JOIN, помогает снизить размер таблиц в памяти, уменьшая необходимость полного сканирования данных.
Использование составных индексов, включающих несколько столбцов, может значительно сократить объем памяти, необходимый для выполнения сложных запросов. Однако важно, чтобы порядок столбцов в индексе соответствовал порядку их использования в запросах. Неправильно подобранные составные индексы могут привести к увеличению памяти из-за излишних данных, которые нужно хранить.
Также стоит учитывать, что индексы, созданные на столбцах с высокой кардинальностью (например, уникальные идентификаторы), значительно эффективнее, чем индексы на столбцах с низкой кардинальностью. Индексы на такие столбцы позволяют уменьшить количество данных, обрабатываемых при запросах, и соответственно снижают нагрузку на память.
Следует избегать излишнего создания индексов. Каждый индекс увеличивает использование памяти и замедляет операции вставки, обновления и удаления данных. Определение необходимого числа индексов зависит от частоты выполнения определенных запросов и структуры базы данных. Применение аналитики производительности запросов и регулярная оптимизация индексов помогает достичь баланса между производительностью и потреблением памяти.
Для снижения использования памяти важно периодически анализировать и пересматривать существующие индексы. Использование инструментов анализа запросов, таких как EXPLAIN в MySQL или PostgreSQL, позволяет выявить неэффективные индексы, которые не используются или занимают излишнее место в памяти.
Оптимизация JOIN операций для минимизации потребления памяти
При выполнении SQL-запросов с использованием операций JOIN важно учитывать их влияние на потребление памяти, так как объединение больших объемов данных может привести к значительным нагрузкам на систему. Оптимизация JOIN операций позволяет снизить этот эффект, улучшив производительность запросов.
Первое, на что следует обратить внимание – это порядок объединения таблиц. При использовании INNER JOIN или LEFT JOIN стоит сначала подключать более маленькие таблицы, чтобы избежать избыточного создания промежуточных результатов. Это особенно актуально для запросов, где одна из таблиц значительно меньше других, и её можно загрузить в память без сильной нагрузки.
Одним из эффективных методов минимизации потребления памяти является использование индексирования. Для операций JOIN индексы на столбцах, которые участвуют в объединении, могут существенно уменьшить время и память, затрачиваемые на поиск соответствующих строк. Применение составных индексов, включающих несколько столбцов, особенно эффективно при соединении с фильтрацией по нескольким условиям.
В случаях, когда необходимо выполнить объединение больших таблиц, следует использовать методы, которые уменьшают количество обрабатываемых строк на каждом этапе. Например, использование подзапросов для предварительной фильтрации данных или агрегации перед выполнением основного JOIN позволяет уменьшить объем данных, с которыми работает основная операция.
Для уменьшения использования памяти также рекомендуется применять операцию JOIN только в тех случаях, когда она действительно необходима. Например, при использовании LEFT JOIN можно избегать объединения строк, которые не имеют соответствующих записей в другой таблице, путем оптимизации фильтров в WHERE-условиях.
Кроме того, следует контролировать размер буферов, используемых сервером базы данных для выполнения JOIN операций. Многие СУБД предоставляют настройки, которые позволяют ограничить размер временных таблиц, создаваемых для объединений. Уменьшение размера буфера может предотвратить переполнение памяти и повысить общую стабильность работы системы.
При работе с большими объемами данных можно использовать технику «разбиения на пакеты» (batching). Это означает выполнение JOIN операций в несколько этапов, с обработкой данных порциями, что минимизирует пиковое потребление памяти в процессе выполнения запроса.
Наконец, стоит помнить о роли статистики базы данных. Постоянное обновление статистики таблиц и индексов позволяет СУБД правильно выбирать стратегию выполнения JOIN операций, что может существенно повлиять на производительность и использование памяти.
Роль агрегатных функций в потреблении памяти SQL запросами
Агрегатные функции в SQL, такие как COUNT(), SUM(), AVG(), MAX() и MIN(), значительно влияют на использование памяти при выполнении запросов. В процессе агрегации данные группируются, что требует временного хранения промежуточных результатов, что может быть ресурсоемким, особенно при больших объемах данных.
При выполнении запросов с агрегацией система должна выделять память для хранения значений, которые могут быть использованы для дальнейших вычислений. Например, при использовании GROUP BY создается дополнительная структура данных для группировки, что может потребовать значительных ресурсов. Чем больше уникальных значений в колонке, тем больше памяти нужно для выполнения запроса. Для сложных агрегатных операций, таких как SUM() или AVG(), дополнительные затраты памяти возникают из-за необходимости хранения значений для каждой группы.
Один из факторов, который влияет на потребление памяти при агрегации, – это количество строк в таблице и уровень параллелизма. В случае больших таблиц система может быть вынуждена выполнять агрегацию в несколько этапов, что требует выделения памяти для хранения промежуточных данных. В зависимости от используемой базы данных, эта операция может быть оптимизирована через использование индексов или специальных методов агрегации, таких как скользящие окна (window functions), которые позволяют избежать полной переработки всех строк.
Использование агрегации на колонках с большим количеством уникальных значений может быть особенно затратным с точки зрения памяти. Например, в случае использования GROUP BY для колонки с большим количеством уникальных значений может возникнуть потребность в создании временных структур данных, что увеличивает общий объем потребляемой памяти. Оптимизация таких запросов может включать использование более селективных фильтров (например, через WHERE) или индексов, что позволяет снизить объем данных, которые необходимо агрегировать.
Особое внимание стоит уделить вопросам производительности при выполнении запросов с несколькими агрегатами. Например, если запрос содержит SUM() и AVG() для одной и той же группы, система может попытаться выполнить вычисления одновременно, чтобы минимизировать затраты памяти. Однако если агрегация затрагивает большие объемы данных, потребуется больше памяти для хранения промежуточных результатов, что может привести к сбоям из-за нехватки ресурсов.
Оптимизация использования памяти при агрегации может быть достигнута через следующие подходы:
- Использование индексов для колонок, по которым осуществляется агрегация.
- Применение фильтров до агрегации для уменьшения объема данных, подвергающихся обработке.
- Использование оконных функций для агрегации по частям данных, что позволяет избежать хранения всех результатов в памяти одновременно.
- Параллельная обработка данных в распределенных системах, что позволяет разделить нагрузку и уменьшить потребление памяти на каждом узле.
Таким образом, агрегатные функции играют ключевую роль в потреблении памяти при выполнении SQL-запросов. Правильное управление этими функциями позволяет значительно повысить производительность запросов и уменьшить нагрузку на ресурсы системы.
Как настроить лимиты памяти для SQL запросов в СУБД
Для ограничения потребления памяти SQL запросами в современных СУБД необходимо использовать встроенные механизмы, доступные в конкретной системе управления базами данных. Настройка лимитов памяти позволяет предотвращать чрезмерное потребление ресурсов и обеспечивать стабильную работу сервера.
В MySQL и MariaDB для ограничения памяти можно использовать параметр max_execution_time, который ограничивает время выполнения запроса, и sort_buffer_size, который регулирует объем памяти для сортировки данных. Этот параметр определяет размер буфера, который используется при выполнении сортировок, и может влиять на использование памяти.
В PostgreSQL есть параметр work_mem, который настраивает объем памяти, выделяемый для выполнения сортировки и хеширования. Параметр shared_buffers регулирует общий объем памяти, используемый для кэширования данных в PostgreSQL. Важно настроить эти параметры в соответствии с потребностями системы, чтобы не перегрузить сервер.
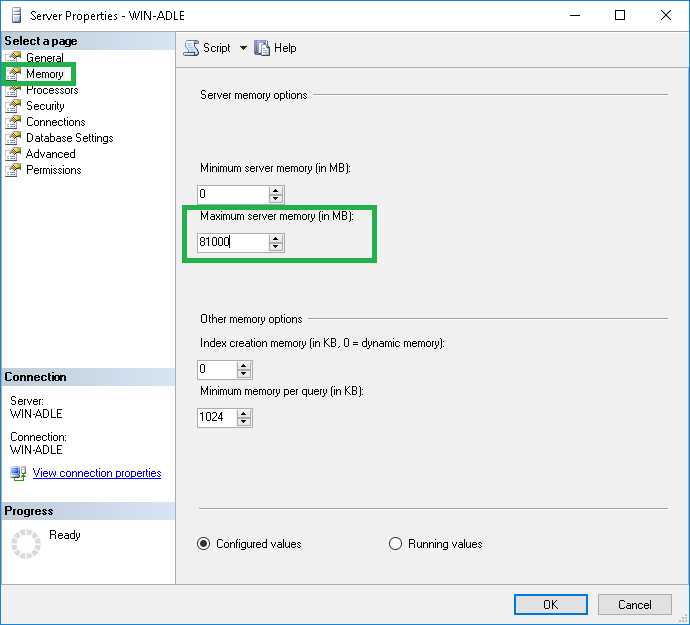
В SQL Server лимитирование памяти выполняется с помощью параметра max server memory, который ограничивает максимальный объем памяти, который может быть использован сервером базы данных. Дополнительно можно использовать параметр max memory per query, чтобы ограничить объем памяти, выделяемый конкретным запросам.
Для более детальной настройки в MySQL можно использовать tmp_table_size и max_heap_table_size, которые ограничивают размер временных таблиц в памяти. Это позволяет избежать переполнения диска, если запросы создают большие временные таблицы. В PostgreSQL можно также настроить temp_buffers для временных буферов, используемых при выполнении операций с временными таблицами.
Каждый из этих параметров зависит от специфики работы системы и характера запросов, выполняемых в базе данных. Настройка лимитов памяти требует тщательного мониторинга и анализа работы запросов для оптимального использования ресурсов. Недооценка или переоценка лимитов может привести к снижению производительности или к системным сбоям.
Использование пагинации для уменьшения нагрузки на память
Пагинация позволяет обрабатывать большие объемы данных по частям, что снижает нагрузку на память при выполнении SQL-запросов. Вместо того чтобы загружать всю таблицу или выборку сразу, данные разбиваются на страницы, и каждая страница загружается по запросу. Это особенно важно при работе с большими базами данных, где запросы могут потребовать значительных ресурсов.
Чтобы реализовать пагинацию, обычно используются два основных подхода:
- OFFSET/FETCH – стандартный метод для выборки данных с определенного индекса. Он позволяет получить, например, 100 записей, начиная с 101-й.
- LIMIT/WHERE – метод с указанием диапазона значений для пагинации. Например, можно запросить записи с id от 100 до 200, что минимизирует количество обрабатываемых данных.
В обоих случаях важно соблюдать оптимизацию запросов для уменьшения их воздействия на память. Рассмотрим несколько рекомендаций:
- Минимизация OFFSET – при использовании OFFSET запросы становятся менее эффективными на больших объемах данных. Для каждого нового запроса база данных должна пропускать множество строк, что приводит к лишней загрузке. Вместо этого рекомендуется использовать методы с прямым указанием диапазона, например, с использованием индекса (например, id).
- Использование индексов – создание индексов на колонках, по которым осуществляется фильтрация (например, id или дата), значительно ускоряет работу пагинации и снижает нагрузку на память.
- Отложенная загрузка – пагинация помогает реализовать отложенную загрузку (lazy loading), где данные подгружаются по мере необходимости. Это может быть полезно в веб-приложениях для динамической подгрузки страниц с данными.
- Ограничение количества записей – установление лимита на количество записей на одной странице позволяет избежать переполнения памяти и ускоряет обработку данных. Оптимальный лимит зависит от структуры данных и используемой системы.
Кроме того, при реализации пагинации важно учитывать, что она требует корректной работы с транзакциями. Если данные в таблице изменяются (добавляются или удаляются) между запросами, это может привести к несоответствиям в данных, которые могут быть выбраны для текущей страницы. Чтобы избежать таких ситуаций, рекомендуется использовать фиксированные критерии для пагинации, такие как уникальные идентификаторы.
Использование пагинации эффективно снижает не только нагрузку на память, но и время отклика запросов. Это особенно актуально для веб-приложений, где важно поддерживать производительность даже при больших объемах данных. Совмещение пагинации с другими методами оптимизации, такими как индексация и кеширование, позволит достичь максимально эффективной работы с базами данных.
Анализ плана выполнения запроса для поиска узких мест
Для оптимизации запросов и минимизации потребления памяти важно анализировать план выполнения запроса. Этот план предоставляет информацию о том, как SQL-система будет обрабатывать запрос, включая последовательность операций, использованные индексы и типы соединений. На основе анализа плана выполнения можно выявить узкие места, которые приводят к избыточному потреблению ресурсов.
Основным инструментом для анализа является команда EXPLAIN (или аналог в разных СУБД). Она возвращает последовательность шагов, которые СУБД выполнит для обработки запроса, что позволяет детально изучить операции и оценить их эффективность. Оценка времени выполнения каждого шага помогает определить, какие операции занимают наибольшее количество времени и памяти.
Основные аспекты, на которые следует обратить внимание при анализе плана выполнения запроса:
1. Типы соединений (Join)
Если запрос использует несколько таблиц, важно понимать, какие соединения применяются. Наиболее распространенные типы соединений включают Nested Loop, Hash Join и Merge Join. Некоторые из них требуют значительных объемов памяти, особенно при работе с большими объемами данных. Например, если используется Nested Loop для больших таблиц, это может привести к избыточному использованию памяти, особенно если отсутствуют соответствующие индексы.
2. Использование индексов
Отсутствие индексов на столбцах, используемых в WHERE или JOIN, может стать серьезной проблемой, требующей полной загрузки таблиц в память. Планы выполнения покажут, использует ли СУБД индексы, и если нет – это сигнал к их добавлению. Однако важно помнить, что создание индекс может увеличить потребление памяти и времени на запись, поэтому нужно тщательно выбирать, какие индексы создавать.
3. Сканирование таблиц
Типы сканирования (например, Full Table Scan, Index Scan) также сильно влияют на память. Full Table Scan является наименее эффективным методом, требующим полной загрузки таблицы в память, что может вызвать перерасход ресурсов. В таких случаях стоит подумать о добавлении индексирования или переработке запроса, чтобы уменьшить необходимость в сканировании всей таблицы.
4. Операции сортировки и группировки
Если в запросе есть операции сортировки (ORDER BY) или группировки (GROUP BY), они могут потреблять значительные объемы памяти, особенно при обработке больших наборов данных. План выполнения покажет, использует ли запрос дисковое пространство для временных файлов или работает исключительно в памяти. Если происходит использование диска для сортировки, это может свидетельствовать о недостаточной памяти для выполнения операции.
5. Фильтрация и предсказание стоимости
При анализе плана выполнения запроса важно понимать, какие фильтры (WHERE) СУБД применяет и как она оценивает их стоимость. Если запрос имеет сложные условия фильтрации, план может показывать, насколько эффективно они применяются. Иногда СУБД не может оптимально распределить фильтры, что ведет к избыточному потреблению памяти, например, при неправильной последовательности фильтров или отсутствии статистики для оценки стоимости.
6. Оценка и оптимизация планов
После получения плана выполнения важно тщательно проанализировать все шаги, оценив их стоимость, включая потребление памяти, времени и дисков. Оптимизация плана может включать переработку запросов, добавление индексов или изменение структуры данных. Часто бывает полезно экспериментировать с различными параметрами, чтобы увидеть, как изменения влияют на использование памяти и времени выполнения.
Вопрос-ответ:
Как ограничить потребление памяти при выполнении SQL-запросов?
Чтобы уменьшить потребление памяти SQL-запросами, можно использовать несколько стратегий. Во-первых, следует ограничить выборку данных, выбирая только необходимые столбцы, а не все поля в таблице. Во-вторых, полезно использовать индексы, что позволит быстрее находить данные и уменьшить нагрузку на память. Также стоит избегать выполнения запросов без фильтров, например, без применения оператора WHERE, который помогает сузить объем обрабатываемых данных. Наконец, можно оптимизировать запросы, чтобы они не выполнялись с использованием большого числа объединений (JOIN), что требует значительных ресурсов памяти.
Что такое оптимизация запросов в контексте использования памяти?
Оптимизация запросов заключается в снижении объема данных, которые обрабатываются во время выполнения SQL-запросов, с целью минимизировать использование памяти. Это можно достичь путем более разумного выбора условий фильтрации (например, правильное использование индексов), выбора только нужных столбцов вместо всех данных в таблице и применения агрегатных функций. Также стоит избегать сложных и ненужных JOIN-ов, которые могут увеличить нагрузку на память. Важно правильно настроить выполнение запросов, чтобы они использовали меньше оперативной памяти.
Какие ошибки могут привести к чрезмерному потреблению памяти SQL-запросами?
Одна из главных ошибок — выполнение запросов без фильтрации данных. Например, запрос без WHERE-клаузы может вытащить всю таблицу, что потребует значительных ресурсов. Также чрезмерное использование оператора JOIN при объединении множества таблиц может привести к большой нагрузке на память, особенно если в объединяемых таблицах есть большое количество строк. Использование подзапросов, которые не индексированы или плохо оптимизированы, также может увеличить потребление памяти, так как они требуют дополнительных вычислений для обработки данных.
Как использование индексов влияет на потребление памяти при выполнении SQL-запросов?
Индексы играют важную роль в оптимизации запросов, особенно когда речь идет о поиске данных. Когда индекс правильно настроен, он помогает ускорить поиск строк в таблице, что снижает объем операций с памятью. Например, при поиске данных с использованием WHERE-клаузы индекс позволяет быстрее находить нужные строки, сокращая использование оперативной памяти. Однако важно помнить, что создание слишком большого числа индексов или их неправильное использование может, наоборот, увеличить нагрузку на память и даже замедлить выполнение запросов, поскольку индексы требуют дополнительного пространства для хранения.
Какие инструменты и методы можно использовать для мониторинга потребления памяти SQL-запросами?
Для мониторинга потребления памяти можно использовать различные инструменты и команды в СУБД. Например, в MySQL или PostgreSQL есть утилиты для мониторинга выполнения запросов, такие как EXPLAIN, которые показывают, как запросы используют индексы и сколько памяти они потребляют. Также можно использовать системные средства мониторинга, такие как мониторинг процессора и памяти на уровне операционной системы. В некоторых СУБД можно использовать специализированные профайлеры запросов, которые дают подробную информацию о том, какие части запросов занимают больше всего ресурсов. Регулярный мониторинг и анализ запросов помогут выявить потенциальные проблемы с потреблением памяти и оптимизировать их.