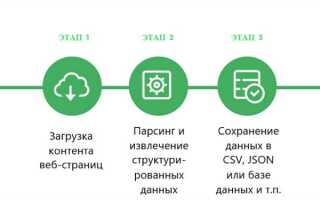
HTML парсер – это инструмент, который позволяет программно извлекать информацию из веб-страниц. Его основная цель – преобразовать HTML-код в структуру, с которой удобно работать в коде. Обычно используется для сбора данных с сайтов, анализа содержимого или автоматизации веб-задач. Важнейший аспект работы с парсерами – это правильное понимание структуры HTML-документа, что позволяет эффективно извлекать нужную информацию.
Для извлечения данных из HTML-страницы в большинстве случаев используется библиотека, которая предоставляет удобный интерфейс для работы с деревом DOM (Document Object Model). Одним из популярных инструментов для парсинга HTML является BeautifulSoup в Python. Это мощная и гибкая библиотека, которая облегчает обработку HTML, работая с такими элементами как теги, атрибуты, классы и т. д. Помимо Python, существует множество других библиотек, таких как Cheerio для Node.js или Jsoup для Java.
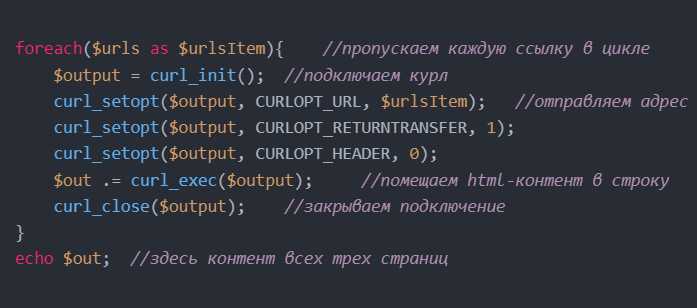
Основные шаги для парсинга HTML заключаются в следующем. Сначала необходимо получить HTML-код страницы, используя, например, библиотеку Requests в Python. Затем этот код передается в парсер, который разбивает его на отдельные элементы и позволяет работать с ними. Примером может быть извлечение всех ссылок на странице, что можно выполнить, обратившись к тегам <a> и их атрибутам href.
Кроме того, важно учитывать динамическое содержание страниц, которое загружается через JavaScript. В таких случаях стандартный парсер может не подойти, и для извлечения данных нужно использовать инструменты для работы с динамическим контентом, такие как Selenium или Playwright. Эти инструменты позволяют эмулировать действия пользователя и извлекать данные из динамических веб-страниц, которые не видны в исходном HTML-коде.
Как выбрать библиотеку для парсинга HTML в Python
Для парсинга HTML в Python существует несколько популярных библиотек, каждая из которых имеет свои особенности. Чтобы выбрать подходящую, важно учитывать несколько ключевых факторов: производительность, простота использования, функциональные возможности и поддержка специфичных типов HTML-документов.
BeautifulSoup – одна из самых популярных библиотек для парсинга HTML. Она проста в использовании, что делает её хорошим выбором для новичков. Подходит для обработки «грязного» HTML, часто используемого на веб-страницах, с множеством ошибок. Однако для больших проектов её производительность может быть недостаточной. Она хороша для небольших и средних задач, таких как извлечение данных с сайтов с неструктурированным HTML.
lxml – более производительная библиотека, которая работает быстрее, чем BeautifulSoup, и лучше справляется с большими объёмами данных. Она поддерживает как парсинг HTML, так и XML, что делает её универсальным инструментом. Если проект требует обработки крупных страниц или множества запросов, lxml будет лучшим выбором. Однако её синтаксис сложнее, чем у BeautifulSoup, и для работы с этой библиотекой потребуется больше времени на изучение.
html.parser – встроенный парсер, доступный в Python без дополнительных установок. Он является хорошим выбором для базовых задач, если вам нужно просто извлечь данные из корректных HTML-документов. Однако по производительности и гибкости он уступает lxml и BeautifulSoup. Использование html.parser оправдано в тех случаях, когда проект не требует высокой производительности или работы с нестандартным HTML.
PyQuery предоставляет API, напоминающее jQuery, что делает его привлекательным для разработчиков, уже знакомых с этим инструментом. PyQuery отлично подходит для парсинга веб-страниц с большими объёмами данных и динамическим контентом. Но для простых задач PyQuery может показаться избыточным.
При выборе библиотеки важно также учитывать совместимость с другими инструментами, например, с Selenium, если нужно работать с динамическими страницами, а не только с их исходным HTML-кодом. В таких случаях комбинация Selenium и BeautifulSoup или Selenium с lxml будет оптимальным решением.
Итак, если ваша задача – извлечение данных с небольших и средних страниц с нетипичными ошибками в коде, используйте BeautifulSoup. Для производительных решений с обработкой больших объёмов данных отдавайте предпочтение lxml. Если вы работаете с динамическими веб-страницами, комбинируйте Selenium с одной из этих библиотек.
Подключение и настройка BeautifulSoup для работы с HTML
Для работы с библиотекой BeautifulSoup необходимо установить её через пакетный менеджер pip. Откройте терминал и выполните команду:
pip install beautifulsoup4
Кроме самой библиотеки BeautifulSoup, для парсинга HTML требуется библиотека lxml или html5lib. Для установки lxml используйте:
pip install lxml
После установки нужных пакетов, импортируйте BeautifulSoup и парсер, который будете использовать. Например:
from bs4 import BeautifulSoup
Для создания объекта BeautifulSoup из HTML-кода, передайте строку с HTML и выберите парсер. Обычно используют «lxml», так как он быстрее и эффективнее:
soup = BeautifulSoup(html_content, "lxml")
Для простоты работы с документами, удобно использовать функцию requests для получения HTML-страниц. Установите её командой:
pip install requests
Пример кода с использованием requests:
import requests
from bs4 import BeautifulSoup
response = requests.get('https://example.com')
soup = BeautifulSoup(response.text, 'lxml')
Теперь вы можете манипулировать HTML-структурой страницы, например, извлекать все ссылки:
links = soup.find_all('a')
for link in links:
print(link.get('href'))
При работе с BeautifulSoup важно помнить, что парсинг больших страниц может занимать время, поэтому если вам нужно работать с большими объёмами данных, рассмотрите возможность использования многозадачности или асинхронного кода.
Как извлечь данные из таблиц с помощью HTML парсера

Для извлечения данных из таблиц HTML страницы используйте библиотеки, такие как BeautifulSoup или lxml, которые позволяют легко работать с DOM-структурой. Важно правильно идентифицировать таблицу и извлечь нужные данные, учитывая структуру HTML. Пример на Python с использованием BeautifulSoup:
Для начала загрузите HTML-документ с помощью requests или другого инструмента, затем создайте объект BeautifulSoup:
from bs4 import BeautifulSoup import requests url = 'http://example.com/table_page' response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser')
Далее, найдите таблицу с помощью метода find() или find_all(). Например, чтобы извлечь первую таблицу на странице:
table = soup.find('table')
Для получения данных из строк таблицы используйте метод find_all('tr'), который возвращает все строки таблицы. Каждая строка состоит из ячеек td или заголовков th:
rows = table.find_all('tr')
for row in rows:
columns = row.find_all(['td', 'th'])
data = [col.text.strip() for col in columns]
print(data)
Если таблица содержит классы или идентификаторы, это можно учесть, чтобы сузить поиск. Например, для таблицы с классом 'data-table':
table = soup.find('table', class_='data-table')
Чтобы извлечь конкретные столбцы, например, первый столбец, можно пройтись по строкам и выбрать ячейку по индексу:
for row in rows:
columns = row.find_all('td')
if columns:
first_column = columns[0].text.strip()
print(first_column)
В некоторых случаях таблицы могут быть динамически изменены с помощью JavaScript. В таких случаях можно использовать Selenium для работы с динамическими страницами или извлечь данные напрямую через API, если оно доступно.
Использование CSS-селекторов для точного поиска элементов
CSS-селекторы представляют собой мощный инструмент для точного поиска элементов в HTML-документах. Использование этих селекторов позволяет минимизировать количество лишних данных при парсинге и ускорить процесс извлечения информации.
Для начала важно понимать структуру CSS-селекторов. Наиболее часто используемые селекторы включают:
- Поиск по тегу: позволяет выбрать все элементы с определённым тегом. Например, селектор
divнайдёт всеэлементы на странице.- Поиск по классу: селектор вида
.class-nameнаходит все элементы с указанным классом. Важно учитывать, что классы могут быть использованы несколько раз на странице.- Поиск по ID: селектор вида
#id-nameвыбирает единственный элемент с конкретным ID. Это самый быстрый способ поиска, так как ID всегда уникален.- Комбинированные селекторы: для точности можно комбинировать селекторы. Например,
div#container .itemнайдёт элементы с классомitemвнутри элемента с IDcontainer.Для ещё более точного поиска можно использовать псевдоклассы и псевдоэлементы:
- :first-child – выбирает первый элемент в родительском контейнере.
- :nth-child(n) – позволяет выбрать элемент по его порядковому номеру в родительском контейнере.
- :not() – исключает элементы, соответствующие определённому селектору. Например,
div:not(.exclude)выберет все, не имеющие классexclude.Для более сложных запросов можно использовать атрибутные селекторы. Например,
[type="text"]выберет все элементы с атрибутомtype, равнымtext.Использование нескольких селекторов одновременно позволяет сузить область поиска. Пример:
div.container > ul.list > li.item:nth-child(2)Такой запрос найдет второй элемент
- в списке
- , который находится внутри контейнера
- Очистка данных. Это важный шаг, на котором вы избавляетесь от мусора (нежелательные теги, пробелы, символы). Для этого можно использовать регулярные выражения или методы, встроенные в библиотеку парсера, например, BeautifulSoup.
- Структурирование данных. Извлеченные элементы могут быть в разрозненных формах. Преобразование их в структурированные формы, такие как списки, словари или JSON, помогает упростить дальнейшую работу. Например, если вы парсите новости с сайта, можно создать список с элементами типа «заголовок», «ссылка», «дата публикации».
- Фильтрация. После извлечения данных важно их отфильтровать, чтобы оставить только нужную информацию. Например, можно отсортировать элементы по дате, удалить дублирующиеся записи или оставить только те, которые соответствуют определенным условиям (например, по ключевым словам).
- Хранение в базе данных. Если данных много и их нужно будет обрабатывать или обновлять, идеальным вариантом будет база данных (например, SQLite, PostgreSQL, MySQL). Это позволит вам эффективно выполнять запросы и манипулировать данными.
- Файлы. Для простых случаев можно сохранять данные в текстовых файлах, CSV или JSON. JSON удобен для хранения структурированных данных, а CSV – для табличных данных. Эти форматы можно легко интегрировать с другими системами и использовать для дальнейшего анализа.
- API. В случае, если вы хотите передавать извлеченные данные в другие приложения или сервисы, можно использовать API. В этом случае данные можно отправлять в реальном времени через HTTP-запросы, используя форматы, такие как JSON или XML.
- Не закрытые теги.
- Некорректно вложенные элементы.
- Неожиданные символы или атрибуты.
- Ошибки в кодировке символов.
- Неопределенные или недостающие атрибуты.
с классомcontainer.Важной особенностью CSS-селекторов является их производительность. Для сложных структур, где требуется обрабатывать большое количество элементов, правильное использование комбинаций классов, ID и псевдоклассов помогает значительно ускорить поиск. Однако важно помнить, что слишком сложные селекторы могут замедлить процесс, особенно на больших страницах с множеством вложенных элементов.
Как обрабатывать и сохранять данные после парсинга
После извлечения данных с помощью HTML-парсера необходимо их обработать и сохранить. Этот процесс включает несколько ключевых этапов: фильтрацию, структурирование и выбор подходящего формата хранения. Рассмотрим, как это можно сделать эффективно.
Прежде чем начать обработку, важно точно понимать, какие данные вам нужны. Это помогает исключить ненужную информацию и ускорить обработку. Например, если вам нужно извлечь только текстовые данные, то лишние HTML-теги можно сразу удалить.
После того как данные подготовлены, необходимо выбрать способ их хранения. Это зависит от объема информации и задач, которые вы решаете:
Не забывайте об обработке ошибок при сохранении данных. Например, если в процессе записи данных в базу данных произошел сбой, важно предусмотреть механизмы для повторной попытки записи или логирования ошибок для последующего анализа.
Наконец, если парсинг и обработка данных выполняются регулярно, стоит настроить автоматическое выполнение скриптов и хранение данных, например, с использованием планировщика задач или облачных решений для обработки больших объемов информации в реальном времени.
Парсинг динамически загружаемых данных с JavaScript
Динамическая загрузка данных с использованием JavaScript становится всё более популярной на современных веб-сайтах. Такие данные не всегда доступны через обычные HTTP-запросы, так как они подгружаются асинхронно, часто с использованием технологий вроде AJAX или Fetch API. Для их извлечения необходимо применить особые подходы и инструменты.
Для начала, стоит понимать, что динамически загружаемые данные не всегда отображаются в исходном HTML-коде страницы, а формируются в процессе выполнения JavaScript. Это означает, что стандартный парсинг с использованием библиотек типа BeautifulSoup не будет работать. Поэтому следует использовать методы, которые позволяют взаимодействовать с JavaScript-кодом или имитировать выполнение сценариев.
Одним из популярных инструментов для парсинга таких данных является библиотека Selenium. Она позволяет управлять браузером, эмулировать действия пользователя и получать доступ к элементам страницы после выполнения всех скриптов. Для этого можно открыть страницу в фоновом режиме, дождаться загрузки всех данных и затем извлечь нужные элементы через DOM.
Вместо Selenium для менее ресурсоёмких решений можно использовать библиотеку Playwright. Она работает аналогично Selenium, но более эффективна в плане производительности. Playwright поддерживает работу с несколькими браузерами, включая Chromium, Firefox и WebKit, и предоставляет удобный API для автоматизации загрузки данных с динамических страниц.
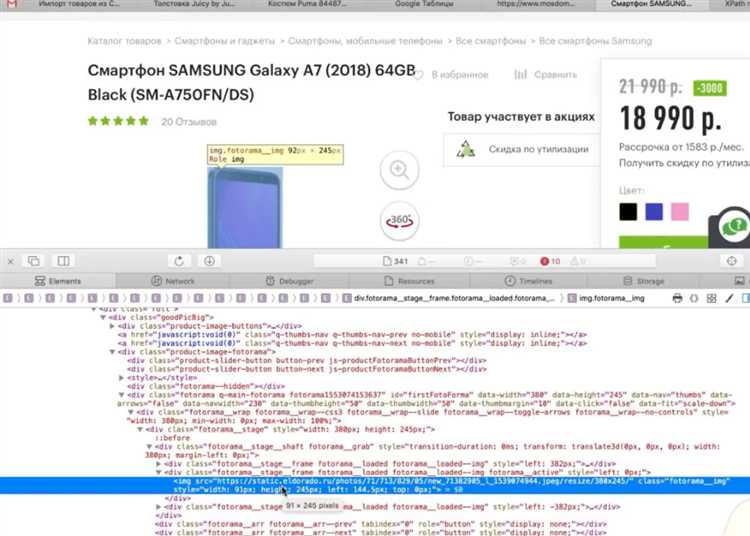
Если данные загружаются через API, можно использовать инструмент для мониторинга сетевых запросов в браузере (например, инструменты разработчика в Chrome). В консоли можно отслеживать, какие запросы отправляются при подгрузке данных, и, если эти запросы доступны, извлекать их с помощью Python-библиотек, таких как requests или aiohttp. После того как вы найдете нужный запрос, можно воспроизвести его в коде и получить данные в формате JSON или XML.
Также полезным методом является анализ JavaScript-кода страницы. Иногда можно найти запросы или данные, закодированные непосредственно в скриптах, что позволяет извлекать информацию без необходимости взаимодействовать с сервером. Для этого можно использовать регулярные выражения или библиотеку PyQuery для работы с кодом страницы.
Наконец, если динамическая загрузка данных происходит с помощью WebSocket или других технологий реального времени, можно использовать библиотеки для работы с такими протоколами, например, websockets в Python. Это позволяет отслеживать события в реальном времени и получать данные сразу после их появления на странице.
Обработка ошибок и некорректного HTML кода в парсере
При работе с HTML-парсерами важно учитывать возможность некорректного или поврежденного HTML-кода. Такой код может привести к сбоям в парсере или неточным результатам. Чтобы минимизировать эти проблемы, необходимо правильно обрабатывать ошибки и учитывать особенности работы с некорректными данными.
Основные виды ошибок, с которыми сталкиваются парсеры HTML:
Чтобы парсер корректно обрабатывал такие ошибки, стоит использовать несколько методов.
1. Автоматическая обработка некорректного HTML с помощью парсера
Современные парсеры, такие как BeautifulSoup или lxml, могут автоматически исправлять некоторые типы ошибок в HTML. Например, они могут закрывать теги, если они не были закрыты, или корректировать вложенность элементов. Это значительно упрощает задачу, особенно при работе с неполными или поврежденными страницами.
2. Исключение ошибок с использованием строгих режимов
Для повышения надежности можно включить строгий режим обработки HTML, который будет генерировать ошибку при нахождении некорректного кода. Например, в lxml можно использовать параметр «recover=False», что заставляет парсер выбрасывать исключение при поврежденном коде, а не пытаться его исправить.
3. Логирование ошибок

Важной частью обработки ошибок является логирование. Даже если парсер сам исправляет ошибку, полезно вести журнал всех исправлений. Это поможет понять, с какими типами ошибок сталкивается парсер, и принять меры для их минимизации. Для этого можно использовать встроенные средства логирования, такие как Python’s logging.
4. Проверка на валидность HTML перед парсингом
Для предотвращения ошибок можно использовать инструменты для проверки валидности HTML. Например, можно использовать валидаторы, такие как W3C HTML Validator, чтобы заранее выявить ошибки. Это особенно полезно при парсинге сторонних страниц, где код может быть не всегда идеальным.
5. Обработка непредвиденных ошибок
Некорректный HTML может привести к неожиданным ситуациям. В таких случаях следует использовать конструкцию try-except, чтобы обрабатывать исключения и избежать падения парсера. Важно предусмотреть различные сценарии, например, пустые теги или недостающие атрибуты.
6. Использование библиотеки для предварительного очищения HTML
Существуют инструменты, такие как HTML Tidy или html5lib, которые помогают очищать HTML перед парсингом. Эти библиотеки могут удалять лишние пробелы, исправлять ошибки в структуре документа и преобразовывать код в валидный формат, что значительно облегчает процесс извлечения данных.
7. Обработка ошибок на уровне данных
После того как HTML будет обработан, важно уделить внимание корректности извлекаемых данных. Ошибки могут проявляться не только на уровне структуры документа, но и на уровне самих данных. Например, отсутствие необходимых данных в элементах или неожиданные типы значений. В таких случаях следует использовать дополнительные проверки на соответствие типов и форматирование данных.
8. Протестировать парсер на реальных данных
Одним из лучших способов убедиться в устойчивости парсера является тестирование на различных реальных страницах с разными ошибками в коде. Это позволяет не только проверить, как парсер справляется с некорректным HTML, но и выявить слабые места в логике обработки ошибок.
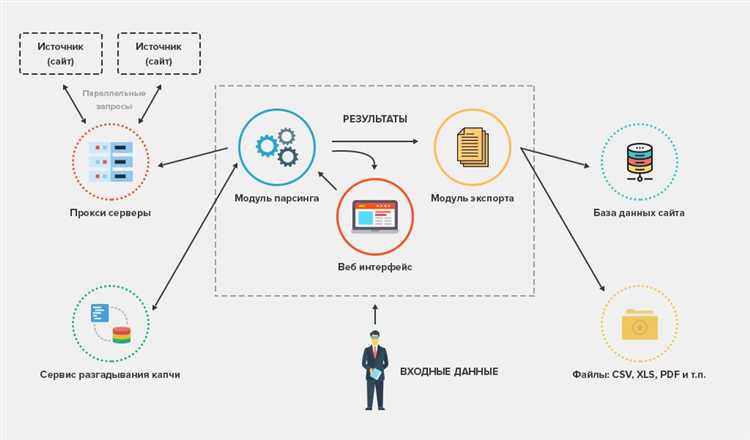
Автоматизация сбора данных с веб-страниц с помощью парсера
Парсинг веб-страниц позволяет автоматизировать сбор структурированных данных из интернет-источников. Чтобы настроить эффективный процесс автоматического извлечения данных, следует учитывать несколько ключевых аспектов.
Выбор парсера. Наиболее популярные библиотеки для автоматизации сбора данных включают BeautifulSoup (Python) и Cheerio (JavaScript). Они позволяют легко извлекать текст, ссылки, изображения и другие элементы из HTML-страниц, обрабатывая их в виде дерева элементов. Для более сложных задач, таких как работа с динамическими сайтами, потребуется использовать такие инструменты, как Selenium или Puppeteer, которые имитируют действия пользователя в браузере.
Обработка структуры HTML. Для автоматизации важно правильно анализировать структуру HTML. Выделение данных из элементов страницы требует использования CSS-селекторов или XPath, что дает точное указание на местоположение нужных данных. Например, чтобы получить все заголовки новостей на сайте, нужно выбрать соответствующие теги, используя их классы или идентификаторы.
Обработка ошибок. В процессе парсинга могут возникать ошибки, связанные с изменениями в структуре веб-страницы, отсутствием нужных элементов или проблемами с сетевым соединением. Важно предусмотреть механизмы для обработки таких ситуаций, например, с помощью блоков try-except или регулярной проверки состояния страницы.
Обработка динамического контента. Многие современные сайты используют JavaScript для динамической загрузки контента. В таких случаях парсеры, которые могут работать с динамическими страницами, становятся необходимыми. Selenium, например, позволяет взаимодействовать с элементами, подгружаемыми через JavaScript, что делает его отличным выбором для таких задач.
Частота запросов. При автоматизации сбора данных важно соблюдать разумный интервал между запросами. Частые запросы к серверу могут привести к блокировке или ограничению доступа. Использование библиотек для задержек, таких как time.sleep в Python, помогает избежать излишней нагрузки на сервер.
Масштабируемость. Для крупных проектов, где требуется собирать данные с множества страниц, важно учитывать возможность масштабирования. Использование многозадачности и асинхронных операций, например, с библиотеками asyncio или threading, позволяет ускорить процесс парсинга и эффективно распределить нагрузку.
Сохранение и хранение данных. После извлечения данных необходимо продумать, как их сохранить. Для небольших объемов можно использовать файлы CSV или JSON, но для масштабируемых решений стоит рассматривать базы данных (например, PostgreSQL или MongoDB). Это обеспечит быструю обработку и доступ к данным для дальнейшего анализа.
Вопрос-ответ:
Что такое HTML парсер и как он работает?
HTML парсер — это инструмент, который анализирует HTML-код веб-страниц и извлекает нужные данные. Он работает, проходя по структуре документа, находя теги, атрибуты и их содержимое, чтобы предоставить пользователю нужную информацию. Этот процесс может включать в себя извлечение текстовых данных, ссылок, изображений, таблиц и других элементов.
Как выбрать подходящий HTML парсер для проекта?
Выбор парсера зависит от нескольких факторов, таких как язык программирования, с которым вы работаете, и требования к скорости или точности обработки данных. Например, для Python популярными являются BeautifulSoup и lxml, а для JavaScript — Cheerio. Важно учитывать, насколько легко парсер справляется с различными структурами HTML, его совместимость с другими библиотеками и производительность при больших объемах данных.
Можно ли использовать HTML парсер для работы с динамическими веб-страницами, загружающими контент через JavaScript?
Стандартные HTML парсеры, такие как BeautifulSoup, не могут корректно обработать контент, загружаемый через JavaScript, потому что они анализируют только статический HTML. Для работы с такими страницами необходимо использовать дополнительные инструменты, такие как Selenium или Playwright, которые позволяют эмулировать работу браузера и загружать динамически изменяющиеся данные. Эти инструменты позволяют получать HTML-страницу уже после выполнения всех скриптов JavaScript, что делает возможным извлечение информации с таких сайтов.
 (пока оценок нет)
(пока оценок нет) Загрузка...Поделиться с друзьями:ТвитнутьПоделитьсяПоделитьсяОтправитьКласснуть
Загрузка...Поделиться с друзьями:ТвитнутьПоделитьсяПоделитьсяОтправитьКласснуть - в списке
- Поиск по классу: селектор вида