Копирование HTML-страницы позволяет изучить структуру сайта, сохранить её локально или адаптировать под собственные нужды. В зависимости от цели и уровня подготовки можно использовать ручной способ или специализированные инструменты. В этой статье рассмотрены оба подхода с указанием конкретных шагов и рекомендаций.
Ручной метод подходит для простых сайтов с минимальным количеством JavaScript. Откройте нужную страницу в браузере, нажмите правой кнопкой мыши и выберите «Просмотреть код страницы» (или нажмите Ctrl+U в Windows / Cmd+Option+U в macOS). Скопируйте HTML-код в редактор кода (например, VS Code или Sublime Text). Обратите внимание: медиафайлы, стили и скрипты не сохраняются автоматически – их необходимо загружать отдельно через инструменты разработчика.
Программы и утилиты позволяют автоматизировать процесс. HTTrack – бесплатная десктопная программа для Windows и Linux, скачивает весь сайт целиком, включая изображения, CSS и JS. Для более гибкого управления используйте Wget с параметрами --mirror и --convert-links. В среде macOS удобно использовать SiteSucker, который копирует сайт в несколько кликов. Для анализа SPA-сайтов, построенных на фреймворках вроде React или Vue, потребуется Puppeteer или Playwright – инструменты, способные рендерить JavaScript перед сохранением DOM.
Выбор метода зависит от сложности страницы, объема копируемого контента и необходимости в сохранении интерактивности. Важно учитывать авторские права при копировании и использовать полученные материалы исключительно в рамках допустимого.
Как сохранить HTML-код страницы через браузер
Чтобы сохранить HTML-код интересующей страницы, откройте её в браузере и выполните следующие действия:
1. Кликните правой кнопкой мыши по свободной области страницы и выберите пункт «Просмотреть исходный код» (в Google Chrome) или «Исходный код страницы» (в Firefox).
2. В открывшемся окне с HTML-кодом нажмите сочетание клавиш Ctrl+S (или Cmd+S на macOS).
3. В появившемся диалоговом окне выберите место для сохранения и укажите формат «Веб-страница, только HTML» или аналогичный, в зависимости от браузера.
4. Подтвердите сохранение. Будет создан файл с расширением .html.
Особенности сохранения в популярных браузерах:
| Браузер | Действие |
|---|---|
| Chrome | Файл → Сохранить как… → Веб-страница, только HTML |
| Firefox | Файл → Сохранить страницу как… → Только HTML |
| Edge | Ctrl+S → Сохранить как → Тип файла: Веб-страница, только HTML |
Если требуется сохранить HTML без форматирования, откройте исходный код, скопируйте его (Ctrl+A → Ctrl+C) и вставьте в текстовый редактор (например, Notepad++ или VS Code), затем сохраните с расширением .html.
Как скачать страницу вместе с изображениями и стилями
Для полной загрузки HTML-страницы со всеми изображениями, CSS и шрифтами следует использовать специализированные инструменты. Один из наиболее эффективных – утилита Wget, доступная на Windows, macOS и Linux.
Команда для скачивания:
wget --mirror --convert-links --page-requisites --no-parent https://example.com
Опция --mirror активирует режим рекурсивной загрузки, --convert-links переписывает ссылки для локального просмотра, --page-requisites загружает все необходимые ресурсы (изображения, CSS, JS), а --no-parent ограничивает загрузку только указанной директорией.
В Windows альтернативный способ – программа HTTrack Website Copier. После установки нужно указать URL страницы, выбрать локальную папку для сохранения и включить опции загрузки внешних ресурсов. HTTrack сохранит структуру сайта и все файлы, включая изображения и стили.
В браузере Google Chrome можно сохранить страницу вручную: нажать Ctrl+S (или Cmd+S на Mac), выбрать тип сохранения «Веб-страница, полностью» и указать путь. Однако такой способ не сохраняет внешние зависимости, загружаемые динамически через JavaScript.
Для сайтов с защитой от копирования или динамической загрузкой контента (например, через AJAX) понадобится использовать браузерные расширения вроде SingleFile, которое сохраняет всю страницу в одном .html файле, включая встроенные стили и изображения как base64-код.
Использование инструмента «Просмотр кода» для копирования фрагментов HTML
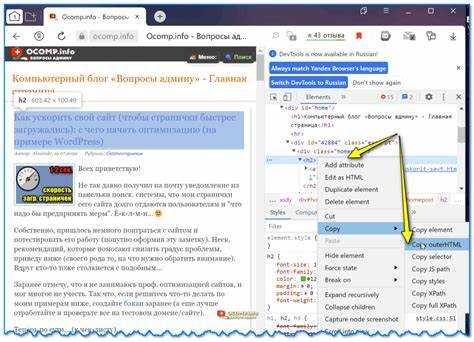
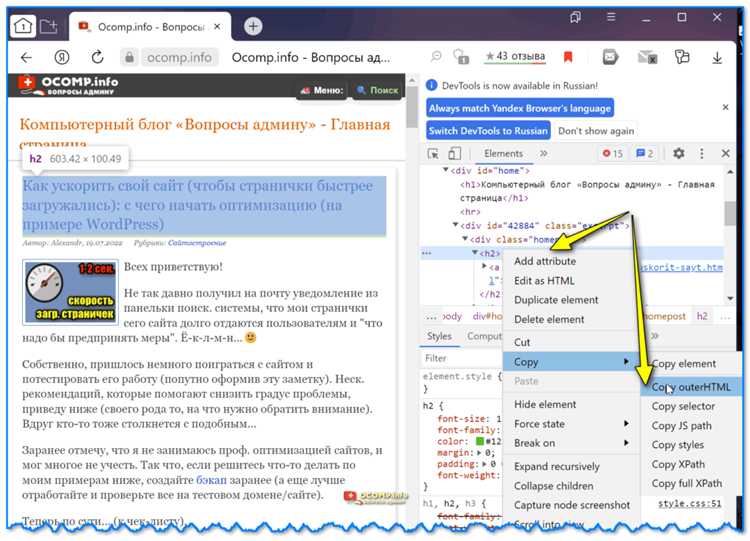
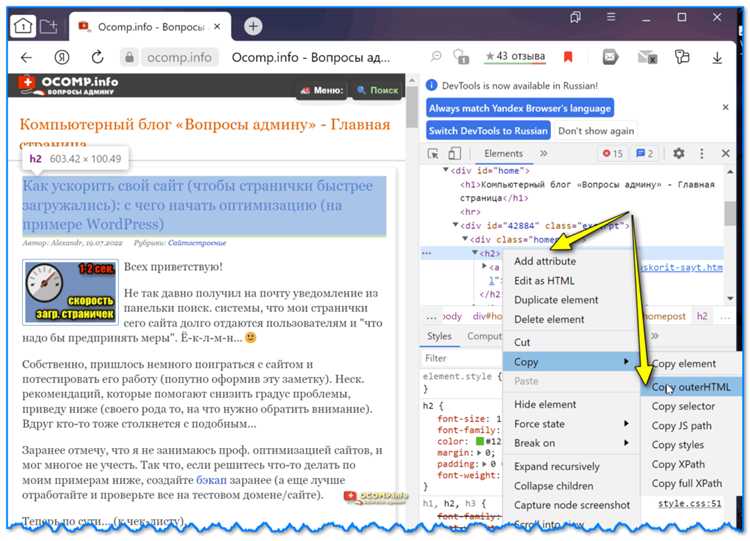
Откройте нужную страницу в браузере. Нажмите правой кнопкой мыши на интересующий элемент и выберите пункт «Просмотреть код» (или «Inspect» в англоязычных версиях). Панель разработчика отобразит HTML-структуру сайта с автоматически выделенным элементом.
Чтобы скопировать нужный фрагмент, выделите соответствующий блок HTML в дереве элементов. Нажмите правой кнопкой мыши и выберите «Copy» → «Copy element» или «Copy outerHTML». Первый вариант копирует только HTML-содержимое без контейнерного тега, второй – вместе с ним.
Если требуется только текст или часть структуры, выделите вручную нужные строки и используйте сочетание клавиш Ctrl+C (Cmd+C на Mac). Обратите внимание, что атрибуты, такие как классы и идентификаторы, сохраняются, что позволяет впоследствии использовать скопированный код с сохранением внешнего вида при наличии нужных CSS.
Для повышения точности копирования переключитесь на вкладку «Elements» и используйте навигацию по иерархии DOM. Наведение курсора на строки в панели подсвечивает соответствующие участки на странице, что помогает избежать ошибок при выборе блока.
Не копируйте слишком большие фрагменты сразу – это может привести к захвату лишнего кода или вложенных скриптов. Лучше работать с небольшими участками, проверяя результат в редакторе кода.
Как скопировать HTML-страницу с помощью расширений браузера
SingleFile – одно из самых точных расширений для сохранения HTML-страниц. Оно сохраняет всю страницу в один файл, включая стили, изображения и скрипты. После установки расширения в Chrome или Firefox, откройте нужную страницу, нажмите на иконку SingleFile, затем – «Сохранить страницу». Файл будет иметь расширение .html и откроется в любом браузере.
Save Page WE – альтернативный инструмент с более гибкими настройками. Позволяет исключать скрипты, выбирать формат сохранения и регулировать структуру ресурсов. Подходит для архивирования и офлайн-доступа. Для использования – нажмите на иконку расширения и выберите нужные параметры перед сохранением.
Web Scraper ориентирован на извлечение структурированных данных, но его можно использовать для получения HTML-кода отдельных элементов или всей страницы. Создайте схему («site map»), укажите нужные элементы, запустите скрапинг, экспортируйте результат в HTML.
Важно: некоторые сайты используют динамическую подгрузку контента (JavaScript). В этом случае сохранённый HTML может отличаться от оригинала. Для корректного копирования используйте расширения с поддержкой отложенной загрузки или инструменты разработчика для предварительного рендеринга.
Применение утилиты wget для скачивания полной HTML-страницы
Утилита wget позволяет сохранить HTML-страницу вместе со всеми связанными ресурсами: стилями, изображениями, скриптами. Это полезно для автономного просмотра или анализа структуры сайта.
- Откройте терминал в системе Linux, macOS или используйте командную строку Windows (при наличии wget).
- Для загрузки полной страницы выполните команду:
wget --mirror --convert-links --page-requisites --no-parent https://example.com/page
--mirrorвключает рекурсивную загрузку и сохранение с временными метками.--convert-linksпреобразует ссылки для корректной работы в офлайн-режиме.--page-requisitesобеспечивает загрузку всех зависимостей страницы (CSS, JS, изображения).--no-parentзапрещает переход к родительским каталогам сайта.
Файлы сохраняются в текущую директорию. Структура каталогов соответствует исходной структуре URL. Для ограничения глубины загрузки используйте флаг -l, например, -l 1 скачает только указанную страницу без перехода по ссылкам.
Для обхода блокировок серверов можно задать User-Agent:
wget --user-agent="Mozilla/5.0" https://example.com/pageЕсли сайт требует аутентификацию, используйте флаги --user и --password:
wget --user=имя --password=пароль https://example.com/secure-pageДля автоматизации добавьте команды в скрипт и запускайте по расписанию через cron или планировщик задач.
Как использовать программу HTTrack для клонирования сайта
Первоначально необходимо скачать и установить программу с официального сайта HTTrack. После установки откройте программу и создайте новый проект. Введите название проекта, укажите категорию и задайте директорию, куда будут сохраняться скачанные файлы.
На следующем шаге укажите URL сайта, который хотите склонировать. HTTrack поддерживает возможность скачивания как одного веб-ресурса, так и нескольких сайтов. Важно настроить параметры, чтобы скачать именно те ресурсы, которые вам нужны – можно указать, какие типы файлов нужно игнорировать (например, изображения или скрипты). Настройки фильтров помогут избежать загрузки ненужных данных.
Далее, HTTrack предложит выбрать режим работы: стандартный или с дополнительными настройками. В большинстве случаев стандартные настройки подходят для большинства сайтов, однако если необходимо скачать только определенные страницы или ограничить глубину переходов, можно использовать расширенные параметры. Это важно, если сайт имеет сложную структуру с большим количеством ссылок.
После того как все настройки завершены, начнется процесс клонирования. HTTrack будет скачивать все страницы сайта, сохраняя структуру директорий, а также ресурсы, такие как изображения, CSS-файлы, JavaScript и другие. Процесс может занять некоторое время в зависимости от размера сайта и качества вашего интернет-соединения.
При клонировании сайта важно соблюдать правила авторского права и использовать программу в рамках закона. HTTrack не предоставляет возможности автоматической фильтрации правомерности контента, поэтому следует заранее убедиться, что копирование материала не нарушает права владельцев сайта.
После завершения скачивания вы получите полный локальный архив сайта, который можно будет просматривать через браузер без подключения к интернету. Важно помнить, что склонированный сайт не будет автоматически обновляться. Для получения актуальных данных потребуется регулярно запускать процесс клонирования.
Ручное копирование HTML-страницы в текстовый редактор и её редактирование

Ручное копирование HTML-страницы в текстовый редактор начинается с открытия исходной страницы в браузере. Для этого нужно использовать инструменты разработчика или контекстное меню браузера, чтобы просмотреть исходный код. Далее описаны шаги для эффективного копирования и редактирования HTML.
1. Откройте страницу в браузере и перейдите в режим просмотра исходного кода. В большинстве современных браузеров для этого достаточно нажать клавишу Ctrl+U или вызвать контекстное меню и выбрать «Просмотреть исходный код».
2. Скопируйте весь HTML-код. В режиме просмотра исходного кода выберите весь текст (Ctrl+A), затем скопируйте его в буфер обмена (Ctrl+C).
3. Откройте текстовый редактор, поддерживающий работу с кодом, например, Notepad++, Sublime Text или Visual Studio Code. Вставьте скопированный код в новый файл (Ctrl+V).
4. Редактирование HTML-кода. После того как код окажется в редакторе, можно начать его редактирование. Важно понимать структуру HTML, чтобы изменения не нарушили функционирование страницы:
- Теги: Изменяйте существующие теги или добавляйте новые, чтобы изменить структуру контента.
- Атрибуты: Корректируйте атрибуты тегов (например,
srcу<img>,hrefу<a>), чтобы изменить ссылки, изображения или другие элементы. - Стиль и оформление: Если страница использует встроенные стили (например, через атрибут
style), их можно менять прямо в коде. - Скрипты: Если на странице есть JavaScript, его можно редактировать, чтобы изменить логику взаимодействия с пользователем.
5. Сохранение изменений. После редактирования сохраните файл в формате .html. Для тестирования изменений откройте файл в браузере.
6. Проверка на ошибки. В процессе редактирования важно следить за правильностью структуры HTML, чтобы избежать ошибок отображения. Например, отсутствие закрывающих тегов или неправильное вложение элементов может повлиять на внешний вид страницы.
7. Дополнительные рекомендации:
- Используйте редактор с подсветкой синтаксиса, чтобы легче находить ошибки.
- После каждого изменения проверяйте страницу в браузере, чтобы удостовериться, что всё отображается корректно.
- Избегайте редактирования динамических элементов, таких как серверные скрипты или базы данных, если вы не знакомы с их функциями.
Вопрос-ответ:
Как вручную скопировать HTML-страницу?
Для того чтобы вручную скопировать HTML-страницу, можно использовать функцию «Просмотр кода страницы» в браузере. Откройте нужную страницу, затем щелкните правой кнопкой мыши и выберите «Просмотр кода страницы» или аналогичную опцию. В открывшемся окне будет представлен весь HTML-код страницы. Выделите этот код, скопируйте и вставьте в текстовый редактор. Сохраните файл с расширением «.html», чтобы получить точную копию страницы.
Можно ли скопировать HTML-страницу с помощью программы?
Да, для копирования HTML-страницы с помощью программы можно использовать специальные инструменты или написание скрипта. Один из самых простых способов — это использование Python и библиотеки BeautifulSoup или requests. С помощью этих инструментов можно автоматически загрузить HTML-код страницы и сохранить его на компьютере. Например, с помощью команды «requests.get(url)» можно получить HTML-код страницы, а затем сохранить его в файл. Это удобный метод для массового скачивания страниц.
Что нужно учитывать при копировании HTML-страницы?
При копировании HTML-страницы важно учитывать, что, помимо самого кода страницы, могут быть скрипты, стили и изображения, которые не будут скопированы с помощью обычного метода. Если вы хотите полностью сохранить страницу, включая все элементы, лучше использовать такие программы, как HTTrack или Wget, которые скачивают не только HTML, но и все связанные с ним ресурсы (картинки, стили, JavaScript). Также стоит помнить о правовых аспектах копирования контента с других сайтов, поскольку это может нарушать авторские права.
Как использовать программу Wget для копирования HTML-страницы?
Программа Wget позволяет скачать HTML-страницу и все её ресурсы. Для этого нужно открыть командную строку и выполнить команду «wget -p -k URL», где «URL» — это адрес страницы. Опция «-p» указывает на скачивание всех ресурсов, таких как изображения и стили, а «-k» преобразует все ссылки на страницы в локальные, чтобы их можно было открыть без доступа к интернету. Эта команда сохраняет структуру сайта и делает его доступным для работы офлайн.
Можно ли копировать HTML-страницу через браузер с сохранением всех стилей и картинок?
Да, для этого можно использовать функцию «Сохранить как» в браузере. Откройте страницу, затем нажмите правую кнопку мыши и выберите «Сохранить как» или аналогичную опцию в меню браузера. В открывшемся окне выберите формат «Веб-страница, полностью» или похожий вариант. Это сохранит HTML-код страницы вместе с внешними файлами (картинки, стили, шрифты). Однако, такой метод имеет свои ограничения, так как некоторые ресурсы могут не сохраниться, если они загружаются через сторонние серверы или динамически генерируются.
Как можно скопировать HTML-страницу вручную?
Для того чтобы скопировать HTML-страницу вручную, нужно выполнить несколько шагов. Сначала откройте страницу в браузере. Затем, кликнув правой кнопкой мыши, выберите опцию «Посмотреть код страницы» или «Просмотр исходного кода». В открывшемся окне будет представлен исходный код HTML. Вы можете выделить весь код, скопировать его и сохранить в текстовом редакторе, например, в Notepad или Sublime Text. Этот метод позволяет получить только исходный код страницы без дополнительных файлов, таких как изображения или стили, которые могут быть загружены отдельно.