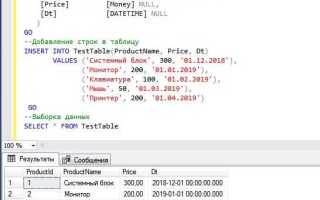
Выбор столбцов в SQL-запросе напрямую влияет на производительность и читаемость кода. При построении эффективных запросов важно ограничивать извлечение данных только теми столбцами, которые реально необходимы для текущей задачи. Это не только ускоряет выполнение запроса, но и снижает нагрузку на систему, особенно когда работа идет с большими объемами данных.
При написании SQL-запроса всегда задавайте себе вопрос: «Какие именно данные мне нужны?» Вместо использования универсального подхода с * (звездочкой), лучше явно указывать перечень столбцов. Например, если вам нужно получить информацию о сотрудниках, указывайте только те поля, которые действительно важны для анализа – например, имя, должность и зарплата. Запросы с явным указанием столбцов, как правило, быстрее обрабатываются и проще оптимизируются.
Дополнительной причиной для выбора нужных столбцов является возможность работы с индексацией. SQL-оптимизаторы часто могут улучшить выполнение запросов, если они видят, что используются только те поля, которые индексируются. Запросы, затрагивающие только индексированные столбцы, работают значительно быстрее. Например, если запрос находит информацию по дате рождения сотрудников, то следует убедиться, что этот столбец индексирован.
Еще одним важным аспектом является уменьшение объема передаваемых данных. Чем меньше столбцов вы запрашиваете, тем меньше данных нужно передавать по сети, что критично для распределенных систем. Это также способствует сокращению времени отклика приложения и снижению потребности в памяти.
Таким образом, выбор столбцов не должен быть случайным, а должен базироваться на реальных требованиях задачи, а также учитывать принципы оптимизации производительности. Осознанный подход к формулировке запроса приведет к значительным улучшениям в скорости работы системы и упрощению дальнейшего анализа данных.
Определение столбцов в запросе на основе задачи

При формировании SQL-запроса важно точно понимать, какие столбцы необходимо выбрать для выполнения конкретной задачи. Выбор столбцов напрямую зависит от целей, которые стоят перед запросом. От этого зависит не только корректность выполнения, но и производительность запроса.
Основные этапы при выборе столбцов:
- Четкое понимание задачи: необходимо определить, какая информация должна быть извлечена. Например, если задача состоит в вычислении средней зарплаты по каждому отделу, то выбираем только столбцы с данными о зарплатах и отделах.
- Минимизация данных: выбирайте только те столбцы, которые действительно необходимы для получения результата. Это снижает нагрузку на базу данных, улучшая производительность запроса.
- Использование агрегатных функций: если вам нужно вычислить такие показатели, как сумма, среднее или количество, выбирайте соответствующие столбцы и используйте агрегатные функции (SUM, AVG, COUNT и т.д.) для обработки данных.
- Группировка данных: если задача требует агрегации данных по определенному критерию (например, по отделам или регионам), выбирайте только те столбцы, которые участвуют в группировке (например, используя GROUP BY).
- Использование JOIN: если информация находится в разных таблицах, выбирайте только те столбцы, которые необходимы для объединения данных. Использование SELECT * может значительно увеличить нагрузку на сервер, особенно если в таблицах много данных.
Пример:
Задача: Получить список сотрудников с их должностями и заработной платой, работающих в департаменте «Маркетинг».
Запрос:
SELECT name, position, salary FROM employees WHERE department = 'Marketing';
В этом запросе выбираются только те столбцы, которые необходимы для отображения данных, связанные с именем, должностью и зарплатой сотрудников отдела маркетинга.
Пример 2:
Задача: Посчитать среднюю зарплату по каждому отделу.
Запрос:
SELECT department, AVG(salary) AS average_salary FROM employees GROUP BY department;
Здесь выбираются только два столбца: отдел и средняя зарплата, что минимизирует количество извлекаемых данных и ускоряет выполнение запроса.
Заключение: правильный выбор столбцов зависит от понимания задачи и требований к данным. Всегда стремитесь к тому, чтобы запросы извлекали только необходимую информацию, что способствует лучшей производительности и точности результатов.
Как избежать избыточных данных при выборке
Чтобы избежать избыточных данных в запросах SQL, необходимо следовать нескольким принципам, которые позволяют сократить объем выборки, улучшить производительность и уменьшить нагрузку на базу данных.
- Использование SELECT с конкретными столбцами – не следует использовать конструкцию SELECT * в запросах, так как это приводит к выборке всех столбцов таблицы, включая те, которые могут не быть необходимы для выполнения задачи.
- Фильтрация данных – всегда используйте WHERE для ограничения количества строк, которые должны быть выбраны. Это позволяет избежать загрузки ненужных данных и ускорить выполнение запроса.
- Использование агрегатных функций – если вам нужны только обобщенные данные (суммы, средние значения, максимумы и минимумы), применяйте агрегатные функции, такие как COUNT, SUM, AVG, MIN, MAX, для того чтобы не извлекать и не передавать полные данные.
- Использование DISTINCT – в случае, когда нужно избавиться от дубликатов, используйте DISTINCT. Это поможет отфильтровать повторяющиеся строки, если это необходимо, вместо того чтобы делать это вручную после выполнения запроса.
- Применение LIMIT – для выборки только части данных используйте LIMIT. Это особенно важно при тестировании запросов или при необходимости получить только часть информации для предварительного анализа.
- Предпочтение индексации – индексирование столбцов, которые часто участвуют в фильтрации и сортировке, позволяет существенно уменьшить объем данных, обрабатываемых запросом. Однако следует избегать ненужных индексов, так как они могут замедлить операции вставки и обновления данных.
- Нормализация данных – избыточные данные могут быть результатом плохо спроектированной схемы базы данных. Нормализация помогает избежать дублирования данных и снижает объем выборки, делая запросы более эффективными.
Следуя этим рекомендациям, можно эффективно управлять объемом данных, предотвращать избыточные выборки и значительно улучшить производительность запросов SQL.
Использование агрегатных функций для выбора столбцов
Агрегатные функции в SQL помогают обрабатывать данные из нескольких строк, возвращая один результат. Они часто используются в запросах для выбора сводной информации по столбцам, например, сумм, средних значений или минимальных и максимальных значений. Выбор столбцов с помощью агрегатных функций помогает уменьшить объем данных и сосредоточиться на ключевых показателях.
Для использования агрегатных функций необходимо помнить, что они могут работать только с числовыми типами данных или с теми типами, где их применение имеет смысл, например, строками для функции COUNT(). Основные агрегатные функции:
- COUNT() – подсчитывает количество строк. Используется для определения числа записей в столбце или группе.
- SUM() – вычисляет сумму значений столбца. Чаще всего используется для числовых данных, таких как доходы или количество товаров.
- AVG() – вычисляет среднее значение. Подходит для анализа распределения данных по количеству, стоимости и т. д.
- MIN() – возвращает минимальное значение в группе данных.
- MAX() – возвращает максимальное значение в группе данных.
Агрегатные функции обычно применяются в комбинации с оператором GROUP BY. Этот оператор группирует строки, а агрегатные функции выполняют вычисления по каждой группе. Например, если необходимо получить средний доход по каждому отделу, запрос может выглядеть так:
SELECT department, AVG(income) FROM employees GROUP BY department;
В этом случае агрегатная функция AVG() применяется к столбцу income, а данные группируются по значению в столбце department.
Важно помнить, что если запрос использует агрегатные функции, и в нем есть другие столбцы, которые не агрегируются, их необходимо включить в оператор GROUP BY. Например:
SELECT department, MIN(income), MAX(income) FROM employees GROUP BY department;
Если столбцы, по которым не производится агрегация, не включены в GROUP BY, запрос вызовет ошибку. Это гарантирует, что агрегатные функции применяются только к данным внутри каждой группы.
Также можно комбинировать агрегатные функции с условными операторами, такими как HAVING. Этот оператор позволяет фильтровать группы после применения агрегатных функций. Например, чтобы получить департаменты, где средний доход больше 50000, можно использовать следующий запрос:
SELECT department, AVG(income) FROM employees GROUP BY department HAVING AVG(income) > 50000;
Такой подход позволяет выделять только те данные, которые соответствуют заданным критериям, и исключать из результата ненужные группы.
Использование агрегатных функций позволяет эффективно анализировать большие объемы данных, сводить их к ключевым меткам и работать с результатами без необходимости ручного перебора каждой строки. Правильный выбор функций и группировка данных помогает значительно упростить процессы анализа и принятия решений.
Как объединять несколько таблиц и правильно выбирать столбцы
Для начала нужно чётко определить, какие таблицы необходимо объединить. Например, если есть таблицы users и orders, то для извлечения данных о пользователях и их заказах потребуется объединить эти таблицы по общему столбцу – user_id.
После того как решено, какие таблицы будут участвовать в запросе, важно правильно выбрать столбцы для выборки. Лучше всего использовать явные ссылки на столбцы с указанием имени таблицы, чтобы избежать путаницы, особенно если таблицы содержат одинаковые имена столбцов.
Пример запроса:
SELECT users.user_id, users.name, orders.order_id, orders.amount
FROM users
INNER JOIN orders ON users.user_id = orders.user_id;
Здесь столбцы user_id и order_id из разных таблиц чётко указаны с префиксами users и orders. Это позволяет избежать ошибок, если оба столбца имеют одинаковые имена.
Если нужно выбрать только уникальные записи, применяйте DISTINCT. Он позволяет исключить дубликаты строк, что важно при объединении таблиц, если данные из одной таблицы могут несколько раз повторяться из-за наличия связей в другой таблице.
Пример с использованием DISTINCT:
SELECT DISTINCT users.name, orders.amount
FROM users
INNER JOIN orders ON users.user_id = orders.user_id;
Правильный выбор столбцов критичен для производительности. Избыточные или неиспользуемые столбцы увеличивают нагрузку на систему, поскольку данные передаются и обрабатываются лишний раз. Старайтесь выбирать только те столбцы, которые реально необходимы для решения задачи.
Кроме того, при объединении таблиц стоит учитывать типы соединений. Например, INNER JOIN возвращает только те строки, которые имеют совпадения в обеих таблицах, а LEFT JOIN оставляет строки из левой таблицы, даже если в правой таблице нет совпадений. Это также влияет на то, какие данные будут отображаться в результате запроса.
Когда выбор столбцов сделан, и соединения настроены, всегда проверяйте запрос на производительность. Иногда использование подзапросов или временных таблиц может значительно ускорить выполнение запросов с большим количеством объединений.
Оптимизация запросов с помощью выборки только нужных столбцов
Выборка только нужных столбцов в SQL-запросах существенно улучшает производительность, сокращая объем передаваемых данных и ускоряя обработку запросов. Вместо использования универсального оператора SELECT * следует явно указывать те столбцы, которые действительно необходимы для решения задачи. Это особенно важно при работе с большими таблицами, где наличие лишних столбцов может привести к значительному увеличению нагрузки на сервер.
Оптимизация начинается с анализа, какие данные действительно необходимы для конечной задачи. Например, если требуется только имя клиента и его адрес, вместо SELECT * нужно использовать SELECT name, address. Такой подход минимизирует объем данных, которые необходимо извлечь из базы данных.
Кроме того, выборка только нужных столбцов помогает уменьшить потребление памяти и сетевой трафик. Это особенно заметно при выполнении запросов к удаленным базам данных, где каждый дополнительный столбец увеличивает объем передаваемой информации.
Другим важным моментом является улучшение индексации. Когда запрос использует только те столбцы, которые проиндексированы, база данных может эффективно использовать индексы для ускорения поиска. В случае использования SELECT * база данных будет вынуждена сканировать больше столбцов, что может снизить производительность, даже если индексы существуют.
Кроме того, важно учитывать, что избыточные столбцы могут привести к излишнему выполнению операций на сервере, например, при фильтрации или сортировке данных. В некоторых случаях избыточные данные могут вызывать увеличение времени ответа запроса, особенно если происходит сложная агрегация или использование сложных функций.
При проектировании запросов нужно стремиться к тому, чтобы каждый столбец в SELECT был целенаправленно выбран для использования в дальнейших операциях. Применяя такую практику, можно достичь существенного улучшения производительности даже при работе с крупными и сложными базами данных.
Использование индексов для ускорения выборки столбцов
Первое правило – индексировать только те столбцы, которые часто участвуют в условиях фильтрации (WHERE), сортировке (ORDER BY) или соединениях (JOIN). Индексы позволяют базе данных находить строки быстрее, избегая полного сканирования таблицы. Например, если запрос часто фильтрует данные по столбцу «дата», создание индекса на этом столбце ускорит выполнение запросов.
Однако стоит помнить, что создание индекса на каждом столбце не всегда эффективно. Каждый индекс занимает место и требует времени на обновление при вставке, удалении или изменении данных. Поэтому создание индекса на каждом часто используемом столбце не всегда оправдано. Рекомендуется индексировать только те столбцы, которые значительно влияют на производительность запросов.
Для многоколоночных запросов полезно использовать составные индексы. Например, если запрос использует фильтрацию по двум столбцам, создание составного индекса (например, на столбцах «дата» и «статус») позволит значительно ускорить выполнение таких запросов. Важно, чтобы порядок столбцов в индексе соответствовал порядку их использования в запросах.
В случае сложных запросов с множественными соединениями, индексы на столбцах, участвующих в этих соединениях, могут существенно ускорить процесс. Например, если запрос объединяет таблицы по столбцам «id», создание индекса на этом столбце позволит базе данных быстрее находить соответствующие строки в обеих таблицах.
При проектировании базы данных важно учитывать характер запросов, которые будут выполняться наиболее часто. Прежде чем создавать индексы, стоит проанализировать типичные запросы и их частоту. Для этого можно использовать инструменты мониторинга и анализа запросов, такие как EXPLAIN в PostgreSQL или SQL Server Profiler, чтобы понять, какие столбцы становятся узким местом в производительности.
Неправильное использование индексов, например, создание индекса на столбцах, которые редко используются в фильтрах или соединениях, может не только не ускорить запросы, но и замедлить их из-за дополнительных затрат на обновление индексов. Поэтому важно тщательно выбирать, какие столбцы индексировать, чтобы улучшить производительность без лишних накладных расходов.
Вопрос-ответ:
Какие столбцы следует выбирать в SQL-запросе?
При выборе столбцов в SQL-запросе важно учитывать только те данные, которые реально нужны для выполнения задачи. Например, если необходимо отобразить список сотрудников, достаточно выбрать столбцы с именами и должностями, а не всю информацию о сотрудниках. Это улучшит производительность запроса и уменьшит количество передаваемых данных.
Зачем исключать лишние столбцы из запроса?
Исключение лишних столбцов помогает улучшить скорость выполнения запроса. Чем меньше данных нужно обработать и передать, тем быстрее будет результат. Это особенно важно при работе с большими объемами данных, где каждое ненужное поле может замедлить процесс.
Как можно выбрать только необходимые столбцы для конкретного запроса?
Чтобы выбрать только нужные столбцы, необходимо тщательно анализировать, какие именно данные требуются для выполнения задачи. Например, если требуется информация только о названии продукта и его цене, то в запросе следует указать только эти два столбца. Также можно использовать ключевое слово `SELECT`, указывая в нем только нужные поля, например: `SELECT name, price FROM products`.
Как улучшить производительность SQL-запросов, если они возвращают много данных?
Чтобы улучшить производительность запросов, которые возвращают большие объемы данных, важно выбирать только те столбцы, которые действительно нужны. Также можно использовать фильтры, такие как `WHERE`, для уменьшения объема данных. Это позволит SQL-серверу быстрее обрабатывать запрос и снизить нагрузку на систему.
Как понять, какие столбцы не нужны в запросе?
Определить ненужные столбцы можно на основе целей запроса. Если столбцы не используются для отображения результатов, фильтрации или агрегации данных, их можно исключить. Например, если в запросе нужно только суммировать продажи по региону, то столбцы с подробностями о клиентах и товарах не понадобятся. Также важно помнить, что чем меньше данных обрабатывается, тем быстрее будет запрос.