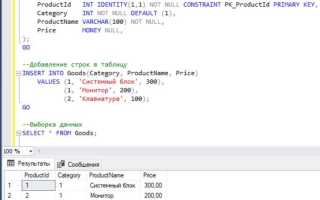
Заполнение столбца в SQL-запросе – ключевая операция при формировании выборок, обновлении данных и подготовке отчетов. В зависимости от задачи применяются различные методы: статическое присваивание значений, генерация по шаблону, использование выражений и агрегатных функций. Каждый из них обладает преимуществами в контексте производительности и читаемости кода.
Для присваивания фиксированных значений используется конструкция SELECT ‘значение’ AS столбец, позволяющая создать виртуальный столбец с одинаковым содержимым. В запросах с INSERT или UPDATE часто применяют DEFAULT и SET соответственно. Если необходимо заполнить столбец значениями на основе логики, используют CASE, который заменяет множественные условия на компактный и читаемый синтаксис.
При работе с пустыми или NULL-значениями эффективно применять функцию COALESCE() или ISNULL(), выбирая первое ненулевое значение из набора. Это особенно полезно при миграции данных или построении витрин, где допустимо использование резервных источников.
Для генерации значений по порядку используется ROW_NUMBER(), а при необходимости случайного распределения – NEWID() в SQL Server или RANDOM() в PostgreSQL. Такие подходы широко применяются при тестировании, генерации выборок и псевдоанонимизации данных.
Оптимальный способ заполнения столбца зависит от используемой СУБД, объема обрабатываемых данных и контекста запроса. Четкое понимание доступных функций и сценариев их применения позволяет сократить время обработки, повысить стабильность и читаемость SQL-кода.
Заполнение столбца фиксированным значением с помощью оператора UPDATE
Для массового присвоения одного и того же значения всем строкам в столбце таблицы используется оператор UPDATE в сочетании с конструкцией SET. Это применимо при инициализации нового столбца, исправлении некорректных данных или унификации значений по заданному критерию.
Синтаксис прост: UPDATE имя_таблицы SET имя_столбца = значение;. Например, чтобы установить значение 'Активен' для всех записей в столбце статус, выполните UPDATE пользователи SET статус = 'Активен';
Если необходимо ограничить область применения, добавьте условие WHERE. Например, чтобы обновить только те записи, где поле дата_регистрации пустое: UPDATE пользователи SET статус = 'Ожидание' WHERE дата_регистрации IS NULL;
При работе с числовыми полями также допустимо присваивание фиксированного значения: UPDATE заказы SET сумма = 0 WHERE сумма IS NULL;
Не используйте этот подход без фильтрации на больших таблицах без необходимости – это приведет к полной блокировке таблицы и может повлиять на производительность. При необходимости обновления миллионов строк рассмотрите пакетную обработку с ограничением количества обновляемых строк за один запрос, используя LIMIT (в MySQL) или аналогичные механизмы.
Перед выполнением массовых изменений рекомендуется создать резервную копию таблицы или использовать транзакции: BEGIN; UPDATE ...; COMMIT;. Это обеспечит возможность отката в случае ошибки.
Использование подзапроса для вычисления значений столбца
Подзапрос в SQL позволяет вычислять значения для столбцов в момент выполнения основного запроса. Он может быть использован для извлечения данных, которые необходимы для вычислений в других столбцах. Подзапросы выполняются внутри основного запроса и могут быть включены в раздел SELECT, WHERE или FROM.
Часто подзапрос используется для расчета агрегированных значений, таких как суммы, средние значения или максимумы, которые затем используются в основном запросе. Рассмотрим пример, где для каждого заказа необходимо вычислить стоимость доставки в зависимости от общей суммы заказа.
SELECT order_id, order_total,
(SELECT delivery_fee
FROM delivery_charges
WHERE min_order_total <= order_total
ORDER BY min_order_total DESC
LIMIT 1) AS delivery_fee
FROM orders;В этом запросе подзапрос извлекает значение delivery_fee из таблицы delivery_charges, основываясь на общей сумме заказа. Подзапрос отсортирован по минимальной сумме заказа, и выбирается максимальное значение, которое меньше или равно сумме текущего заказа.
При использовании подзапросов важно учитывать их производительность. Сложные или многократные подзапросы могут замедлить выполнение запроса, особенно если они выполняются для каждой строки основного запроса. В таких случаях полезно рассмотреть оптимизацию, например, использование JOIN вместо подзапроса или индексацию часто используемых столбцов.
Подзапросы также могут быть полезны при необходимости вычисления значений для разных групп данных. Например, для нахождения среднего значения по каждой категории товаров можно использовать подзапрос, который выполняет агрегацию в рамках каждой группы, а затем использовать это значение в основном запросе.
SELECT category_id, AVG(order_total),
(SELECT AVG(order_total)
FROM orders
WHERE category_id = o.category_id) AS category_avg
FROM orders o
GROUP BY category_id;Здесь подзапрос рассчитывает среднюю сумму заказов по каждой категории товаров и возвращает эти данные для дальнейшего использования в основном запросе. Важно, чтобы подзапросы, выполняющие агрегированные вычисления, корректно учитывали нужные фильтры для каждой строки основного запроса.
Еще один пример использования подзапроса – это вычисление значений с учетом условий, которые могут меняться динамически в зависимости от данных. Например, можно рассчитать коэффициент скидки для каждого клиента, основываясь на их покупках, с использованием подзапроса для получения суммарных данных о покупках клиента.
SELECT customer_id, total_spent,
(SELECT discount
FROM discounts
WHERE total_spent >= required_spent
ORDER BY required_spent DESC
LIMIT 1) AS discount
FROM customers;Здесь подзапрос получает коэффициент скидки для каждого клиента, основываясь на их суммарных расходах. Такой подход позволяет гибко и динамично вычислять значения для столбцов в зависимости от изменяющихся данных.
Присвоение значения столбцу при помощи JOIN с другой таблицей
Пример задачи: у нас есть таблица orders с заказами и таблица customers с информацией о клиентах. Нам необходимо добавить в столбец customer_name таблицы orders имя клиента из таблицы customers, используя общий идентификатор – customer_id.
UPDATE orders
SET customer_name = customers.name
FROM customers
WHERE orders.customer_id = customers.id;
В этом примере мы используем UPDATE для обновления столбца customer_name в таблице orders, соединяя её с таблицей customers через условие orders.customer_id = customers.id. Это обновит значения в столбце на основе данных из другой таблицы.
Основные рекомендации:
- Убедитесь, что столбцы для соединения имеют одинаковые типы данных. Ошибка типов может привести к неудачным соединениям или ошибкам в запросах.
- Используйте
INNER JOIN, если хотите получить только те строки, где есть совпадение в обеих таблицах. В противном случае можно применитьLEFT JOINили другие типы соединений в зависимости от требований к результату. - Внимательно подходите к производительности. Если таблицы большие, такой запрос может быть ресурсоёмким, особенно если соединение происходит по неиндексированным столбцам.
Для более сложных случаев можно использовать условные выражения в SET, чтобы присваивать разные значения в зависимости от условий:
UPDATE orders
SET customer_name =
CASE
WHEN customers.status = 'VIP' THEN 'VIP ' || customers.name
ELSE customers.name
END
FROM customers
WHERE orders.customer_id = customers.id;
Этот запрос добавит префикс "VIP" к имени клиента, если его статус в таблице customers равен "VIP".
Присваивание значений с использованием JOIN – мощный инструмент для работы с данными в SQL, особенно когда необходимо обогатить таблицу информацией из других источников, не создавая лишних дублирующих столбцов.
Заполнение пустых значений с использованием COALESCE
Функция COALESCE в SQL используется для обработки пустых значений (NULL) в запросах. Это полезный инструмент, когда необходимо заменить NULL значением по умолчанию или другим значением, которое имеет приоритет в вычислениях.
Синтаксис функции COALESCE прост: COALESCE(expression1, expression2, ..., expressionN). Функция возвращает первое ненулевое значение из списка переданных аргументов. Если все аргументы равны NULL, результатом будет NULL.
Пример использования COALESCE: при выполнении запроса на выборку данных из таблицы заказов, где могут быть пустые значения в столбце «дата отправки», можно заменить их на текущую дату:
SELECT order_id, COALESCE(shipping_date, CURRENT_DATE) AS shipping_date FROM orders;
В этом случае, если в поле shipping_date будет NULL, будет возвращена текущая дата. COALESCE позволяет не только заполнить NULL значением по умолчанию, но и выполнить более сложные операции с несколькими возможными значениями.
При работе с числовыми данными COALESCE может использоваться для предотвращения ошибок вычислений. Например, при расчете сумм или средних значений, когда могут встречаться NULL:
SELECT order_id, COALESCE(discount, 0) + total_amount AS final_amount FROM orders;
Здесь COALESCE заменяет NULL в столбце discount на 0, обеспечивая корректные вычисления итоговой суммы. Без использования COALESCE, такие строки с NULL могут привести к неправильным результатам или ошибкам в запросах.
COALESCE полезна и для объединения значений разных столбцов. Если столбец A содержит пустые значения, можно использовать COALESCE, чтобы взять данные из столбца B, если значения в A отсутствуют. Это полезно в ситуациях, когда данные распределены по нескольким полям, и важно заполнять их из разных источников.
SELECT user_id, COALESCE(phone_number, email) AS contact_info FROM users;
В этом примере, если в поле phone_number отсутствует значение, будет возвращен email пользователя. Такой подход часто используется при обработке данных, где информация может быть неполной или распределенной.
Важно помнить, что COALESCE обрабатывает только NULL-значения. Если в столбце присутствуют пустые строки, они не будут заменены. Для работы с такими случаями можно использовать дополнительные функции, такие как NULLIF или CASE.
Использование COALESCE повышает гибкость SQL-запросов, позволяя эффективно работать с неполными данными и обеспечивать их консистентность при извлечении или вычислениях.
Применение функции CASE для условного заполнения столбца
Функция CASE в SQL позволяет выполнять условные проверки прямо внутри запросов, что делает её незаменимым инструментом при заполнении столбцов в зависимости от определённых условий. В отличие от простого IF, функция CASE может быть использована в SELECT, UPDATE, INSERT и других операциях для управления значениями в столбцах на основе логики.
Основная структура функции CASE выглядит следующим образом:
CASE WHEN условие1 THEN результат1 WHEN условие2 THEN результат2 ELSE результат_по_умолчанию END
Каждое условие проверяется по порядку, и как только одно из них оказывается истинным, соответствующее значение возвращается в качестве результата. Если ни одно из условий не выполнено, используется результат по умолчанию, если он задан в части ELSE.
Пример использования CASE для условного заполнения столбца:
SELECT имя, CASE WHEN возраст < 18 THEN 'Несовершеннолетний' WHEN возраст BETWEEN 18 AND 60 THEN 'Взрослый' ELSE 'Пенсионер' END AS категория_возраста FROM пользователи;
В данном примере столбец категория_возраста заполняется в зависимости от значения возраста пользователя. Для значений меньше 18 лет присваивается статус "Несовершеннолетний", для возраста от 18 до 60 лет – "Взрослый", а для остальных значений – "Пенсионер".
При использовании функции CASE важно помнить, что она может применяться не только для простых условий. Можно также работать с более сложными выражениями, такими как сравнения, логические операторы или даже вложенные функции CASE для создания многоуровневых условий.
Ещё один пример с применением CASE в операциях обновления данных:
UPDATE товары SET цена = CASE WHEN категория = 'Электроника' THEN цена * 1.1 WHEN категория = 'Одежда' THEN цена * 1.2 ELSE цена END;
Этот запрос обновляет цены товаров в зависимости от их категории. Для электроники цена увеличивается на 10%, для одежды – на 20%, для остальных товаров цена остаётся прежней.
При использовании функции CASE важно учитывать производительность запросов, особенно если условия становятся слишком сложными. В таких случаях может быть полезным пересматривать логику вычислений или использовать индексы для ускорения работы с большими объёмами данных.
Генерация последовательных значений через ROW_NUMBER
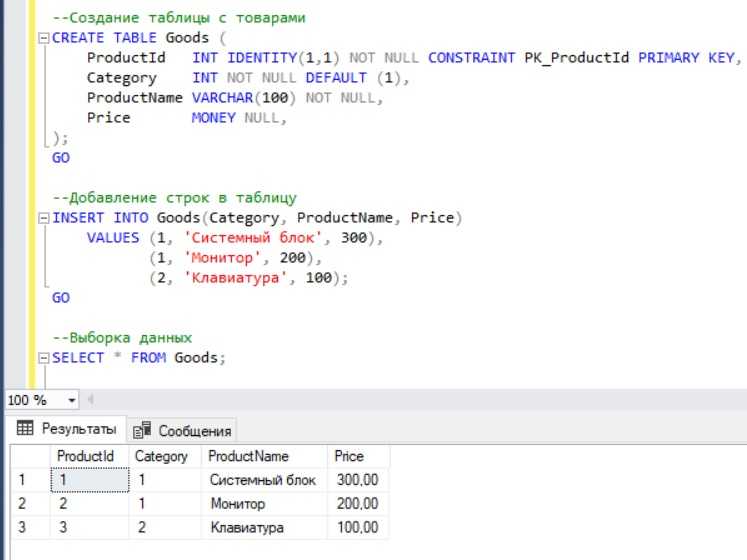
Функция ROW_NUMBER() в SQL предоставляет эффективный способ генерации последовательных значений для строк в запросах. Это полезно, когда нужно нумеровать строки или создать уникальный идентификатор на основе порядка данных.
С помощью ROW_NUMBER() можно назначить уникальный номер каждой строке в наборе данных, что позволяет создавать динамичные последовательности, не требующие предварительного ввода значений. Главное преимущество – это возможность создания числовых идентификаторов в реальном времени на основе текущего порядка строк в запросе.
Пример использования:
SELECT ROW_NUMBER() OVER (ORDER BY date_created) AS row_num, user_id, user_name FROM users;
В этом примере функция ROW_NUMBER() создает последовательность номеров для каждой строки в таблице users, сортируя результаты по полю date_created. В результате, каждая строка будет иметь уникальный номер, который можно использовать для различных целей, например, для создания отчетов или распределения задач.
Важно понимать, что порядок, определяемый в ORDER BY внутри функции ROW_NUMBER(), играет ключевую роль. Без явной сортировки порядок номеров может быть непредсказуемым, что приведет к ошибкам в логике запроса. Также стоит помнить, что функция не возвращает одинаковые номера для строк с одинаковыми значениями в колонках сортировки.
Применение ROW_NUMBER() с группировками:
SELECT category_id, ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY date_created DESC) AS row_num, product_name FROM products;
В данном примере функция генерирует последовательность номеров для товаров в пределах каждой категории (category_id). Для каждой категории начинается своя нумерация, что удобно при анализе товаров по категориям.
Преимущества использования ROW_NUMBER():
- Гибкость в определении порядка номеров через сортировку и группировку.
- Обеспечивает уникальность последовательных значений без необходимости вручную их генерировать.
- Удобна для создания отчетов, фильтрации и кластеризации данных.
Ограничения и важные моменты:
- Номера генерируются только в контексте текущего набора данных. При изменении сортировки или фильтров они могут измениться.
- Функция не является заменой для автогенерации уникальных значений, таких как идентификаторы в базах данных.
- Не поддерживается в некоторых старых версиях СУБД, например в MySQL до версии 8.0.
Использование ROW_NUMBER() может существенно упростить решение многих задач, связанных с нумерацией и сортировкой данных в SQL-запросах, обеспечивая гибкость и точность в обработке информации.
Обновление столбца на основе агрегатных функций
Обновление столбца с использованием агрегатных функций в SQL позволяет динамически изменять данные в зависимости от результатов вычислений, таких как суммы, средние значения, минимумы и максимумы. Это полезно, когда необходимо актуализировать значения в одном столбце на основе агрегированных данных из других строк таблицы или даже из разных таблиц.
Для выполнения таких операций используется подзапрос с агрегатной функцией. Например, обновление столбца на основе среднего значения другого столбца в той же таблице может выглядеть так:
UPDATE employees SET salary = (SELECT AVG(salary) FROM employees) WHERE department = 'IT';
Здесь для сотрудников отдела IT устанавливается новое значение зарплаты, равное средней зарплате по всем сотрудникам в таблице. Такой подход позволяет динамически корректировать данные в зависимости от общей картины в таблице, не вводя заранее зафиксированные значения.
Агрегатные функции также могут использоваться с группировкой для обновления столбца на основе данных, сгруппированных по определённому критерию. Например, если нужно обновить столбец с бонусами в зависимости от суммы продаж по каждому сотруднику:
UPDATE employees SET bonus = (SELECT SUM(sales) FROM sales WHERE sales.employee_id = employees.id) WHERE EXISTS (SELECT 1 FROM sales WHERE sales.employee_id = employees.id);
Этот запрос обновляет значение бонуса для каждого сотрудника, исходя из суммы его продаж, представленных в таблице sales.
Важно учитывать, что использование агрегатных функций в запросах на обновление может повлиять на производительность, особенно при работе с большими объёмами данных. Оптимизация запросов, например, с использованием индексов и правильного выбора агрегатных функций, поможет избежать излишней нагрузки на сервер.
Кроме того, стоит быть внимательным при применении агрегатных функций в подзапросах, чтобы они не возвращали более одного значения, иначе запрос завершится с ошибкой. Для этого можно использовать дополнительные фильтры или условия, чтобы гарантировать корректность данных.
Присвоение значения столбцу при вставке данных через INSERT SELECT
Пример использования INSERT SELECT с присваиванием значений столбцам: при вставке данных можно использовать выражения в SELECT, чтобы изменить или вычислить значение столбца перед его вставкой в целевую таблицу.
Предположим, у нас есть таблица orders, и мы хотим вставить данные в таблицу archived_orders. При этом нам нужно изменить значение столбца order_status на «archived» для всех вставляемых строк.
INSERT INTO archived_orders (order_id, customer_id, order_status)
SELECT order_id, customer_id, 'archived'
FROM orders
WHERE order_date < '2023-01-01';Здесь, при вставке данных, значение для order_status будет всегда присвоено как 'archived'. Этот подход полезен, когда нужно изменить или добавить фиксированное значение столбцу в момент выполнения запроса.
Кроме того, можно использовать более сложные вычисления для присваивания значений столбцам. Например, при вставке данных можно вычислить значение на основе данных из других столбцов.
INSERT INTO archived_orders (order_id, customer_id, total_amount)
SELECT order_id, customer_id, total_amount * 1.1
FROM orders
WHERE order_date < '2023-01-01';В этом примере в столбец total_amount будет вставлена увеличенная на 10% сумма. Это может быть полезно, например, для учета инфляции или перерасчета стоимости товаров.
При использовании метода INSERT SELECT также важно учитывать типы данных и совместимость столбцов. Если столбцы не соответствуют по типу данных или размеры полей, возникнут ошибки. В таких случаях можно воспользоваться функциями преобразования типов, например CAST() или CONVERT().
Для более сложных случаев можно комбинировать несколько столбцов и выражений. Например, чтобы вставить данные с условным присвоением значений:
INSERT INTO archived_orders (order_id, customer_id, order_status)
SELECT order_id, customer_id,
CASE WHEN total_amount > 1000 THEN 'high_value' ELSE 'normal' END
FROM orders
WHERE order_date < '2023-01-01';В этом запросе для столбца order_status будет присваиваться значение в зависимости от суммы заказа: если сумма больше 1000, присваивается 'high_value', иначе – 'normal'.
Таким образом, INSERT SELECT с присвоением значений столбцам – это мощный инструмент для обработки и модификации данных при их вставке, позволяющий снизить сложность операций и улучшить производительность, поскольку позволяет выполнить все операции за один запрос.
Вопрос-ответ:
Какие способы существуют для заполнения столбца в SQL запросе?
Существует несколько способов для заполнения столбца в SQL запросе. Наиболее распространённые из них включают использование команды `INSERT`, которая добавляет новые строки в таблицу, а также команду `UPDATE`, которая изменяет существующие значения в одном или нескольких столбцах. Также можно использовать функции SQL, такие как `COALESCE`, для замены `NULL` значений на заданное значение. В некоторых случаях полезно использовать выражения с подзапросами для динамического заполнения данных из других таблиц.
Как можно заполнить столбец значениями из другой таблицы?
Для заполнения столбца значениями из другой таблицы используется SQL-оператор `UPDATE` в сочетании с подзапросом или соединением. Например, можно использовать конструкцию `UPDATE таблица1 SET столбец = (SELECT значение FROM таблица2 WHERE условие)`. Это позволяет обновить столбцы в одной таблице на основе данных из другой. Также возможен вариант с использованием `JOIN` для объединения таблиц и последующего обновления данных на основе полученных значений.
Можно ли использовать условие для заполнения столбца в SQL запросе?
Да, в SQL можно использовать условие для заполнения столбца с помощью выражений `CASE` или `IF`. Например, с помощью `CASE` можно задать условие, по которому будет определяться, какое значение должно быть присвоено столбцу. Пример: `UPDATE таблица SET столбец = CASE WHEN условие THEN значение1 ELSE значение2 END`. Это позволяет изменять данные в столбце в зависимости от условий, например, присваивать разные значения на основе других данных в таблице.
Как автоматически заполнить столбец в SQL без указания конкретных значений?
Чтобы автоматически заполнить столбец в SQL, можно использовать встроенные функции или выражения. Например, можно задать значением столбца текущую дату с помощью функции `CURRENT_DATE` или заполнить столбец уникальными значениями с помощью функции `UUID()`. Также можно использовать `AUTO_INCREMENT` для числовых столбцов, чтобы автоматически генерировать уникальные значения при добавлении новых строк в таблицу.
Как изменить все значения в одном столбце SQL-запросом?
Для изменения всех значений в столбце SQL-запросом используется команда `UPDATE`. С помощью неё можно заменить все значения в выбранном столбце на новое значение. Пример запроса: `UPDATE таблица SET столбец = новое_значение`. Если необходимо обновить значения только в определённых строках, можно добавить условие в `WHERE`. Например, `UPDATE таблица SET столбец = новое_значение WHERE условие`. Это позволяет более точно контролировать, какие строки будут обновлены.
Какие способы существуют для заполнения столбца в SQL запросе?
Заполнение столбца в SQL запросе может быть выполнено различными способами в зависимости от требований задачи. Одним из простых способов является использование команды `UPDATE` с указанием нового значения для столбца. Например, можно обновить значения в столбце для всех строк или для определённого набора строк с помощью условия `WHERE`. Также можно заполнить столбец значениями по умолчанию, определёнными на уровне структуры таблицы, или использовать функции для вычисления значений (например, `NOW()` для текущей даты). В некоторых случаях может быть полезным применение `INSERT INTO` для добавления данных в новый столбец при вставке строк в таблицу. Для автоматизации заполнения столбца часто применяют триггеры, которые запускаются при изменении данных в других столбцах.