Запуск триггера в SQL – это важная операция, которая требует понимания, как он работает и как правильно его инициировать. Триггеры выполняются автоматически при изменении данных в таблицах, что делает их мощным инструментом для выполнения ряда операций, таких как проверка данных, аудирование или автоматическое обновление информации. Но неправильное использование триггеров может привести к неожиданным результатам или снижению производительности базы данных.
Для корректного запуска триггера необходимо понять его типы и условия срабатывания. Триггеры могут быть до или после выполнения SQL-операций, таких как вставка, обновление или удаление данных. Важно правильно настроить их так, чтобы они не конфликтовали с основными операциями базы данных, и не вызывали излишних нагрузок. Например, триггеры, срабатывающие на каждое изменение, могут замедлить работу системы, если не контролировать частоту срабатываний.
Рекомендуется использовать триггеры только там, где это необходимо для поддержания целостности данных или автоматизации процессов. В остальных случаях их следует избегать, чтобы не перегружать систему лишними операциями. Кроме того, всегда важно тестировать триггеры на тестовых данных, прежде чем запускать их в продакшн-среде, чтобы предотвратить возможные ошибки или потерю информации.
Также стоит обратить внимание на порядок их выполнения, особенно в случае с несколькими триггерами, настроенными на одну таблицу. В зависимости от СУБД порядок может быть различным, и это может повлиять на конечный результат. Некоторые базы данных предоставляют возможность указать порядок срабатывания триггеров, что важно учитывать при проектировании системы.
Настройка триггера для автоматического выполнения действий
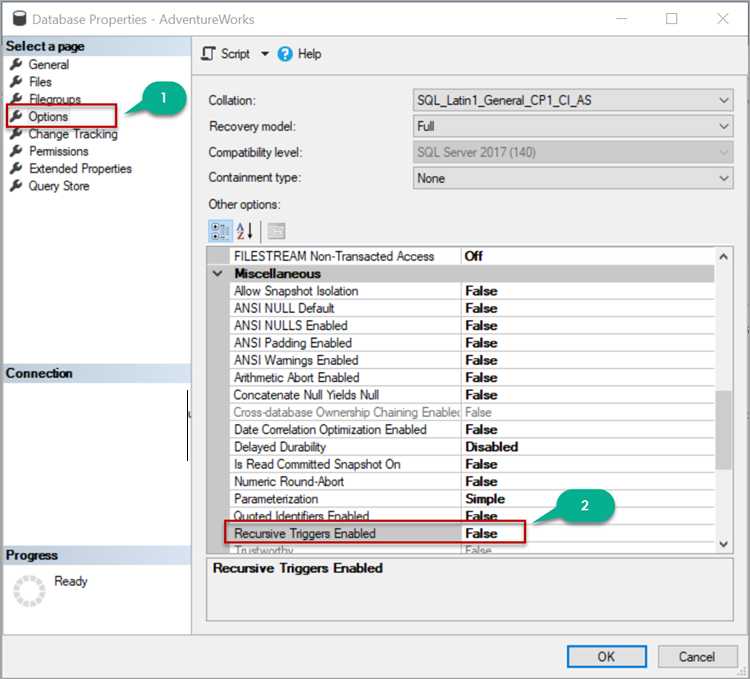
Для настройки триггера в SQL необходимо учесть несколько ключевых аспектов. Во-первых, важно определить, на каком событии триггер будет срабатывать: это может быть INSERT, UPDATE или DELETE. Далее нужно точно указать таблицу или представление, на которых будет происходить отслеживание изменений.
Пример синтаксиса для создания триггера в MySQL:
CREATE TRIGGER имя_триггера AFTER INSERT ON имя_таблицы FOR EACH ROW BEGIN -- действия, которые будут выполнены END;
Триггер запускается автоматически после вставки данных в указанную таблицу. Для разных СУБД синтаксис может незначительно отличаться, поэтому важно ознакомиться с документацией по используемой системе управления базами данных.
Для выполнения действия на основе изменений данных, можно использовать конструкцию FOR EACH ROW, что позволяет ссылаться на измененную строку в контексте триггера. Это позволяет, например, автоматически записывать лог изменений или вычислять и обновлять связанные поля в других таблицах.
В случае необходимости использовать переменные в триггере, можно оперировать значениями из NEW или OLD, в зависимости от типа операции. NEW применяется для вставленных или обновленных строк, а OLD – для удаленных или старых значений при обновлении.
Важно правильно настроить безопасность триггера. Например, если триггер выполняет длительные операции, его выполнение может повлиять на производительность базы данных. В таких случаях рекомендуется использовать асинхронные процессы или вынести сложные вычисления за пределы триггера, чтобы избежать блокировки таблицы на длительный период.
Не забывайте тестировать триггер на небольших данных до его использования в рабочей среде, чтобы убедиться в корректности выполнения действий и их влиянии на систему в целом.
Выбор подходящего события для активации триггера
При проектировании триггеров в SQL важно правильно выбрать событие, которое будет их активировать. Каждое событие имеет свои особенности, влияющие на производительность и логику работы базы данных. Основные типы событий активации триггеров включают INSERT, UPDATE и DELETE.
INSERT подходит для случаев, когда необходимо выполнить действия сразу после добавления новой записи в таблицу. Например, если нужно автоматически заполнять поля с датой создания или логировать операции добавления данных. Однако важно учитывать, что при массовом вставлении данных (например, в результате операции загрузки большого объема информации) такие триггеры могут создать нагрузку на систему, особенно если они вызывают дополнительные запросы или обновления.
UPDATE активируется при изменении существующих данных в таблице. Этот тип триггера полезен, когда нужно отслеживать изменения определенных столбцов, например, фиксировать изменения статусов заказов или обновления цен. Но здесь также стоит учитывать возможное увеличение числа операций при частых обновлениях. Если обновление затрагивает несколько строк, может возникнуть избыточная нагрузка, и триггер может срабатывать чаще, чем ожидается.
DELETE применяется при удалении записей из таблицы. Это событие полезно для ведения истории изменений или автоматического удаления зависимых данных в других таблицах. Важно помнить, что триггер DELETE часто используется для каскадных удалений, что может привести к непредсказуемым последствиям, если не учитывать зависимость данных в базе.
Кроме того, существует возможность комбинировать несколько типов событий. Например, можно создать триггер, который будет срабатывать при любом изменении данных – как вставке, так и обновлении или удалении. Это полезно для аудита или при необходимости выполнения одинаковых действий независимо от типа изменения.
Особое внимание следует уделить производительности. Триггеры, активируемые при INSERT, UPDATE или DELETE, могут значительно замедлять выполнение операций, если они не оптимизированы. Использование условий и фильтров в триггере помогает избежать ненужных вызовов при несущественных изменениях данных.
Кроме того, необходимо учитывать частоту и характер операций в вашей базе данных. Если изменения происходят редко, можно выбрать событие, которое будет срабатывать при каждом изменении, но если база данных активно обновляется, лучше ограничить действия триггера только критичными случаями, например, при изменении определенных столбцов или значений.
Таким образом, выбор события для активации триггера зависит от конкретных задач и характеристик работы вашей базы данных. Важно заранее оценить, какие операции будут выполняться чаще всего, и оптимизировать триггеры, чтобы избежать избыточных или слишком частых срабатываний.
Определение условий срабатывания триггера
Условия срабатывания триггера в SQL определяются с помощью ключевых моментов: события (DML-операции), момент времени (до или после операции), а также ограничения, проверяющие изменения в данных.
- Тип события: Триггеры могут быть привязаны к следующим операциям:
- INSERT – срабатывает при добавлении новой записи в таблицу.
- UPDATE – срабатывает при изменении существующих данных.
- DELETE – срабатывает при удалении данных из таблицы.
- Момент срабатывания: Триггер может быть настроен на два типа срабатывания:
- BEFORE – триггер выполняется до выполнения основной операции (например, перед вставкой, обновлением или удалением данных).
- AFTER – триггер выполняется после выполнения основной операции.
- Условия срабатывания: Важно правильно указать условия, при которых триггер будет активироваться. Например:
- Проверка значений столбцов при операции обновления или вставки, например, значение в одном из полей должно быть больше или равно определённому значению.
- Использование системных переменных, например, проверка старых и новых значений для предотвращения ненужных срабатываний при отсутствии изменений.
Пример: создание триггера, который будет срабатывать только при изменении значения в поле salary и если оно больше 1000:
CREATE TRIGGER salary_update_trigger AFTER UPDATE ON employees FOR EACH ROW BEGIN IF NEW.salary > 1000 THEN -- действия при условии END IF; END;
Применение условий срабатывания позволяет избежать ненужных или избыточных операций, что может повысить производительность и корректность работы базы данных.
Управление зависимостями между триггерами в базе данных
Для управления зависимостями между триггерами необходимо:
1. Определение порядка активации триггеров: Сначала следует чётко прописать, в каком порядке триггеры должны срабатывать. В SQL нет встроенной поддержки явного порядка активации, поэтому важно продумать логику, чтобы триггер не вызвал выполнение другого, если это не требуется. Рекомендуется использовать временные флаги или статусные поля, чтобы предотвратить повторное срабатывание триггера, который уже был активирован.
2. Управление с помощью временных таблиц: Использование временных таблиц для хранения промежуточных данных позволяет минимизировать взаимодействие между триггерами и избежать избыточных операций. Например, если один триггер вносит изменения в таблицу, другой триггер может их обработать, если данные были заранее сохранены в временной таблице, и не будет необходимо повторно запускать основной процесс.
3. Разделение логики: Хорошая практика – разделение триггеров по типам операций. Например, триггеры для INSERT, UPDATE и DELETE должны быть независимыми, чтобы минимизировать возможные пересечения. Если триггеры выполняют одинаковую задачу, их можно объединить в один триггер с проверкой условий, что позволит избежать избыточности и улучшить читаемость кода.
4. Отслеживание изменений через журнал: Для лучшего понимания, какие триггеры были активированы и когда, можно использовать журнал изменений. Это особенно полезно в сложных системах, где триггеры могут взаимодействовать с несколькими таблицами. Ведение логов позволяет точно отслеживать зависимости и устранять возможные ошибки, вызванные неправильным порядком срабатывания.
5. Оценка производительности: Сложные зависимости между триггерами могут негативно сказаться на производительности базы данных. Поэтому важно регулярно проводить анализ и оптимизацию триггеров, чтобы минимизировать время их выполнения. Один из способов – это анализ плана выполнения запросов и использование индексов для ускорения операций, с которыми работают триггеры.
6. Использование функций для проверки условий: Иногда удобно использовать функции для проверки условий срабатывания триггеров, чтобы уменьшить дублирование кода. Например, если триггер должен срабатывать только при определённом значении поля, функция, проверяющая это условие, может быть использована в разных триггерах для обеспечения их консистентности.
7. Резервное тестирование: Все изменения и добавления новых триггеров должны быть протестированы в тестовой среде с реальными данными. Это позволяет избежать неожиданных последствий, связанных с незапланированными зависимостями и пересечениями логики различных триггеров.
Подходы к управлению зависимостями между триггерами помогают сохранить стабильность и предсказуемость работы базы данных, минимизируя риски и улучшая производительность системы.
Использование языков программирования в SQL-триггерах
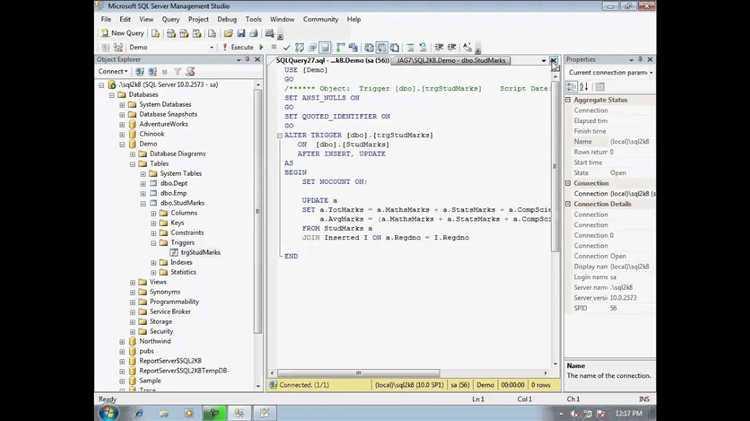
SQL-триггеры позволяют автоматизировать выполнение различных операций в базе данных. Для создания сложной логики в триггерах разработчики могут использовать встроенные языки программирования, которые поддерживаются в СУБД. Это расширяет возможности триггеров, позволяя не ограничиваться только SQL-запросами.
Основные языки программирования, используемые в SQL-триггерах:
- PL/pgSQL (для PostgreSQL): Язык, расширяющий возможности SQL, позволяет использовать переменные, циклы и условные операторы. PL/pgSQL идеально подходит для реализации бизнес-логики и сложных вычислений внутри триггеров.
- PL/SQL (для Oracle): Этот язык программирования расширяет стандартный SQL, позволяя использовать обработку ошибок, функции и процедуры. Он эффективно работает для реализации многократных операций с транзакциями и сложных вычислений.
- T-SQL (для Microsoft SQL Server): Язык, который включает функции для работы с переменными, условными операторами и циклами. T-SQL используется для написания триггеров, где необходимо обрабатывать данные в несколько этапов или выполнять дополнительные проверки.
- Transact-SQL (для MySQL): Несмотря на ограничения в сравнении с другими СУБД, MySQL поддерживает некоторые элементы процедурного программирования в своих триггерах, такие как циклы и условные операторы. Этот язык полезен для выполнения несложных операций и проверок.
Каждый язык программирования в триггерах имеет свои особенности и ограничения. Например, PL/pgSQL поддерживает работу с большими объемами данных и позволяет вызывать другие функции, что важно для сложных бизнес-процессов. В свою очередь, T-SQL идеально подходит для работы с транзакциями, обеспечивая высокую надежность и целостность данных при выполнении действий внутри триггера.
Чтобы эффективно использовать программирование в триггерах, необходимо учитывать следующие аспекты:
- Оптимизация производительности: Из-за того, что триггеры выполняются автоматически при изменении данных, важно минимизировать нагрузку на систему. Использование сложных циклов и множественных операций в триггерах может замедлить работу базы данных.
- Идентификация и обработка ошибок: Использование обработки исключений позволяет обеспечить стабильную работу триггера в случае возникновения неожиданных ситуаций, таких как нарушение целостности данных или отсутствие необходимых значений.
- Логирование действий: Для диагностики и отслеживания работы триггера важно реализовать механизм логирования. Это поможет выявлять и устранять проблемы в процессе работы с триггерами.
В итоге, использование языков программирования в триггерах позволяет значительно повысить гибкость и мощность механизмов автоматизации в базе данных, однако требует внимания к вопросам производительности и правильной обработки ошибок.
Отладка и тестирование триггера в рабочей среде

Отладка и тестирование триггеров в рабочей среде требует внимательности и правильного подхода, поскольку ошибочно настроенный триггер может повлиять на производительность системы или нарушить данные. Важно следовать нескольким ключевым рекомендациям.
1. Логирование действий триггера – Один из наиболее эффективных способов отслеживания работы триггера в реальной среде – это использование логирования. Включение логирования в коде триггера позволяет отслеживать все операции, которые он выполняет, и выявлять возможные ошибки или неучтенные случаи. Для этого можно использовать команды типа RAISE NOTICE или записывать информацию о выполнении в отдельные таблицы.
2. Использование транзакций – Для минимизации возможных негативных последствий на данные и производительность важно выполнять тестирование триггера внутри транзакции. Это позволяет откатить изменения, если триггер работает некорректно, и не затронет данные в базе. Тестирование в пределах транзакции также помогает убедиться, что триггер правильно взаимодействует с другими операциями в базе данных.
3. Создание тестовых данных – Для тестирования триггера необходимо использовать ограниченное количество тестовых данных, максимально приближенных к реальным условиям работы. Это позволяет увидеть, как триггер будет работать при разных входных значениях, и проверить его поведение на крайних и граничных значениях.
4. Использование режимов отладки СУБД – Многие системы управления базами данных (СУБД) предлагают встроенные инструменты для отладки, например, режим EXPLAIN или специальные утилиты для пошагового выполнения SQL-запросов. Эти инструменты полезны для диагностики проблем, связанных с производительностью триггера или его взаимодействием с другими запросами.
5. Модульное тестирование триггера – Разработку триггера следует тестировать по частям. Важно сначала проверить его логику без привязки к реальной системе, а затем постепенно интегрировать его с основной базой. Использование тестовых окружений с замкнутыми зависимостями помогает быстрее выявить ошибки без риска для основной системы.
6. Проверка производительности – После того как триггер протестирован на корректность работы, необходимо оценить его влияние на производительность базы данных. Даже небольшой дополнительный запрос или операция, выполняемая триггером, может значительно замедлить работу системы, особенно если триггер срабатывает часто. Следует использовать инструменты мониторинга производительности, чтобы оценить время выполнения запросов до и после активации триггера.
7. Постоянный мониторинг в рабочей среде – После деплоя триггера в продакшн-среду необходимо обеспечить его постоянный мониторинг. Ошибки могут проявляться не сразу, а только в условиях высоких нагрузок или при изменении структуры данных. Важно иметь систему предупреждений о сбоях, чтобы своевременно реагировать на возможные проблемы.
Тестирование и отладка триггеров требует комплексного подхода. Нужно не только проверять корректность выполнения, но и оценивать влияние на производительность, взаимодействие с другими процессами и стабильность работы всей системы.
Мониторинг работы триггеров и анализ их производительности
1. Логирование выполнения триггеров – один из первых шагов в мониторинге. Для этого необходимо добавить в триггер механизм логирования, который фиксирует время его выполнения, тип операции (INSERT, UPDATE, DELETE) и количество затронутых строк. Это помогает определить, какие триггеры оказывают наибольшее влияние на производительность.
2. Использование системных представлений позволяет отслеживать активность триггеров в реальном времени. В SQL Server можно использовать представление sys.triggers, чтобы выявить, какие триггеры активны и какие таблицы они затрагивают. В PostgreSQL полезным будет запрос к pg_trigger и pg_stat_user_tables, который показывает, сколько строк было затронуто триггером за последний период.
3. Оценка времени выполнения триггеров играет ключевую роль. Для этого можно использовать профилирование запросов. Например, в MySQL инструмент EXPLAIN может показать, сколько времени уходит на выполнение запросов, инициируемых триггером. В Oracle стоит обратить внимание на DBMS_PROFILER или DBMS_XPLAN для анализа планов выполнения.
4. Минимизация нагрузки от триггеров должна стать приоритетной задачей. Для этого рекомендуется избегать выполнения сложных вычислений в триггерах, а также выносить их в отдельные задачи или асинхронные процессы. Это поможет сократить время отклика и снизить нагрузку на сервер.
5. Использование индексов для таблиц, на которых срабатывают триггеры, критично. Без правильно настроенных индексов триггеры могут значительно замедлить выполнение операций. Особенно это касается триггеров, которые обрабатывают большие объемы данных или часто выполняются.
7. Регулярные тесты и оптимизация – регулярное тестирование триггеров с помощью реальных данных и анализ их воздействия на производительность поможет выявить узкие места. Рекомендуется выполнять нагрузочные тесты с различными конфигурациями триггеров, чтобы понять, как они ведут себя при увеличении объема данных или нагрузки на систему.
Постоянный мониторинг и анализ триггеров позволяет не только улучшить производительность базы данных, но и обеспечить её стабильную работу при увеличении нагрузки. Важно помнить, что триггеры должны быть эффективными и не создавать дополнительных проблем для системы.
Управление правами доступа при использовании триггеров
При использовании триггеров в базе данных важно правильно настроить права доступа, чтобы избежать несанкционированного вмешательства или ошибок в обработке данных. Неправильно настроенные права могут привести к утечке данных, неверной обработке запросов или нарушению целостности базы данных.
1. Разделение прав на создание и выполнение триггеров
Для обеспечения безопасности следует ограничить права на создание и изменение триггеров. Рекомендуется предоставлять такие права только администраторам или пользователям с особыми привилегиями. Это позволяет минимизировать риск внесения изменений в триггеры, которые могут повлиять на работу всей базы данных.
2. Контроль прав на исполнение триггеров
Триггеры, в отличие от обычных запросов, могут быть выполнены автоматически, что увеличивает важность контроля их выполнения. Следует настроить разрешения на выполнение триггеров таким образом, чтобы только авторизованные пользователи или процессы могли инициировать их работу. Это можно сделать с помощью роли или схемы, которая ограничивает доступ только необходимым пользователям.
3. Принципы минимизации привилегий
Каждому пользователю или процессу следует предоставлять только те права, которые необходимы для выполнения конкретных операций. Например, если триггер изменяет только определенные таблицы, пользователи, не имеющие прав на эти таблицы, не должны иметь возможность вызвать триггер. Это предотвращает возможность случайных или злонамеренных изменений.
4. Аудит и мониторинг триггеров
Рекомендуется внедрить систему аудита для отслеживания действий, связанных с триггерами. Это поможет своевременно обнаружить несанкционированное использование триггеров или некорректное их выполнение. В некоторых системах можно настроить логирование вызовов триггеров, а также результаты их работы.
5. Использование ограничений для защиты данных
В процессе работы триггеров данные могут быть изменены в результате автоматических операций. Чтобы избежать нежелательных изменений, можно использовать дополнительные ограничения на уровне таблиц, такие как внешние ключи, уникальные индексы или проверки на уровне данных, которые обеспечат защиту на случай ошибок или попыток несанкционированного доступа через триггеры.
6. Роль системного администратора
Системный администратор должен регулярно проверять права доступа к триггерам и другим объектам базы данных. Важно следить за тем, чтобы триггеры не создавались без должного контроля и не изменялись без необходимых согласований. Регулярные ревизии прав доступа позволят предотвратить потенциальные угрозы и повысить безопасность работы с базой данных.
Вопрос-ответ:
Что такое триггер SQL и зачем он нужен?
Триггер SQL — это специальный объект в базе данных, который автоматически выполняет определённые действия при наступлении определённых условий. Например, триггер может срабатывать при добавлении, изменении или удалении данных в таблице. Триггеры часто используют для обеспечения целостности данных или автоматизации различных процессов, таких как обновление данных в других таблицах или ведение логов изменений.
Можно ли использовать несколько триггеров на одну таблицу?
Да, можно. В одной таблице можно создать несколько триггеров, которые будут срабатывать на разные события или в разные моменты времени. Например, один триггер может срабатывать перед вставкой данных, а другой — после. Важно понимать, что если триггеры для одной таблицы конфликтуют между собой (например, два триггера пытаются изменить одни и те же данные), может возникнуть ошибка. Поэтому нужно внимательно следить за логикой работы триггеров, чтобы избежать таких ситуаций.