Правильный выбор инструмента для работы с SQL-запросами напрямую влияет на эффективность разработки и работы с базами данных. Несмотря на широкое разнообразие доступных решений, каждый инструмент имеет свои особенности, которые могут значительно ускорить процесс написания, отладки и выполнения запросов. Важно понимать, что выбор зависит не только от функционала, но и от специфики работы с базой данных, уровня знаний пользователя и требований к проекту.
Для начинающих пользователей, ищущих простой и интуитивно понятный интерфейс, идеальными станут такие инструменты, как DBeaver или MySQL Workbench. Эти приложения предоставляют визуальные редакторы, поддержку автодополнения запросов и возможность работы с несколькими базами данных одновременно, что делает их удобными для освоения SQL.
Для опытных разработчиков, которым требуется мощная функциональность и гибкость, хорошими вариантами будут DataGrip или SQL Server Management Studio (SSMS). Эти инструменты предлагают не только поддержку сложных запросов и скриптов, но и интеграцию с системами контроля версий, анализ производительности запросов и продвинутую отладку. Важно также учитывать поддержку популярных СУБД и возможность работы с большими объемами данных.
В выборе стоит также учитывать совместимость с используемой системой и специфические потребности проекта. Например, если работа идет исключительно с PostgreSQL, хорошим решением будет pgAdmin, которое предоставляет полный набор инструментов для этой СУБД. Выбор инструмента, который идеально подходит под ваши требования, обеспечит не только комфортную работу, но и повысит производительность на всех этапах взаимодействия с базой данных.
Как выбрать инструмент в зависимости от типа базы данных
Выбор инструмента для написания SQL-запросов напрямую зависит от типа базы данных, с которой предстоит работать. Разные СУБД (системы управления базами данных) имеют свои особенности, которые влияют на функционал инструментов и их совместимость с конкретной СУБД.
Для работы с реляционными базами данных, такими как MySQL, PostgreSQL, Microsoft SQL Server, идеально подойдут универсальные графические интерфейсы, поддерживающие множество различных СУБД. Пример таких инструментов – DBeaver и HeidiSQL. Они предлагают поддержку всех основных операций SQL, а также возможность работы с различными СУБД через единую панель. DBeaver выделяется своей поддержкой плагинов для специфичных для СУБД расширений и может работать с более 80 различными СУБД, включая NoSQL решения.
Когда требуется работать исключительно с MySQL или MariaDB, то лучшим выбором будет MySQL Workbench. Этот инструмент специально разработан для MySQL и предоставляет удобную среду для проектирования схем базы данных, создания запросов и их оптимизации. Вдобавок, MySQL Workbench поддерживает работу с репликацией и мониторингом серверов.
Для PostgreSQL стоит обратить внимание на pgAdmin. Это мощный инструмент с поддержкой всех современных возможностей PostgreSQL, включая работу с расширениями и управление производительностью. pgAdmin удобен для разработки и отладки запросов, а также поддерживает работу с пользователями и правами доступа.
В случае работы с Oracle Database важно учитывать, что для неё оптимально использовать Oracle SQL Developer. Этот инструмент полностью интегрирован с Oracle DB и включает в себя расширенные функции для работы с PL/SQL, а также средства для создания отчетов и анализа производительности.
Для NoSQL баз данных, таких как MongoDB, Cassandra и Redis, стоит выбирать специализированные инструменты, такие как MongoDB Compass или Studio 3T. Эти приложения предлагают удобный графический интерфейс для взаимодействия с документами в MongoDB, а также поддерживают создание запросов, индексов и управление данными в реальном времени.
В зависимости от вашего рабочего процесса и типа базы данных, также могут быть полезны инструменты для командной работы и совместной разработки, такие как DataGrip от JetBrains. DataGrip поддерживает множество СУБД, включая реляционные и NoSQL базы данных, и предлагает мощный редактор SQL с автодополнением, отладчиком запросов и визуальными средствами анализа данных.
Важно также учитывать необходимость в поддержке облачных сервисов, если вы работаете с такими платформами, как AWS RDS или Google Cloud SQL. В таких случаях могут быть полезны инструменты, поддерживающие интеграцию с облачными сервисами и возможность работы через API.
Преимущества графических интерфейсов для начинающих пользователей
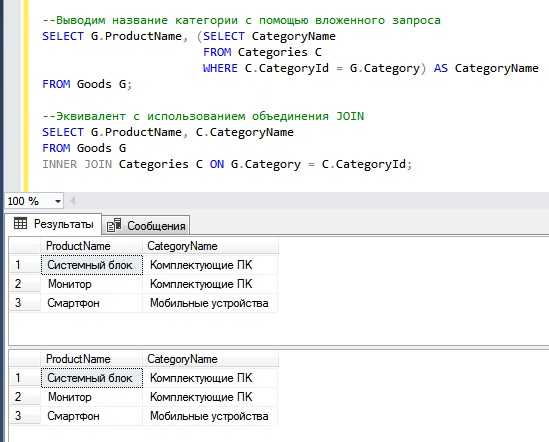
Графические интерфейсы (GUI) снижают порог входа в работу с SQL за счёт визуализации структуры баз данных и упрощённого формулирования запросов.
- Автозаполнение и подсказки. Средства вроде DBeaver или HeidiSQL предлагают списки таблиц, полей и функций, что экономит до 30 % времени на ввод синтаксиса.
- Визуальное построение запросов. Конструкторы запросов (Query Builder) позволяют перетаскиванием объединять таблицы и задавать условия, снижая риск ошибок в JOIN и WHERE.
- Предпросмотр результатов. Мгновенная выборка первых 100–500 строк помогает быстро проверять корректность запросов без полной загрузки больших объёмов данных.
- Графики и диаграммы. Инструменты, такие как DataGrip, умеют строить гистограммы и круговые диаграммы по результатам запросов, упрощая первичный анализ данных.
- История и ревизии. В GUI хранятся выполненные запросы и их результаты, что облегчает возвращение к прошлым операциям и восстановление случайно изменённого кода.
- Выберите инструмент с минимальным набором функций: начните с бесплатных версий DBeaver Community или MySQL Workbench.
- Практикуйте создание запросов через конструктор и сравнивайте с текстовыми вариантами для понимания синтаксиса.
- Используйте встроенные шаблоны: 80 % часто повторяющихся запросов доступны в списке “snippets” большинства GUI.
- Настройте цветовое выделение ключевых слов и ошибок: это ускоряет отладку и помогает заметить опечатки.
- Переходите к текстовому редактору постепенно: после освоения GUI пробуйте писать запросы вручную, опираясь на подсказки среды.
GUI-инструменты позволяют новичкам быстрее освоить логику SQL-запросов, сводя к минимуму технические препятствия и поддерживая постоянное визуальное сопровождение процесса.
Как настроить работу с несколькими базами данных одновременно
Выбор инструмента, поддерживающего одновременное подключение к разным СУБД, ускоряет анализ и интеграцию данных. Рекомендовано обратить внимание на следующие возможности:
1. Конфигурация нескольких подключений. В настройках клиента задайте отдельные профили для каждой БД: хост, порт, тип СУБД, учётные данные. Например, в DBeaver создайте новые “Connection” через File → New → Database Connection, указывая в названии источник (prod_postgres, analytics_mysql).
2. Каталогизация соединений. Группируйте подключения по проектам или средам. В DataGrip можно создать “Data Source Folder” и перетащить в него источники, чтобы быстро переключаться между тестовой и боевой средой.
3. Разграничение контекстов. При работе с кодом SQL используйте теги для обозначения активной БД. В SQL Workbench/J предусмотрен синтаксис — @connectionName перед блоком запроса. В Visual Studio Code с расширением mssql прописывайте в начале файла: — Database: SalesDB, — Database: ReportingDB.
4. Параллельный запуск запросов. Инструменты типа DbVisualizer или HeidiSQL позволяют открыть несколько вкладок с разными подключениями. Для одновременного выполнения включите опцию “Execute in all open editors” и настройте таймауты запросов под каждую БД.
5. Учет различий диалектов. Выберите редактор с подсветкой синтаксиса для нескольких СУБД. DataGrip автоматически распознаёт диалект, исходя из профиля, и при работе с разными движками переключается между SQL-диалектами без ручного указания.
6. Мониторинг и логирование. Активируйте лог запросов для каждого подключения. В DBeaver включите Connection → Query Manager → Log, чтобы отслеживать время выполнения и возможные ошибки. В случае сбоя инструмент покажет в каком профиле произошёл сбой.
Какие функции автодополнения и подсветки синтаксиса важны при выборе инструмента
Автодополнение должно предлагать не только названия таблиц и колонок, но и выражения: JOIN по ключам, функции агрегации, оконные функции и пользовательские UDF. Идеально, когда подсказки учитывают контекст запроса: после WHERE – только логические операторы и сравнения, внутри GROUP BY – только группируемые поля.
Поддержка SQL-диалектов: инструмент автоматически распознаёт синтаксис PostgreSQL, MySQL, SQL Server или Oracle и адаптирует подсветку. При этом запрещённые в текущем диалекте конструкции (например, LIMIT в Oracle) подчёркиваются как ошибки.
Подсветка строковых, числовых и временных литералов разных форматов (ISO‑DATE, UNIX‑TIMESTAMP) помогает мгновенно обнаружить опечатки. Особое внимание к шаблонам регулярных выражений в операторе LIKE: цветовое разграничение самих паттернов.
Навигация по объектам базы: при вводе имени таблицы или представления показывается количество строк, схема и пример первых 5 записей. Это ускоряет выбор полей и минимизирует ошибки.
Важна возможность настраивать цветовую палитру подсветки под собственные предпочтения (тёмная/светлая тема, контрастность), а также экспортировать/импортировать настройки между рабочими станциями.
Поддержка интеграции с другими инструментами для аналитики и отчетности
Инструмент должен уметь экспортировать результаты запросов в форматы, поддерживаемые BI‑системами: CSV с опцией разделителя, JSON с вложенными объектами и XML с XSD‑валидацией. Желательно наличие встроенных коннекторов к популярным платформам: Power BI (через OData или прямое API), Tableau (через Hyper API) и Looker (через JDBC/ODBC‑драйверы).
Наличие REST‑API позволяет автоматизировать запуск подготовленных запросов из внешних скриптов и сервировать данные в режиме on‑demand. При выборе обратите внимание на скорость отклика эндпойнтов: не менее 100 запросов в минуту в пиковый час и время ответа до 200 мс для payload размером до 1 МБ.
Поддержка вебхуков и событийной доставки данных (push‑механизм) пригодится для обновления дашбордов в реальном времени. Ищите инструменты, позволяющие настраивать фильтрацию и трансформацию данных на стороне сервиса перед отправкой, чтобы снизить нагрузку на BI‑решение.
Интеграция с системами планирования задач (Airflow, Prefect) через плагин или SDK упрощает организацию ETL‑процессов. Для сложных сценариев ориентируйтесь на инструменты с возможностью использования кастомных Python‑скриптов или SQL‑макросов внутри конвейера.
Наличие готовых шаблонов и модулей подключения к OLAP‑кубам (Mondrian, Apache Kylin) и data warehouse (Snowflake, BigQuery) ускоряет внедрение. При анализе обратите внимание на автоматическое управление сессиями, пул соединений и поддержку SSO через OAuth2 или Kerberos для единой авторизации в аналитической экосистеме.
Как оценить скорость работы инструмента при обработке больших данных
Выбор объёма тестовых данных: создайте набор не менее 100 млн строк в формате CSV или Parquet, отражающий реальную структуру таблиц. При этом загрузите 20–30 GB данных, чтобы измерения были репрезентативны.
Метрика времени выполнения: учитывайте три этапа: парсинг запроса, оптимизацию плана и фактическое выполнение. Зафиксируйте время каждого этапа средствами профайлера (например, EXPLAIN ANALYZE в PostgreSQL или Query Profile в MySQL).
Потоковая нагрузка: моделируйте одновременные подключения – минимум 10 сессий, выполняющих читательские и записывающие операции. Измерьте среднее время ответа и 95-й перцентиль латентности.
Использование ресурсов: контролируйте CPU, память и I/O с помощью системных утилит (htop, iostat). Для надёжного сравнения оставьте фоновую нагрузку ниже 5% от максимума каждого ресурса.
Повторяемость результатов: запускайте каждый тест не менее трёх раз. Рассчитайте среднее и стандартное отклонение времени выполнения. Если отклонение превышает 10%, настройте параметры сервера и повторите.
Пределы масштабирования: постепенно увеличивайте объём данных и количество параллельных запросов. Определите точку, где время выполнения растёт нелинейно (более чем на 20% при удвоении нагрузки).
Отчетность: составьте документ с графиками «время–объём данных» и «LAT95–число потоков». Используйте открытые инструменты (Grafana, Kibana) для визуализации и автоматического сбора метрик.
Какие инструменты подходят для командной работы и версионного контроля
DataGrip от JetBrains интегрируется с Git, Mercurial и SVN, позволяя выполнять коммит, ребейз и просмотр истории прямо в окне редактора. Поддержка pull requests через плагин GitToolBox ускоряет согласование изменений в SQL-файлах.
Azure Data Studio обеспечивает синхронизацию проектов через встроенную поддержку Git и GitHub. Опция Live Share позволяет нескольким разработчикам одновременно редактировать один файл запроса и обсуждать правки в реальном времени.
DBeaver EE предлагает интеграцию с Git и SVN, автоматически фиксирует изменения в SQL-скриптах и хранит привязку к метаданным соединений. Раздел «Project Explorer» структурирует запросы по папкам, совместно доступным для всех участников команды.
dbt (Core + Cloud) ориентирован на аналитические конвейеры: SQL-модели хранятся в репозитории Git, изменения проходят через pull request, а cloud-окружение запускает CI-пайплайны с тестированием и документированием.
GitLab SQL IDE встроен в GitLab CE/EE, позволяет писать и запускать запросы в контексте merge request. Автоматические проверки через CI/CD (например, lint, performance-тесты) обеспечивают качество кода перед слиянием.
Рекомендация: при выборе ориентируйтесь на стек технологий (он‑прем или облако), необходимость встроенного CI/CD и поддержку коллективного редактирования. Для аналитических платформ лучше подходят dbt и Azure Data Studio, для универсальной работы с разными базами – DataGrip или DBeaver EE.
Вопрос-ответ:
Какие основные критерии учитывать при выборе инструмента для написания SQL-запросов?
При выборе важно оценить поддержку нужных СУБД, наличие удобного редактора с подсветкой синтаксиса и автодополнением, доступ к истории запросов, возможности профилирования и анализа производительности, а также уровень лицензии и стоимость. Также стоит обратить внимание на интеграцию с системами управления версиями и наличие возможностей экспорта результатов.
Насколько важно наличие визуального конструктора запросов?
Визуальный конструктор помогает быстрее собирать простые выборки, особенно тем, кто неуверен в синтаксисе SQL. Но при сложных запросах он может оказаться громоздким. Рекомендуется выбирать инструменты, где есть и конструктор, и возможность работы в текстовом режиме без ограничений.
Какие плюсы и минусы облачных решений для написания SQL?
Облачные сервисы обеспечивают доступ из любого места, упрощают совместную работу и обычно включают автоматическое обновление. Минусы — зависимость от интернет‑соединения, риски безопасности при работе с чувствительными данными и возможные ограничения по объёму хранения или по времени выполнения запросов.
Что стоит проверить в плане безопасности при выборе SQL-редактора?
Важно убедиться в наличии шифрования соединения (SSL/TLS), поддержке многофакторной аутентификации, возможности ограничения по IP и ролям пользователей. Полезно узнать, как инструмент хранит и защищает учётные данные, а также доступны ли журналы аудита действий.
Как оценить стоимость лицензии и избежать переплат?
Сначала определите число пользователей и требуемый функционал: базовые редакторы зачастую бесплатны, продвинутые — платные. Сравните годовые и помесячные планы, учтите скрытые расходы на техподдержку и обновления. Хорошей практикой будет тестовый период, чтобы понять, соответствует ли цена реальной пользе.
Какие критерии помогут выбрать удобный графический интерфейс для составления SQL-запросов?
При выборе графического интерфейса обращайте внимание на поддержку автодополнения названий таблиц и полей, подсветку синтаксиса и валидацию запросов в реальном времени. Проверьте возможность быстрого перехода к структуре базы данных и просмотра связей между таблицами. Удобным будет интерфейс с настраиваемыми шаблонами запросов и возможностью сохранять часто используемые запросы. Также важно оценить, насколько просто экспортировать результаты в нужный формат (CSV, Excel) и интегрировать инструмент с вашей средой разработки.
Насколько важно наличие встроенных функций анализа производительности при выборе инструмента для SQL?
Наличие встроенных средств анализа скорости выполнения запросов позволяет находить «узкие места» в сложных выборках. Обычно такие функции показывают план выполнения, время на каждый шаг и объем сканируемых данных. Это помогает оптимизировать индексы и структуру запросов без переключения на сторонние утилиты. Если вы работаете с большими таблицами или сложными объединениями, отдавайте предпочтение инструменту с профилировщиком запросов и возможностью сравнивать несколько версий запросов по времени выполнения.