При работе с Python часто возникает задача преобразования двух списков в один словарь. Это может быть полезно, например, когда нужно сопоставить ключи и значения для быстрого доступа к данным. В этой статье рассмотрим несколько эффективных способов решения этой задачи, основываясь на стандартных возможностях Python.
В Python существует несколько подходов к созданию словаря из двух списков. Наиболее прямолинейным способом является использование функции zip, которая объединяет два списка в пары, а затем передает их в конструктор словаря. Однако, важно учитывать особенности работы с различными типами данных и возможные ошибки, которые могут возникнуть при несовпадении длин списков. В некоторых случаях полезно использовать дополнительные проверки или методы для обработки таких ситуаций.
Еще один способ – это использование генераторов словарей, который позволяет более гибко управлять процессом создания словаря. Этот метод подходит для случаев, когда необходимо выполнить дополнительные операции с элементами списков перед их добавлением в словарь. Важно помнить, что хотя такой способ может быть удобен, он также требует внимательности к деталям, чтобы избежать ошибок при обработке данных.
Использование функции zip для объединения двух списков

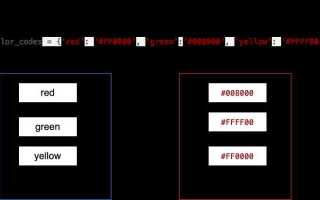
Функция zip() позволяет эффективно объединить два или более итерируемых объекта, таких как списки, в один, создавая кортежи, где каждый кортеж содержит элементы из соответствующих позиций исходных списков. Это полезно, например, при создании словаря, где один список может представлять ключи, а другой – значения.
Пример использования zip() для объединения двух списков:
keys = ['a', 'b', 'c']
values = [1, 2, 3]
result = dict(zip(keys, values))
print(result)Этот код создаст словарь: {'a': 1, 'b': 2, 'c': 3}. Важно помнить, что функция zip() останавливается на минимальной длине среди переданных итерируемых объектов. Если один список короче другого, элементы из лишнего списка игнорируются.
Для создания словаря важно, чтобы первый список содержал уникальные элементы, так как в словарях ключи не могут повторяться. В случае, если ключи повторяются, последний элемент для каждого ключа перезапишет предыдущий.
Если необходимо объединить больше двух списков, это можно сделать так:
list1 = ['a', 'b', 'c']
list2 = [1, 2, 3]
list3 = ['x', 'y', 'z']
result = list(zip(list1, list2, list3))
print(result)Это создаст список кортежей: [('a', 1, 'x'), ('b', 2, 'y'), ('c', 3, 'z')]. Такая структура полезна для более сложных данных, которые нужно обрабатывать параллельно.
Как преобразовать результат zip в словарь с помощью dict()

Функция zip() позволяет объединять два и более итерируемых объекта в последовательности кортежей, где каждый кортеж содержит элементы с одинаковыми индексами из исходных объектов. Когда нужно преобразовать результат zip в словарь, это можно сделать с помощью встроенной функции dict(), которая принимает итерируемые объекты, возвращающие кортежи из двух элементов.
Пример преобразования:
keys = ['a', 'b', 'c']
values = [1, 2, 3]
result = dict(zip(keys, values))
print(result)
В этом примере zip(keys, values) создаст итератор, который возвращает последовательность кортежей: ('a', 1), ('b', 2), ('c', 3). Функция dict() преобразует эти кортежи в словарь, где элементы из первого списка становятся ключами, а элементы второго – значениями. Результатом выполнения будет словарь: {'a': 1, 'b': 2, 'c': 3}.
Если количество элементов в списках не совпадает, zip() ограничит результат длиной самого короткого списка. В случае, если в одном из списков элементов меньше, чем в другом, лишние элементы будут проигнорированы.
Если необходимо обработать ситуацию, когда длины списков различны, можно использовать itertools.zip_longest(), который заполняет недостающие значения заданным значением, например, None. Это полезно, если важно сохранить все данные, а не обрезать их.
from itertools import zip_longest
keys = ['a', 'b', 'c']
values = [1, 2]
result = dict(zip_longest(keys, values, fillvalue=None))
print(result)
Этот код создаст словарь {'a': 1, 'b': 2, 'c': None}, где для отсутствующего значения используется None.
Что делать, если списки разной длины?

Если два списка, из которых вы хотите создать словарь, имеют разную длину, Python по умолчанию свяжет элементы по индексу. Это означает, что элементы, расположенные на одинаковых позициях в обоих списках, будут объединены в пары ключ-значение. Если один список длиннее другого, излишние элементы в более длинном списке будут проигнорированы. В случае если список ключей длиннее списка значений, это приведет к ошибке.
Как решить эту проблему? Можно воспользоваться несколькими подходами для корректной работы с разными длинами списков:
1. Использование функции zip() с обработкой остатков: Метод zip() объединяет списки, но при этом обрезает их до длины самого короткого списка. Если необходимо сохранить все элементы, можно дополнительно обработать остатки.
Пример:
keys = ['a', 'b', 'c']
values = [1, 2]
result = dict(zip(keys, values)) # {'a': 1, 'b': 2}
Если вам нужно сохранить все ключи, а недостающие значения установить по умолчанию, можно использовать itertools.zip_longest().
2. Заполнение недостающих значений: Если важно сохранить все элементы из более длинного списка, можно дополнить недостающие значения (например, значением None или любым другим).
from itertools import zip_longest
keys = ['a', 'b', 'c']
values = [1, 2]
result = dict(zip_longest(keys, values, fillvalue=None)) # {'a': 1, 'b': 2, 'c': None}
3. Оставление лишних элементов в списке: Если важен именно порядок, но не обязательность наличия значений для всех ключей, можно вручную обрабатывать лишние элементы, оставив их в виде списка или другого контейнера, вместо того чтобы игнорировать их.
4. Подсчет элементов: Если требуется, чтобы и в коротком списке были дублирующиеся элементы, можно использовать цикл, который вручную повторит значения, пока не завершится соответствующий список.
Таким образом, Python предоставляет гибкие способы для работы с разными длинами списков, и выбор метода зависит от специфики задачи.
Создание словаря с уникальными ключами из двух списков
Для создания словаря из двух списков в Python, где элементы первого списка становятся ключами, а второго – значениями, можно использовать функцию zip(). Однако, чтобы гарантировать уникальность ключей, важно учитывать возможные дубли в первом списке. В случае их присутствия, будет произведена замена значений для повторяющихся ключей, что может привести к потере данных.
Пример кода для простого создания словаря:
keys = ['a', 'b', 'c']
values = [1, 2, 3]
result = dict(zip(keys, values))
print(result)Однако если ключи не уникальны, и вы хотите сохранить все значения, можно использовать коллекцию defaultdict из модуля collections. В этом случае, каждому ключу будет соответствовать список значений, а не одно значение:
from collections import defaultdict
keys = ['a', 'b', 'a']
values = [1, 2, 3]
result = defaultdict(list)
for key, value in zip(keys, values):
result[key].append(value)
print(dict(result))Результат: {'a': [1, 3], 'b': [2]}
Если необходимо просто оставить последний элемент для каждого ключа, то можно воспользоваться стандартным методом создания словаря с помощью zip() и dict(), а перед этим очистить список ключей от повторов. Для этого подойдет использование set() или же создание нового списка с уникальными ключами, например, с помощью выражения генератора:
keys = ['a', 'b', 'a']
values = [1, 2, 3]
result = dict(zip(set(keys), values))
print(result)Этот метод может работать корректно, если порядок элементов не имеет значения. Однако, если порядок ключей важен, а дубли нужно исключить, можно использовать решение с уникализацией элементов первого списка, сохраняя порядок с помощью dict.fromkeys() или подхода с OrderedDict для более сложных задач.
Таким образом, подход к созданию словаря зависит от того, что именно требуется от ключей – их уникальность или возможность хранения нескольких значений для одного ключа. Важно выбирать подход, соответствующий бизнес-логике задачи.
Как использовать значения по умолчанию для недостающих элементов

В Python для создания словаря из двух списков можно использовать метод zip(), но иногда в одном из списков могут быть недостающие элементы. В таких случаях полезно указать значения по умолчанию для отсутствующих ключей. Рассмотрим, как это можно сделать с помощью функции dict.fromkeys() и библиотеки collections.defaultdict.
Допустим, у вас есть два списка: один содержит ключи, а другой – значения. Если один из списков длиннее другого, то при использовании zip() могут возникнуть проблемы. Чтобы решить эту задачу, можно использовать значение по умолчанию для недостающих ключей.
Пример с dict.fromkeys(): если второй список короче первого, можно добавить недостающие ключи с заданным значением:
keys = ['a', 'b', 'c']
values = [1, 2]
result = dict(zip(keys, values)) # {'a': 1, 'b': 2}
result.update(dict.fromkeys(keys[len(values):], 0)) # {'a': 1, 'b': 2, 'c': 0}
print(result)
Здесь мы создаем словарь с помощью zip(), а затем дополняем его с помощью fromkeys(), чтобы для недостающих ключей установить значение 0.
Другой способ – использовать defaultdict из модуля collections. Этот класс позволяет автоматически присваивать значения по умолчанию для ключей, которые ещё не были добавлены в словарь:
from collections import defaultdict
keys = ['a', 'b', 'c']
values = [1, 2]
result = defaultdict(int, zip(keys, values)) # {'a': 1, 'b': 2, 'c': 0}
print(dict(result))
Здесь defaultdict(int) означает, что все недостающие ключи будут иметь значение по умолчанию 0 (так как int() возвращает 0). Если второй список короче первого, недостающие ключи будут автоматически заполнены значениями по умолчанию.
Использование значений по умолчанию позволяет не только решать проблему с недостающими элементами, но и избегать ошибок при попытке обращения к несуществующему ключу. Выбор метода зависит от конкретной ситуации: dict.fromkeys() удобен для добавления значений по умолчанию для всей коллекции ключей, а defaultdict – для динамичного создания словаря с автоматическим присвоением значений при доступе к несуществующему ключу.
Преобразование нескольких списков в словарь

Когда нужно создать словарь из нескольких списков в Python, часто используют сочетание функции zip() и конструктора dict(). Этот метод позволяет эффективно комбинировать элементы из разных списков и присваивать значения ключам.
Предположим, что у нас есть два списка: один с ключами, а другой – с соответствующими значениями. Используя zip(), мы объединяем эти списки в пары, которые затем передаем в конструктор dict().
keys = ['a', 'b', 'c']
values = [1, 2, 3]
result = dict(zip(keys, values))
print(result)Результат будет следующим:
{'a': 1, 'b': 2, 'c': 3}Однако, что делать, если у вас больше двух списков? В этом случае можно комбинировать zip() с другими техниками, например, с использованием *args для распаковки элементов. Рассмотрим пример:
keys = ['a', 'b', 'c']
values1 = [1, 2, 3]
values2 = [10, 20, 30]
result = dict(zip(keys, zip(values1, values2)))
print(result)Этот код создает словарь, в котором ключи связаны с кортежами значений из двух списков:
{'a': (1, 10), 'b': (2, 20), 'c': (3, 30)}Если необходимо преобразовать больше списков, используйте zip() для объединения всех списков в одну структуру и затем создавайте словарь. Однако, будьте внимательны, чтобы количество элементов в списках было одинаковым. Если длины списков различаются, zip() обрежет лишние элементы, что может повлиять на итоговый результат.
Кроме того, для более сложных операций можно применять циклы. Например, чтобы создать словарь, где ключами будут индексы элементов, а значениями – кортежи из нескольких списков, можно использовать следующее решение:
lists = [keys, values1, values2]
result = {i: tuple(x[i] for x in lists) for i in range(len(keys))}
print(result)В результате получаем словарь с индексами, где значениями будут кортежи:
{0: ('a', 1, 10), 1: ('b', 2, 20), 2: ('c', 3, 30)}Таким образом, преобразование нескольких списков в словарь в Python – это гибкий процесс, который позволяет легко адаптировать код под конкретные задачи, используя комбинацию стандартных функций языка.
Как избежать потери данных при объединении списков
При объединении двух списков важно учитывать несколько аспектов, чтобы избежать потери данных. Особенно это актуально, когда нужно создать словарь из двух списков, например, один список содержит ключи, а другой – значения. В таких случаях важно тщательно контролировать процесс слияния, чтобы не потерять ни один элемент.
Вот несколько рекомендаций для безопасного объединения списков:
- Использование правильной структуры данных: Если порядок элементов важен, можно использовать
zipдля точного сопоставления элементов из двух списков. Он обеспечит сохранение структуры, даже если списки будут разной длины. - Обработка разных длин списков: Если длина списков не совпадает, можно заранее определить, что делать с «лишними» элементами. Например, обрезать длинный список или дополнить короткий списком пустых значений (
Noneили другие placeholders). - Предотвращение потери уникальных ключей: Если создается словарь, где ключи могут повторяться, стоит заранее обработать этот случай. Например, можно использовать
collections.defaultdictили сохранить несколько значений для одного ключа в виде списка. - Проверка на пустые списки: Прежде чем объединять списки, всегда проверяйте их на пустоту. Пустые списки могут привести к нежелательным результатам, например, при создании словаря из двух списков: если один из них пуст, результат будет неполным или некорректным.
- Учет порядка элементов: При объединении важно учитывать, что порядок элементов в списках может влиять на конечный результат. Если порядок значений критичен, убедитесь, что элементы из одного списка сопоставляются с элементами из другого в правильной последовательности.
Если вы правильно подходите к процессу объединения и учитываете эти рекомендации, потери данных можно избежать. Однако, стоит помнить, что для сложных случаев, таких как обработка дублирующихся ключей или разная длина списков, придется использовать дополнительные механизмы контроля, такие как проверки и обработки ошибок.
Примеры создания словаря с различными типами данных в списках
В Python можно создавать словари, используя различные типы данных в списках. Рассмотрим несколько примеров, где ключи и значения могут быть как строками, так и числами, а также списками и другими сложными структурами данных.
1. Когда оба списка содержат строки, создание словаря происходит просто. Например, ключами будут строки, а значениями – другие строки:
keys = ['a', 'b', 'c'] values = ['apple', 'banana', 'cherry'] dictionary = dict(zip(keys, values)) print(dictionary)
Результат: {‘a’: ‘apple’, ‘b’: ‘banana’, ‘c’: ‘cherry’}
2. В случае числовых значений создание словаря с использованием чисел в качестве значений выглядит аналогично:
keys = [1, 2, 3] values = [10, 20, 30] dictionary = dict(zip(keys, values)) print(dictionary)
Результат: {1: 10, 2: 20, 3: 30}
3. Если значения представлены списками, мы получаем словарь с более сложной структурой. В этом случае можно хранить дополнительные данные, связанные с каждым ключом:
keys = ['id1', 'id2', 'id3'] values = [[1, 'Alice'], [2, 'Bob'], [3, 'Charlie']] dictionary = dict(zip(keys, values)) print(dictionary)
Результат: {‘id1’: [1, ‘Alice’], ‘id2’: [2, ‘Bob’], ‘id3’: [3, ‘Charlie’]}
4. Когда в списках встречаются разные типы данных, например, числа и строки, создание словаря возможно и в этом случае:
keys = ['name', 'age', 'city'] values = ['John', 25, 'New York'] dictionary = dict(zip(keys, values)) print(dictionary)
Результат: {‘name’: ‘John’, ‘age’: 25, ‘city’: ‘New York’}
5. Можно создавать словарь и из списка кортежей, где каждый кортеж представляет собой пару (ключ, значение). Это подходит, если необходимо заранее подготовить пару данных:
pairs = [('a', 10), ('b', 20), ('c', 30)]
dictionary = dict(pairs)
print(dictionary)
Результат: {‘a’: 10, ‘b’: 20, ‘c’: 30}
6. Для более сложных случаев, например, если в списках содержатся словари, можно комбинировать такие структуры. Например:
keys = ['first', 'second']
values = [{'name': 'Alice'}, {'name': 'Bob'}]
dictionary = dict(zip(keys, values))
print(dictionary)
Результат: {‘first’: {‘name’: ‘Alice’}, ‘second’: {‘name’: ‘Bob’}}
Эти примеры показывают гибкость Python в создании словарей с использованием разных типов данных, что позволяет решать задачи, связанные с обработкой информации в разных форматах.