В Python работа с коллекциями данных, такими как списки, является одной из основ программирования. Иногда возникает необходимость удалить строку из списка, будь то удаление по значению или по индексу. Это не всегда интуитивно понятно для новичков, так как для каждой ситуации существуют свои методы. Важно понимать, какой из них будет наиболее эффективным для вашего конкретного случая.
Для удаления строки по значению можно использовать метод remove(). Этот метод ищет первый элемент, равный переданному значению, и удаляет его. Важно, что если такого элемента нет в списке, будет выброшено исключение ValueError. Например:
my_list = ['яблоко', 'банан', 'вишня']
my_list.remove('банан') # результат: ['яблоко', 'вишня']Однако, если вам необходимо удалить строку по индексу, то вам следует воспользоваться методом pop(). Этот метод удаляет элемент по индексу и возвращает его. Если индекс не указан, метод удаляет и возвращает последний элемент списка. При этом pop() не выбрасывает исключение, если индекс выходит за пределы списка, в отличие от remove():
my_list = ['яблоко', 'банан', 'вишня']
my_list.pop(1) # результат: 'банан', список: ['яблоко', 'вишня']Иногда бывает полезно удалить все элементы, которые равны заданному значению. Для этого лучше использовать генератор списков, так как он позволяет создавать новый список с исключением ненужных значений:
my_list = ['яблоко', 'банан', 'вишня', 'банан']
my_list = [x for x in my_list if x != 'банан'] # результат: ['яблоко', 'вишня']Не забывайте, что выбор метода зависит от ваших задач. Важно учитывать размер списка и количество операций, которые вам нужно выполнить. Для простых случаев методы remove() и pop() подойдут идеально, но для более сложных случаев стоит обратить внимание на генераторы списков.
Удаление строки по индексу с помощью метода del
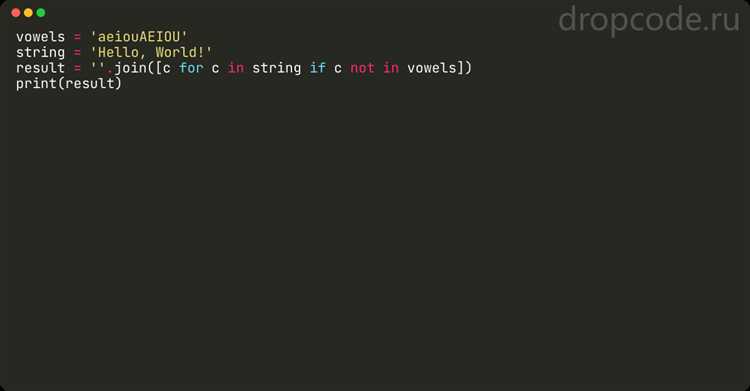
Метод del позволяет удалить элемент списка по его индексу. При этом важно учитывать, что индексы в Python начинаются с нуля. Если индекс превышает длину списка, произойдёт ошибка IndexError.
Пример удаления строки из списка по индексу:
my_list = ["яблоко", "банан", "киви"]
del my_list[1]
print(my_list) # Выведет: ['яблоко', 'киви']Метод del удаляет именно элемент, а не возвращает его. То есть, в отличие от метода pop(), использование del не предоставляет удалённое значение.
Также стоит помнить, что del можно использовать для удаления срезов списка:
my_list = ["яблоко", "банан", "киви", "груша"]
del my_list[1:3]
print(my_list) # Выведет: ['яблоко', 'груша']В случае, если индекс не существует, будет сгенерирована ошибка. Чтобы избежать этого, можно использовать конструкцию try-except или проверку наличия индекса в списке с помощью оператора in.
if 5 < len(my_list):
del my_list[5]
else:
print("Индекс вне диапазона!")Этот метод эффективен, когда необходимо удалить элемент без необходимости возвращать его, а также когда нужно работать с диапазонами элементов.
Использование метода remove() для удаления строки

Метод remove() позволяет удалить первое вхождение строки из списка. Он принимает один аргумент – значение, которое требуется удалить. Если строка отсутствует в списке, метод вызывает исключение ValueError.
Пример использования:
fruits = ['яблоко', 'банан', 'киви', 'яблоко']
fruits.remove('яблоко')
print(fruits)В этом примере из списка fruits удаляется первое вхождение строки 'яблоко'. После выполнения кода список будет содержать: ['банан', 'киви', 'яблоко'].
Важно помнить, что метод remove() изменяет исходный список и работает только с первым найденным элементом, даже если в списке присутствуют дубликаты. Чтобы удалить все вхождения строки, нужно использовать цикл или метод filter().
Пример удаления всех вхождений строки:
fruits = ['яблоко', 'банан', 'киви', 'яблоко']
while 'яблоко' in fruits:
fruits.remove('яблоко')
print(fruits)Этот код удалит все 'яблоки' из списка.
Метод remove() работает эффективно, но при использовании с большими списками может потребовать дополнительных затрат времени, так как поиск элемента в списке имеет линейную сложность. Если необходимо удалять элементы по индексу или часто, следует рассмотреть использование других структур данных, например, множества или словаря, которые обеспечивают более быстрые операции удаления.
Удаление строки через pop() и обработка индекса ошибки
Метод pop() в Python позволяет удалить элемент из списка по индексу и вернуть его. Если индекс не указан, по умолчанию удаляется последний элемент. Однако при работе с этим методом важно учитывать возможные ошибки, связанные с неверным индексом.
Чтобы удалить строку, нужно указать индекс её позиции в списке. Например, для удаления строки на третьем месте можно использовать следующий код:
my_list = ["яблоко", "банан", "вишня", "груша"]
my_list.pop(2)Этот код удалит строку "вишня" из списка. Метод pop() возвращает удалённый элемент, что позволяет сразу использовать его в дальнейшем. Например, можно сохранить удалённую строку в переменную:
removed_item = my_list.pop(2)
print(removed_item)Однако при попытке удалить элемент по индексу, который выходит за пределы списка, возникнет ошибка IndexError. Чтобы избежать этой ошибки, важно предварительно проверять, что индекс находится в пределах допустимых значений. Например, можно использовать конструкцию try-except:
try:
my_list.pop(10)
except IndexError:
print("Ошибка: индекс за пределами списка")Такой подход позволит предотвратить возникновение ошибок при попытке удалить элемент с некорректным индексом. Кроме того, можно перед использованием pop() проверить длину списка с помощью len(), чтобы убедиться, что индекс доступен:
index = 10
if index < len(my_list):
removed_item = my_list.pop(index)
else:
print("Индекс выходит за пределы списка")Таким образом, метод pop() в сочетании с обработкой ошибок помогает безопасно удалять элементы из списка, не сталкиваясь с неожиданными исключениями.
Как удалить все строки, равные заданному значению
Для удаления всех строк, равных определённому значению, используйте генератор списков. Это надёжный способ, исключающий модификацию списка во время итерации:
список = ["яблоко", "банан", "яблоко", "груша"]
значение = "яблоко"
список = [элемент for элемент in список if элемент != значение]
В результате список будет содержать только те элементы, которые не совпадают с заданным значением. Такой подход сохраняет порядок элементов и не вызывает ошибок, связанных с удалением элементов по индексу.
Если требуется удалить строки из списка, содержащего как строки, так и другие типы данных, применяйте дополнительную проверку типа:
список = ["текст", 42, "текст", None]
значение = "текст"
список = [элемент for элемент in список if not (isinstance(элемент, str) and элемент == значение)]
Это предотвратит удаление элементов, не являющихся строками, даже если они равны по значению. Избегайте метода remove(), так как он удаляет только первое вхождение и требует многократного вызова в цикле, что неэффективно при больших объёмах данных.
Применение list comprehension для удаления строк
List comprehension позволяет создать новый список, исключив строки, которые соответствуют заданному условию. Это предпочтительный способ, когда требуется фильтрация без изменения оригинального списка.
- Чтобы удалить конкретную строку:
список = [s for s in список if s != "удаляемая_строка"] - Удаление строк по части содержимого:
список = [s for s in список if "подстрока" not in s] - Игнорирование строк с учётом регистра:
список = [s for s in список if s.lower() != "пример"] - Удаление пустых или пробельных строк:
список = [s for s in список if s.strip()]
Использование list comprehension предпочтительнее циклов for с удалением элементов, так как позволяет избежать ошибок, связанных с изменением списка во время итерации.
Удаление строки с условием через фильтрацию
Фильтрация – эффективный способ удалить строки из списка по заданному критерию. Для этого применяют генераторы списков с условием.
Пример: удалить все строки, содержащие подстроку "temp":
data = ["temp_file", "main.py", "temp_log", "readme.md"]
filtered = [s for s in data if "temp" not in s]
Результат: ['main.py', 'readme.md']. Условие "temp" not in s исключает строки с ненужным содержимым.
Если требуется удалить строки по длине, например, короче 5 символов:
data = ["log", "config", "init", "main"]
filtered = [s for s in data if len(s) >= 5]
Результат: ['config']. Использование len(s) >= 5 сохраняет только нужные элементы.
Для удаления строк, начинающихся с символа "_":
data = ["_cache", "main.py", "_temp", "app.py"]
filtered = [s for s in data if not s.startswith("_")]
Такой подход масштабируем и читаем. Он сохраняет структуру списка без модификации оригинала.
Особенности удаления строк в многомерных списках
Для удаления строки по индексу используется del или метод pop(). Например, del matrix[2] удалит третью строку из списка matrix. Метод pop(2) делает то же, но дополнительно возвращает удалённый элемент.
Удаление по значению требует точного совпадения вложенного списка: matrix.remove([1, 2, 3]) удалит первую строку, содержащую ровно эти элементы. Если структура вложенного списка отличается, даже незначительно, метод вызовет ошибку ValueError.
Удаление строк с определённым условием требует фильтрации: matrix = [row for row in matrix if row[0] != 0] удалит все строки, где первый элемент равен нулю. Этот способ предпочтительнее при работе с условиями, так как не вызывает проблем с индексами.
При изменении многомерного списка внутри цикла for использовать remove() или del не рекомендуется. Лучше создавать новый список на основе фильтрации, чтобы избежать пропуска элементов из-за смещения индексов.
Если требуется удалить все пустые строки, применяется фильтр: matrix = [row for row in matrix if row]. Это удаляет вложенные списки, эквивалентные пустому списку [], но не влияет на строки с нулями или пустыми строками внутри.