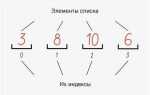
В Python сортировка – это ключевая операция, которая используется в различных областях, начиная от обработки данных и заканчивая оптимизацией работы программ. Встроенные алгоритмы сортировки, такие как sorted() и метод sort(), базируются на алгоритме Timsort, который сочетает в себе лучшие аспекты сортировок слиянием и вставками. Это позволяет эффективно работать с большими массивами данных, достигая оптимальной производительности на большинстве реальных наборов данных.
Особенность алгоритма Timsort заключается в его адаптивности: он умеет эффективно обрабатывать уже частично отсортированные данные. Это особенно важно при работе с большими списками, когда часть данных может быть уже отсортирована или находиться в близком к отсортированному виде. Кроме того, Timsort использует принцип стабильности сортировки, что означает, что равные элементы сохраняют свой относительный порядок после сортировки.
Для более глубокого понимания стоит обратить внимание на альтернативы встроенным методам. Алгоритм быстрой сортировки (Quicksort) зачастую оказывается более быстрым в условиях случайных данных, однако его худшая производительность (O(n²)) проявляется при уже отсортированных или почти отсортированных входных данных. В отличие от этого, сортировка слиянием работает стабильно, но требует дополнительной памяти для хранения промежуточных данных.
При выборе алгоритма сортировки стоит учитывать характер данных, с которыми предстоит работать. В случаях, когда входные данные малые или когда необходима стабильная сортировка, Python предлагает достаточно быстрые и удобные решения. Однако для более сложных задач с большими объемами данных и высокой частотой обновлений стоит рассматривать оптимизацию алгоритмов, а также комбинированные методы сортировки, которые могут значительно ускорить выполнение программы.
Как выбрать подходящий алгоритм сортировки для проекта

При выборе алгоритма сортировки для проекта важно учитывать несколько ключевых факторов: объем данных, требования к скорости выполнения, возможность использования памяти и тип данных, с которыми работает алгоритм.
1. Оценка объема данных: Алгоритмы сортировки сильно различаются по производительности в зависимости от количества элементов. Для малых массивов (до нескольких тысяч элементов) можно использовать простые алгоритмы, такие как сортировка вставками или сортировка выбором, так как их простота и небольшие затраты на реализацию оправдывают более низкую эффективность. Однако при работе с большими массивами следует выбирать более эффективные алгоритмы, такие как быстрая сортировка или сортировка слиянием.
2. Учет сложности алгоритма: Алгоритмы сортировки могут различаться по своей временной сложности. Например, быстрая сортировка имеет среднюю сложность O(n log n), что делает её предпочтительным выбором для большинства случаев. В то время как сортировка пузырьком имеет худшую сложность O(n²), что делает её непригодной для работы с большими объемами данных.
3. Потребности по памяти: Если проект ограничен по памяти, стоит обратить внимание на алгоритмы с минимальными требованиями к дополнительной памяти. Например, сортировка вставками требует только O(1) дополнительной памяти, в то время как сортировка слиянием требует O(n) дополнительной памяти для хранения временных массивов.
4. Тип данных: Некоторые алгоритмы могут работать быстрее или эффективнее с определенными типами данных. Например, если данные уже частично отсортированы, то сортировка вставками может оказаться более эффективной. В случае данных с многими дублирующимися элементами эффективным будет поразрядный алгоритм сортировки (например, картирование).
5. Параллельность: Для очень больших объемов данных стоит рассматривать алгоритмы, которые поддерживают параллельную обработку, такие как сортировка слиянием с параллельным выполнением. Эти алгоритмы могут значительно ускорить процесс сортировки на многозадачных системах.
Выбор алгоритма сортировки должен быть обусловлен особенностями проекта. Невозможно выделить универсальный алгоритм, который бы подходил для всех случаев. Важно проводить тестирование с реальными данными и учитывать ограничение по времени и памяти для оптимальной производительности.
Особенности работы сортировки с большими объемами данных
Для обработки больших объемов данных важно учитывать ограничения памяти. Алгоритмы, которые требуют дополнительной памяти для хранения промежуточных результатов, могут оказаться непригодными для очень больших массивов, где объем оперативной памяти ограничен. В таких случаях стоит рассмотреть алгоритмы, которые работают «на месте», такие как сортировка пузырьком или сортировка вставками, но они менее эффективны на больших данных.
Сортировка слиянием, хотя и требует дополнительной памяти, хорошо работает с большими объемами данных благодаря своей стабильной временной сложности O(n log n). Однако для массивов, которые не помещаются в память, необходимо использовать внешнюю сортировку. Это подход, при котором данные обрабатываются по частям, часто с использованием жестких дисков или других средств хранения.
Скорость сортировки также зависит от того, как данные могут быть разделены. Если массив данных можно эффективно разбить на подмассивы, каждый из которых сортируется отдельно, то это позволяет параллелизировать задачу. Например, алгоритм быстрой сортировки может быть адаптирован для многозадачности, что значительно ускоряет процесс обработки на многопроцессорных системах.
Другим важным аспектом является распределение данных. Когда данные представлены в виде уже отсортированных или почти отсортированных частей, можно использовать адаптивные алгоритмы сортировки, такие как Timsort, который применяется в Python. Этот алгоритм использует преимущества уже отсортированных фрагментов, минимизируя количество операций.
Наконец, важным моментом является выбор подходящей структуры данных для сортировки. Например, если данных слишком много для обработки в памяти, но необходимо проводить сортировку с быстрым доступом к элементам, то использование структур данных, таких как куча или B-деревья, может быть более эффективным, чем стандартные массивы.
Как оптимизировать сортировку по времени выполнения в Python

Чтобы эффективно оптимизировать время выполнения алгоритмов сортировки в Python, нужно учитывать несколько ключевых аспектов, таких как выбор подходящего алгоритма, использование встроенных функций и уменьшение сложности данных.
1. Выбор алгоритма сортировки: Наиболее быстрым для большинства случаев является сортировка слиянием и быстрая сортировка. Для больших объемов данных их сложность составляет O(n log n), что позволяет эффективно справляться с сортировкой при большом числе элементов. Однако для небольших коллекций лучше использовать сортировку вставками, которая имеет меньшую константу времени и для небольших списков работает быстрее.
2. Использование встроенной функции sorted() и метода list.sort(): В Python встроенная сортировка реализована на основе алгоритма Timsort, который оптимизирует время работы для частично отсортированных данных. Сортировка с использованием метода list.sort() выполняется на месте и является более эффективной по памяти, чем sorted(), которая создает новый список. В большинстве случаев использование этих встроенных методов является предпочтительным, поскольку они имеют лучшую производительность, чем многие другие алгоритмы сортировки.
3. Предсортированные данные: Если данные уже частично отсортированы, то алгоритм Timsort значительно ускоряет сортировку. В таких случаях стоит учитывать предварительную обработку данных и избегать их полного перемешивания перед сортировкой.
4. Параллельная сортировка: Для очень больших данных можно использовать многозадачность или многопоточность для параллельной сортировки. Например, с помощью библиотеки concurrent.futures можно распределить задачу сортировки на несколько потоков, что может значительно ускорить процесс на многозадачных системах.
5. Минимизация операций обмена: Оптимизация работы сортировщика заключается в минимизации количества обменов элементов. Для этого важно избегать лишних операций и использовать алгоритмы, которые снижают количество перестановок, такие как сортировка слиянием или быстрая сортировка, в отличие от сортировки пузырьком.
6. Профилирование и тестирование: Прежде чем оптимизировать алгоритм сортировки, необходимо провести профилирование с использованием таких инструментов, как cProfile, чтобы понять, где именно происходят узкие места. После этого можно применить targeted optimizations, например, путем выбора правильного алгоритма сортировки в зависимости от специфики данных.
Применение встроенных функций сортировки в Python: преимущества и ограничения
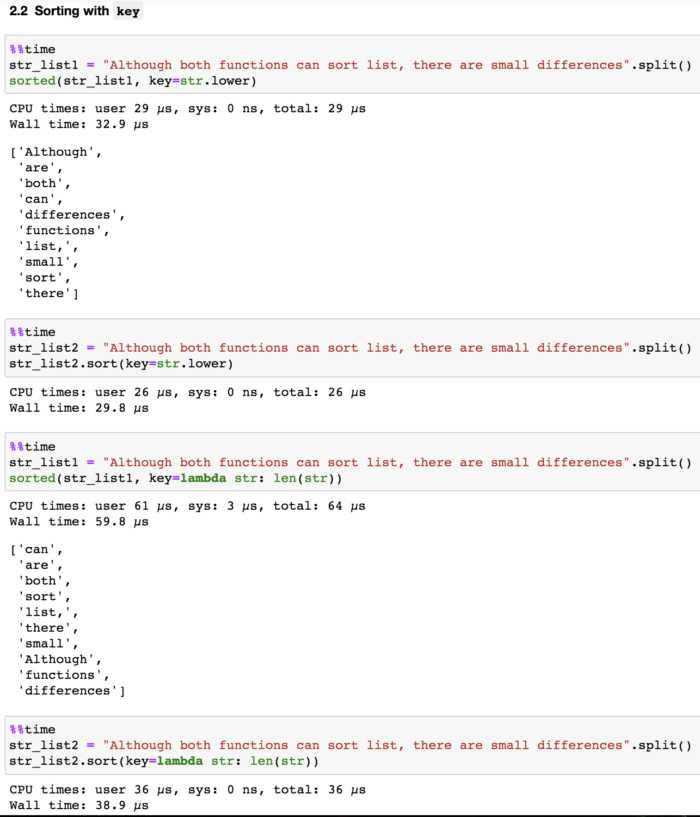
В Python для сортировки данных часто используются встроенные функции sorted() и метод list.sort(). Оба подхода предоставляют удобный способ упорядочивания коллекций, но имеют разные особенности в использовании.
Преимущества
- Простота и читаемость: Функции
sorted()иlist.sort()интуитивно понятны и требуют минимальных усилий для применения. Это делает код более читаемым и ускоряет разработку. - Оптимизация под производительность: Эти функции используют алгоритм Timsort, который в большинстве случаев имеет хорошую производительность. Время работы составляет
O(n log n)для общего случая иO(n)для уже отсортированных данных. - Поддержка кастомных функций сортировки: Оба метода позволяют задавать параметр
key, что дает возможность сортировать по произвольному критерию, например, по определенному полю в объектах. - Стабильность сортировки: Timsort – стабильный алгоритм, что означает, что элементы с одинаковыми значениями сохраняют свой порядок относительно друг друга.
Ограничения
- Изменение исходных данных: Метод
list.sort()изменяет сам список, в отличие отsorted(), который возвращает новый отсортированный список. Это может привести к ошибкам, если разработчик не учитывает это поведение. - Использование дополнительной памяти: В случае использования
sorted()создается новый список, что требует дополнительной памяти. Это может быть проблемой при работе с большими объемами данных. - Ограничение по типам данных: Встроенные функции не могут работать с объектами произвольных типов без корректного определения их порядка через параметр
keyили перегрузку метода__lt__в случае пользовательских классов.
Использование встроенных функций сортировки в Python удобно, но важно учитывать их особенности при выборе между sorted() и list.sort(), чтобы оптимизировать производительность и избежать неожиданных ошибок в коде.
Влияние стабильности сортировки на результат при повторяющихся значениях
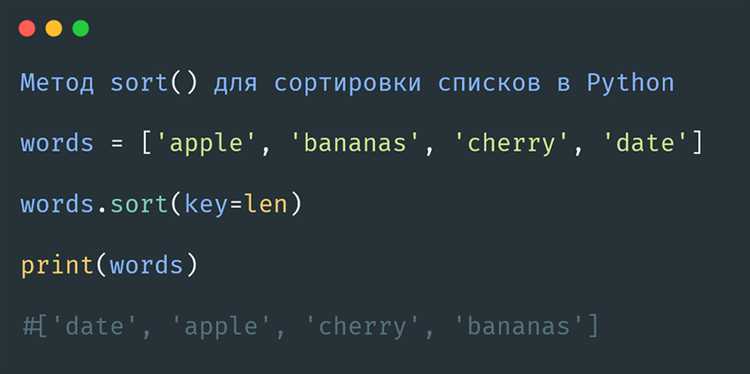
Стабильность сортировки в контексте алгоритмов означает сохранение порядка элементов с одинаковыми значениями относительно их исходного положения в списке. Это свойство важно, когда данные содержат одинаковые элементы, и требуется гарантировать, что их относительный порядок останется неизменным после сортировки.
При использовании нестабильных сортировок, таких как сортировка пузырьком или быстрая сортировка в некоторых вариациях, элементы с одинаковыми значениями могут поменяться местами, что изменяет их первоначальный порядок. Это может быть нежелательно в некоторых сценариях, например, при сортировке объектов, где важен порядок появления или связанная с элементами информация.
Стабильные сортировки, такие как сортировка слиянием или сортировка вставками, сохраняют этот порядок. Это особенно важно в случаях, когда данные представляют собой объекты с множеством атрибутов, и сортировка по одному из атрибутов не должна нарушать порядок объектов по другим признакам.
Для разработки эффективных алгоритмов сортировки важно учитывать, что в зависимости от контекста задачи стабильность может быть критически важной или не иметь значения. В случаях, где порядок повторяющихся элементов не влияет на конечный результат, можно использовать нестабильные алгоритмы, что обеспечит меньшие вычислительные затраты. В других ситуациях стабильная сортировка поможет избежать ошибок и сохранить консистентность данных.
Использование алгоритмов сортировки в многозадачных приложениях на Python

Алгоритмы сортировки играют ключевую роль в многозадачных приложениях на Python, где важна не только скорость обработки данных, но и эффективное использование ресурсов системы. Когда несколько потоков или процессов одновременно сортируют данные, важно правильно выбирать алгоритмы и учитывать особенности многозадачности.
В многозадачных приложениях часто используется параллелизм для ускорения процессов. В таких случаях необходимо учитывать несколько факторов, включая блокировки ресурсов, синхронизацию данных и возможность увеличения производительности при масштабировании на несколько ядер.
- Многозадачность и блокировки: В многозадачных приложениях важно минимизировать блокировки, которые могут возникать при работе с общими данными. Алгоритмы сортировки, которые используют разделение данных на части (например, Merge Sort), могут эффективно использовать параллельные потоки для обработки различных частей данных одновременно.
- Использование алгоритмов сортировки с низким уровнем блокировок: В Python важно помнить о GIL (Global Interpreter Lock), который ограничивает параллельное выполнение байт-кода в одном процессе. Однако многозадачные приложения могут извлечь пользу из алгоритмов, которые минимизируют количество операций, требующих синхронизации, таких как Quick Sort или сортировка слиянием.
- Параллельная сортировка с использованием многопроцессности: Для задач, где GIL является ограничением, можно использовать многопроцессные подходы, например, с помощью модуля
multiprocessing. Каждый процесс может сортировать отдельный кусок данных, а затем происходит объединение результатов. Это особенно эффективно при работе с большими объемами данных, требующих масштабирования.
Пример использования многозадачности с алгоритмом сортировки слиянием:
- Данные разбиваются на несколько частей с помощью модуля
multiprocessing. - Каждая часть сортируется в отдельном процессе с помощью стандартного алгоритма сортировки, такого как
sorted()или Quick Sort. - После завершения сортировки результаты объединяются в один отсортированный список с использованием метода слияния.
Для улучшения производительности в многозадачных приложениях на Python рекомендуется выбирать алгоритмы сортировки, которые обеспечивают быстрые вычисления в параллельных потоках, а также избегать лишней синхронизации, что может привести к снижению общей производительности. Один из наиболее эффективных вариантов – это использование алгоритма Quick Sort с ограничением на размер подмассива, после чего используется сортировка слиянием на маленьких подмассивах.
Реализация пользовательских алгоритмов сортировки на Python

При разработке программ часто возникает необходимость в создании собственных алгоритмов сортировки для специфических задач. Реализация таких алгоритмов в Python может варьироваться в зависимости от поставленных требований, таких как производительность, особенности данных или потребности в нестандартных операциях. Рассмотрим несколько примеров пользовательских алгоритмов сортировки и особенности их реализации.
1. Сортировка пузырьком
Этот алгоритм является классическим примером простого, но неэффективного метода сортировки. Он проходит по списку несколько раз, сравнивая соседние элементы и меняя их местами, если они расположены в неправильном порядке.
def bubble_sort(arr):
n = len(arr)
for i in range(n):
swapped = False
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
swapped = True
if not swapped:
break
return arr
Этот алгоритм имеет временную сложность O(n²) в худшем случае, что делает его неэффективным для больших наборов данных.
2. Сортировка вставками
Алгоритм сортировки вставками работает путем последовательного выбора элементов и вставки их в уже отсортированную часть массива. Он эффективен для небольших массивов или почти отсортированных данных.
def insertion_sort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
Время работы этого алгоритма также O(n²), но при правильном использовании на малых объемах данных он может быть достаточно быстрым.
3. Быстрая сортировка
Быстрая сортировка – это один из наиболее эффективных алгоритмов сортировки, использующих принцип «разделяй и властвуй». Он работает путем выбора опорного элемента, разделения массива на две части и рекурсивной сортировки этих частей.
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
Алгоритм имеет среднюю временную сложность O(n log n), но в худшем случае (при неправильном выборе опорного элемента) может достигать O(n²).
4. Сортировка слиянием
Сортировка слиянием также использует метод «разделяй и властвуй». Массив делится пополам, каждая часть сортируется рекурсивно, а затем сливается в отсортированный массив. Алгоритм стабилен и имеет хорошую производительность.
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
Этот алгоритм имеет временную сложность O(n log n), но требует дополнительной памяти для хранения промежуточных массивов, что может быть важным фактором для больших данных.
Рекомендации по выбору алгоритма
При выборе алгоритма сортировки важно учитывать объем данных и требования к производительности. Для небольших массивов сортировка пузырьком или вставками может быть достаточно эффективной. Для средних и больших массивов следует использовать более быстрые алгоритмы, такие как быстрая сортировка или сортировка слиянием. Важно также учитывать стабильность алгоритма – сортировка слиянием и вставками являются стабильными, в то время как быстрая сортировка – нет.
Вопрос-ответ:
Что такое алгоритм сортировки в Python и как он работает?
Алгоритм сортировки в Python — это метод упорядочивания элементов в списке или другом коллекции данных. В Python есть несколько встроенных алгоритмов для сортировки, таких как сортировка методом пузырька, сортировка вставками и быстрая сортировка. Каждый алгоритм имеет свои особенности, в зависимости от сложности выполнения и используемой структуры данных. Например, метод сортировки по возрастанию или убыванию сортирует элементы с учетом их значений, а не их типов. Сортировка в Python осуществляется за счет применения различных стратегий, которые влияют на скорость и эффективность алгоритма в разных ситуациях.
Какие бывают способы сортировки в Python и какие их отличия?
В Python существует несколько методов сортировки: метод пузырька, сортировка вставками, быстрая сортировка, сортировка слиянием и другие. Каждый метод имеет свои особенности. Например, сортировка методом пузырька считается медленной, так как она многократно сравнивает и меняет местами соседние элементы. Быстрая сортировка более эффективна для больших данных, а сортировка слиянием используется для работы с очень большими наборами данных, когда важно минимизировать использование памяти. Различия между ними заключаются в скорости выполнения и сложности алгоритма в разных условиях.
Что такое метод сортировки "пузырьком" и когда его стоит использовать?
Метод сортировки пузырьком — это простой алгоритм, который многократно проходит по списку и меняет местами элементы, если они расположены в неправильном порядке. Это происходит до тех пор, пока не будет выполнен полный проход по списку, не требующий изменений. Несмотря на свою простоту, сортировка пузырьком имеет большие недостатки в плане производительности, особенно для больших списков, так как ее сложность составляет O(n²). Этот метод рекомендуется использовать для небольших коллекций или в случаях, когда простота реализации важнее, чем высокая скорость.
Как работает быстрая сортировка в Python и почему она считается эффективной?
Быстрая сортировка (QuickSort) — это алгоритм, который использует принцип "разделяй и властвуй". Он выбирает опорный элемент из списка и разделяет остальные элементы на две группы: меньшие и большие, чем опорный. Далее каждая из этих групп сортируется рекурсивно. Быстрая сортировка считается эффективной, так как в среднем она работает за время O(n log n), что гораздо быстрее, чем другие алгоритмы сортировки, такие как сортировка пузырьком или вставками. Этот алгоритм подходит для работы с большими объемами данных.
Можно ли использовать сортировку в Python для пользовательских объектов?
Да, в Python можно сортировать пользовательские объекты. Для этого нужно определить, как именно сравнивать эти объекты. Обычно это делается с помощью метода __lt__ (less than), который позволяет указать, как сравнивать два объекта. Например, можно создать класс, в котором будет задан порядок сортировки по какому-либо полю или атрибуту объекта. После этого можно использовать встроенную функцию sorted() или метод .sort(), чтобы отсортировать объекты этого класса.