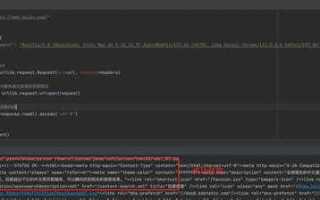
В Python 3 библиотека urllib2 была интегрирована в модуль urllib, а также частично переработана. Если вы хотите использовать функциональность, аналогичную старой urllib2, вам нужно будет использовать другие компоненты этого модуля, такие как urllib.request и urllib.error.
В Python 2 urllib2 был предназначен для работы с HTTP-запросами, включая отправку запросов и обработку ответов. В Python 3 это поведение теперь распределено между несколькими модулями, что улучшает разделение логики и облегчает работу с различными типами запросов. Чтобы перенести старый код, необходимо адаптировать использование функций и классов из urllib.request, например, для отправки запросов и работы с ответами.
Чтобы установить и использовать urllib в Python 3, достаточно стандартной установки Python. Однако для тех, кто переходит с Python 2, следует обратить внимание на изменения в API. Если вам все же требуется функциональность, идентичная urllib2, вы можете импортировать нужные части из urllib.request или других подмодулей. Важно понимать, что прямой аналог urllib2 в Python 3 отсутствует, и для работы с HTTP запросами вам нужно будет использовать правильные импорты и методы из urllib.
Почему urllib2 не существует в Python 3?
В Python 3 модуль urllib2 был удалён, поскольку его функциональность была интегрирована в другие части стандартной библиотеки. В Python 2 urllib2 был важным модулем для работы с HTTP-запросами, однако в Python 3 архитектура работы с сетевыми запросами претерпела значительные изменения.
Основным шагом в эволюции библиотеки стало объединение функционала из нескольких модулей в Python 2 в единый пакет urllib. Это включало работу с URL, кодирование запросов и сам процесс отправки HTTP-запросов. В результате была создана более согласованная и удобная для использования структура, где функции из urllib2 теперь доступны через urllib.request, urllib.error и другие подмодули.
Конкретные изменения касаются таких методов, как urllib.request.urlopen, который теперь выполняет функции, ранее разделённые между urllib2.urlopen и другими функциями. Дополнительно, Python 3 улучшил поддержку работы с кодировками и декодировками, что привело к устранению необходимости в urllib2 как отдельном модуле.
Для разработчиков, мигрирующих с Python 2 на Python 3, важно знать, что код, использующий urllib2, нужно адаптировать. Вместо urllib2.urlopen() следует использовать urllib.request.urlopen(). Однако стоит учитывать, что в Python 3 также были улучшены функции обработки ошибок, что обеспечило большую гибкость и удобство работы с сетевыми запросами.
Таким образом, удаление urllib2 в Python 3 связано с улучшением структуры библиотеки и консолидацией функций в более удобные и логичные модули. Новая архитектура стала более логичной и эффективной для современных задач, упрощая работу с HTTP-запросами и обработкой ошибок.
Чем отличается urllib2 от urllib в Python 3?
В Python 3 библиотека urllib заменяет несколько модулей из Python 2, включая urllib2. Модуль urllib2 в Python 2 был предназначен для работы с HTTP-запросами, поддерживал создание запросов, обработку ответов и аутентификацию. В Python 3 эта функциональность была перераспределена и интегрирована в несколько отдельных подмодулей в рамках urllib.
Основное отличие заключается в том, что в Python 3 нет прямого аналога urllib2. Вместо этого, для выполнения задач, ранее решаемых с использованием urllib2, используются модули, такие как:
- urllib.request – для выполнения HTTP-запросов, отправки данных и обработки ответов.
- urllib.error – для обработки ошибок, возникающих при работе с urllib.request.
- urllib.parse – для парсинга URL-адресов и их компонентов.
- urllib.robotparser – для работы с файлами robots.txt.
Кроме того, в Python 3 был улучшен механизм аутентификации. В urllib.request теперь доступна удобная работа с аутентификацией через класс HTTPBasicAuthHandler и другие обработчики.
Стоит отметить, что в Python 3 из-за новой структуры модуля urllib было улучшено разделение обязанностей и повысилась читаемость кода. Если в Python 2 для выполнения большинства задач использовался один модуль urllib2, то в Python 3 каждый модуль отвечает за отдельный аспект работы с URL.
Таким образом, если вы переходите на Python 3, вам не нужно искать модуль urllib2, вместо него нужно использовать соответствующие подмодули urllib.request, urllib.error и urllib.parse.
Как использовать urllib вместо urllib2 в Python 3?
В Python 3 библиотека urllib заменяет функциональность, предоставляемую urllib2 в Python 2. Основные изменения касаются разделения пакетов на несколько модулей. В частности, код, использующий urllib2 в Python 2, в Python 3 будет работать через модуль urllib, но с некоторыми отличиями в синтаксисе и структуре.
Основные моменты, на которые стоит обратить внимание при переходе с urllib2 на urllib в Python 3:
1. В Python 3 не существует отдельного модуля urllib2. Все его функции были перераспределены по различным подмодулям urllib:
urllib.request– для работы с HTTP-запросами, аналогично функции urllib2.urllib.error– для обработки ошибок, связанных с запросами.urllib.parse– для разбора URL и кодирования параметров.urllib.robotparser– для анализа robots.txt.
2. В Python 3 для отправки HTTP-запросов используется urllib.request вместо urllib2.urlopen. Например, чтобы выполнить GET-запрос:
import urllib.request
response = urllib.request.urlopen('http://example.com')
html = response.read().decode('utf-8')
3. Для отправки POST-запросов, необходимо использовать urllib.request.Request с указанием метода:
import urllib.request
import urllib.parse
data = urllib.parse.urlencode({'key': 'value'}).encode()
req = urllib.request.Request('http://example.com', data=data, headers={'User-Agent': 'Mozilla/5.0'})
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
4. Для работы с заголовками, как в urllib2, можно использовать параметр headers в запросах. Это позволяет задавать необходимые HTTP-заголовки при отправке запросов, например, для имитации работы браузера.
5. Обработка ошибок осуществляется через модули urllib.error и try-except блоки:
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://example.com')
except urllib.error.HTTPError as e:
print('HTTP error:', e.code)
except urllib.error.URLError as e:
print('URL error:', e.reason)
else:
html = response.read().decode('utf-8')
Используя эти подходы, вы сможете адаптировать код с использованием urllib2 для Python 3 с минимальными изменениями.
Какие альтернативы существуют для urllib2 в Python 3?
В Python 3 модуль urllib2 был заменён на несколько других компонентов, которые выполняют схожие функции, но с улучшениями и более гибкой архитектурой. Рассмотрим основные альтернативы.
urllib.request– это прямой аналогurllib2в Python 3, предоставляющий возможности для работы с HTTP-запросами. Он включает функции для отправки GET, POST запросов, обработки ответов и работы с заголовками. Использование этого модуля не требует дополнительных установок, так как он является частью стандартной библиотеки.requests– сторонняя библиотека, популярная благодаря простоте и удобству в использовании. Она поддерживает работу с HTTP-запросами, управлением сессиями, аутентификацией, обработкой ошибок и множеством других функций.requestsстановится выбором для большинства разработчиков, так как делает код чище и проще.http.client– это более низкоуровневая альтернатива для работы с HTTP-запросами. Модуль предоставляет доступ к более детализированному управлению запросами, включая возможность настроить соединения вручную, обрабатывать ответы и работать с кодами состояния.http.clientрекомендуется использовать в случаях, когда требуется высокая гибкость, но он требует больше усилий для настройки и работы.aiohttp– библиотека для асинхронной работы с HTTP. Она позволяет отправлять запросы и получать ответы асинхронно, что полезно при выполнении большого количества параллельных запросов. В случае работы с большим количеством сетевых операций, использованиеaiohttpзначительно ускоряет процесс благодаря асинхронной обработке.httplib2– сторонняя библиотека, которая поддерживает как синхронные, так и асинхронные запросы. Она также позволяет работать с HTTP-заголовками, сессиями и авторизацией.httplib2не так популярна, какrequests, но остаётся полезной в определённых случаях, особенно когда нужно работать с прокси или куки.
Выбор между этими библиотеками зависит от конкретных задач. Для большинства случаев urllib.request или requests будут наиболее удобными и функциональными. Если же требуется высокопроизводительная работа с большим количеством запросов, стоит обратить внимание на aiohttp.
Как установить библиотеку urllib в Python 3?
В Python 3 библиотека urllib уже встроена в стандартную библиотеку, и её не нужно устанавливать дополнительно через pip или другие инструменты. Однако, важно понимать, что в Python 3 она была переработана и разделена на несколько модулей: urllib.request, urllib.parse, urllib.error, urllib.robotparser.
Если вам необходимо использовать возможности работы с HTTP-запросами или парсинг URL-адресов, вам нужно импортировать соответствующие части библиотеки. Например:
import urllib.request import urllib.parse
Если вы хотите работать с запросами, например, отправлять HTTP-запросы, вам следует использовать urllib.request:
response = urllib.request.urlopen('http://example.com')
html = response.read()
Для работы с URL-адресами, такими как парсинг и манипуляции с параметрами, используйте urllib.parse:
parsed_url = urllib.parse.urlparse('http://example.com/path?query=1')
Таким образом, для работы с urllib в Python 3 не нужно никаких дополнительных шагов по установке, достаточно правильно импортировать нужные модули в вашем проекте. Также стоит помнить, что Python 3 имеет более строгие требования к кодировкам, и при работе с urllib важно учитывать это, особенно при отправке и получении данных.
Какие модули входят в состав библиотеки urllib в Python 3?
Библиотека urllib в Python 3 состоит из нескольких подмодулей, каждый из которых выполняет определенные задачи для работы с HTTP-запросами и адресами. Основные модули включают:
- urllib.request – предназначен для работы с HTTP-запросами. Этот модуль позволяет отправлять запросы, получать ответы и работать с URL-адресами. Также в нем есть инструменты для работы с аутентификацией и параметрами запросов.
- urllib.error – содержит исключения, которые могут быть выброшены при работе с запросами, например,
URLErrorиHTTPError. Эти исключения полезны для обработки ошибок при сетевых запросах. - urllib.parse – модуль для парсинга URL. Он включает функции для разборки URL-адресов на составляющие (схема, хост, путь и т.д.), а также для их корректной сборки. Полезен при работе с параметрами URL, например, для кодирования данных в строку запроса.
- urllib.response – используется для обработки ответов HTTP-запросов. Включает в себя классы, такие как
addinfourl, который предоставляет информацию о ответе, например, заголовки ответа. - urllib.robotparser – модуль для работы с файлами
robots.txt. Он позволяет парсить эти файлы и определять, разрешено ли определенным агентам обращаться к конкретным частям сайта.
Эти модули можно комбинировать для выполнения различных задач, связанных с сетевыми запросами и обработкой URL, что делает библиотеку urllib мощным инструментом для работы с интернет-ресурсами в Python 3.
Как настроить прокси-сервер с использованием urllib в Python 3?
Для настройки прокси-сервера с использованием библиотеки urllib в Python 3, необходимо использовать модуль urllib.request, который предоставляет инструменты для работы с HTTP-запросами. Прокси-серверы могут быть полезны для анонимного серфинга, обхода блокировок или управления сетевыми запросами.
Прежде чем настроить прокси, следует определиться с типом прокси-сервера (HTTP, HTTPS, SOCKS) и его параметрами (адрес, порт, имя пользователя, пароль). В Python 3 это делается через словарь с конфигурацией прокси-сервера, который затем передается в urllib.request.ProxyHandler.
Пример кода для использования прокси-сервера в urllib:
import urllib.request
# Определение прокси-серверов
proxies = {
"http": "http://user:password@proxy_address:proxy_port",
"https": "https://user:password@proxy_address:proxy_port"
}
# Создание прокси-обработчика
proxy_handler = urllib.request.ProxyHandler(proxies)
# Создание opener с прокси
opener = urllib.request.build_opener(proxy_handler)
# Установка opener как глобального для всех запросов
urllib.request.install_opener(opener)
# Пример запроса через прокси
url = "http://example.com"
response = urllib.request.urlopen(url)
print(response.read().decode('utf-8'))
В этом примере создается обработчик прокси, который настраивает использование прокси-серверов для HTTP и HTTPS запросов. Затем создается объект opener, который используется для выполнения запросов через указанные прокси. Важно, что метод install_opener делает прокси доступным для всех последующих HTTP-запросов в программе.
Если прокси не требует аутентификации, можно опустить часть с именем пользователя и паролем. Для работы с SOCKS-прокси можно использовать библиотеку PySocks, которая интегрируется с urllib для поддержки SOCKS-прокси.
Обратите внимание, что при работе с прокси важно корректно обрабатывать ошибки соединения, так как проблемы с прокси могут вызвать сбои в работе программы. Рекомендуется использовать обработчики исключений для предсказуемой обработки ошибок.
Как обрабатывать ошибки при использовании urllib в Python 3?
При работе с urllib в Python 3 важно учитывать возможные ошибки, которые могут возникнуть во время выполнения запросов. Для эффективной обработки ошибок необходимо использовать исключения, которые предоставляет библиотека. Рассмотрим основные виды ошибок и способы их обработки.
1. Ошибки сети и подключения
Для работы с сетевыми ресурсами могут возникать ошибки подключения, такие как проблемы с доступом к серверу или неправильный URL. Эти ошибки генерируются как исключения типа urllib.error.URLError. Чтобы корректно их обработать, используйте блок try-except:
from urllib import request, error
try:
response = request.urlopen('https://example.com')
except error.URLError as e:
print(f"Ошибка подключения: {e.reason}")
В переменной e.reason хранится подробное описание причины ошибки, например, если сервер недоступен.
2. Ошибки HTTP
В случае, если сервер возвращает ошибку HTTP (например, 404 или 500), это вызывает исключение urllib.error.HTTPError. Это исключение имеет атрибуты, которые позволяют получить код ошибки и описание:
from urllib import request, error
try:
response = request.urlopen('https://example.com/nonexistent')
except error.HTTPError as e:
print(f"HTTP ошибка: {e.code} - {e.reason}")
Здесь e.code вернет код статуса HTTP, а e.reason – пояснение к ошибке. Это позволяет точно определить, что пошло не так.
3. Обработка ошибок для различных типов запросов
В зависимости от типа запроса (GET, POST и т.д.) могут возникать разные ошибки. При работе с методами, такими как urlopen или urlretrieve, рекомендуется всегда обрабатывать ошибки, связанные с нарушением сетевых протоколов. Используйте точные исключения для каждой ситуации, чтобы минимизировать ошибки и упростить отладку.
4. Ожидание и повторные попытки
Если ошибка вызвана временным сбой в сети или сервере, можно реализовать повторные попытки запроса с задержкой. В этом случае применяют конструкцию с циклом и использованием time.sleep() для паузы между попытками:
import time
from urllib import request, error
url = 'https://example.com'
max_retries = 3
for attempt in range(max_retries):
try:
response = request.urlopen(url)
break
except error.URLError as e:
print(f"Попытка {attempt + 1} не удалась: {e.reason}")
if attempt < max_retries - 1:
time.sleep(2)
Такой подход помогает повысить устойчивость программы в случае временных ошибок.
5. Логирование ошибок
Для диагностики и дальнейшего анализа полезно записывать все ошибки в лог. Используйте встроенный модуль logging для ведения журнала ошибок:
import logging
from urllib import request, error
logging.basicConfig(filename='app.log', level=logging.ERROR)
try:
response = request.urlopen('https://example.com')
except error.URLError as e:
logging.error(f"Ошибка при подключении: {e.reason}")
Логирование помогает отслеживать ошибки и анализировать их в будущем.
Эти методы позволяют эффективно справляться с ошибками при использовании urllib в Python 3 и минимизировать влияние непредвиденных ситуаций на выполнение программы.
Вопрос-ответ:
Что такое urllib2 и почему я не могу использовать его в Python 3?
В Python 2 библиотека `urllib2` использовалась для работы с HTTP-запросами, но в Python 3 она была переработана и разделена на несколько отдельных модулей, таких как `urllib.request`, `urllib.error`, и другие. Если вы пытаетесь использовать `urllib2` в Python 3, вам нужно будет адаптировать код под новые модули, так как `urllib2` больше не существует в Python 3.
Каким образом можно заменить `urllib2` на `urllib` в Python 3?
В Python 3 вам нужно использовать модуль `urllib.request` для отправки HTTP-запросов, который выполняет те же функции, что и `urllib2` в Python 2. Например, вместо `urllib2.urlopen()` используйте `urllib.request.urlopen()`. Если вам нужно обработать ошибки, вы также можете использовать `urllib.error` для перехвата исключений, таких как `URLError` или `HTTPError`.
Могу ли я использовать старый код с `urllib2` в Python 3, и что для этого нужно сделать?
Для того чтобы использовать старый код, написанный с `urllib2` в Python 3, вам нужно будет переписать его с учётом новых модулей, так как `urllib2` в Python 3 не существует. Например, замените `urllib2.urlopen()` на `urllib.request.urlopen()`. Код для работы с заголовками, методами запросов и обработкой ошибок также потребует изменений. Это означает, что вам нужно будет использовать другие модули, такие как `urllib.request` для запросов и `urllib.error` для обработки исключений.
Что делать, если мне нужно работать с HTTP-запросами в Python 3 и я не хочу переписывать код с использованием urllib?
Если вам не хочется переписывать код с использованием модуля `urllib`, вы можете рассмотреть использование более высокого уровня библиотек, таких как `requests`. Эта библиотека предоставляет удобный интерфейс для работы с HTTP-запросами, и она полностью совместима с Python 3. Для установки `requests` используйте команду `pip install requests`. Это упростит работу с HTTP-запросами, так как `requests` обрабатывает многие моменты автоматически, такие как обработка ошибок и установка заголовков.