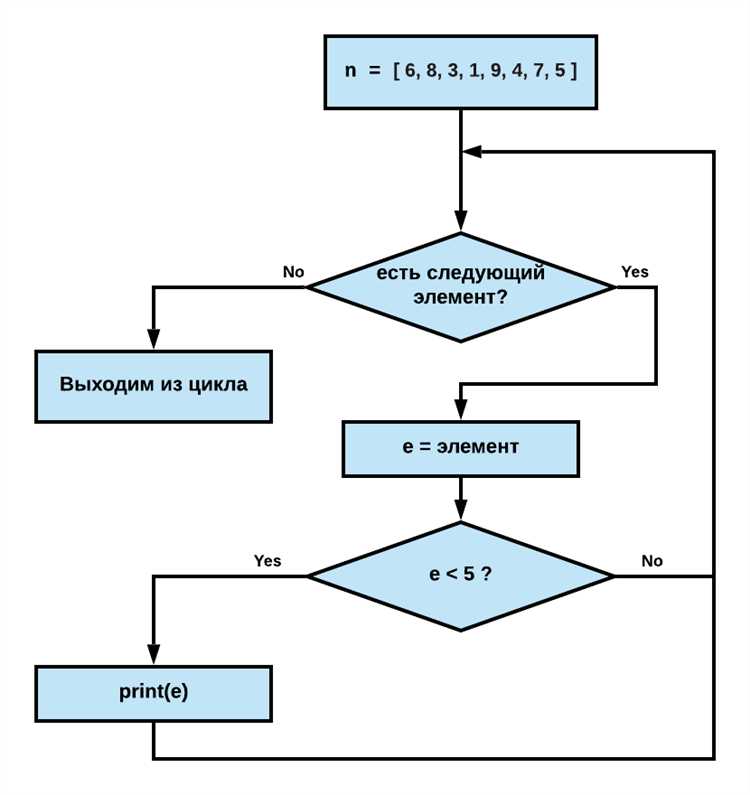
Циклы – это один из основополагающих инструментов Python, позволяющий автоматизировать повторяющиеся задачи. В языке Python доступны два типа циклов: for и while, каждый из которых имеет свои особенности и области применения. Циклы позволяют эффективно обрабатывать большие объемы данных, автоматизировать рутинные операции и значительно сокращать объем кода. Вместо того чтобы писать однотипные команды вручную, циклы позволяют выполнять их многократно, что делает код более компактным и читаемым.
Для задач автоматизации, таких как обработка файлов, выполнение операций над элементами списка или взаимодействие с API, циклы являются незаменимым инструментом. Например, цикл for используется для итерации по элементам коллекций, таких как списки и множества, что позволяет обрабатывать данные по одному за раз. В то время как цикл while идеально подходит для выполнения операций до тех пор, пока не выполнится определённое условие, что важно при работе с динамическими процессами, такими как мониторинг состояний или обработка потоков данных.
Использование циклов эффективно не только для небольших проектов, но и для масштабных автоматизированных систем, где каждый цикл может быть настроен для выполнения множества различных задач. К примеру, с помощью циклов можно создавать системы резервного копирования, автоматизировать работу с базами данных или реализовывать сложные алгоритмы обработки текстовых файлов. Важно отметить, что грамотное использование циклов не только ускоряет процесс разработки, но и значительно улучшает производительность программы за счёт минимизации повторяющегося кода и упрощения его поддержки.
Как организовать обработку данных с помощью цикла for

Цикл for в Python широко используется для автоматизации обработки данных, когда нужно выполнить одинаковые операции над элементами коллекции (списка, строки, множества и других). Он позволяет эффективно и лаконично обрабатывать данные без необходимости использования дополнительных конструкций, таких как индексы или условия.
data = [1, 2, 3, 4, 5]
for item in data:
print(item)
Если задача состоит в применении функции к каждому элементу, например, умножить все числа в списке на 2, то цикл for будет выглядеть так:
data = [1, 2, 3, 4, 5]
for i in range(len(data)):
data[i] = data[i] * 2
print(data)
Для сложных коллекций, например, словарей, цикл for можно использовать для итерации по ключам или значениям. Например, чтобы вывести все ключи и значения из словаря:
data = {'a': 1, 'b': 2, 'c': 3}
for key, value in data.items():
print(key, value)
Это полезно, когда нужно выполнить операцию с обеими составляющими словаря, например, подсчитать суммы или преобразовать данные.
Циклы for могут быть также вложенными, что позволяет обрабатывать многомерные структуры данных. Например, для обработки списка списков, где каждый вложенный список содержит числа, можно использовать следующий подход:
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
for sublist in data:
for item in sublist:
print(item)
Важной особенностью цикла for является использование генераторов, которые позволяют создавать новые коллекции, изменяя данные на лету. Например, для создания нового списка, содержащего квадраты чисел из исходного списка, можно применить генератор списка:
data = [1, 2, 3, 4, 5]
squares = [x ** 2 for x in data]
print(squares)
Генераторы позволяют эффективно работать с большими объемами данных, не требуя значительных затрат памяти.
Цикл for также полезен при фильтрации данных. Например, если необходимо выбрать только те элементы из списка, которые удовлетворяют определенному условию:
data = [1, 2, 3, 4, 5]
even_numbers = [x for x in data if x % 2 == 0]
print(even_numbers)
Этот подход позволяет легко и быстро отфильтровывать данные без написания дополнительных функций.
Использование цикла for в обработке данных позволяет существенно повысить производительность и уменьшить количество строк кода. Это особенно полезно в задачах автоматизации, где требуется повторить однотипные операции на множестве данных, делая код читаемым и эффективным.
Автоматизация повторяющихся задач с использованием цикла while

Цикл while в Python позволяет эффективно автоматизировать задачи, которые требуют выполнения до тех пор, пока не будет выполнено определенное условие. Это особенно полезно, когда количество повторений заранее неизвестно и зависит от изменения состояния программы.
Основная структура цикла while выглядит так:
while условие:
действияЦикл продолжает выполняться, пока условие остается истинным. Рассмотрим несколько примеров, где использование while эффективно для автоматизации задач.
1. Повторение операции до достижения цели
Один из типичных случаев – выполнение операции, пока не будет достигнут заданный результат. Например, автоматизация повторных попыток подключения к серверу, если первое подключение не удалось.
import time
# Пример автоматического подключения к серверу
attempts = 0
connected = False
while not connected and attempts < 5:
try:
# попытка подключения
connected = try_connect_to_server()
except ConnectionError:
attempts += 1
time.sleep(2) # пауза перед следующей попыткой
Здесь цикл будет пытаться подключиться к серверу до тех пор, пока не будет установлено соединение или не исчерпаются все попытки.
2. Автоматизация процессов с непредсказуемым числом повторений
Когда количество повторений заранее неизвестно, цикл while позволяет решить задачу динамически. Например, обработка данных до тех пор, пока не встретится специальный маркер (например, пустая строка).
data = ["apple", "banana", "cherry", ""]
index = 0
while data[index] != "":
process(data[index])
index += 1
Этот код будет обрабатывать элементы списка до тех пор, пока не встретит пустую строку, что позволяет гибко адаптировать обработку данных под разные условия.
3. Преимущества цикла while в автоматизации
- Гибкость. Цикл
whileможет быть использован для задач, где количество повторений зависит от непредсказуемых факторов (например, получение данных с сервера). - Простота. Синтаксис цикла
whileпроще для понимания в случаях, когда условие окончания выполнения не привязано к счетчику. - Интерактивность. Он позволяет адаптироваться к состоянию программы в процессе её работы, что дает возможность динамически изменять поведение.
4. Потенциальные проблемы и как их избежать
При использовании while важно следить за тем, чтобы условие выхода из цикла было корректно прописано. В противном случае можно столкнуться с бесконечным циклом, который заблокирует выполнение программы.
- Проверка условия выхода. Убедитесь, что условие выхода может быть достигнуто при определенных обстоятельствах.
- Избежание бесконечного цикла. Всегда включайте логику для отслеживания прогресса (например, счетчики или таймеры), чтобы избежать бесконечных итераций.
5. Реальные примеры использования
- Автоматическая обработка файлов: Чтение и обработка файлов в цикле до тех пор, пока не будут обработаны все строки или пока не будет достигнут конец файла.
- Автоматическое тестирование: Запуск тестов в цикле до тех пор, пока все тесты не будут успешными или пока не исчерпаются все тестовые сценарии.
- Мониторинг состояния: Цикл для регулярной проверки состояния системы или ресурса (например, мониторинг серверных логов).
Использование циклов для работы с файлами и директориями
Циклы в Python позволяют автоматизировать обработку множества файлов и директорий, что полезно при работе с большими объемами данных. Для этих целей часто используют модули os и glob, которые предоставляют функции для взаимодействия с файловой системой.
С помощью цикла for можно перебирать файлы в указанной директории. Например, для получения списка всех файлов в папке можно использовать функцию os.listdir(). Для фильтрации файлов по расширению применяют условие внутри цикла:
import os
path = 'путь_к_директории'
for filename in os.listdir(path):
if filename.endswith('.txt'):
print(filename)
Этот код найдет все текстовые файлы в указанной директории. Важно помнить, что os.listdir() возвращает все файлы и папки, включая скрытые, поэтому для точной работы с файлами можно дополнительно проверять их тип с помощью os.path.isfile().
Для более сложных задач, таких как рекурсивный поиск файлов в подкаталогах, можно использовать os.walk(). Этот метод возвращает генератор, который поочередно выдает кортежи, содержащие путь, подкаталоги и файлы. Пример использования:
for root, dirs, files in os.walk('путь_к_директории'):
for file in files:
if file.endswith('.log'):
print(os.path.join(root, file))
Этот код рекурсивно ищет все файлы с расширением .log во всех подкаталогах. Такой подход значительно упрощает обработку данных в сложных файловых структурах.
Для удобной работы с файлами, например, при выполнении операций с именами или содержимым, можно использовать модуль glob, который поддерживает использование шаблонов. Это полезно, когда нужно работать с файлами, соответствующими определенным паттернам. Пример использования:
import glob
for file in glob.glob('путь_к_директории/*.csv'):
print(file)
В этом примере с помощью шаблона *.csv выбираются все CSV-файлы в указанной папке. glob предоставляет более гибкие возможности для фильтрации файлов по шаблону, включая поддержку регулярных выражений.
Важным моментом при работе с файлами в цикле является корректная обработка ошибок, связанных с отсутствием прав на чтение или запись. Использование блока try-except помогает избежать сбоев программы при таких ситуациях. Пример:
for file in os.listdir(path):
try:
with open(os.path.join(path, file), 'r') as f:
print(f.read())
except PermissionError:
print(f'Нет доступа к файлу {file}')
Как применять циклы для сбора и обработки данных из API
Циклы – мощный инструмент для автоматизации процессов работы с API, особенно когда необходимо обрабатывать большие объемы данных. В большинстве случаев API предоставляет информацию постранично или пакетами, и циклы позволяют эффективно собирать, обрабатывать и сохранять данные без излишней загрузки памяти.
Основная задача при работе с API – это правильная организация запросов и обработка ответов. Рассмотрим пример использования цикла для сбора и обработки данных через API на Python.
Основные шаги
- Получение данных из API: API часто возвращает данные в виде JSON-объектов. Для взаимодействия с API можно использовать библиотеку
requests. - Обработка данных: Для работы с полученными данными используем циклы, которые помогут перебрать все страницы или элементы в ответах API.
- Запись данных: После обработки данных можно сохранить результаты в файлы или базу данных для дальнейшего анализа.
Пример использования цикла для сбора данных

Предположим, что необходимо получить информацию о списке пользователей с API, который возвращает по 50 пользователей на страницу. Чтобы собрать данные с нескольких страниц, можно использовать цикл:
import requests
url = "https://api.example.com/users"
params = {"page": 1, "per_page": 50}
users = []
while True:
response = requests.get(url, params=params)
data = response.json()
if not data:
break
users.extend(data)
params["page"] += 1
print(f"Всего пользователей: {len(users)}")
В данном примере цикл продолжает выполнять запросы, пока API не вернет пустой список данных. Каждую страницу данных мы добавляем в список users.
Советы по эффективному использованию циклов
- Обработка ошибок: Всегда обрабатывайте ошибки, чтобы избежать сбоев в случае, если API временно недоступно. Используйте конструкцию
try-exceptдля перехвата исключений. - Ограничения по частоте запросов: Многие API ограничивают количество запросов в единицу времени. Убедитесь, что вы соблюдаете эти ограничения, чтобы избежать блокировки. Добавляйте задержки между запросами с помощью
time.sleep(). - Параллельная обработка: Если API поддерживает многозадачность, можно использовать
asyncioили библиотеки типаconcurrent.futuresдля параллельного выполнения запросов и ускорения обработки.
Пример обработки ошибок и задержки
import requests
import time
url = "https://api.example.com/data"
params = {"page": 1}
data = []
while True:
try:
response = requests.get(url, params=params)
response.raise_for_status()
page_data = response.json()
if not page_data:
break
data.extend(page_data)
params["page"] += 1
time.sleep(1) # Задержка между запросами
except requests.exceptions.RequestException as e:
print(f"Ошибка запроса: {e}")
break
print(f"Собрано данных: {len(data)}")
Этот код учитывает возможные ошибки и добавляет паузу между запросами, чтобы снизить нагрузку на сервер и избежать блокировки за частые запросы.
Заключение
Циклы позволяют эффективно собирать и обрабатывать большие объемы данных из API, минимизируя риски сбоев и перегрузки системы. Использование циклов в сочетании с обработкой ошибок и учетом ограничений API помогает автоматизировать задачи и получать данные без излишних затрат времени и ресурсов.
Обработка ошибок при работе с циклами в автоматизации
Простой пример использования цикла с обработкой ошибок:
for i in range(10):
try:
result = 10 / i
except ZeroDivisionError:
print(f"Ошибка деления на ноль при i = {i}")
except Exception as e:
print(f"Неизвестная ошибка: {e}")
Когда данные, с которыми работает цикл, могут быть невалидными (например, значения из внешних источников), полезно использовать дополнительные проверки. Пример:
for item in data_list:
if isinstance(item, int):
print(item ** 2)
else:
print(f"Невалидный элемент: {item}")
Если список data_list может содержать как числа, так и другие типы данных, важно исключить их заранее, чтобы избежать ошибок. Включение таких проверок уменьшает вероятность возникновения исключений и улучшает качество автоматизации.
В некоторых случаях работа с сетевыми ресурсами может вызывать ошибки, такие как потеря соединения или тайм-аут. В этих ситуациях полезно использовать блоки try...except в сочетании с повторными попытками, например:
import time
for attempt in range(3):
try:
response = requests.get("https://example.com")
break
except requests.exceptions.RequestException as e:
print(f"Ошибка запроса: {e}")
if attempt < 2:
time.sleep(2)
else:
print("Не удалось выполнить запрос после 3 попыток.")
Этот код пытается выполнить HTTP-запрос до трех раз, с паузой между попытками. Такой подход гарантирует, что в случае временных проблем с сетью процесс не завершится аварийно.
Кроме того, стоит помнить о важности логирования ошибок. Регистрация каждой ошибки с указанием контекста помогает анализировать причины сбоя и оптимизировать работу системы. Логи должны содержать не только текст ошибки, но и дополнительную информацию, такую как значения переменных и шаги выполнения программы.
Наконец, важно выделить ситуацию, когда цикл не должен продолжаться после возникновения ошибки. В таких случаях можно использовать конструкцию raise, чтобы пробросить исключение и завершить выполнение программы:
for item in data_list:
if not valid(item):
raise ValueError(f"Невалидный элемент: {item}")
process(item)
Этот подход помогает быстрее выявить ошибки в данных и предотвратить дальнейшую обработку некорректной информации.
Оптимизация циклов для больших объемов данных
При обработке больших объемов данных в Python важную роль играет эффективность работы с циклами. Несколько ключевых техник позволяют значительно ускорить выполнение кода, минимизируя время обработки и использование памяти.
1. Использование генераторов вместо списков
Генераторы позволяют обходиться без создания промежуточных списков в памяти, что особенно важно при работе с большими объемами данных. Вместо того, чтобы формировать полный список данных, генераторы создают элементы по мере их запроса. Это снижает нагрузку на память и увеличивает скорость обработки.
Пример:
# Список (занимает больше памяти) squares = [x*x for x in range(1000000)] # Генератор (эффективнее по памяти) squares = (x*x for x in range(1000000))
2. Использование встроенных функций и библиотек
Множество стандартных функций Python оптимизировано для работы с большими объемами данных. Функции, такие как map(), filter() и reduce(), часто работают быстрее, чем циклы for благодаря внутренним оптимизациям и использованию C-библиотек.
Пример:
# Вместо цикла for лучше использовать map data = list(map(lambda x: x * 2, range(1000000)))
3. Использование многозадачности и параллельных вычислений
Для ускорения обработки больших объемов данных можно использовать параллельные вычисления с помощью библиотеки concurrent.futures или multiprocessing. Разделение работы на несколько потоков или процессов позволяет значительно снизить время выполнения, особенно при наличии нескольких ядер процессора.
Пример:
from concurrent.futures import ThreadPoolExecutor def process_item(item): return item * 2 with ThreadPoolExecutor() as executor: results = list(executor.map(process_item, range(1000000)))
4. Оптимизация алгоритмов и логики
Скорость работы циклов напрямую зависит от алгоритма. Важно использовать наиболее эффективные алгоритмы для конкретной задачи. Например, при работе с большими данными вместо линейного поиска можно применить двоичный поиск или хеширование, что снизит время работы с O(n) до O(log n) или O(1).
5. Векторизация с использованием NumPy
Если данные можно представить в виде массива, рекомендуется использовать библиотеку NumPy. Она позволяет работать с массивами данных более эффективно, используя оптимизированные C-библиотеки. Вместо циклов for можно применять операции над массивами, что существенно ускоряет вычисления.
Пример:
import numpy as np data = np.arange(1000000) squared_data = data ** 2
6. Оптимизация с помощью JIT-компиляции
Использование Just-in-Time компиляции (JIT) может существенно ускорить выполнение циклов. Библиотека Numba позволяет добавлять JIT-компиляцию к функциям Python, улучшая их производительность при выполнении на больших данных.
Пример:
from numba import jit @jit def process_data(data): return [x * 2 for x in data] data = range(1000000) result = process_data(data)
7. Использование кэширования
При повторяющихся вычислениях можно использовать кэширование с помощью библиотеки functools.lru_cache. Это позволяет избежать повторных вычислений для тех же входных данных, что значительно ускоряет обработку.
Пример:
from functools import lru_cache @lru_cache(maxsize=None) def expensive_function(x): return x * x result = expensive_function(100)
Применяя эти методы, можно значительно улучшить производительность при работе с большими объемами данных, минимизируя потребление ресурсов и время обработки.
Вопрос-ответ:
Что такое цикл в Python и как он используется для автоматизации задач?
Цикл в Python — это конструкция, которая позволяет многократно выполнять блок кода до тех пор, пока выполняется определённое условие. Для автоматизации задач циклы полезны, например, при необходимости обработки больших объёмов данных, повторяющихся операций или выполнения одинаковых действий с несколькими объектами. Например, можно использовать цикл для автоматического обхода файлов в папке или для вычисления сумм по списку чисел.
Какие типы циклов существуют в Python и чем они отличаются?
В Python существуют два основных типа циклов: цикл for и цикл while. Цикл for используется для итерации по объектам (например, по элементам списка или строкам), а цикл while продолжает выполнение до тех пор, пока заданное условие остаётся истинным. Основное различие между ними заключается в том, что for заранее знает количество итераций, а while продолжает работать, пока не выполнится условие.
Как избежать бесконечного цикла в Python при автоматизации?
Бесконечные циклы могут возникать, если условие выхода из цикла никогда не становится ложным. Чтобы избежать этого, важно правильно настроить условие выхода и внимательно проверять логику программы. Например, если в цикле используется переменная, которая должна изменяться, необходимо убедиться, что она будет изменяться должным образом, чтобы условие цикла стало ложным и он завершился. Для дополнительной безопасности можно использовать команду break, чтобы принудительно выйти из цикла, если произошло что-то непредвиденное.