В Python встроенные структуры данных представляют собой ключевые элементы для хранения и обработки информации в программах. Они обеспечивают эффективное взаимодействие с данными и позволяют решать широкий спектр задач. Среди самых популярных – списки, кортежи, множества и словарь. Каждая из этих структур имеет свои особенности и применяется в зависимости от конкретной задачи.
Списки в Python являются динамическими массивами. Их основное преимущество – возможность изменять размер в процессе выполнения программы. Однако их время работы для операций вставки и удаления элементов может быть медленным, если это происходит в середине списка. Для более быстрой работы с данными, когда важна именно скорость поиска, лучше использовать множества, которые гарантируют постоянное время доступа к элементам, но не позволяют хранить дубликаты.
Кортежи, с другой стороны, являются неизменяемыми структурами данных. Они экономят память и часто используются для хранения констант или группировки данных, которые не должны изменяться. Если важно гарантировать неизменность, то кортежи – это идеальный выбор. Словарь же представляет собой структуру, которая хранит пары ключ-значение, и является одной из самых гибких для поиска и сопоставления данных. Однако операции с большими словарями могут требовать значительных ресурсов, особенно при работе с большими объемами информации.
Как выбрать между списком и кортежем для хранения данных?
При выборе между списком и кортежем необходимо учитывать несколько ключевых аспектов: изменяемость, производительность и семантика данных. Оба типа данных позволяют хранить элементы в определённом порядке, но их поведение и оптимизация различаются.
Список (list) является изменяемым объектом, что означает возможность добавления, удаления и изменения элементов в процессе выполнения программы. Это делает список гибким инструментом, подходящим для динамичных коллекций данных, где структура может изменяться. Например, если в программе требуется изменять размер коллекции, добавлять новые элементы или изменять существующие, то список будет оптимальным выбором.
Кортеж (tuple), в отличие от списка, является неизменяемым. Это свойство делает его более эффективным с точки зрения памяти и скорости обработки, особенно когда количество операций с данными минимально. Кортежи могут использоваться, когда необходимо гарантировать, что данные не будут изменяться в ходе работы программы, например, для хранения координат, параметров или постоянных значений.
Производительность также играет значительную роль при выборе между этими типами. Кортежи в среднем занимают меньше памяти и быстрее обрабатываются при доступе к элементам по сравнению с списками. Если доступ к данным осуществляется часто и необходимо минимизировать накладные расходы, кортеж может оказаться более подходящим выбором. Однако при необходимости изменять данные это преимущество исчезает.
Кроме того, кортежи могут быть использованы как ключи в словарях, в отличие от списков, что делает их незаменимыми для реализации некоторых алгоритмов или структур данных. Это свойство объясняется тем, что кортежи, будучи неизменяемыми, являются хешируемыми объектами, тогда как списки – нет.
Резюмируя, выбор между списком и кортежем зависит от требований к данным. Если нужно работать с изменяющимися данными – выбирайте список. Если данные должны оставаться неизменными и требуется повышенная производительность, используйте кортеж.
Какие преимущества и ограничения у множества (set) в Python?
Множество (set) в Python представляет собой неупорядоченную коллекцию уникальных элементов. Его отличительные особенности делают структуру данных полезной в ряде задач, однако есть и ограничения, о которых важно знать при использовании.
Преимущества:
1. Уникальность элементов: Множество не допускает дублирования значений. При добавлении элемента, который уже существует в множестве, его повторно не добавляют, что исключает необходимость вручную проверять уникальность значений.
2. Быстрый поиск: Операции поиска, удаления и добавления элемента в множество имеют в среднем время выполнения O(1), что делает множество эффективным при работе с большими объемами данных.
3. Операции с множествами: Python предоставляет несколько встроенных операций для работы с множествами, таких как объединение, пересечение, разность и симметрическая разность, что позволяет легко и быстро манипулировать данными.
4. Множество как фильтр: Благодаря своей природе множества эффективно используют для удаления дубликатов из других коллекций, таких как списки или кортежи.
Ограничения:
1. Неупорядоченность: Множество не сохраняет порядок элементов. Это ограничивает возможности индексации, а также сложнее в случае, когда требуется работать с элементами в определенной последовательности.
2. Отсутствие дублирующихся значений: Хотя это и преимущество в большинстве случаев, в некоторых ситуациях необходимость хранения одинаковых значений может стать ограничением, так как множество не поддерживает их повторное добавление.
3. Невозможность использования изменяемых типов данных: Множество в Python не может содержать изменяемые объекты, такие как списки или другие множества, поскольку такие объекты не являются хешируемыми и не могут быть ключами для хеш-таблицы, которая используется для реализации множества.
4. Использование памяти: Из-за реализации на основе хеш-таблиц множества могут занимать больше памяти, чем другие коллекции, такие как списки или кортежи, особенно при большом количестве элементов.
В целом, множество в Python идеально подходит для ситуаций, где важно поддержание уникальности элементов, быстродействие операций и работа с множественными операциями, однако оно имеет свои ограничения, которые необходимо учитывать при выборе структуры данных для задачи.
Когда стоит использовать словарь (dict) для хранения пар «ключ-значение»?
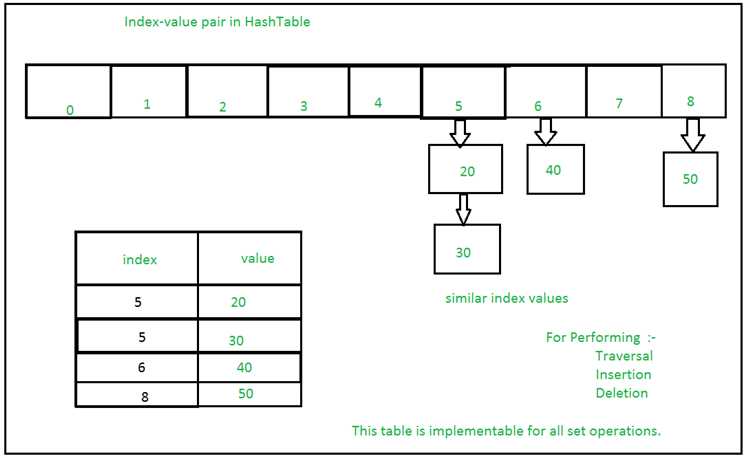
Если данные требуют ассоциативной связи, например, когда нужно хранить информацию о пользователях по их ID или накапливать статистику по категориям, словарь станет оптимальным выбором. В таких случаях важно, чтобы каждый элемент имел уникальный идентификатор, а поиск по этому ключу был быстрым. Например, если необходимо хранить информацию о пользователях по email, где email – это уникальный ключ, словарь обеспечит быстрый доступ к данным по каждому адресу.
Другим примером использования является хранение настроек приложения, где каждая настройка имеет уникальное имя (ключ) и ассоциированное с ним значение. Например, можно использовать словарь для хранения параметров конфигурации веб-сервера, где каждый параметр – это строка, а его значение – числовое или строковое значение.
Также словари удобны для реализации различных алгоритмов, где требуется связать элементы с уникальными идентификаторами. Например, при решении задач на графы, где вершины или ребра графа можно представлять в виде ключей и значений, что упрощает обработку данных и их изменение в процессе выполнения алгоритма.
В случаях, когда порядок элементов важен или когда нужно хранить повторяющиеся ключи, словарь не подходит. Если требуется хранить порядок добавления или иметь возможность хранения нескольких значений с одинаковыми ключами, следует рассмотреть другие структуры данных, такие как список или коллекцию.
Что влияет на скорость работы списков и словарей в Python?
Скорость работы списков и словарей в Python зависит от множества факторов, включая их внутреннюю реализацию, особенности алгоритмов и общую нагрузку на память.
Списки
Основные аспекты, влияющие на производительность списков:
- Динамическое выделение памяти: При добавлении элементов в список Python использует амортизированную стоимость операции добавления (O(1)), но периодически увеличивает размер списка, что приводит к увеличению времени выполнения при добавлении больших объемов данных.
- Реализация как динамического массива: При добавлении или удалении элементов в середине списка время работы операции может быть O(n), так как элементы сдвигаются. Это особенно важно при частых изменениях размера списка.
- Доступ по индексу: Операция доступа по индексу имеет время O(1), так как список реализован как динамический массив.
- Обработка памяти: Списки могут занимать больше памяти из-за необходимости хранения информации о размере и ссылках на элементы.
Словари

Основные факторы, влияющие на производительность словарей:
- Хеширование: Операции вставки, удаления и поиска в словаре выполняются за O(1) в среднем, благодаря использованию хеш-таблицы. Однако в случае коллизий (когда два ключа имеют одинаковый хеш) скорость может уменьшиться до O(n), хотя это случается крайне редко.
- Динамическое изменение размера: Как и в случае со списками, словарь автоматически увеличивает свой размер по мере добавления элементов. Это также имеет амортизированную сложность O(1), но в случае переполнения может замедлить операции.
- Типы данных в качестве ключей: Скорость работы словаря зависит от типов данных, используемых в качестве ключей. Нереализованные хеш-функции или сложные объекты могут замедлить работу хеширования.
- Перераспределение хеш-таблицы: Когда словарь становится слишком большим, Python перераспределяет хеш-таблицу, что увеличивает затраты на операции в этот момент.
Рекомендации для оптимизации

- Для работы с большими списками старайтесь минимизировать количество операций добавления/удаления элементов в середине списка, предпочитая операции с концом списка.
- При работе с большими словарями используйте ключи, которые быстро хешируются (например, строки или числа), чтобы минимизировать время поиска и вставки.
- Если предполагается большое количество изменений в структуре данных, рассмотрите использование альтернативных структур данных, таких как deque для списков или collections.defaultdict для словарей, которые могут быть более эффективными в определенных ситуациях.
Как безопасно изменять и объединять списки в многозадачных приложениях?

В многозадачных приложениях работа с изменяемыми объектами, такими как списки, требует внимательности из-за потенциальных проблем с конкурентным доступом. Одновременные изменения в одном и том же списке из нескольких потоков могут привести к непредсказуемым результатам. Для безопасной работы со списками важно правильно синхронизировать доступ к данным.
Первое, что следует учитывать, – это использование блокировок. Модуль threading предоставляет объект Lock, который позволяет синхронизировать доступ к разделяемым ресурсам. Для изменения списка, например, добавления или удаления элементов, необходимо захватить блокировку, чтобы гарантировать, что только один поток будет изменять список в конкретный момент времени.
Пример использования Lock для безопасного изменения списка:
import threading lock = threading.Lock() shared_list = [] def safe_append(item): with lock: shared_list.append(item)
В этом примере функция safe_append гарантирует, что только один поток может добавить элемент в список в любой момент времени. Это предотвращает повреждение данных при одновременных изменениях.
Для объединения списков в многозадачной среде важно также учитывать порядок и целостность данных. Когда требуется объединить несколько списков, лучше избегать прямого использования оператора +, который может привести к неожиданным результатам при параллельном доступе. Вместо этого рекомендуется использовать блокировки или другие механизмы синхронизации.
Пример безопасного объединения списков с блокировкой:
def safe_extend(other_list): with lock: shared_list.extend(other_list)
Еще один способ синхронизации работы с разделяемыми данными – использование очередей из модуля queue. Очереди, такие как Queue, автоматически защищены от конкуренции потоков, что делает их идеальными для многозадачных приложений, где нужно передавать или изменять данные между потоками.
Для оптимизации производительности в многозадачных приложениях можно также использовать пул потоков (ThreadPoolExecutor) из модуля concurrent.futures, который позволяет ограничить количество одновременно работающих потоков и эффективно управлять ими. Однако для сложных операций с изменяемыми данными, таких как работа со списками, блокировки или другие механизмы синхронизации остаются важными.
Использование атомарных операций, таких как list.append(), также может быть полезным, поскольку такие операции зачастую выполняются быстро и без вмешательства других потоков, если нет явной блокировки. Однако для более сложных операций, таких как сортировка или добавление элементов в середину списка, необходимо применять синхронизацию для предотвращения конфликтов.
Важно помнить, что в многозадачных приложениях, где требуется высокая производительность и низкие задержки, использование блокировок может быть узким местом. В таких случаях стоит рассмотреть использование более продвинутых структур данных, например, очередей с приоритетами или специализированных коллекций, которые могут обеспечить безопасность без явных блокировок.
Какие особенности работы с коллекциями данных при большом объеме информации?
1. Использование памяти: Стандартные структуры данных, такие как списки и словари, требуют значительного объема памяти, особенно при больших объемах информации. Для оптимизации использования памяти стоит рассмотреть генераторы вместо списков, поскольку они не сохраняют все элементы в памяти одновременно, а генерируют их по мере необходимости. Также полезно использовать множества и словарь с компактизированными значениями, если важна скорость и экономия памяти.
2. Алгоритмическая эффективность: При увеличении данных скорость обработки может заметно снизиться. Например, операции добавления и удаления элементов в списке могут занимать O(n) времени. Для ускорения работы стоит использовать deque из модуля collections, который позволяет выполнять операции с обеих сторон за O(1) время. Словари и множества в Python имеют время доступа O(1), что делает их идеальными для обработки больших объемов данных.
3. Сортировка и фильтрация: Операции сортировки и фильтрации данных на больших объемах становятся более затратными. Стандартная сортировка имеет сложность O(n log n), что может быть недостаточно эффективно при больших объемах. В таких случаях лучше использовать специализированные алгоритмы или библиотеки, такие как NumPy, которые обеспечивают более быстрые операции сортировки и работы с большими массивами данных.
4. Обработка данных параллельно: Для масштабируемости стоит подумать о многозадачности или параллельной обработке данных. Использование многопроцессорных технологий через библиотеку multiprocessing может значительно повысить производительность при параллельной обработке данных. Однако важно понимать, что не все задачи можно эффективно распараллелить, и в таких случаях стоит использовать асинхронные подходы через библиотеку asyncio.
5. Выбор подходящих типов данных: Для специфичных типов данных можно использовать специализированные структуры. Например, для хранения строковых данных лучше использовать строки фиксированной длины, а для числовых – массивы NumPy, которые оптимизированы для хранения больших объемов данных. Также, для хранения огромных данных эффективно использовать библиотеки, такие как pandas, которые предоставляют высокоэффективные структуры данных для анализа.
7. Разделение данных: Когда объем данных становится слишком большим для обработки в одном процессе, можно применять методы разделения данных на меньшие блоки или использование распределенных систем, таких как Apache Spark или Dask. Эти системы позволяют эффективно обрабатывать данные на нескольких узлах, что значительно ускоряет работу с большими объемами данных.
Вопрос-ответ:
Какие встроенные структуры данных предоставляет Python и в чем их особенности?
Python предлагает несколько встроенных структур данных, каждая из которых имеет свои особенности. Наиболее часто используемые структуры — это списки (list), множества (set), кортежи (tuple), словари (dict) и строки (str). Списки представляют собой изменяемые коллекции, которые могут хранить элементы различных типов. Множества обеспечивают хранение уникальных элементов без повторений, а кортежи — это неизменяемые последовательности данных. Словари представляют собой коллекции пар «ключ-значение», что делает их удобными для хранения информации, ассоциированной с уникальными идентификаторами. Строки в Python также являются неизменяемыми коллекциями символов.
Почему списки в Python считаются гибкими структурами данных?
Списки в Python являются очень гибкими, поскольку поддерживают динамическое изменение размера и могут хранить объекты любых типов. Это означает, что вы можете добавлять, удалять и изменять элементы в списке по мере необходимости. Также они поддерживают индексацию, срезы и перебор элементов, что делает их удобными для работы с последовательностями данных. В отличие от массивов в других языках, списки в Python автоматически изменяют свой размер при добавлении или удалении элементов, что избавляет от необходимости заранее указывать их размер.
В чем отличие между кортежами и списками в Python?
Основное отличие между кортежами и списками заключается в том, что кортежи — это неизменяемые структуры данных, в то время как списки являются изменяемыми. Это значит, что после создания кортежа его элементы нельзя изменить, удалить или добавить новые. В свою очередь, списки позволяют выполнять такие операции. Кортежи обычно используются для хранения фиксированных наборов данных, когда требуется гарантировать их неизменность. Они также могут быть более производительными в некоторых случаях, так как их неизменность снижает накладные расходы на управление памятью.
Для чего используются множества в Python и какие их особенности?
Множества в Python используются для хранения уникальных элементов без порядка. Они удобны, когда важно работать с набором данных, исключая дубликаты. В отличие от списков, множества не сохраняют порядок элементов, и их нельзя индексировать, что делает их не подходящими для случаев, когда важно последовательное расположение элементов. Множества поддерживают быстрые операции проверки вхождения, добавления и удаления элементов, что делает их полезными в задачах, где требуется работа с большими объемами данных, например, для поиска пересечений или объединений множеств.
Как работают словари в Python и чем они полезны?
Словари в Python — это структуры данных, которые хранят пары «ключ-значение». Ключи в словарях должны быть уникальными и неизменяемыми (например, числа, строки, кортежи), в то время как значения могут быть любыми объектами. Словари полезны, когда нужно хранить данные в виде ассоциативных пар, например, для представления объектов с различными атрибутами или для быстрого поиска значений по ключу. Операции с использованием словарей (например, поиск, добавление и удаление элементов) выполняются очень быстро, благодаря использованию хеширования для ключей.