Создание алгоритма на Python начинается не с кода, а с четкой формулировки задачи. Если цель – отсортировать массив чисел, необходимо определить, какая именно сортировка требуется: по возрастанию, убыванию, устойчиво или с приоритетом по значениям. На этом этапе важно записать входные и выходные данные в виде конкретных примеров, чтобы исключить неоднозначности в логике.
Следующий шаг – построение псевдокода. Это структурированное описание логики на человеческом языке. Например, если алгоритм должен находить наибольший общий делитель двух чисел, его псевдокод может включать цикл, который будет выполнять деление до тех пор, пока остаток не станет равным нулю. Псевдокод помогает выявить логические ошибки до начала программирования.
После этого можно переходить к написанию кода. На этапе реализации важно использовать функции для изоляции логики, избегать дублирования и предусмотреть обработку ошибок. Например, если алгоритм работает с пользовательским вводом, необходимо валидировать типы данных с помощью конструкции try-except.
Завершающий этап – тестирование и оптимизация. Алгоритм должен корректно обрабатывать не только типовые, но и граничные случаи. Например, пустой список или большое количество элементов. Для проверки можно использовать модуль unittest или библиотеку pytest, что позволит автоматизировать тестирование и быстрее выявлять ошибки при изменениях в коде.
Как определить задачу для алгоритма и сформулировать входные данные
Разделение на подзадачи: разложите цель на минимальные логические шаги. Если задача – сортировка по убыванию, уточните: «вход – список целых чисел», «выход – тот же список, но отсортированный по убыванию». Определите, нужно ли учитывать дубликаты, отрицательные значения, пустые списки.
Формализация входных данных: укажите точный тип данных: список целых чисел, строка ASCII без пробелов, словарь с числовыми ключами. Пропишите диапазоны: «целые от -106 до 106«, «строка длиной не более 100 символов». Это необходимо для последующей проверки корректности и оптимальности алгоритма.
Обработка граничных случаев: предусмотрите ввод, выходящий за стандартные рамки: пустые структуры, null-значения, невалидные форматы. Определите, должен ли алгоритм завершаться с ошибкой или возвращать дефолтное значение.
Примеры входа и выхода: без них невозможно протестировать логику. Пример: вход – [5, 2, 9], ожидаемый результат – 2. Один пример – минимально допустимо, лучше – три: нормальный, пограничный, некорректный.
Уточнение контекста использования: определите, где и как будет применяться алгоритм – в реальном времени, в фоновом режиме, с пользовательским вводом или API. Это влияет на требования к скорости, надежности и масштабируемости.
Как выбрать подходящие структуры данных для хранения информации
Выбор структуры данных зависит от характера операций, которые предполагается выполнять над информацией. Если требуется быстрый доступ по ключу, используйте dict – доступ к элементу по ключу выполняется за O(1). Для упорядоченных коллекций с возможностью быстрой вставки в конец и удаления с конца – list. Однако вставка в начало списка или удаление из начала требует O(n), что делает его неэффективным для очередей.
Если данные необходимо обрабатывать по принципу «первым пришёл – первым вышел», используйте collections.deque. Она обеспечивает O(1) на вставку и удаление с обеих сторон. Для хранения уникальных значений – set, который гарантирует быстрое добавление и проверку наличия элемента.
Для ассоциативного хранения, когда ключи не только строки, но и любые хешируемые объекты – также подходит dict. Когда порядок элементов критичен, используйте collections.OrderedDict, если нужна совместимость с Python 3.6 и ниже. В новых версиях dict сохраняет порядок по умолчанию.
При работе с неизменяемыми наборами данных, передаваемыми между функциями, эффективны tuple. Они экономичнее по памяти и быстрее списков в итерациях. Для подсчёта элементов – collections.Counter, особенно при анализе текстов и логов.
При проектировании алгоритма заранее определите:
- нужна ли уникальность элементов;
- важен ли порядок хранения;
- как часто будут происходить вставки, удаления, поиск;
- нужно ли изменять структуру после создания.
На основании ответов выбирайте структуру, минимизирующую временные и пространственные издержки. Неправильный выбор часто приводит к деградации производительности, особенно при больших объёмах данных.
Как разбить алгоритм на последовательные шаги и записать план действий
Начните с формулировки конечной цели: что конкретно должен сделать алгоритм. Избегайте абстрактных формулировок, указывайте измеримые и проверяемые результаты.
Далее определите входные данные. Укажите типы, структуру и допустимые значения. Например, список целых чисел, строка с датой, словарь с конфигурацией. Приведите примеры допустимого ввода.
Определите желаемый формат выходных данных. Чётко зафиксируйте, что именно должен вернуть алгоритм: одно число, список, логическое значение и т.д.
Разделите процесс обработки данных на атомарные операции. Каждая операция должна быть описана так, чтобы её можно было реализовать как отдельную функцию. Например: «Отсортировать список по убыванию», «Отфильтровать элементы по условию X», «Вычислить сумму», «Проверить наличие значения Y».
Для каждой операции определите, какие данные она принимает и что возвращает. Избегайте неявных зависимостей между шагами.
Сформируйте линейную последовательность шагов, добавляя промежуточные проверки (например, контроль пустых значений, валидацию типов, диапазонов). Не переходите к следующему действию без уверенности в корректности результата предыдущего.
После этого создайте псевдокод. Это упрощённое текстовое описание алгоритма, где каждая строка соответствует одному шагу. Используйте конструкции вида: «если … то …», «иначе …», «для каждого … в …», «вернуть результат».
Наконец, проверьте план на полноту: все ли возможные варианты входных данных учтены, предусмотрены ли граничные случаи, определено ли поведение при ошибках.
Как реализовать начальный прототип алгоритма на Python

Создайте функцию с ясным названием и четко определёнными параметрами. Избегайте глобальных переменных. Все, что необходимо алгоритму, должно передаваться в виде аргументов.
Задайте базовую логику через последовательность простых шагов. Используйте итерации и условные конструкции, но избегайте преждевременной оптимизации. Пример:
def find_max(numbers: list[int]) -> int:
max_val = numbers[0]
for num in numbers:
if num > max_val:
max_val = num
return max_val
Добавьте временные проверки на каждом этапе с помощью print() или assert. Это помогает локализовать ошибки и проверить корректность промежуточных значений. Пример:
assert isinstance(numbers, list), "Ожидается список чисел"
Разделите алгоритм на независимые части, если он включает несколько этапов. Например, сначала фильтрация данных, затем сортировка, затем анализ. Каждая часть должна быть реализована отдельной функцией с конкретной задачей.
Обязательно покройте прототип минимальными юнит-тестами на крайние случаи: пустые входы, одинаковые значения, неожиданные типы. Используйте pytest или встроенный модуль unittest.
Не добавляйте обработку исключений на этом этапе, если только она не критична для логики. Прототип должен оставаться прозрачным и легко читаемым.
Как отладить код с помощью встроенных инструментов и print
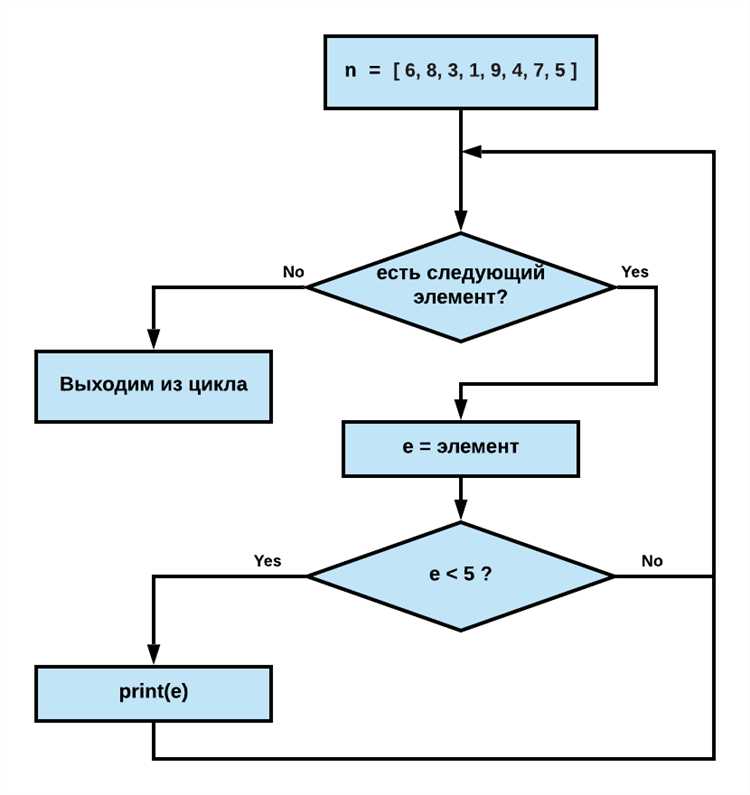
Для эффективной отладки Python-кода можно использовать встроенные средства, такие как функция print() и модуль pdb. Они позволяют отслеживать значения переменных, порядок выполнения и выявлять ошибки логики без внешних IDE.
- Использование print()
- Следите за порядком вызовов функций, добавляя print в начало каждой:
print("Функция calculate() вызвана"). - Не используйте print внутри циклов с большим числом итераций без необходимости – это замедлит выполнение и усложнит анализ.
- После устранения ошибки удаляйте лишние print или временно заменяйте их на логирование через
logging.debug().
- Модуль pdb
- Для установки точки останова вставьте строку
import pdb; pdb.set_trace()перед проблемным участком. - Во время остановки можно использовать команды:
n– выполнить текущую строку и перейти к следующей;s– войти внутрь вызываемой функции;c– продолжить выполнение до следующей точки останова;p переменная– вывести значение переменной;q– выйти из отладки.
- При работе с циклами ставьте
set_trace()внутри условия, ограничивающего количество срабатываний, чтобы избежать сотен остановок.
Для сложных случаев комбинируйте оба метода: предварительный анализ через print, а точечная отладка – через pdb. Это ускоряет диагностику и повышает точность исправлений.
Как добавить обработку ошибок и предусмотреть нестандартные ситуации
Для обеспечения надежности программы важно предусматривать обработку ошибок. Ошибки могут возникать на разных этапах выполнения: при взаимодействии с пользователем, работе с файлами, подключении к базе данных или выполнении внешних запросов. Каждый из этих случаев требует конкретных решений.
Использование конструкции try-except позволяет перехватывать исключения и предотвращать аварийное завершение программы. Рассмотрим пример, как это можно реализовать:
try:
value = int(input("Введите число: "))
except ValueError:
print("Ошибка: введено не число.")В данном примере, если пользователь введет нечисловое значение, программа не завершится с ошибкой, а отработает блок except, который сообщит о неправильном вводе.
Однако обработка ошибок не ограничивается только перехватом исключений. Важно также предусматривать возможные нестандартные ситуации. Например, если программа работает с сетью, важно учитывать случаи, когда сервер недоступен или происходит тайм-аут. В таких случаях можно использовать несколько типов исключений и создавать различные сценарии для каждой из ситуаций.
Пример обработки нескольких типов исключений:
try:
response = requests.get("https://example.com")
response.raise_for_status() # Проверка на успешный статус код
except requests.ConnectionError:
print("Ошибка сети. Проверьте подключение.")
except requests.Timeout:
print("Ошибка: время ожидания истекло.")
except requests.HTTPError as e:
print(f"HTTP ошибка: {e.response.status_code}")
except Exception as e:
print(f"Произошла непредвиденная ошибка: {str(e)}")При работе с файлами также стоит учитывать возможные ошибки, например, когда файл не существует или нет прав на его запись:
try:
with open("data.txt", "r") as file:
content = file.read()
except FileNotFoundError:
print("Файл не найден.")
except PermissionError:
print("Нет прав для чтения файла.")Важно помнить, что избыточная обработка ошибок, особенно для стандартных случаев, может сделать код сложным и трудным для понимания. Поэтому нужно сбалансировать количество исключений, чтобы они действительно отражали потенциальные проблемы, а не обрабатывали каждый малейший случай.
Дополнительно, можно использовать блок else и finally для выполнения кода, который должен быть выполнен независимо от наличия ошибки или после успешного завершения:
try:
result = 10 / 0
except ZeroDivisionError:
print("Деление на ноль невозможно.")
else:
print("Операция выполнена успешно.")
finally:
print("Этот блок выполнится в любом случае.")Обработка ошибок и нестандартных ситуаций – это ключевой аспект при разработке надежных и устойчивых программ, способных корректно реагировать на различные исключительные события.
Как протестировать алгоритм на разных наборах входных данных
Тестирование алгоритма – важный этап в процессе разработки, который позволяет убедиться в корректности работы программы. Чтобы тесты были эффективными, необходимо проанализировать различные наборы входных данных. Это помогает выявить потенциальные ошибки и недочеты, которые могут возникнуть в реальных условиях.
Для тестирования алгоритма на разных наборах входных данных следуйте нескольким ключевым шагам:
- Определение границ входных данных: Прежде чем приступать к тестированию, необходимо четко определить, какие данные алгоритм должен обрабатывать. Разделите их на несколько категорий:
- Минимальные данные (крайний случай, например, пустой список, нулевое значение и т. д.)
- Максимальные данные (предельные значения, которые алгоритм должен обработать без ошибок)
- Средние значения (данные, которые могут быть характерны для обычных случаев использования)
- Необычные данные (исключительные случаи, например, отрицательные значения, нулевые элементы)
- Проведение тестов на различных наборах данных: Примените алгоритм к каждому набору данных, начиная от крайних случаев до типичных. Ожидаемые результаты должны быть заранее известны и зафиксированы. Важно проверять, что алгоритм правильно справляется с обоими: обычными и исключительными случаями.
- Тестирование на больших объемах данных: Алгоритм может работать корректно на маленьких наборах, но при больших данных производительность или правильность работы может снизиться. Протестируйте алгоритм с большими входными данными, чтобы убедиться, что он эффективно обрабатывает такие объемы без сбоев.
- Использование случайных данных: Генерация случайных наборов данных поможет проверить, насколько алгоритм универсален. Используйте библиотеку
randomдля создания случайных данных, которые соответствуют условиям, установленным для входа. Это поможет выявить ошибки, которые могут возникнуть в условиях случайности. - Использование тестов на основе характеристик алгоритма: В некоторых случаях можно заранее предсказать, какие входные данные могут привести к неэффективной работе алгоритма. Например, для сортировок важно проверить уже отсортированные данные, наоборот – обратный порядок, а также случайные перестановки элементов.
- Анализ временной сложности: Для более глубокого тестирования важно отслеживать, как быстро работает алгоритм на различных наборах данных. Это можно сделать с помощью библиотеки
timeв Python. Измерьте время работы алгоритма на данных разного объема и проанализируйте, насколько его производительность ухудшается при увеличении объема входных данных.
Результаты тестирования помогут не только проверить корректность алгоритма, но и определить его производительность, что особенно важно при решении масштабируемых задач. Применяйте разнообразные наборы данных, чтобы убедиться, что ваш алгоритм работает должным образом в любых ситуациях.
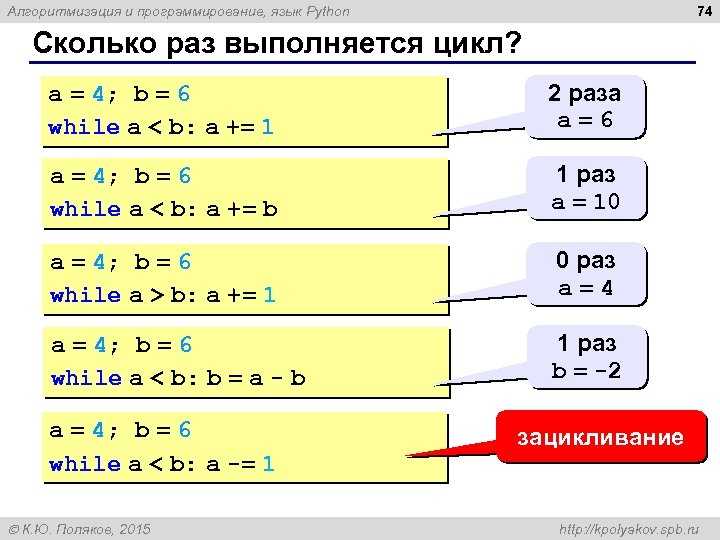
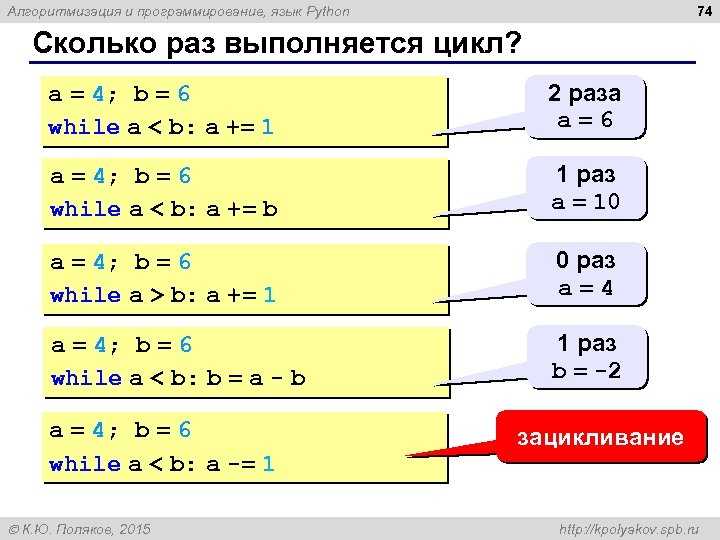
Как измерить время выполнения и оптимизировать узкие места
Для эффективной оптимизации алгоритмов необходимо точно измерять время выполнения кода и находить узкие места. Это позволяет не только улучшить производительность, но и избежать ненужных оптимизаций, которые могут оказаться неэффективными.
Для измерения времени выполнения в Python используются несколько методов. Один из самых простых и удобных – это модуль time, который предоставляет функцию time.time(). Она возвращает текущее время в секундах с момента эпохи (обычно 1970 года). Для измерения времени работы блока кода, можно использовать следующий подход:
import time
start_time = time.time()
# Ваш код
end_time = time.time()
print(f"Время выполнения: {end_time - start_time} секунд")
Этот способ подходит для быстрого измерения времени, однако для более точных измерений, особенно когда речь идет о микросекундах, рекомендуется использовать time.perf_counter(), так как она предоставляет более точное значение времени.
Второй подход – использование timeit, модуля, специально предназначенного для тестирования времени выполнения небольших фрагментов кода. Он автоматически повторяет выполнение кода несколько раз для получения более стабильных результатов. Пример использования:
import timeit
print(timeit.timeit('sum(range(100))', number=1000))
Когда измерено время выполнения, важно проанализировать результаты, чтобы выявить узкие места. Основные подходы к оптимизации зависят от типа алгоритма и характера работы программы, но можно выделить несколько универсальных стратегий:
- Избегание избыточных вычислений: Например, если в цикле несколько раз выполняется одно и то же вычисление, лучше вынести его за пределы цикла.
- Использование эффективных структур данных: Например, замените список на множество, если вам нужно только проверить наличие элемента, или используйте очередь вместо списка для частых добавлений и удалений элементов.
- Параллельное выполнение: Для вычислений, которые можно разделить на независимые задачи, рассмотрите использование многозадачности (модули threading или multiprocessing).
Одним из важных инструментов для нахождения узких мест является профилирование. Для этого используется встроенный модуль cProfile, который позволяет анализировать время работы функций и выявлять «тяжелые» участки кода. Пример его использования:
import cProfile
def test_function():
# Ваш код
pass
cProfile.run('test_function()')
Результат профилирования покажет, сколько времени занимает каждая функция и сколько раз она была вызвана. Это поможет точно локализовать проблемные участки, которые требуют оптимизации.
Вопрос-ответ:
Какой алгоритм проще всего создать на Python для новичка?
Для начинающих программистов можно начать с простых алгоритмов, например, с алгоритма сортировки пузырьком. Он помогает понять основные принципы работы с циклами и условиями. В этом алгоритме элементы массива сравниваются попарно и меняются местами, если они идут в неправильном порядке. Это хороший способ потренироваться в работе с массивами и циклами, а также понять, как работает алгоритмическая логика.
Как правильно разбить задачу на этапы при создании алгоритма на Python?
Когда вы создаете алгоритм на Python, важно разделить задачу на несколько шагов. Сначала определите, что именно должен делать ваш алгоритм. Затем разбейте его на более мелкие задачи. Например, если нужно написать программу для поиска максимального числа в списке, шаги могут быть такими: 1) Получить данные (список чисел); 2) Пройти по всем числам в списке; 3) Найти максимальное значение; 4) Вернуть результат. Разделение задачи на логичные этапы помогает сделать процесс разработки более понятным и упрощает отладку.
Какие ошибки часто делают начинающие при написании алгоритмов на Python?
Одна из самых распространенных ошибок у новичков — это неправильно подобранные структуры данных. Например, использование списка вместо множества для проверки уникальности элементов может значительно снизить производительность. Также многие не учитывают крайние случаи (например, пустые списки или нулевые значения), что приводит к ошибкам выполнения. Еще одна распространенная ошибка — это использование сложных конструкций без четкого понимания их работы, что может затруднить отладку и чтение кода.
Как протестировать алгоритм, чтобы убедиться, что он работает корректно?
Для тестирования алгоритма важно создать несколько тестовых случаев, которые проверят все возможные варианты поведения программы. Например, если ваш алгоритм сортирует список, нужно протестировать его на уже отсортированных данных, на данных, отсортированных в обратном порядке, на пустом списке и на списке с одинаковыми элементами. Такой подход позволит выявить ошибки и убедиться, что алгоритм работает корректно во всех ситуациях. Использование фреймворков для тестирования, таких как `unittest` в Python, может помочь автоматизировать этот процесс.