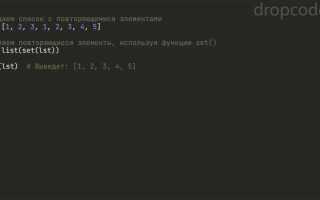
Дубликаты в списках могут привести к неверным результатам при анализе данных, увеличению времени выполнения алгоритмов и избыточному потреблению памяти. В Python существует несколько способов удаления повторяющихся элементов, и выбор конкретного метода зависит от требований к порядку элементов и производительности.
Если порядок не имеет значения, можно использовать преобразование списка в множество: list(set(my_list)). Это самый быстрый способ, но он не сохраняет порядок исходных данных. Для сохранения порядка с Python 3.7 можно воспользоваться dict.fromkeys(): list(dict.fromkeys(my_list)). Этот метод сохраняет только первое вхождение каждого элемента и работает быстро за счёт хэш-таблицы словаря.
Когда важна гибкость или требуется фильтрация по сложным условиям, применяется цикл с проверкой: for item in my_list: if item not in seen: …. Такой подход универсален, но при больших объёмах данных может работать медленно из-за линейного поиска в списке уже встреченных значений. Для ускорения стоит использовать множество как структуру хранения уникальных элементов во время итерации.
Выбор подхода должен быть обоснован: оцените размер списка, необходимость сохранить порядок и допустимость дополнительных структур данных. Эффективное удаление дубликатов – ключ к оптимизированному коду.
Как удалить дубликаты с сохранением порядка элементов

Один из вариантов – это обход списка с добавлением элементов в новый список только в том случае, если они ещё не встречались. Для этого удобно воспользоваться встроенным типом данных `set`, который позволяет отслеживать уникальные элементы без изменений порядка их появления в исходном списке.
Пример кода:
def remove_duplicates(lst): seen = set() result = [] for item in lst: if item not in seen: result.append(item) seen.add(item) return result
Этот метод работает следующим образом: создаётся пустое множество `seen`, которое будет хранить уникальные элементы. В цикле по каждому элементу списка проверяется, есть ли он уже в `seen`. Если нет, элемент добавляется в итоговый список `result` и в множество `seen`.
Этот подход сохраняет порядок элементов, так как добавление нового элемента происходит только при его первом встречении в списке, а не при его повторении. Это позволяет эффективно избавиться от дубликатов без перемешивания данных.
Ещё один способ, использующий функциональные возможности Python – это использование генераторов списков с условием для добавления уникальных элементов:
def remove_duplicates(lst): return [x for i, x in enumerate(lst) if x not in lst[:i]]
Здесь для каждого элемента в списке проверяется, встречался ли он раньше, с использованием среза списка. Этот метод также сохраняет порядок, но может быть менее эффективным для больших списков из-за повторных проверок.
Если необходимо работать с большими объемами данных и важна высокая производительность, первым вариантом с использованием множества будет оптимальным решением.
Удаление дубликатов в списке со вложенными структурами

При работе со списками, содержащими вложенные структуры данных, например, списки внутри списков или словари внутри списков, задача удаления дубликатов становится более сложной. Стандартные методы, такие как использование множества (set), не подходят, так как они не могут обрабатывать изменяемые элементы, такие как списки или словари.
Для решения этой проблемы можно использовать рекурсивный подход, который будет проверять все вложенные элементы и исключать дубликаты на всех уровнях структуры. Важно помнить, что в Python изменяемые объекты, такие как списки и словари, не могут быть добавлены в множество напрямую, так как множества требуют, чтобы все их элементы были хешируемыми.
Рассмотрим пример, где в списке содержатся как простые элементы, так и вложенные структуры:
data = [
[1, 2, 3],
[4, 5, 6],
[1, 2, 3],
{'key': 'value'},
{'key': 'value'}
]
Чтобы удалить дубликаты, необходимо рекурсивно проходить по всем вложенным элементам, сравнивая их между собой. Для этого можно использовать вспомогательную функцию, которая будет проверять наличие дубликатов на каждом уровне вложенности. Вот пример кода:
def remove_duplicates(data):
seen = set()
def recursive_remove(item):
if isinstance(item, list):
return [recursive_remove(i) for i in item if tuple(i) not in seen and not seen.add(tuple(i))]
elif isinstance(item, dict):
return {key: recursive_remove(value) for key, value in item.items()}
else:
return item
return recursive_remove(data)
Этот код рекурсивно удаляет дубликаты как в списках, так и в словарях. Важно отметить, что для проверки вложенных структур используется преобразование их в кортежи с помощью функции tuple(), что позволяет хешировать их и добавлять в множество seen.
Если в структуре данных встречаются более сложные объекты, такие как пользовательские классы, для их поддержки нужно будет реализовать дополнительные методы сравнения и хеширования, например, через методы __eq__ и __hash__.
Также, если вложенная структура данных слишком велика и требует оптимизации, можно рассмотреть использование специализированных библиотек, таких как pandas для работы с большими объемами данных и быстрого удаления дубликатов.
Удаление дубликатов без учёта регистра строк

При сравнении строк в Python чувствительность к регистру по умолчанию сохраняется. Чтобы удалить дубликаты, игнорируя регистр, необходимо привести все элементы списка к единому виду для сравнения, но сохранить исходное форматирование хотя бы одного экземпляра каждой уникальной строки.
Для этого удобно использовать вспомогательную структуру – множество для отслеживания уже встреченных значений в нижнем регистре:
def remove_case_insensitive_duplicates(data):
seen = set()
result = []
for item in data:
lowered = item.lower()
if lowered not in seen:
seen.add(lowered)
result.append(item)
return result
Этот метод сохраняет порядок появления элементов и оставляет первую встреченную строку с оригинальным регистром. Подходит для любых итерируемых объектов, содержащих строки. Важно: item.lower() не модифицирует оригинальную строку, а создаёт новую, что исключает побочные эффекты.
Рекомендация: если список большой, используйте генераторное выражение внутри цикла для экономии памяти, но избегайте однострочных решений с set, так как они не сохраняют порядок и не дают контроля над форматированием.
Чем отличаются set(), dict.fromkeys() и list comprehension
set() удаляет дубликаты, но не сохраняет порядок элементов до Python 3.6 включительно. Начиная с Python 3.7, порядок сохраняется, но это не гарантировано спецификацией языка. При использовании list(set(lst)) результат может быть непредсказуемым с точки зрения порядка.
dict.fromkeys(lst) сохраняет порядок следования элементов, начиная с Python 3.7, и позволяет избавиться от дубликатов, так как ключи в словаре уникальны. Для получения списка без повторений нужно обернуть результат в list(): list(dict.fromkeys(lst)). Этот способ быстрее, чем set() при необходимости сохранить порядок.
Список включения с условием (list comprehension) предоставляет наибольшую гибкость. Например, [x for i, x in enumerate(lst) if x not in lst[:i]] сохраняет порядок, но работает медленнее на больших списках из-за линейной проверки x not in lst[:i] на каждом шаге.
Если важен порядок и производительность – использовать dict.fromkeys(). Если порядок не важен – set(). Для сложной фильтрации или условий – list comprehension.
Как удалить дубликаты по определённому ключу в списке словарей
При работе со списками словарей часто возникает необходимость оставить только один элемент с уникальным значением определённого ключа. Для этого удобно использовать множество для отслеживания уже встреченных значений.
Пример: из списка пользователей нужно оставить только одного с каждым уникальным email.
users = [
{"name": "Анна", "email": "anna@example.com"},
{"name": "Борис", "email": "boris@example.com"},
{"name": "Анна", "email": "anna@example.com"},
]
seen = set()
unique_users = []
for user in users:
email = user["email"]
if email not in seen:
seen.add(email)
unique_users.append(user)
Этот метод сохраняет порядок элементов. Если порядок не важен, можно использовать словарь с генератором:
unique_users = list({user["email"]: user for user in reversed(users)}.values())[::-1]
Использование reversed позволяет сохранить последний вариант каждого дубликата. Для сохранения первого – уберите reversed.
Ключевое преимущество подхода – линейная сложность по времени при минимальном объёме кода.
Удаление дубликатов в списке чисел с плавающей точкой
Работа с числами с плавающей точкой осложняется тем, что значения, визуально кажущиеся одинаковыми, могут не совпадать в бинарном представлении. Например, 1.0 и 0.9999999999999999 – разные значения, хотя при округлении могут быть равны. Для точного удаления дубликатов необходимо учитывать заданную точность сравнения.
- Использовать
round()– простой способ устранения мелких расхождений:
nums = [1.0, 1.0000001, 2.5, 2.5000001]
unique = list({round(x, 6) for x in nums})
- Для более гибкого контроля – использовать
math.isclose()с итеративной фильтрацией:
import math
def remove_float_duplicates(lst, rel_tol=1e-9, abs_tol=0.0):
result = []
for num in lst:
if not any(math.isclose(num, existing, rel_tol=rel_tol, abs_tol=abs_tol) for existing in result):
result.append(num)
return result
nums = [1.0, 1.0000000001, 2.0, 2.0000000001]
unique = remove_float_duplicates(nums)
- Сортировка перед фильтрацией ускоряет обработку больших списков:
def dedup_sorted_floats(lst, tol=1e-9):
lst.sort()
result = [lst[0]]
for num in lst[1:]:
if abs(num - result[-1]) > tol:
result.append(num)
return result
Рекомендуется избегать преобразования в set без предварительного округления – потеряется контроль над точностью сравнения. Использование decimal.Decimal целесообразно при необходимости высокой точности и воспроизводимости.