Для работы с веб-страницами на языке Python чаще всего используется библиотека requests, которая позволяет быстро и эффективно получать HTML-код страницы. Это основа для дальнейшего парсинга, автоматизации или тестирования. Простота и легкость в использовании делают requests идеальным инструментом для получения данных с сайтов.
Перед тем как начать, нужно установить эту библиотеку, если она еще не установлена. Это можно сделать с помощью команды:
pip install requestsПосле установки, для того чтобы получить HTML код страницы, достаточно отправить GET-запрос на нужный URL. Пример простого кода для этого:
import requests
response = requests.get('https://example.com')
html_code = response.text
print(html_code)Этот код позволяет получить весь HTML-код страницы в виде текста. Важно помнить, что иногда веб-сайты могут отвечать ошибкой или блокировать запросы с неизвестных источников. В таких случаях полезно использовать дополнительные параметры, такие как заголовки для имитации браузера, или библиотеки для обхода ограничений, например, BeautifulSoup для парсинга HTML.
Установка необходимых библиотек для работы с HTTP запросами
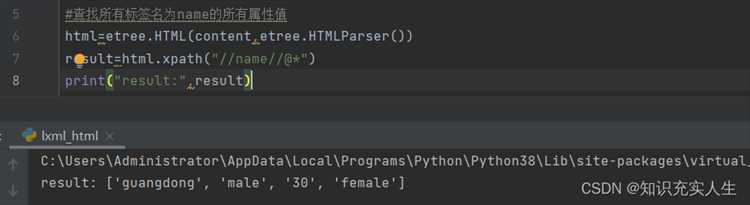
Для начала установки библиотеки requests выполните следующие шаги:
- Откройте терминал или командную строку.
- Используйте pip – стандартный инструмент для установки Python-библиотек. Введите команду:
- После установки проверьте правильность установки, запустив в Python-консоли:
pip install requests
import requests
Если ошибок не возникло, библиотека установлена успешно и готова к использованию. Она позволяет легко отправлять GET, POST и другие типы HTTP-запросов. Например:
import requests
response = requests.get('https://example.com')
print(response.text)
Если необходимо работать с более сложными HTTP-сессиями или кастомизировать заголовки, куки или параметры запросов, используйте функции и методы, предоставляемые библиотекой requests.
Для работы с более низкоуровневыми HTTP-запросами, когда требуется полный контроль над заголовками и потоками, можно использовать стандартную библиотеку http.client.
Для ее использования в вашем проекте нет необходимости в установке дополнительных пакетов. Эта библиотека входит в стандартную поставку Python. Пример кода с использованием http.client:
import http.client
conn = http.client.HTTPSConnection("example.com")
conn.request("GET", "/")
response = conn.getresponse()
print(response.read().decode())
Для более сложных проектов часто используется сочетание этих библиотек, в зависимости от уровня необходимой абстракции и сложности запросов.
Использование библиотеки requests для получения HTML кода
Библиотека requests позволяет эффективно и просто отправлять HTTP-запросы и получать HTML код страницы. Это один из самых популярных инструментов для работы с веб-страницами в Python, благодаря своей простоте и гибкости.
Для начала работы с requests необходимо установить библиотеку, если она еще не установлена. Это можно сделать с помощью команды:
pip install requests
После установки можно приступить к получению HTML кода страницы. Основной метод для выполнения запросов в библиотеке – requests.get(). Рассмотрим базовый пример:
import requests
response = requests.get('https://example.com')
html_code = response.text
print(html_code)
В данном примере метод get() отправляет запрос на указанную URL-страницу, а response.text возвращает HTML код страницы в виде строки.
Важно учитывать несколько нюансов при работе с requests:
- Проверка статуса ответа. Ответ от сервера может быть неудачным (например, страница не найдена или возникла ошибка сервера). Для проверки успешности запроса используйте свойство
status_code:
if response.status_code == 200:
print("Запрос успешен")
else:
print(f"Ошибка {response.status_code}")
- Обработка ошибок. Для более безопасной работы с сетью стоит обрабатывать возможные исключения. Например, можно использовать блок
try-exceptдля перехвата сетевых ошибок:
try:
response = requests.get('https://example.com')
response.raise_for_status() # Возбудит исключение при ошибке HTTP
except requests.exceptions.RequestException as e:
print(f"Ошибка запроса: {e}")
- Управление таймаутом. Важно указать таймаут для предотвращения бесконечных ожиданий в случае проблем с сетью. Это можно сделать через параметр
timeout:
response = requests.get('https://example.com', timeout=10) # 10 секунд
Таймаут поможет избежать долгих задержек, если сервер не отвечает.
- Передача параметров запроса. В случае, если нужно передать параметры в запрос (например, для поиска или фильтрации данных), используйте аргумент
params:
params = {'q': 'Python'}
response = requests.get('https://example.com/search', params=params)
print(response.text)
Таким образом, библиотека requests предоставляет простой и мощный инструмент для получения HTML кода страниц. Однако для работы с динамическими страницами (например, тех, которые загружаются с помощью JavaScript) потребуется использовать дополнительные инструменты, такие как Selenium или Playwright.
Парсинг HTML кода с использованием BeautifulSoup

Для работы с HTML-кодом в Python часто используют библиотеку BeautifulSoup. Она предоставляет удобные методы для извлечения данных, поиска элементов, модификации HTML и взаимодействия с DOM деревом. Чтобы начать, необходимо установить библиотеку через pip: pip install beautifulsoup4.
Для парсинга страницы сначала нужно получить её HTML-код. Обычно для этого используется библиотека requests, которая позволяет отправить GET-запрос. Пример кода для загрузки страницы:
import requests from bs4 import BeautifulSoup url = 'https://example.com' response = requests.get(url) html = response.text
После того как HTML-код страницы получен, можно передать его в BeautifulSoup для анализа:
soup = BeautifulSoup(html, 'html.parser')
С помощью объекта soup можно искать элементы, основываясь на различных признаках, таких как теги, классы, идентификаторы или атрибуты. Например, чтобы найти все <a> теги на странице, можно использовать метод find_all:
links = soup.find_all('a')
for link in links:
print(link.get('href'))
Метод find используется для поиска первого элемента, который соответствует заданному критерию. Для получения конкретного элемента с уникальным идентификатором (id) можно воспользоваться следующим кодом:
element = soup.find(id='unique-id') print(element.text)
Если требуется извлечь элементы с определенным классом, используется атрибут class_ (ключевое слово class зарезервировано в Python):
elements = soup.find_all(class_='some-class') for el in elements: print(el.text)
BeautifulSoup также позволяет извлекать атрибуты тегов. Для этого используется метод get, который позволяет получить значение любого атрибута тега:
img_tag = soup.find('img')
src = img_tag.get('src')
print(src)
При необходимости можно обрабатывать данные, используя регулярные выражения. Библиотека BeautifulSoup интегрируется с модулем re, что позволяет выполнять более сложные запросы. Например, чтобы найти все ссылки, содержащие в URL определённую подстроку, можно использовать регулярное выражение:
import re
links = soup.find_all('a', href=re.compile('example'))
for link in links:
print(link.get('href'))
Для работы с вложенными тегами также можно использовать методы find_parent, find_all_next, find_all_previous, которые позволяют двигаться по дереву DOM в нужном направлении.
Чтобы извлечь текст без HTML-тегов, можно использовать атрибут text:
text = soup.get_text() print(text)
Для более сложных задач стоит обратить внимание на методы фильтрации и комбинирования запросов. Например, можно использовать цепочку вызовов методов, чтобы найти элементы, которые соответствуют нескольким условиям:
soup.find_all('div', class_='class1').find_all('a', href=True)
Парсинг HTML с помощью BeautifulSoup является мощным инструментом для извлечения данных из веб-страниц, автоматизации сбора информации и анализа контента. Важно учитывать структуру документа и выбирать наиболее подходящие методы для эффективного и точного извлечения нужной информации.
Обработка ошибок при запросах и парсинге страницы

При работе с HTTP-запросами и парсингом данных часто возникают ошибки, которые могут существенно повлиять на результат. Эффективная обработка этих ошибок позволяет избежать сбоев и улучшить стабильность приложения.
Первый тип ошибок, с которыми можно столкнуться, – это проблемы при выполнении HTTP-запроса. Основные исключения, которые могут возникнуть при использовании библиотеки requests, это ConnectionError, Timeout, TooManyRedirects и RequestException. Каждое из этих исключений требует специфического подхода к обработке.
Для предотвращения ошибок соединения или тайм-аутов важно устанавливать время ожидания с помощью параметра timeout в методах запроса. Например, указание timeout=10 ограничит время ожидания ответа 10 секундами. В случае ошибки, например, при достижении лимита времени ожидания, будет выброшено исключение Timeout, которое можно перехватить и обработать:
import requests
try:
response = requests.get('https://example.com', timeout=10)
response.raise_for_status() # Проверка успешности запроса
except requests.exceptions.Timeout:
print("Ошибка: Превышено время ожидания")
except requests.exceptions.RequestException as e:
print(f"Ошибка запроса: {e}")
Если запрос приводит к TooManyRedirects, это сигнализирует о возможной неправильной настройке редиректов на сервере. В таких случаях стоит ограничить количество перенаправлений с помощью параметра max_redirects, чтобы избежать бесконечных циклов.
После того как запрос выполнен успешно, начинается этап парсинга HTML-страницы. Ошибки на этом этапе могут быть связаны с некорректным содержимым страницы, например, если HTML-структура отличается от ожидаемой. Использование парсеров, таких как BeautifulSoup, подразумевает, что HTML-документ будет правильно структурирован. Однако в случае поврежденного HTML, парсер может выдать ошибку.
Для предотвращения проблем с парсингом следует заранее проверять корректность содержимого ответа. Например, с помощью метода response.content можно убедиться в том, что полученные данные соответствуют ожидаемому формату. Дополнительно, для работы с нестандартными или поврежденными страницами можно использовать опцию features=»html.parser» в BeautifulSoup, которая позволяет корректно обработать неидеальный HTML.
from bs4 import BeautifulSoup
response = requests.get('https://example.com')
soup = BeautifulSoup(response.content, 'html.parser')
Кроме того, важно учитывать, что сервер может вернуть пустую страницу или ответ с кодом состояния, не равным 200 (например, 404 или 500). В таких случаях следует проверять response.status_code перед дальнейшей обработкой:
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
else:
print(f"Ошибка: Страница не доступна, код ошибки {response.status_code}")
Для сложных проектов рекомендуется внедрять механизм логирования. Это позволит фиксировать возникающие ошибки и вовремя реагировать на них. Важно логировать не только исключения, но и статусы HTTP-запросов, что помогает в диагностике проблем на всех этапах взаимодействия с веб-ресурсом.
Наконец, стоит учитывать, что структура страницы может изменяться, поэтому перед парсингом необходимо регулярно проверять актуальность используемых CSS-селекторов и XPath-выражений. Регулярные тесты и контроль изменений на целевых страницах помогут минимизировать ошибки в долгосрочной перспективе.
Получение динамически загружаемого контента с помощью Selenium
С помощью Selenium можно получить контент, который загружается асинхронно через JavaScript, что невозможно сделать стандартными методами, такими как библиотека requests. Это особенно полезно при парсинге современных сайтов, использующих React, Angular или другие фреймворки для динамической генерации контента.
Для работы с динамическим контентом необходимо использовать драйвер браузера, который будет эмулировать действия пользователя, такие как прокрутка страницы или ожидание загрузки элементов. Наиболее распространённые браузеры для работы с Selenium – Chrome и Firefox.
Чтобы начать, нужно установить Selenium и драйвер для выбранного браузера. Например, для работы с Chrome потребуется драйвер ChromeDriver. Его можно скачать с официального сайта и указать путь в скрипте.
Для установки Selenium используйте команду:
pip install selenium
Пример простого скрипта для получения данных с динамически загружаемой страницы:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Путь к драйверу Chrome
driver = webdriver.Chrome(executable_path='/path/to/chromedriver')
Открываем страницу
driver.get('https://example.com')
Ожидаем загрузки элемента (например, списка статей)
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'article-list'))
)
Получаем HTML-код страницы после загрузки
page_source = driver.page_source
Закрываем браузер
driver.quit()
Ключевым моментом является использование WebDriverWait и expected_conditions для ожидания загрузки элементов, которые могут появляться через некоторое время. Это позволяет избежать ошибок, связанных с попыткой извлечь контент до полной загрузки страницы.
Также стоит учитывать, что для получения данных с динамических страниц можно использовать прокрутку страницы (scrolling). Для этого можно симулировать прокрутку с помощью JavaScript через Selenium, что позволяет загружать новые данные при достижении конца страницы.
Пример прокрутки страницы:
# Прокручиваем страницу до конца
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
После выполнения прокрутки можно повторно ожидать появления новых элементов и извлекать их. Если требуется более сложное взаимодействие, можно использовать действия с клавишами или мышью, которые поддерживаются в Selenium.
Как сохранить полученный HTML код в файл
После того как HTML код страницы был получен с помощью Python, его можно сохранить в файл для последующего анализа или хранения. Это можно сделать с помощью стандартных средств работы с файлами в Python.
Для сохранения HTML-кода в файл можно использовать функцию open(), которая позволяет создать новый файл или открыть существующий для записи. После этого можно записать содержимое с помощью метода write().
Пример кода для сохранения HTML-кода в файл:
import requests
# Получаем HTML код страницы
url = "https://example.com"
response = requests.get(url)
html_code = response.text
# Сохраняем HTML в файл
with open("page.html", "w", encoding="utf-8") as file:
file.write(html_code)
В этом примере:
requests.get(url)отправляет запрос на указанный URL и получает HTML-код страницы.- Функция
open("page.html", "w", encoding="utf-8")открывает файл для записи (если файл не существует, он будет создан) с кодировкой UTF-8. - Метод
write()записывает HTML-код в файл.
Для предотвращения возможных ошибок, таких как отсутствие прав на запись или проблемы с кодировкой, всегда рекомендуется использовать обработку исключений:
try:
with open("page.html", "w", encoding="utf-8") as file:
file.write(html_code)
except Exception as e:
print(f"Ошибка при сохранении файла: {e}")
Если нужно сохранить файл с уникальным именем, можно добавить метку времени или уникальный идентификатор в имя файла:
import time
filename = f"page_{int(time.time())}.html"
with open(filename, "w", encoding="utf-8") as file:
file.write(html_code)
Таким образом, можно не только получить HTML-код, но и безопасно сохранить его в файл для дальнейшего использования.