Процесс компиляции в Python отличается от традиционных языков программирования, таких как C++ или Java, поскольку Python является интерпретируемым языком. Тем не менее, даже при отсутствии явного этапа компиляции в исходном коде, Python все равно использует промежуточные шаги для выполнения программ. Эти шаги включают компиляцию исходного кода в байт-код и его интерпретацию виртуальной машиной Python (PVM).
Когда вы запускаете Python-скрипт, интерпретатор сначала преобразует код в байт-код, который представляет собой платформонезависимый набор инструкций. Этот байт-код сохраняется в файлах с расширением .pyc и хранится в каталоге __pycache__, чтобы ускорить последующие запуски программы. Важно понимать, что байт-код не является машинным кодом и не может быть непосредственно исполнен процессором, но он значительно быстрее, чем исходный код, что уменьшает время интерпретации программы.
Ключевым моментом является то, что Python не выполняет компиляцию в традиционном понимании этого слова. Это важное отличие от статически типизированных языков, где процесс компиляции является обязательным для получения исполнимого файла. В Python компиляция выполняется автоматически при первом запуске, но если код не изменился, интерпретатор будет использовать уже существующий байт-код, что делает выполнение программы более эффективным.
Кроме того, важно учитывать, что Python не выполняет явную оптимизацию кода в процессе компиляции. Это означает, что некоторые оптимизации, такие как агрегация операций или удаление мертвого кода, остаются на усмотрение разработчика или должны быть выполнены на уровне самой программы. Следовательно, для повышения производительности кода на Python необходимо использовать соответствующие подходы, такие как профилирование, анализ производительности и применение специализированных библиотек, например, Cython или PyPy, которые могут ускорить выполнение программы за счет оптимизаций на уровне байт-кода или JIT-компиляции.
Как интерпретатор Python преобразует исходный код в байт-код
Процесс преобразования исходного кода Python в байт-код состоит из нескольких ключевых этапов, на каждом из которых выполняются специфичные задачи. Важно понимать, как именно происходит этот процесс для более глубокого освоения работы с интерпретатором Python.
Когда Python-программа запускается, интерпретатор сначала анализирует исходный код с использованием лексического и синтаксического анализа. На этом этапе код делится на токены, что позволяет строить абстрактное синтаксическое дерево (AST). AST представляет собой структурированное представление кода, где каждый элемент соответствует операции или выражению.
Затем, из полученного AST создается байт-код. Это промежуточное представление кода, которое является низкоуровневым, но все еще платформенно-независимым. Байт-код в Python представляет собой набор инструкций для виртуальной машины Python (PVM), которая непосредственно выполняет этот код.
Для преобразования в байт-код Python использует модуль compile(). Этот процесс не требует компилятора в традиционном смысле, так как Python является интерпретируемым языком, а не полностью скомпилированным. После компиляции в байт-код, интерпретатор выполняет его, передавая инструкции виртуальной машине.
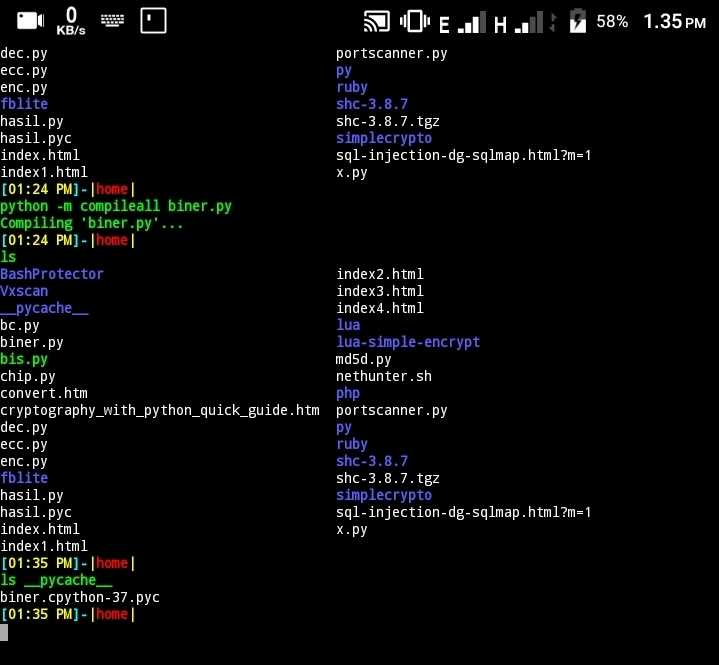
Одним из важных аспектов является то, что Python использует байт-код для ускорения выполнения программ. Когда скрипт запускается впервые, байт-код сохраняется в файлах с расширением .pyc, что позволяет избежать повторной компиляции при следующем запуске программы, если исходный код не изменился.
Байт-код является независимым от операционной системы и архитектуры процессора, что дает Python значительное преимущество в кроссплатформенности. Однако выполнение байт-кода все равно происходит в рамках виртуальной машины, которая обеспечивает дополнительные абстракции и механизмы безопасности.
Таким образом, процесс компиляции в байт-код является важной частью архитектуры Python, позволяя оптимизировать выполнение программ и облегчить переносимость кода между различными системами.
Роль файла.pyc и его связь с производительностью программы
Когда Python скрипт выполняется, интерпретатор сначала компилирует исходный код в байт-код, который сохраняется в файлах с расширением .pyc. Эти файлы находятся в директории __pycache__, и их основная цель – ускорить загрузку и выполнение программ.
При первом запуске Python интерпретирует исходный код, преобразуя его в байт-код, который затем сохраняется в .pyc файле. При последующих запусках, если исходный код не изменился, интерпретатор загружает уже скомпилированный байт-код из .pyc файла. Это избавляет от необходимости повторно компилировать код, что ускоряет запуск программы, особенно при большом объеме исходного кода.
Производительность программы напрямую зависит от наличия .pyc файлов. Без них каждый запуск программы требует дополнительного времени на компиляцию исходного кода. Этот процесс может занять несколько миллисекунд или даже секунд, в зависимости от размера и сложности проекта. Наличие .pyc файлов минимизирует этот временной разрыв и позволяет программе запускаться быстрее.
Кроме того, использование скомпилированных файлов помогает в оптимизации работы интерпретатора. Байт-код, который хранится в .pyc файле, уже отформатирован и готов для выполнения. В результате интерпретатору не нужно тратить время на синтаксический анализ и преобразование кода в промежуточное представление, что сокращает общий цикл выполнения программы.
Тем не менее, важно учитывать, что .pyc файлы не всегда оказывают значительное влияние на производительность, особенно в случае небольших скриптов. Основное улучшение заметно в крупных проектах, где количество файлов и сложность программы существенно увеличивают время на начальную компиляцию.
Для максимальной оптимизации производительности рекомендуется контролировать процесс компиляции и удаления устаревших .pyc файлов, особенно в случаях, когда часто обновляется исходный код. В некоторых случаях может быть полезно использовать параметр -O при компиляции, чтобы генерировать оптимизированные версии байт-кода (с удалением инструкций для отладки), что также положительно сказывается на скорости работы программы.
Как работает Python при запуске программы в интерактивном режиме
Интерактивный режим Python позволяет пользователю запускать код сразу после ввода, что делает процесс разработки и отладки быстрее. Когда вы запускаете Python в интерактивном режиме (например, через команду python в терминале или в REPL-интерфейсе), происходит несколько ключевых этапов обработки кода.
Основные шаги работы Python при запуске программы в интерактивном режиме:
- Запуск интерпретатора Python: При запуске Python в интерактивном режиме загружается интерпретатор, который ждет ввода команд от пользователя. В этот момент интерпретатор создает окружение для работы с кодом, в котором доступны стандартные библиотеки и переменные.
- Чтение команд и выполнение: Каждую введенную строку Python анализирует и немедленно выполняет. В отличие от запуска файла, где код сначала компилируется в байт-код, в интерактивном режиме выполнение происходит по мере ввода. Этот процесс называется анализом и выполнением кода по строкам.
- Преобразование в байт-код: Хотя код выполняется сразу, Python все равно компилирует его в байт-код. Это необходимо для того, чтобы обеспечить интерпретацию и выполнение команд. Для каждой введенной строки Python генерирует соответствующий байт-код, который затем передается виртуальной машине Python для выполнения.
- Использование локальных и глобальных областей видимости: При интерактивном вводе Python управляет двумя основными областями видимости – локальной и глобальной. В глобальной области видимости хранятся все переменные и функции, доступные на уровне сессии. Локальная область видимости используется внутри функций. При выполнении кода в интерактивном режиме переменные и функции сохраняются в глобальной области видимости, что позволяет использовать их на протяжении всей сессии.
- Работа с объектами: В интерактивном режиме Python обрабатывает объекты, как в обычной программе. Например, при создании переменной или объекта класс выполняется через вызов конструктора, а затем объект сохраняется в памяти, доступный для манипуляций в дальнейшем.
Особенности работы в интерактивном режиме Python:
- Не сохраняются данные между сессиями. При закрытии интерпретатора все объекты и переменные теряются.
- При выполнении кода в REPL можно быстро тестировать фрагменты кода, что удобно для отладки или изучения Python.
- Используется динамическая типизация, что позволяет изменять типы данных переменных в процессе работы программы.
Интерактивный режим – это мощный инструмент для разработчиков, обеспечивающий гибкость и скорость работы. Он полезен для выполнения небольших фрагментов кода, проверки гипотез и обучения, но для больших программ лучше использовать скрипты, которые выполняются целиком после компиляции.
Разница между компиляцией в Python и другими языками программирования
Основное отличие компиляции Python от других языков программирования заключается в его интерпретируемом характере. В отличие от C, C++ или Java, где используется традиционная компиляция в машинный код, Python сначала компилируется в байт-код, который затем исполняется интерпретатором. Это означает, что Python не требует предварительной компиляции в машинный код, что ускоряет цикл разработки, но в то же время может снижать производительность по сравнению с скомпилированными языками.
В языках вроде C или C++ весь исходный код преобразуется в исполнимые бинарные файлы с помощью компилятора, и результат компиляции уже не зависит от исходного кода. В случае Python, исходный код компилируется в байт-код (.pyc файлы), но этот процесс не превращает программу в окончательную форму для исполнения. В отличие от компилятора C, интерпретатор Python выполняет байт-код построчно, что позволяет вносить изменения в программу без необходимости пересборки проекта.
Java использует промежуточный этап, похожий на Python, но с отличием: код компилируется в байт-код, который затем исполняется на виртуальной машине Java (JVM). В случае Python байт-код исполняется через интерпретатор CPython, который имеет свою специфику оптимизации, но всё равно требует дополнительного времени на выполнение. Java, благодаря JIT-компиляции (Just-In-Time), может повышать производительность за счёт оптимизации кода на этапе выполнения.
Также стоит отметить, что Python не имеет собственного процесса линковки, как это происходит в C или C++, где компилятор связывает объектные файлы в исполнимый файл. В Python же весь код исполняется динамически и модульная система работает с импортом и загрузкой кода во время исполнения программы. Это позволяет ускорить разработку, но также может привести к большему потреблению памяти и времени на выполнение.
Одним из главных преимуществ Python является его гибкость: при наличии исходного кода, программа может быть изменена и перезапущена без необходимости компиляции. В то время как для языков вроде C или C++, необходимо пройти через процесс компиляции и линковки каждый раз при изменении исходного кода. Эта особенность делает Python особенно подходящим для быстрого прототипирования и сценариев, где время разработки важнее, чем скорость исполнения.
Как оптимизировать скорость старта Python-программы с помощью компиляции
Использование .pyc файлов позволяет ускорить загрузку программы, так как при запуске Python-скрипта интерпретатор может сразу использовать уже скомпилированный байт-код, а не заново компилировать исходный код. Для этого необходимо активировать опцию сохранения байт-кода с помощью параметра python -m py_compile.
Инструменты для оптимизации старта. Существуют альтернативные способы компиляции, такие как использование Cython, который позволяет преобразовывать Python-код в C-расширения. Это значительно ускоряет выполнение кода и сокращает время старта программы. Cython позволяет компилировать Python-код в нативный код, что исключает необходимость интерпретации каждого модуля при запуске.
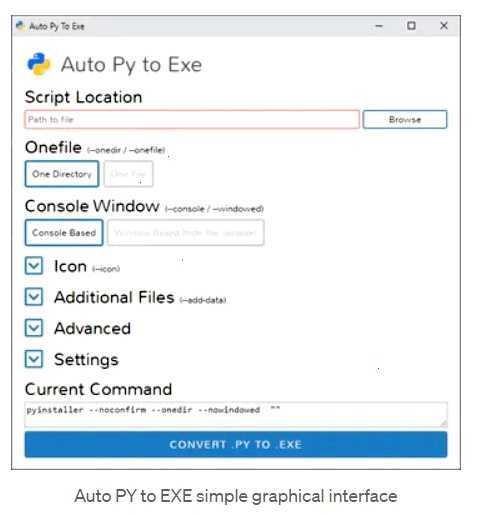
PyInstaller и другие упаковщики также могут ускорить запуск программы. Эти инструменты не только упаковывают Python-программу и её зависимости в один исполнимый файл, но и предварительно компилируют её в байт-код. Это устраняет необходимость в интерпретации исходного кода при запуске, а значит, ускоряет старт.
Использование статической компиляции позволяет дополнительно ускорить выполнение. В некоторых случаях целесообразно использовать библиотеки, которые поддерживают статическую компиляцию, такие как Nuitka. Этот инструмент компилирует Python в нативный код, что исключает накладные расходы, связанные с интерпретацией кода на старте.
Также стоит учитывать методы оптимизации импорта. Один из эффективных способов – минимизация использования «тяжелых» библиотек и импорта ненужных модулей в начальной фазе программы. Компиляция только тех частей кода, которые необходимы для запуска, помогает сократить время старта.
В результате использования перечисленных методов можно значительно уменьшить время, необходимое для старта Python-программы, обеспечив более быстрый отклик и сокращение задержек при запуске сложных приложений.
Как отладить проблемы с компиляцией Python в различных средах
Для эффективной отладки проблем с компиляцией Python важно учитывать, в какой среде происходит выполнение кода. Ошибки могут быть связаны как с неправильными настройками окружения, так и с особенностями компиляции на различных платформах. В зависимости от среды (локальная машина, контейнеры Docker, виртуальные окружения или CI/CD системы), подходы к отладке могут значительно отличаться.
При использовании виртуальных окружений важно убедиться, что в нем установлены все необходимые зависимости. Наиболее частой проблемой является несовместимость версий библиотек или отсутствие некоторых из них. Для выявления таких проблем можно использовать команду pip freeze, чтобы проверить, какие пакеты установлены в окружении. В случае несоответствия версий лучше всего обновить зависимости с помощью pip install -U.
Когда проект работает в контейнере Docker, необходимо обращать внимание на конфигурацию образа и версию Python, указанную в Dockerfile. Часто возникает ситуация, когда на локальной машине работает одна версия Python, а в контейнере – другая. Для диагностики можно использовать команду docker exec -it , чтобы убедиться, что версия Python соответствует требованиям проекта.
Если проблема связана с компиляцией C-расширений, которые часто используются в библиотеке, такой как NumPy или SciPy, стоит проверить наличие необходимых инструментов для компиляции, таких как gcc или make. Эти инструменты могут быть не установлены в минимальных образах Docker или в некоторых операционных системах, таких как Windows. Для установки инструментов на Ubuntu можно воспользоваться командой sudo apt-get install build-essential, а для Windows – установить Visual C++ Build Tools.
В CI/CD системах (например, Jenkins, GitLab CI, CircleCI) важно внимательно следить за конфигурациями окружения и шагами пайплайна. Часто проблемы с компиляцией могут возникать из-за некорректно настроенных переменных окружения, отсутствующих зависимостей или из-за того, что сборка происходит на другом сервере с другой версией Python. Для отладки полезно добавить дополнительные логирование на каждом шаге сборки, чтобы точно выяснить, на каком этапе происходит ошибка.
Особое внимание стоит уделить ошибкам синтаксиса или импорта, которые могут появляться в разных версиях интерпретаторов Python. Для поиска несовместимостей между версиями Python (например, между Python 2.x и 3.x) можно использовать tox или другие инструменты для тестирования в разных версиях интерпретатора. Тестирование на нескольких версиях Python важно для предотвращения ошибок, которые проявляются только в определенной версии.
Если в процессе компиляции возникают ошибки, связанные с отсутствием или несовместимостью зависимостей, полезно использовать virtualenv или conda для управления изолированными окружениями. Это позволяет исключить проблемы с конфликтующими версиями библиотек, которые могут присутствовать в глобальной среде Python.
Для успешной отладки компиляции Python в разных средах ключевым моментом является последовательность шагов: от проверки версий зависимостей и инструментов сборки до корректировки конфигураций окружений и использования инструментов для работы с несколькими версиями интерпретатора. Регулярное обновление зависимостей и настройка окружений позволяют минимизировать ошибки компиляции и повышают стабильность работы приложения в любых средах.
Вопрос-ответ:
Как Python выполняет компиляцию и что важно знать об этом процессе?
Компиляция Python начинается с преобразования исходного кода в байт-код, который Python может выполнить. Этот процесс происходит в несколько этапов. Сначала интерпретатор читает исходный код, а затем создает байт-код — промежуточный формат, который Python использует для выполнения программы. Преимущество такого подхода в том, что байт-код выполняется быстрее, чем исходный текст, но при этом сохраняется гибкость языка. Очень важно понимать, что Python является интерпретируемым языком, и его байт-код не зависит от платформы, на которой выполняется программа. Однако Python выполняет компиляцию только в том случае, если файл был изменен после последней компиляции. Это позволяет ускорить выполнение программ, поскольку не нужно каждый раз перекомпилировать все файлы.
Какой принцип работы компилятора Python влияет на производительность?
Одним из важных факторов является то, что Python использует байт-код, который исполняется на виртуальной машине. Этот подход не требует полной компиляции в машинный код, что сокращает время старта программы. Однако на производительность может повлиять тот факт, что интерпретатор Python выполняет множество операций в реальном времени, а не заранее. Это может быть не так эффективно, как компиляция в машинный код, как в других языках программирования, например, C или C++. Также стоит отметить, что Python не компилирует код в машинный, а оставляет его на уровне байт-кода, что делает программу менее быстрой в сравнении с теми, которые компилируются непосредственно в исполнимые файлы.
Как Python обрабатывает импорт модулей во время компиляции?
Когда Python сталкивается с импортом модуля, он проверяет, был ли этот модуль уже скомпилирован в байт-код. Если да, то используется уже скомпилированная версия, что позволяет избежать повторной компиляции и ускоряет выполнение программы. В случае, если модуль еще не был скомпилирован, Python создает байт-код и сохраняет его в специальный кэш. Это предотвращает повторную компиляцию в будущем. Очень важно, чтобы кэшированный байт-код был актуален, иначе Python может снова компилировать файл, что приведет к дополнительным затратам времени.
Какие ограничения существуют при компиляции Python-кода?
Одним из основных ограничений является то, что Python компилируется в байт-код, а не в машинный код, что снижает его производительность в некоторых случаях, особенно при сложных вычислениях. Еще одним ограничением является зависимость от интерпретатора: разные версии Python могут компилировать и исполнять код немного по-разному. Это может привести к несовместимости между версиями Python. К тому же, несмотря на то, что байт-код ускоряет выполнение программы, он не позволяет достичь той же скорости, как языки, использующие прямую компиляцию в машинный код, что важно при решении задач, требующих высокой производительности, например, в области научных вычислений.