

В Java управление памятью происходит через два основных механизма – heap и stack. Эти области памяти имеют различные цели и способы использования, что критически важно для понимания того, как работает программа и как эффективно управлять ресурсами. В этой статье рассмотрим особенности работы этих двух областей, их различия и ключевые моменты, которые следует учитывать при разработке приложений на Java.
Stack (стек) используется для хранения данных, которые напрямую связаны с выполнением методов: локальные переменные, параметры методов, а также ссылки на объекты, находящиеся в heap. Стек выделяется и освобождается автоматически при вызове и завершении методов. Каждое новое выполнение метода добавляет новый фрейм в стек, который удаляется по мере завершения работы метода. Такой подход гарантирует быстрый доступ к данным и эффективное управление памятью для часто вызываемых функций.
Heap (кучa) в отличие от стека используется для динамического выделения памяти. Когда объект создается с помощью оператора new, он размещается в куче. Это пространство управляется сборщиком мусора, который периодически очищает неиспользуемые объекты, чтобы освободить память. В отличие от стека, где память выделяется и освобождается строго по порядку, объекты в куче могут существовать произвольно долго, что накладывает определенные требования на управление временем жизни этих объектов.
Понимание различий между этими двумя типами памяти позволяет оптимизировать производительность и избежать утечек памяти. Например, чрезмерное использование памяти в куче без должного контроля может привести к замедлению работы программы из-за частых сборок мусора, в то время как избыточное использование стека может привести к переполнению стека, что вызовет ошибки выполнения. Поэтому важно правильно распределять ресурсы между стеком и кучей, учитывая особенности работы Java Virtual Machine (JVM) и характер задачи.
Heap и stack память в Java: как они работают
В Java память управляется через два основных региона: стек (stack) и кучу (heap). Каждый из этих регионов используется для разных целей и имеет свои особенности в управлении памятью, что важно для производительности и оптимизации работы программы.
Стек (stack) используется для хранения локальных переменных и информации о вызовах методов. Когда метод вызывается, в стек помещается фрейм (stack frame), который включает в себя локальные переменные и адрес возврата. Этот фрейм удаляется, когда метод завершает выполнение. Стек работает по принципу LIFO (Last In, First Out), что означает, что последний добавленный элемент будет первым удалён.
Стек имеет ограниченный размер, который задаётся JVM при запуске программы. Из-за этого может возникнуть ошибка переполнения стека (stack overflow), если программа использует слишком много памяти для локальных переменных или рекурсивных вызовов. В отличие от кучи, стек является высокоскоростным и быстрым по своей природе.
Куча (heap) используется для динамического выделения памяти, например, для объектов, создаваемых с помощью оператора new. Все объекты в Java находятся в куче, и они управляются сборщиком мусора (Garbage Collector). Когда объект больше не нужен, сборщик мусора освобождает память, занятую этим объектом. В отличие от стека, куча имеет гораздо больший объём памяти, но доступ к ней медленнее.
В отличие от стека, объекты в куче могут пережить вызовы методов и быть доступны из разных частей программы. Однако неправильное управление кучей может привести к утечкам памяти, если ссылки на объекты не обнуляются, и сборщик мусора не может освободить память.
Рекомендации по использованию памяти:
- Используйте стек для хранения данных, которые не требуют длительного существования, таких как параметры метода и временные данные.
- Старайтесь минимизировать использование рекурсии, так как каждый рекурсивный вызов использует новый фрейм в стеке.
- Для долгоживущих объектов используйте кучу, но следите за тем, чтобы объекты не оставались в памяти без надобности (правильное управление ссылками).
- Для уменьшения вероятности утечек памяти контролируйте объекты в куче и освобождайте их, когда они становятся ненужными.
Таким образом, стек и куча имеют разные назначения и важны для эффективной работы Java-программ. Стек быстро управляет памятью для локальных данных, в то время как куча предоставляет более гибкое, но менее быстрое пространство для долгоживущих объектов. Понимание того, как и когда использовать каждый из этих типов памяти, критично для написания производительных и безопасных приложений на Java.
Как работает стек в Java и зачем он нужен?
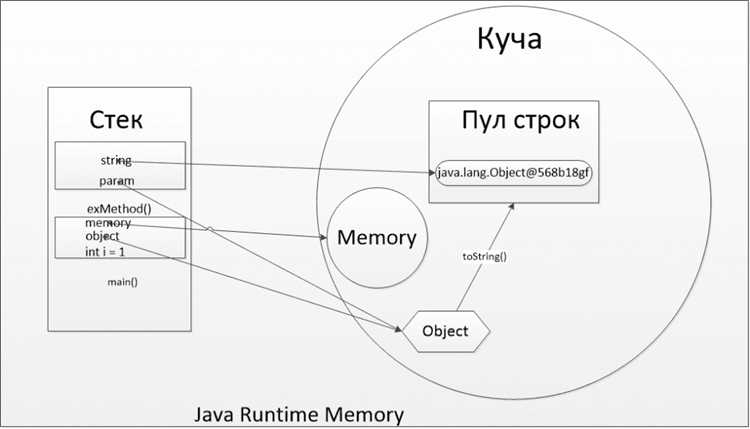
Стек в Java используется для хранения локальных переменных и информации о состоянии выполнения метода. Каждый раз, когда вызывается метод, в стек добавляется новый фрейм (структура данных, представляющая состояние метода). Этот фрейм включает в себя локальные переменные и параметры метода, а также адрес возврата, который указывает, куда нужно вернуться после завершения выполнения метода.
Когда метод завершает свою работу, его фрейм удаляется из стека, и управление передается обратно на адрес, указанный в фрейме. Это позволяет стеку работать по принципу «последним вошел – первым вышел» (LIFO), где каждый новый вызов метода добавляет элемент в стек, а завершение метода удаляет его.
Стек является эффективной областью памяти, поскольку операции добавления и удаления фреймов происходят очень быстро. В отличие от heap-памяти, которая используется для динамического выделения памяти и требует дополнительных операций для управления памятью, стек автоматически освобождает память по мере завершения работы методов. Это снижает риск утечек памяти и делает работу с памятью более предсказуемой.
Основное ограничение стека – его размер. Если приложение вызывает слишком много методов или слишком глубокие рекурсии, стек может переполниться, что приведет к ошибке StackOverflowError. Поэтому важно учитывать глубину рекурсии и количество одновременных вызовов методов, особенно в случае работы с большими объемами данных или сложными алгоритмами.
Стек в Java необходим для эффективной работы многозадачности. Каждый поток в Java имеет свой собственный стек, что позволяет обеспечить независимость и изоляцию данных между потоками. Это упрощает разработку многозадачных приложений и снижает вероятность ошибок при параллельной обработке.
Разница между стековой и кучевой памятью в Java
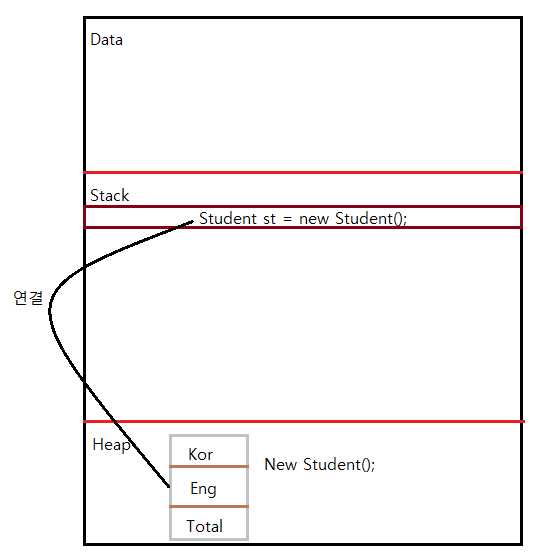
В Java стек и куча выполняют разные функции в управлении памятью. Стек используется для хранения примитивных типов данных и ссылок на объекты, а куча – для самих объектов, создаваемых в процессе работы программы. Эти два типа памяти отличаются по принципу выделения, срокам жизни данных и области использования.
Стековая память ограничена и управляется по принципу LIFO (Last In, First Out). Каждый метод, вызванный в программе, создает свой фрейм в стеке, в котором хранятся локальные переменные и ссылки на объекты. Когда метод завершает выполнение, его фрейм уничтожается, и память освобождается автоматически. Этот процесс очень быстрый, но стек ограничен в размере, что может привести к ошибке переполнения стека (StackOverflowError) при глубокой рекурсии.
Кучевая память, в свою очередь, используется для динамического выделения памяти для объектов, создаваемых через операторы new. Куча значительно более гибкая по сравнению со стеком, так как не ограничена количеством вызовов методов. Однако объекты в куче остаются в памяти до тех пор, пока на них не перестанут ссылаться, после чего они могут быть удалены сборщиком мусора (Garbage Collector). Это делает управление кучей менее предсказуемым и более затратным по времени, поскольку сборка мусора требует дополнительных ресурсов.
Основное различие между этими типами памяти заключается в области жизни данных. Стек управляется автоматически, его размер ограничен и зависит от размера стека потока. Куча же гораздо более динамична, позволяя создавать объекты разных размеров, но требует внимательного управления памятью и может привести к утечкам памяти, если ссылки на объекты не будут правильно освобождены.
Важно учитывать, что операции в стеке быстрее, так как доступ к данным осуществляется за постоянное время. В куче доступ может быть медленнее из-за необходимости управления динамической памятью и проведения сборки мусора. Рекомендуется минимизировать количество данных, хранимых в куче, и использовать стек для временных объектов, а также помнить о возможности утечек памяти в случае ненадлежащего управления кучей.
Что происходит при выделении памяти в стеке и куче?
При выделении памяти в стеке и куче происходят различные процессы, обусловленные архитектурными особенностями каждой области памяти. Стек работает по принципу LIFO (последним пришел – первым вышел), что означает, что память выделяется и освобождается по мере выполнения методов. Каждый метод, вызываемый в программе, создает новый фрейм в стеке, который содержит локальные переменные, параметры метода и данные для возврата. Стек ограничен по размеру и имеет фиксированное место в памяти, что делает его быстрым для операций, но при этом риск возникновения переполнения стека (StackOverflowError) велик при глубоком рекурсивном вызове или при создании слишком больших локальных данных.
Куча, в свою очередь, представляет собой область памяти для динамического выделения, где хранится информация о созданных объектах. Каждый объект, который создается с помощью оператора `new` в Java, выделяется в куче. Куча значительно более гибкая и может расти по мере необходимости, но операции с кучей медленнее, поскольку она требует работы сборщика мусора для управления памятью. Объекты в куче существуют до тех пор, пока на них есть ссылки, после чего они могут быть уничтожены при сборке мусора. Это делает работу с кучей менее предсказуемой в плане времени, но зато более гибкой по сравнению с памятью стека.
При выделении памяти в стеке операция происходит мгновенно: система просто увеличивает указатель стека. Освобождение памяти также происходит автоматически при выходе из области видимости метода. В куче выделение памяти может занять больше времени, так как система должна найти свободное место для нового объекта. Освобождение памяти в куче происходит только через сборщик мусора, который может освободить память в любое время, что делает освобождение ресурсов менее предсказуемым.
Для оптимизации использования памяти важно понимать различие между этими областями. Если данные, с которыми работает программа, имеют фиксированный и ограниченный размер, предпочтительнее использовать стек. Это гарантирует быстрый доступ и освобождение памяти. Для объектов, которые должны существовать длительное время или имеют переменный размер, необходимо использовать кучу. Важно следить за тем, чтобы не создавать чрезмерное количество объектов или не забывать ссылки на ненужные объекты, чтобы избежать утечек памяти.
Как сборщик мусора управляет кучей в Java?
Куча в Java разделена на несколько областей: Young Generation, Old Generation и Permanent Generation (для старых версий JVM) или Metaspace (для новых версий). Каждая из этих областей требует особого подхода при управлении мусором.
Young Generation – это область, где создаются новые объекты. Она разделена на три части: Eden Space и два Survivor Space. Когда объекты только создаются, они размещаются в Eden. После каждого цикла GC объекты, выжившие в Eden, перемещаются в одну из Survivor областей, а затем, если они остаются живыми, переходят в Old Generation.
Old Generation хранит объекты, которые «пережили» несколько сборок мусора в Young Generation. Сборка мусора в этой области происходит реже, но более затратно, так как объекты, которые были в памяти долго, обычно занимают много места и могут быть связаны с другими объектами. Когда Old Generation заполняется, запускается Full GC.
Metaspace (вместо Permanent Generation в современных версиях JVM) используется для хранения метаданных классов. Эта область может динамически расширяться в зависимости от потребностей приложения, что помогает избежать проблем с ограничением размера Permanent Generation, которое было в старых версиях JVM.
Сборщик мусора использует несколько алгоритмов для управления кучей: Mark-and-Sweep, Generational Garbage Collection и Reference Counting.
Mark-and-Sweep – это основной алгоритм, используемый в большинстве современных JVM. Он состоит из двух фаз: в первой фазе все объекты помечаются, которые доступны через корневые ссылки, во второй – те, которые не были помечены, удаляются.
Generational Garbage Collection эффективно использует принцип, что большинство объектов имеют короткий срок жизни. Объекты, созданные недавно, размещаются в Young Generation, и GC быстро удаляет те, которые не пережили несколько сборок мусора. Старые объекты перемещаются в Old Generation, где сборка мусора происходит реже.
Reference Counting – менее распространенный метод, который отслеживает количество ссылок на объект. Когда количество ссылок на объект становится равным нулю, объект можно удалить. Однако этот метод страдает от проблем с циклическими ссылками, что ограничивает его использование в Java.
В Java работа сборщика мусора происходит на фоне выполнения программы, и обычно программист не контролирует этот процесс. Однако есть способы настроить сборщик мусора, используя флаги JVM, такие как -Xms, -Xmx, которые управляют размером кучи, а также флаги для выбора конкретного алгоритма сборки мусора.
Важно помнить, что эффективность работы сборщика мусора зависит от конфигурации JVM и типа приложения. Для высоконагруженных приложений может потребоваться настройка стратегии сборки мусора, чтобы минимизировать задержки, вызванные процессом уборки мусора.
Влияние размера стека на производительность приложений Java
Размер стека в Java определяет максимальное количество памяти, которое может быть выделено для вызовов методов и хранения локальных переменных. Этот параметр имеет прямое влияние на производительность, особенно в приложениях с глубокими рекурсиями или большим количеством потоков.
Маленький размер стека может привести к частым ошибкам StackOverflowError. Такие ошибки происходят, когда стек не может выделить достаточно памяти для выполнения метода. Например, при глубокой рекурсии или большом количестве вложенных вызовов метод может выйти за пределы выделенного стека, что вызовет сбой приложения. Это существенно влияет на стабильность работы программы, особенно в многозадачных приложениях.
С другой стороны, слишком большой размер стека увеличивает потребление памяти, что также может сказаться на производительности. Каждое выделение памяти для потока требует значительных системных ресурсов. Для многозадачных приложений это может стать проблемой, если количество потоков велико. Например, при увеличении стека на 1 МБ, система может быть не в состоянии эффективно управлять большим количеством потоков, что приведет к уменьшению общей производительности.
Оптимальный размер стека зависит от конкретных задач. Для стандартных многозадачных приложений достаточно стека размером 256-512 КБ. Для приложений с интенсивной рекурсией или специализированных задач, таких как алгоритмы обработки больших данных, можно увеличить размер стека до 1-2 МБ. Однако увеличивать размер стека следует осторожно, чтобы не вызвать чрезмерное потребление памяти, что может привести к замедлению работы всего приложения.
Параметр стека можно настроить при запуске Java-программы с помощью опции -Xss. Это позволяет найти баланс между необходимым количеством памяти для рекурсии и стабильностью приложения. Например, для уменьшения вероятности ошибок StackOverflowError в приложении с глубокой рекурсией можно установить параметр -Xss1m, что задаст размер стека в 1 МБ. Но для потоков, не использующих рекурсию, может быть достаточно меньшего значения.
Кроме того, важно учитывать, что при увеличении размера стека для одного потока, общая память, доступная для системы, уменьшается, что может привести к дефициту памяти при запуске большого числа потоков. Поэтому необходимо провести тестирование и мониторинг, чтобы определить оптимальные параметры стека в зависимости от специфики работы приложения.
Как избежать переполнения стека в Java?
Переполнение стека в Java происходит, когда размер стека вызовов превышает доступную память. Это может привести к ошибке StackOverflowError, особенно при работе с рекурсией. Вот несколько методов для предотвращения этой проблемы.
- Ограничение глубины рекурсии: При проектировании алгоритмов с использованием рекурсии важно учитывать ограничение глубины рекурсивных вызовов. Рекомендуется всегда проверять условия выхода из рекурсии, чтобы избежать бесконечного вызова.
- Использование итераций вместо рекурсии: Если алгоритм позволяет, замените рекурсию на цикл. Это устранит риски переполнения стека, поскольку итеративные решения используют память кучи, а не стека.
- Понимание размера стека: В JVM можно настроить размер стека с помощью параметра
-Xss. При необходимости увеличьте его, чтобы предотвратить переполнение в случае сложных рекурсивных алгоритмов. - Использование хвостовой рекурсии: В Java JVM не поддерживает оптимизацию хвостовой рекурсии, но если ваш алгоритм использует хвостовую рекурсию, это может быть полезно в других языках, где такая оптимизация есть. В Java такие алгоритмы всё равно будут использовать стек.
- Оптимизация алгоритмов: Переходите к более эффективным алгоритмам, которые используют меньше рекурсивных вызовов, или разделяйте задачу на более мелкие части. Например, вместо одного большого рекурсивного вызова разбивайте его на несколько более простых.
- Использование очередей и стеков в памяти кучи: Если задача требует работы с большим количеством данных, переместите их в структуру данных, которая использует кучу (например, очередь), чтобы не перегружать стек вызовов.
Применение этих рекомендаций позволит эффективно управлять памятью стека и избежать ошибок переполнения при разработке на Java.
Как управление памятью в стеке влияет на многозадачность в Java?

В Java многозадачность реализована с использованием потоков, и каждый поток имеет свой собственный стек. Стек используется для хранения локальных переменных и информации о вызовах методов. Управление памятью в стеке напрямую влияет на производительность многозадачных приложений, так как операции с памятью в стеке выполняются быстро и не требуют сложной синхронизации.
Основные аспекты, которые стоит учитывать:
- Изоляция потоков: Каждый поток в Java имеет отдельный стек, что позволяет избежать конфликтов при работе с локальными переменными. Это снижает вероятность возникновения состояний гонки и блокировок, которые могут повлиять на производительность многозадачных приложений.
- Быстрое выделение памяти: Операции выделения и освобождения памяти в стеке происходят быстро благодаря его LIFO (Last In, First Out) структуре. Это делает стеки идеальными для многозадачности, где требуется быстрое создание и уничтожение потоков.
- Ограничение по размеру стека: Размер стека для каждого потока ограничен, и при его превышении может возникнуть ошибка переполнения стека (StackOverflowError). Это важно учитывать при проектировании многозадачных приложений, особенно если потоки выполняют сложные вычисления или имеют глубокую рекурсию.
Для оптимизации использования стека в многозадачных приложениях рекомендуется:
- Настроить размер стека в зависимости от характера работы потоков. Например, для потоков с небольшим объемом локальных данных можно уменьшить размер стека, чтобы избежать переполнения при большом количестве потоков.
- Избегать глубокой рекурсии, так как это может быстро привести к переполнению стека, особенно при большом количестве одновременно работающих потоков.
- Использовать неблокирующие структуры данных и алгоритмы, чтобы минимизировать время, которое потоки проводят в заблокированном состоянии, и ускорить обработку данных.
Управление стеком в многозадачной среде Java позволяет эффективно использовать ресурсы, но важно тщательно контролировать его размеры и правильное распределение памяти для каждого потока, чтобы избежать проблем с производительностью и стабильностью.
Риски и ошибки при работе с кучей и стеком в Java
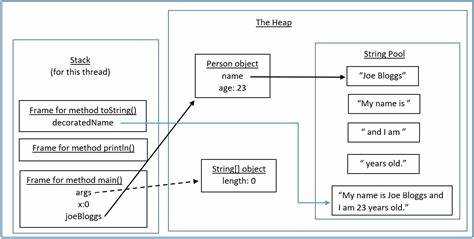
Основные ошибки при работе с памятью в Java часто связаны с управлением кучей и стеком. Эти две области памяти имеют разные цели и ограничения, что может приводить к проблемам, если их не учитывать. Наиболее распространенные риски включают переполнение стека, утечки памяти, неправильное использование ссылок и неэффективное распределение ресурсов.
Переполнение стека – это одна из самых частых ошибок, возникающих из-за слишком глубоких рекурсий. Стек памяти ограничен и, если рекурсия не имеет корректного выхода или слишком много уровней вызовов, может произойти StackOverflowError. Чтобы избежать этого, следует оптимизировать рекурсивные функции или заменить их на итеративные подходы, если это возможно. Использование tail-recursion или увеличение максимального размера стека также могут помочь, но это не всегда решает проблему в долгосрочной перспективе.
Утечки памяти, возникающие при работе с кучей, становятся серьезной проблемой, когда объект, больше не используемый, все еще остается доступным через ссылку. Это может привести к тому, что сборщик мусора не освободит память, так как считает объект все еще живым. Чтобы избежать утечек, важно внимательно следить за временем жизни объектов, использовать weak-ссылки для кэширования и регулярно профилировать приложение для выявления ненужных ссылок, удерживающих память.
Неэффективное использование кучи также может привести к частым сборкам мусора, которые, в свою очередь, замедляют выполнение программы. Для этого важно оптимизировать создание и удаление объектов, избегать создания временных объектов в горячих участках кода и использовать пул объектов для часто создаваемых экземпляров. Также стоит следить за размерами и настройками кучи (например, через параметры JVM), чтобы избежать чрезмерного использования памяти и частых пауз на сборку мусора.
Неправильное управление ссылками – еще одна ошибка, которую можно часто встретить в приложениях на Java. Например, если объект сохраняется в коллекции или контейнере, который не освобождает память после его удаления, это приводит к накоплению неиспользуемых объектов и утечкам. Для минимизации таких ошибок важно следить за жизненным циклом объектов, использовать инструменты для анализа памяти, такие как профайлеры, и избегать долгоживущих ссылок на временные объекты.
Наконец, важно понимать, что оптимизация работы с памятью в Java не сводится к простому увеличению размера кучи или стека. Необходимо учитывать конкретные требования приложения, такие как время отклика, нагрузка на систему и особенности сборщика мусора. Понимание этих аспектов позволяет эффективно управлять памятью и минимизировать риски, связанные с ее исчерпанием или перераспределением.





