Строка, содержащая данные в виде пар ключ–значение, может быть преобразована в словарь различными способами. В простейшем случае, если структура строки соответствует формату JSON, используется функция json.loads() из стандартного модуля json. Например, строка ‘{«ключ»: «значение», «число»: 42}’ после преобразования возвращает словарь с двумя элементами. При этом важно учитывать корректность синтаксиса: одинарные кавычки необходимо заменить на двойные, иначе произойдёт исключение json.decoder.JSONDecodeError.
Если строка не соответствует JSON, но содержит разделители, можно использовать split() и dict() в комбинации. Пример: строка вида ‘ключ1=значение1;ключ2=значение2’ сначала разбивается по ‘;’, затем каждая пара – по ‘=’. Результатом будет список пар, из которого создаётся словарь. Такой метод требует предварительной проверки на наличие пустых элементов и корректного количества разделителей в каждой паре.
Для более сложных шаблонов используется регулярное выражение через модуль re. Это особенно полезно, если данные в строке неформализованы или содержат вложенные структуры. Пример: извлечение всех пар вида key:value с последующим приведением типов. При этом может потребоваться ручная обработка значений, если они представляют собой числа, булевы значения или вложенные списки.
При преобразовании строки в словарь важно учитывать не только формат данных, но и требования к безопасности. Использование eval() категорически не рекомендуется при обработке внешнего ввода, так как оно выполняет произвольный код. Альтернатива – функция ast.literal_eval() из модуля ast, которая безопасно интерпретирует строку, содержащую Python-литералы.
Как превратить строку формата JSON в словарь с помощью json.loads()

Функция json.loads() из модуля json принимает строку, содержащую корректный JSON, и возвращает объект Python, чаще всего – словарь. Перед использованием необходимо убедиться, что строка соответствует требованиям формата: двойные кавычки, допустимые типы значений (числа, строки, списки, логические значения, null).
Пример корректной строки:
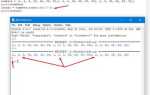
import json
data = '{"имя": "Алиса", "возраст": 30, "активен": true}'
результат = json.loads(data)
print(результат)
# {'имя': 'Алиса', 'возраст': 30, 'активен': True}
Типичные ошибки:
- Использование одинарных кавычек вместо двойных
- Отсутствие кавычек вокруг ключей
- Применение
True,False,Noneвместоtrue,false,null
Чтобы избежать сбоев, перед десериализацией стоит валидировать JSON. Если структура нестабильна, оберните вызов json.loads() в блок try-except:
try:
результат = json.loads(строка)
except json.JSONDecodeError as e:
print(f"Ошибка разбора JSON: {e}")
При работе с кодировками следует убедиться, что строка в формате UTF-8. Если полученные данные – это байтовая строка, её нужно декодировать:
строка = байты.decode("utf-8")
результат = json.loads(строка)
Функция json.loads() – надёжный инструмент при условии строгого соответствия входной строки спецификации JSON. Несоответствие приводит к исключениям, поэтому проверка входных данных критична.
Разбор строки с ключами и значениями, разделёнными символами

Если строка содержит пары вида ключ=значение, разделённые, например, запятыми, её можно преобразовать в словарь с использованием методов split() и генератора словаря. Пример:
s = "name=Иван,age=30,city=Москва"
Для преобразования:
result = dict(pair.split('=') for pair in s.split(','))
При наличии пробелов стоит применить strip() к каждой части:
result = dict(pair.strip().split('=') for pair in s.split(','))
Если в значениях могут встречаться символы-разделители, используйте split(‘=’, 1), чтобы избежать разбиения по всем вхождениям:
result = dict(pair.strip().split('=', 1) for pair in s.split(','))
При нестандартных разделителях (например, ; и :) подход адаптируется аналогично:
s = "user:admin;pass:1234;active:yes"
result = dict(pair.strip().split(':', 1) for pair in s.split(';'))
Если структура строки непредсказуема, рекомендуется предварительно проверить наличие нужных символов и количество частей после разделения:
result = {}
for pair in s.split(','):
if '=' in pair:
key_value = pair.split('=', 1)
if len(key_value) == 2:
key, value = key_value
result[key.strip()] = value.strip()
Такой подход защищает от ошибок при повреждённой или неполной строке.
Преобразование строки, полученной из запроса, в словарь через urllib.parse

Для разбора строки параметров запроса удобно использовать функцию urllib.parse.parse_qs. Она принимает строку вида «key1=value1&key2=value2» и возвращает словарь, где каждому ключу соответствует список значений.
Пример:
from urllib.parse import parse_qs
query_string = "name=ivan&age=30&hobby=reading&hobby=traveling"
result = parse_qs(query_string)
print(result)
Результат:
{'name': ['ivan'], 'age': ['30'], 'hobby': ['reading', 'traveling']}Чтобы извлечь одиночные значения без списков, используется словарное выражение:
flat_result = {k: v[0] if len(v) == 1 else v for k, v in result.items()}
Если требуется учесть декодирование символов (например, «%20» в пробел), используйте предварительно urllib.parse.unquote:
from urllib.parse import unquote
decoded = unquote(query_string)
parsed = parse_qs(decoded)
Для извлечения параметров из полного URL, включая путь, применяют urllib.parse.urlparse:
from urllib.parse import urlparse
url = "https://example.com/search?q=python&lang=ru"
parsed_url = urlparse(url)
params = parse_qs(parsed_url.query)
Функции модуля urllib.parse не требуют установки и работают во всех версиях Python 3. Их поведение предсказуемо: все значения – списки, дублирующиеся параметры группируются, порядок сохраняется.
Использование ast.literal_eval для парсинга словаря из строки
Модуль ast предоставляет функцию literal_eval(), которая безопасно преобразует строковое представление литералов Python в соответствующие объекты. В отличие от eval(), literal_eval() не исполняет произвольный код, что исключает возможность выполнения вредоносных конструкций.
- Импорт модуля:
from ast import literal_eval - Ожидаемый формат строки: валидное представление словаря, как например
"{'ключ': 1, 'значение': [1, 2, 3]}" - Недопустимые элементы: выражения, функции, операторы – всё, что не является литералом Python
Пример использования:
from ast import literal_eval
строка = "{'a': 1, 'b': [10, 20]}"
словарь = literal_eval(строка)
print(словарь['b'][1]) # 20
Если строка содержит синтаксическую ошибку или недопустимые элементы, literal_eval() выбрасывает ValueError или SyntaxError. Это поведение позволяет выявлять некорректный ввод на раннем этапе.
- Использовать
literal_eval()только с полностью контролируемыми строками - Перед вызовом функции рекомендуется удостовериться, что строка начинается и заканчивается фигурными скобками
- Для вложенных структур (списки, кортежи, словари)
literal_eval()сохраняет все типы данных
Этот метод особенно применим в случаях, когда словарь сериализован в строку вручную или получен из текстового файла без формального формата (например, JSON).
Обработка строк с вложенными структурами словарей
Если строка содержит сериализованные данные с вложенными словарями, использовать ast.literal_eval() предпочтительнее, чем eval(), поскольку он безопаснее и корректно обрабатывает вложенные структуры:
from ast import literal_eval
data = literal_eval('{"user": {"id": 1, "name": "Анна"}, "active": true}')
При наличии булевых значений в формате JSON (true, false), но в строке Python, literal_eval() выдаст ошибку. В этом случае строку нужно адаптировать, заменив true и false на True и False:
import re
raw = '{"user": {"id": 1, "name": "Анна"}, "active": true}'
normalized = re.sub(r'\btrue\b', 'True', raw)
data = literal_eval(normalized)
Если строка соответствует формату JSON, использовать json.loads() предпочтительнее:
import json
raw = '{"user": {"id": 1, "name": "Анна"}, "active": true}'
data = json.loads(raw)
При вложенности на несколько уровней важно проверить, что все кавычки – двойные, иначе json.loads() выдаст исключение. Для строк с одинарными кавычками применима предварительная замена:
raw = raw.replace("'", '"')
data = json.loads(raw)
Если вложенные словари передаются с экранированными кавычками, используйте двойную десериализацию:
raw = '{"config": "{\\"mode\\": \\"auto\\", \\"retry\\": 3}"}'
outer = json.loads(raw)
inner = json.loads(outer["config"])
При автоматической обработке входящих строк разумно реализовать проверку на корректность через try-except с логированием ошибок на каждом этапе десериализации, особенно при глубоко вложенных структурах.
Преобразование строки, содержащей пары ключ=значение, в словарь
В Python преобразование строки с парами «ключ=значение» в словарь может быть выполнено несколькими способами. Основная цель – правильно извлечь ключи и значения, разделяя их, и сформировать из этого стандартный словарь. Рассмотрим различные подходы.
Предположим, что у нас есть строка:
'a=1,b=2,c=3'
Использование метода split() для разбивки строки
Простейший способ – использовать метод split(), чтобы разделить строку по разделителю (например, запятая), а затем преобразовать каждый элемент в пару ключ-значение.
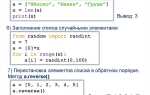
input_str = 'a=1,b=2,c=3'
pairs = input_str.split(',')
result = {k: v for k, v in (pair.split('=') for pair in pairs)}
print(result)
В данном примере сначала строка делится на подстроки по запятой, затем каждая подстрока разделяется на ключ и значение. Результатом является словарь:
{'a': '1', 'b': '2', 'c': '3'}
Использование функции map() для преобразования
Другим способом является использование функции map(), которая применяет заданную функцию к каждому элементу строки.
input_str = 'a=1,b=2,c=3'
result = dict(map(lambda x: x.split('='), input_str.split(',')))
print(result)
Этот метод также делит строку на пары и преобразует их в словарь. Результат аналогичен первому примеру.
Особенности работы с типами данных
При извлечении значений важно учитывать, что они изначально будут строками. Если нужно преобразовать их в числовые типы (например, в целые числа), это можно сделать с помощью int() или других соответствующих функций:
input_str = 'a=1,b=2,c=3'
result = {k: int(v) for k, v in (pair.split('=') for pair in input_str.split(','))}
print(result)
Это преобразует все значения в целые числа, и результат будет:
{'a': 1, 'b': 2, 'c': 3}
Работа с некорректными данными
При обработке строк важно учитывать возможные ошибки в данных, такие как отсутствие символа «=» или наличие лишних пробелов. В таких случаях можно добавить дополнительные проверки:
input_str = 'a=1, b=2, c=3'
pairs = input_str.split(',')
result = {}
for pair in pairs:
if '=' in pair:
k, v = pair.split('=')
result[k.strip()] = v.strip()
print(result)
Этот код обеспечит корректную обработку строк с пробелами вокруг символа «=» и других потенциальных проблем.
Разбор строки с множественными значениями по одному ключу
Когда в строке несколько значений, относящихся к одному ключу, необходимо учесть их правильное разделение и организацию в словарь. Примером может быть строка, где значения связаны запятыми или другими разделителями. В таких случаях используется метод split(), чтобы выделить каждое отдельное значение, а затем оно добавляется в список или другой подходящий контейнер.
Предположим, есть строка, где ключ и несколько значений разделены двоеточием, а сами значения – запятыми: "ключ:значение1,значение2,значение3". В Python можно использовать следующий код для преобразования этой строки в словарь:
input_str = "ключ:значение1,значение2,значение3"
key, values = input_str.split(":")
value_list = values.split(",")
result_dict = {key: value_list}
print(result_dict)Этот код разделяет строку по двоеточию, а затем каждое значение по запятой. Полученная структура будет выглядеть так:
{"ключ": ["значение1", "значение2", "значение3"]}Если в исходной строке присутствует несколько таких пар, можно использовать цикл для обработки каждого элемента:
input_list = ["ключ1:значение1,значение2", "ключ2:значение3,значение4"]
result_dict = {}
for item in input_list:
key, values = item.split(":")
result_dict[key] = values.split(",")
print(result_dict)Результатом будет словарь, в котором каждому ключу соответствуют списки значений:
{"ключ1": ["значение1", "значение2"], "ключ2": ["значение3", "значение4"]}Если необходимо работать с более сложными разделителями или строками с ошибками, следует использовать дополнительные методы обработки исключений или регулярные выражения для более гибкого подхода.
Как избежать ошибок при преобразовании строки с неподходящим форматом
При преобразовании строки в словарь в Python важно соблюдать строгие требования к формату данных. Частые ошибки возникают, если строка не соответствует ожидаемой структуре. Чтобы избежать подобных проблем, нужно заранее проверять и корректировать формат строки.
1. Проверьте наличие правильных кавычек. Если строка представлена в формате JSON, обязательно используйте двойные кавычки для ключей и строковых значений. Однотипные кавычки (одинарные вместо двойных) могут привести к синтаксическим ошибкам при попытке конвертировать строку с помощью json.loads().
2. Убедитесь, что элементы разделены запятой. Ошибка часто возникает, когда ключи и значения не отделены друг от друга или отсутствуют необходимые разделители, такие как запятая. Проверьте, чтобы все элементы были правильно оформлены и не допускались лишние пробелы между элементами.
3. Используйте проверку на ошибки с помощью try-except. Это позволяет отлавливать исключения, если строка имеет неправильный формат, и избегать необработанных ошибок. Пример использования:
import json
try:
my_dict = json.loads(my_string)
except json.JSONDecodeError:
print("Ошибка формата строки")
4. Если строка содержит нестандартные символы или ошибки в форматировании, стоит провести предварительную очистку. Например, можно использовать регулярные выражения для удаления лишних пробелов или символов.
5. Перед конвертацией строки в словарь можно попытаться распарсить ее вручную с использованием методов строки. Например, заменив неверные символы или преобразовав формат разделителей (например, заменить двоеточие на запятую в случае ошибок).
6. Для сложных или вложенных структур данных, таких как списки внутри словарей, следует убедиться, что структура в строке не нарушена и вложенные элементы правильно разделены. Дополнительная проверка и рекурсивный анализ таких данных минимизируют риски ошибок.
Вопрос-ответ:
Как преобразовать строку в словарь в Python?
В Python преобразование строки в словарь можно выполнить с помощью функции `eval()`, если строка представляет собой корректное выражение словаря, например: `»{‘ключ’: ‘значение’}»`. Однако стоит быть осторожным, поскольку использование `eval()` может привести к уязвимостям в программе, если строка поступает от ненадежного источника. Альтернативой является использование метода `json.loads()`, если строка представляет собой валидный JSON, например: `'{«ключ»: «значение»}’`. В этом случае результатом будет словарь.
Можно ли использовать другие способы преобразования строки в словарь без применения `eval()`?
Да, для безопасного преобразования строки в словарь можно использовать библиотеку `json`. Если строка соответствует формату JSON, метод `json.loads()` корректно преобразует строку в словарь. Например: `json.loads(‘{«ключ»: «значение»}’)`. Это гораздо безопаснее, чем использование `eval()`, так как JSON не поддерживает выполнение произвольного кода.
Что делать, если строка не соответствует формату JSON, но нужно извлечь из неё данные в виде словаря?
Если строка не соответствует стандарту JSON, но её можно интерпретировать как данные в виде пар «ключ-значение», то можно воспользоваться регулярными выражениями или методами обработки строк для создания словаря вручную. Например, если строка выглядит так: `’ключ1: значение1, ключ2: значение2’`, можно разделить её на части и преобразовать в словарь. Для этого можно использовать метод `split()` и цикл для добавления пар в словарь.
Какие ограничения существуют при преобразовании строки в словарь?
Ограничения зависят от формата исходной строки. Если строка представляет собой некорректный JSON или неверно отформатированное выражение словаря, то преобразование в словарь не будет возможным без предварительной обработки данных. Также использование метода `eval()` небезопасно, если строка поступает из ненадёжных источников, так как это может привести к выполнению вредоносного кода.
Есть ли альтернатива `eval()` для преобразования строк в словарь, если структура строки сложная?
Если структура строки сложная, и она не соответствует стандарту JSON, то можно использовать методы парсинга данных, такие как регулярные выражения. Для сложных случаев часто применяют парсеры, которые могут извлечь пары «ключ-значение» и преобразовать их в словарь. Также можно рассмотреть написание собственного парсера для специфического формата строки, если это необходимо для решения задачи.