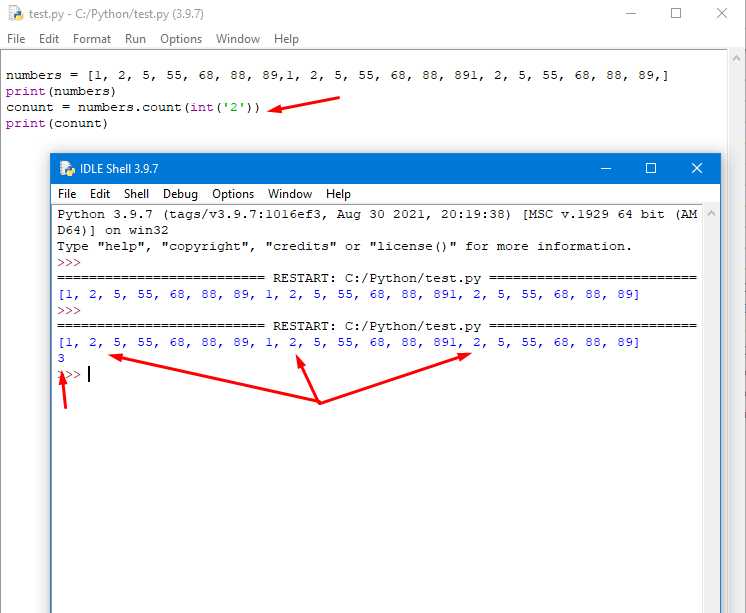
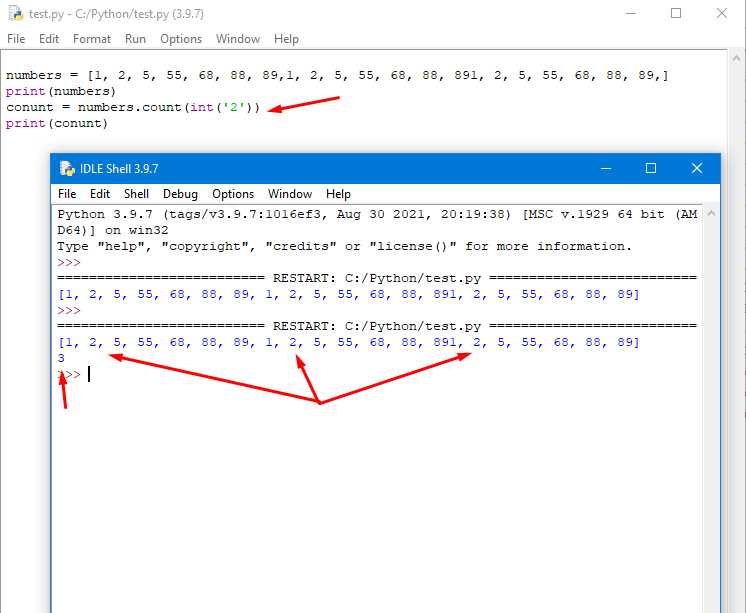
В языке Python часто возникает необходимость подсчета количества вхождений определенных элементов в список. Задача может быть решена различными способами в зависимости от типа данных и требуемой производительности. Один из самых эффективных методов – это использование встроенных методов, таких как list.count(), или более гибких решений, как использование библиотеки collections.
Метод list.count() позволяет быстро подсчитать количество вхождений конкретного элемента в списке. Он прост в использовании, но его производительность может быть недостаточной при работе с большими списками, так как этот метод выполняет полный обход списка. Если необходимо подсчитать вхождения нескольких элементов или часто выполнять подобные операции, стоит обратить внимание на использование collections.Counter, который значительно ускоряет процесс за счет внутренней оптимизации.
При работе с большими данными стоит учитывать время выполнения алгоритма. Например, в случае больших объемов данных использование set для удаления дубликатов и последующего подсчета может быть эффективным решением. Важно также помнить, что в случае работы с изменяемыми типами данных (например, списками или словарями), подсчет элементов может привести к нежелательным побочным эффектам. Поэтому правильный выбор метода зависит от специфики задачи и особенностей работы с данными.
Как посчитать количество элементов в списке с помощью метода count()
Метод count() в Python позволяет быстро посчитать, сколько раз определённый элемент встречается в списке. Это полезно, если нужно узнать частоту появления конкретного значения без использования циклов или дополнительных структур данных.
Синтаксис метода следующий: list.count(x), где x – это элемент, для которого нужно посчитать количество вхождений в список list.
Пример:
my_list = [1, 2, 3, 4, 2, 2, 5] count_of_twos = my_list.count(2)
Метод count() работает за время O(n), где n – это количество элементов в списке. Это означает, что производительность может пострадать, если список содержит большое количество элементов, и требуется несколько подсчётов.
Важно помнить, что метод count() не изменяет исходный список и возвращает только количество вхождений элемента. Если элемент отсутствует в списке, метод вернёт 0.
Пример для отсутствующего элемента:
my_list = [1, 2, 3] count_of_fours = my_list.count(4)
Метод count() является простым и эффективным инструментом для подсчёта вхождений, но для многократных подсчётов одного и того же элемента можно рассмотреть другие способы, такие как использование collections.Counter, чтобы ускорить процесс в случае работы с большими данными.
Использование цикла for для подсчета элементов в списке

Цикл for в Python позволяет эффективно перебирать элементы списка и выполнять операции с каждым из них. Для подсчета нужных элементов можно использовать простую структуру, которая позволяет обработать данные без использования сложных встроенных функций. Один из самых распространенных случаев – подсчет определенных значений, например, количества вхождений конкретного элемента в список.
Для подсчета элементов с помощью цикла for, необходимо пройтись по каждому элементу списка и, если он соответствует искомому значению, увеличить счетчик. Рассмотрим пример:
count = 0
target = 5
numbers = [1, 2, 5, 3, 5, 5, 4]
for num in numbers:
if num == target:
count += 1
print(count)
Если необходимо подсчитать несколько различных элементов, можно использовать дополнительные условия или вложенные циклы. Для подсчета всех уникальных элементов в списке подойдет использование словаря:
numbers = [1, 2, 5, 3, 5, 5, 4]
counts = {}
for num in numbers:
if num in counts:
counts[num] += 1
else:
counts[num] = 1
print(counts)
Этот код создает словарь counts, где ключами являются элементы списка, а значениями – их количество. Такой подход позволяет быстро подсчитывать все уникальные элементы списка.
Цикл for – это мощный инструмент для подсчета элементов в списках, который позволяет гибко настроить логику подсчета в зависимости от задачи. Использование дополнительных конструкций, таких как условия и словари, дает возможность эффективно обрабатывать данные без лишних вычислений.
Подсчет элементов с учетом условия: фильтрация с использованием list comprehension
Для подсчета количества элементов, соответствующих определенному условию, достаточно использовать конструкцию с условием внутри list comprehension. Пример: подсчитаем количество четных чисел в списке:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_count = len([num for num in numbers if num % 2 == 0])
print(even_count)Здесь мы создаем новый список, в который включаем только те числа, которые являются четными. Затем, с помощью функции len(), считаем количество этих элементов. Это дает результат, равный 5, так как в списке 5 четных чисел.
Подсчет с условием часто используется для фильтрации данных, например, при работе с текстами, списками слов или другими коллекциями. Рассмотрим пример фильтрации строк по длине:
words = ["python", "java", "c", "javascript", "html"]
long_words_count = len([word for word in words if len(word) > 4])
print(long_words_count)Здесь мы ищем слова, длина которых больше 4 символов. Результат будет равен 3, так как только слова «python», «javascript» и «java» соответствуют условию.
Такая фильтрация с подсчетом элементов с использованием list comprehension обладает несколькими преимуществами: она минимизирует необходимость в дополнительных циклах или функциях, улучшает читаемость и ускоряет выполнение программы для небольших объемов данных. Однако, при работе с большими списками, использование list comprehension может потребовать больше памяти из-за создания нового списка, поэтому в таких случаях можно использовать генератор, чтобы избежать лишних затрат на память.
Вместо того чтобы создавать промежуточный список, можно использовать конструкцию с генератором, которая будет подсчитывать элементы непосредственно в процессе их обработки:
even_count = sum(1 for num in numbers if num % 2 == 0)
print(even_count)Здесь sum(1 for num in numbers if num % 2 == 0) возвращает количество четных чисел в списке без создания дополнительного списка, что экономит память и делает код более эффективным для больших данных.
Как найти индекс первого вхождения элемента в списке с помощью метода index()
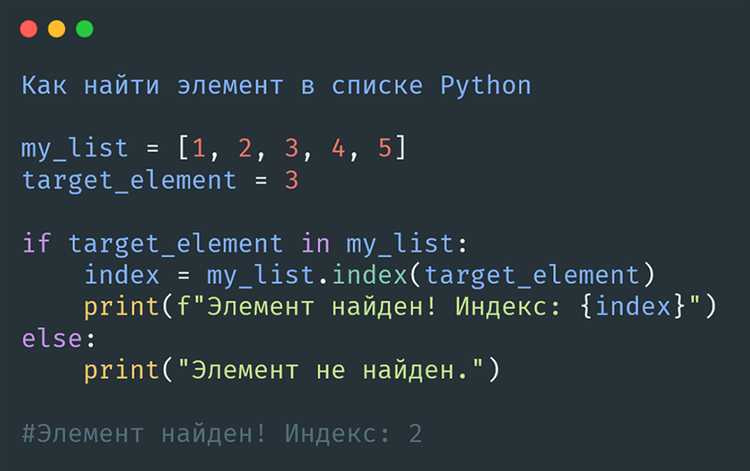
Метод index() в Python позволяет найти индекс первого вхождения элемента в списке. Если элемент присутствует в списке, метод возвращает его индекс. В противном случае возникает исключение ValueError.
Пример использования метода:
my_list = [10, 20, 30, 40, 30]
index = my_list.index(30)
print(index) # Выведет 2В данном примере метод index() возвращает индекс первого вхождения числа 30 в список, который равен 2.
Метод index() принимает два необязательных аргумента:
- start – индекс, с которого начинается поиск.
- end – индекс, на котором заканчивается поиск.
Если вам нужно ограничить поиск в определённом диапазоне, можно передать эти параметры:
my_list = [10, 20, 30, 40, 30]
index = my_list.index(30, 3) # Начнёт поиск с индекса 3
print(index) # Выведет 4В этом примере поиск начинается с индекса 3, поэтому метод вернёт индекс второго вхождения числа 30, который равен 4.
Важно помнить, что если элемент не найден в списке, метод index() вызовет исключение ValueError. Чтобы избежать ошибок, можно предварительно проверить, существует ли элемент в списке, например, с помощью оператора in:
if 30 in my_list:
index = my_list.index(30)
print(index)
else:
print("Элемент не найден")Метод index() идеально подходит для поиска первого вхождения элемента, но если вам нужно найти все индексы, на которых встречается элемент, можно использовать цикл или списковое включение.
Реализация подсчета уникальных элементов в списке с использованием словаря
Для подсчета уникальных элементов в списке на Python удобно использовать словарь. Ключи словаря будут представлять уникальные элементы, а значения – количество их повторений в списке. Такой подход эффективен, поскольку операции добавления и проверки существования ключей в словаре выполняются за время O(1), что делает решение быстрым даже для больших коллекций данных.
Для реализации подсчета уникальных элементов нужно пройтись по списку и обновить счетчик для каждого элемента. Например, можно использовать метод dict.get(), который позволяет безопасно увеличивать счетчик для каждого элемента, если он уже есть в словаре, или инициализировать счетчик, если ключа еще нет.
Пример кода:
def count_unique_elements(lst):
count_dict = {}
for element in lst:
count_dict[element] = count_dict.get(element, 0) + 1
return count_dictВ этом примере функция count_unique_elements принимает список, создает пустой словарь count_dict, после чего для каждого элемента списка увеличивает его счетчик. Если элемент еще не встречался, его счетчик инициализируется значением 1.
В результате выполнения функции возвращается словарь, где ключи – это уникальные элементы списка, а значения – количество их вхождений.
Данный метод предпочтительнее, чем использование вложенных циклов, так как словарь обеспечивает более быструю работу, исключая необходимость проверок на наличие элемента в списке. Важно помнить, что порядок элементов в словаре до версии Python 3.7 не сохранялся, однако с версии 3.7 порядок вставки элементов стал гарантированным.
Можно также использовать collections.Counter, который является специализированной оболочкой для подсчета элементов и автоматически создает словарь, где ключи – это элементы списка, а значения – их количество. Однако вручную реализованный подход дает больше контроля над процессом подсчета и возможностью обработки данных по мере их анализа.
Пример с использованием collections.Counter:
from collections import Counter
def count_unique_elements(lst):
return dict(Counter(lst))Этот код выполняет ту же задачу, но с использованием готовой библиотеки. В зависимости от требований задачи, можно выбирать между собственным решением с использованием словаря и библиотечным вариантом.
Оптимизация подсчета элементов с использованием коллекций: Counter
Для эффективного подсчета элементов в списке Python можно воспользоваться модулем collections, который предоставляет класс Counter. Этот класс позволяет значительно упростить задачу подсчета частоты появления элементов и повысить производительность по сравнению с обычными методами.
Основное преимущество Counter – это автоматизация подсчета без необходимости использования циклов и условных операторов. Он сразу создает словарь, где ключами являются элементы списка, а значениями – их количество в списке.
Пример использования:
from collections import Counter
data = ['apple', 'orange', 'banana', 'apple', 'apple', 'orange']
count = Counter(data)
print(count)Результат выполнения приведенного кода будет следующим:
Counter({'apple': 3, 'orange': 2, 'banana': 1})Counter автоматически определяет, сколько раз каждый элемент встречается в списке, что делает его удобным и быстрым инструментом для анализа данных.
Еще одно полезное свойство – это возможность получения самых частых элементов с помощью метода most_common(). Например, чтобы вывести два самых популярных элемента, можно использовать следующий код:
most_common_elements = count.most_common(2)
print(most_common_elements)Результат:
[('apple', 3), ('orange', 2)]Если требуется подсчитать не только элементы, но и их частоту по определенным группам данных, Counter можно комбинировать с другими коллекциями, такими как defaultdict, что дает гибкость в решении более сложных задач.
Counter также поддерживает операцию сложения и вычитания коллекций. Например, для двух списков можно подсчитать разницу:
count1 = Counter(['apple', 'banana', 'apple'])
count2 = Counter(['apple', 'orange'])
difference = count1 - count2
print(difference)Результат:
Counter({'banana': 1})Этот подход позволяет эффективно работать с большими объемами данных и сэкономить время на написание сложных алгоритмов подсчета.
При использовании Counter важно помнить, что он ориентирован на быстроту работы с данными, но может занимать больше памяти, чем стандартные структуры данных, такие как списки или множества. Однако при решении задач, где важна скорость подсчета элементов, это несущественно.
Вопрос-ответ:
Как в Python подсчитать количество определённых элементов в списке?
Для подсчёта количества элементов в списке можно использовать метод `count()`. Этот метод возвращает количество вхождений указанного элемента в список. Например, если у нас есть список `my_list = [1, 2, 3, 2, 4, 2]` и мы хотим узнать, сколько раз встречается число 2, мы можем использовать `my_list.count(2)`, что вернёт значение 3.