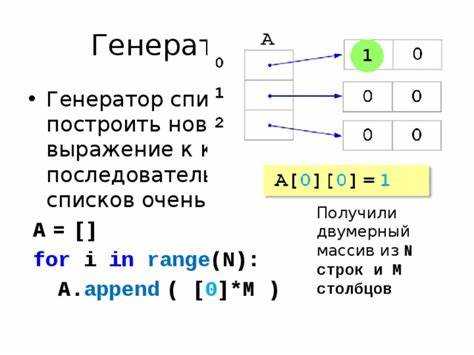
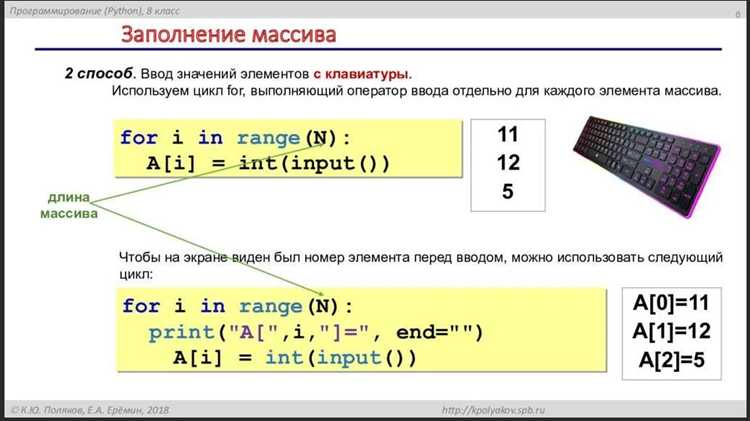
В Python двумерные массивы чаще всего представлены в виде списков списков или объектов библиотеки NumPy. Преобразование такой структуры в одномерный массив необходимо при линейной обработке данных, построении моделей или подготовке входов для нейросетей. Например, из массива [[1, 2], [3, 4]] требуется получить [1, 2, 3, 4].
Если используется стандартный список списков, можно применять вложенные циклы или генераторы списков: [elem for row in matrix for elem in row]. Этот способ эффективен и читаем даже при большом объеме данных. Он исключает необходимость использования дополнительных библиотек, что особенно важно в проектах с ограничениями на зависимости.
При работе с NumPy следует использовать метод flatten() или функцию ravel(). Первый возвращает копию, второй – представление того же объекта в памяти. Разница критична при обработке больших массивов: np.ravel(matrix) работает быстрее и экономит ресурсы, если не требуется изменять исходный массив.
Для многоуровневых вложенных структур рекомендуется применять модуль itertools, особенно chain.from_iterable(). Он позволяет разворачивать массивы любой глубины, сохраняя при этом читаемость и производительность. Подход особенно полезен при парсинге или очистке данных, полученных из внешних источников.
Как распаковать вложенные списки с помощью list comprehension
Для преобразования двумерного массива в одномерный список в Python используется вложенный list comprehension. Такой подход обеспечивает компактность и высокую скорость выполнения при работе с большими объемами данных.
Синтаксис выражения:
flat_list = [elem for sublist in matrix for elem in sublist]В этом выражении matrix – исходный двумерный массив, sublist – каждая вложенная строка, а elem – элемент внутри этой строки. Итерация происходит по всем подспискам, а затем по элементам каждого подсписка.
Пример с конкретными значениями:
matrix = [[1, 2], [3, 4], [5, 6]]
flat = [x for row in matrix for x in row]
# Результат: [1, 2, 3, 4, 5, 6]Поддерживаются любые типы элементов: строки, числа, объекты. Обработка происходит слева направо: сначала перебор подсписков, затем вложенных элементов.
Рекомендуется использовать list comprehension вместо sum(matrix, []), поскольку последний метод имеет квадратичную сложность из-за повторной конкатенации списков. List comprehension эффективнее при линейной распаковке данных.
Если требуется фильтрация, условие добавляется в конец выражения:
[x for row in matrix for x in row if x % 2 == 0]Такой способ позволяет одновременно распаковать и отфильтровать данные без дополнительного цикла.
Использование встроенного модуля itertools для плоского списка
Модуль itertools предоставляет функцию chain, позволяющую эффективно объединять вложенные списки без явного использования вложенных циклов. Для преобразования двумерного массива в одномерный применяется itertools.chain.from_iterable().
Пример:
import itertools
matrix = [[1, 2], [3, 4], [5, 6]]
flat_list = list(itertools.chain.from_iterable(matrix))
print(flat_list) # [1, 2, 3, 4, 5, 6]
Метод from_iterable() обрабатывает внешний список как итератор, извлекая элементы внутренних списков по очереди без создания промежуточных структур. Это особенно полезно при работе с большими массивами, так как снижает накладные расходы на память.
Функция chain() также может быть использована напрямую, но требует передачи каждого подсписка в качестве отдельного аргумента:
flat_list = list(itertools.chain(*matrix))
Использование chain.from_iterable() предпочтительно, если двумерный массив поступает в виде одной переменной. Это решение читабельно, лаконично и масштабируемо для любых размеров вложенности.
Преобразование массива NumPy в одномерный с помощью ravel и flatten
Методы ravel() и flatten() позволяют получить одномерное представление многомерного массива NumPy, но различаются по способу обращения с памятью.
ravel() возвращает представление исходного массива без копирования данных. Это означает, что изменения в возвращённом массиве отразятся на исходном, если это возможно. Метод работает быстрее и экономичнее по памяти, особенно при работе с большими массивами. Используется, когда не требуется изолированное копирование:
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = a.ravel()
b[0] = 99
# Теперь a[0, 0] == 99
flatten() всегда создает копию. Полученный массив не связан с исходным, поэтому любые изменения не повлияют на оригинал. Это необходимо, когда требуется независимый одномерный массив:
c = a.flatten()
c[0] = 0
# a остаётся без изменений
Если важна производительность и не требуется копия, следует использовать ravel(). Для безопасной изоляции данных подходит flatten(). Оба метода возвращают одномерный массив типа numpy.ndarray и поддерживают любую размерность исходного массива.
Сравнение reshape и flatten при работе с NumPy
reshape() изменяет форму массива без изменения данных. Возвращает представление исходного массива, если возможно, иначе – копию. Преобразование двумерного массива в одномерный достигается вызовом reshape(-1). Это эффективно по памяти, так как чаще всего создаётся представление, а не новый объект.
flatten() всегда возвращает копию массива, даже если преобразование возможно без неё. Это гарантирует независимость от исходного массива, но требует дополнительных ресурсов при работе с большими данными.
Если требуется модифицировать одномерный массив без влияния на оригинальный, используйте flatten(). Для экономии памяти и повышения производительности предпочтительнее reshape(-1), особенно в циклах и при работе с большими объёмами данных.
Изменения в массиве, полученном через reshape(), могут отразиться на исходном массиве, в то время как flatten() полностью изолирован. Это критично при параллельной обработке данных или отладке.
Преобразование двумерных данных из CSV-файла в одномерный список
Для преобразования содержимого CSV-файла в одномерный список следует использовать модуль csv или встроенные средства обработки строк. Ниже представлены конкретные шаги и рекомендации:
- Откройте CSV-файл в режиме чтения с указанием кодировки, если она известна. Используйте
with open('файл.csv', newline='', encoding='utf-8'). - Прочитайте данные с помощью
csv.readerили.read().splitlines(), если структура файла проста и не содержит вложенных кавычек и запятых. - Преобразуйте каждую строку (список значений) в одномерный формат с помощью вложенного прохода по элементам:
import csv
flat_list = []
with open('data.csv', newline='', encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
flat_list.extend(row)
- Используйте
extend(), а неappend(), чтобы не получить список списков. - Для удаления пустых значений примените фильтрацию:
flat_list = [x for x in flat_list if x]. - При необходимости преобразования типов данных (например, в числа) используйте генератор:
flat_list = [int(x) for x in flat_list].
Такой подход эффективен при работе с числовыми таблицами, анкетами и другими структурированными наборами данных, где важна линейная структура для последующей обработки.
Извлечение элементов по строкам или столбцам и их объединение
Для извлечения элементов из двумерного массива в Python часто используются библиотеки, такие как NumPy. С их помощью можно быстро манипулировать данными, извлекая строки или столбцы, а затем объединяя их в одномерные массивы.
Чтобы извлечь строку или столбец из двумерного массива, можно применить индексацию и срезы. Например:
- Для извлечения строки по индексу
i из массиваarr используйте:arr[i]. - Для извлечения столбца по индексу
j из массиваarr используйте:arr[:, j].
Иногда бывает необходимо извлечь несколько строк или столбцов сразу. Это можно сделать с помощью срезов:
- Для извлечения нескольких строк с индексами от
iдоjиспользуйте:arr[i:j]. - Для извлечения нескольких столбцов используйте:
arr[:, i:j].
После извлечения данных, часто требуется объединить их в одномерный массив. В NumPy это можно сделать с помощью функции ravel() или метода flatten():
arr.ravel()– возвращает одномерный массив, содержащий элементы двумерного массива в том порядке, в котором они расположены.arr.flatten()– аналогичнаravel(), но возвращает копию массива, а не представление.
Если нужно объединить несколько извлеченных строк или столбцов в один одномерный массив, можно использовать функцию numpy.concatenate(). Например:
numpy.concatenate([arr[0], arr[1]])– объединяет первую и вторую строки в одномерный массив.numpy.concatenate([arr[:, 0], arr[:, 1]])– объединяет первый и второй столбец в одномерный массив.
При объединении важно учитывать тип данных, так как разные типы могут вызывать проблемы с преобразованием или потери точности при объединении числовых массивов с различной разрядностью.
Обработка вложенных списков разной длины при преобразовании

Когда мы работаем с двумерными массивами разной длины (например, вложенные списки с переменным количеством элементов), преобразование их в одномерный массив может столкнуться с рядом проблем. Важно правильно обработать такие структуры, чтобы избежать ошибок при доступе к данным и сохранить целостность информации.
1. Нормализация длины подсписков
Если требуется преобразовать двумерный массив в одномерный, можно предварительно привести все вложенные списки к одинаковой длине. Это особенно актуально, когда данные представляют собой таблицы, где каждая строка должна содержать одинаковое количество элементов. Один из способов – дополнить короткие подсписки значениями по умолчанию (например, None или 0), что сделает длину всех вложенных списков одинаковой.
2. Использование метода extend
Если нам нужно объединить списки разной длины в одномерный массив, можно воспользоваться методом extend. Этот метод добавляет элементы вложенных списков поочередно в основной список. Он автоматически игнорирует разницу в длине, не вызывая ошибок.
3. Преобразование с учётом пропусков
В случае, если необходимо сохранить структуру вложенности, но при этом получить одномерный список с учётом пропусков, можно использовать цикл с условием. Пример: если вложенные списки имеют разную длину, мы можем создать новый список, в который будем добавлять элементы, заполняя пропуски, где необходимо.
4. Решение для сложных вложений
Для более сложных случаев (например, когда вложенные списки содержат другие вложенные списки или смешанные типы данных), стоит использовать рекурсивный подход. В этом случае можно написать рекурсивную функцию, которая будет обходить все уровни вложенности и добавлять элементы в одномерный список.
Пример рекурсивной функции:
def flatten(lst):
result = []
for item in lst:
if isinstance(item, list):
result.extend(flatten(item))
else:
result.append(item)
return result
Этот метод подходит для любых уровней вложенности, независимо от их длины.
Вопрос-ответ:
Что такое двумерный массив в Python и как его можно преобразовать в одномерный?
Двумерный массив (или список) в Python — это структура данных, которая представляет собой список списков, где каждый элемент внутреннего списка может быть доступен с помощью двух индексов: для строки и для столбца. Преобразовать такой массив в одномерный можно с использованием различных методов, таких как циклы, list comprehension или встроенная функция itertools.chain().