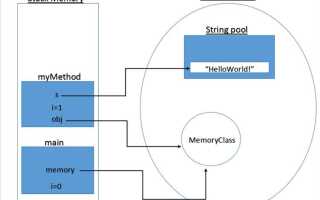
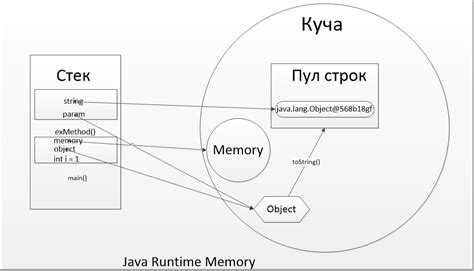
В языке Java память управляется через две основные области: куча (heap) и стек (stack). Куча используется для динамического распределения памяти, а стек – для хранения данных, связанных с выполнением методов и локальными переменными. Каждый объект в Java размещается в куче, в то время как примитивные типы и ссылки на объекты хранятся в стеке. Эта модель упрощает управление памятью, но требует от разработчика внимания к особенностям работы с памятью, чтобы избежать утечек и других проблем.
Каждый раз, когда создается объект в Java, он размещается в куче, которая имеет свой сборщик мусора. Сборщик мусора (Garbage Collector, GC) отслеживает объекты, которые больше не используются, и освобождает память, занимаемую этими объектами. Существует несколько типов сборщиков мусора, таких как Serial GC, Parallel GC, G1 GC и другие, которые имеют разные стратегии для оптимизации производительности и минимизации пауз в работе приложения.
Одним из важнейших аспектов управления памятью является различие между стеком и кучей в контексте многозадачности. Стек создается для каждого потока, а куча – общая для всех потоков приложения. Это значит, что объекты в куче могут быть доступны нескольким потокам, что требует синхронизации для предотвращения конфликтов данных. Важно понимать, что синхронизация может негативно сказаться на производительности, поэтому при проектировании многозадачных приложений важно учитывать эти моменты.
Рекомендуется внимательно следить за временем жизни объектов, чтобы избежать утечек памяти. Если объект больше не используется, но ссылка на него продолжает существовать, сборщик мусора не сможет освободить память. Одним из способов предотвращения таких проблем является использование слабых ссылок (WeakReference) для объектов, которые могут быть удалены сборщиком мусора, если они больше не нужны.
Как работает управление памятью в Java: основные принципы
Управление памятью в Java основывается на автоматическом выделении и освобождении памяти с помощью механизма сборщика мусора (Garbage Collector). В отличие от языков, требующих ручного управления памятью, Java минимизирует риск ошибок, связанных с утечками памяти, благодаря автоматической очистке.
Основная задача сборщика мусора заключается в том, чтобы отслеживать объекты, которые больше не используются в программе, и освобождать память, занятую этими объектами. Сборщик мусора в Java работает на основе принципа доступности объектов, что означает, что объект будет удален, когда на него не будет ссылок в коде.
Память в Java делится на несколько областей, каждая из которых имеет свое назначение и особенности работы:
1. Стек (Stack)
В стеке хранится информация о вызовах методов и локальных переменных. Стек работает по принципу LIFO (Last In, First Out), что означает, что элементы добавляются и удаляются с конца. Каждому потоку выделяется отдельный стек.
2. Куча (Heap)
Куча используется для хранения объектов, созданных с помощью оператора new. Память в куче делится на несколько областей: Young Generation (молодое поколение), Old Generation (старое поколение) и Permanent Generation (перманентное поколение). В новых версиях Java Permanent Generation была заменена на Metaspace.
3. Metaspace
Metaspace хранит метаданные классов и другой информации, связанной с классами. В отличие от Permanent Generation, Metaspace не ограничен фиксированным размером, что улучшает гибкость управления памятью.
4. Сборщик мусора
Сборщик мусора Java делит работу на несколько этапов: сначала очищаются объекты в Young Generation, затем в Old Generation. Существует несколько алгоритмов сборки мусора, таких как Mark-and-Sweep, Generational GC и G1 GC, каждый из которых оптимизирует процесс удаления объектов в зависимости от ситуации.
При выборе подходящего алгоритма сборки мусора нужно учитывать характер приложения. Например, для приложений с высокой нагрузкой и требованиями по времени отклика рекомендуется использовать G1 GC, который разделяет память на регионы и минимизирует паузы.
5. Выделение памяти и управление ссылками
Когда объект создается в куче, Java автоматически управляет его жизненным циклом. Однако программисты должны помнить, что наличие ненужных ссылок на объект может помешать его сбору мусора. Важно избегать создания слабых ссылок (Weak References) и ненужных объектов, что поможет уменьшить нагрузку на систему.
Рекомендации:
Для эффективного использования памяти в Java стоит учитывать несколько принципов:
- Избегать создания лишних объектов, особенно внутри циклов.
- Использовать слабые и мягкие ссылки (WeakReference, SoftReference) для объектов, которые можно безопасно освободить.
- Профилировать и оптимизировать использование памяти с помощью инструментов, таких как VisualVM и JProfiler.
- При необходимости вручную управлять сборкой мусора с помощью вызова
System.gc(), но это не рекомендуется для частого использования.
Что такое куча и стек в Java: различия и использование
Стек представляет собой область памяти, которая используется для хранения локальных переменных и ссылок на объекты. Каждый метод в Java имеет свой стековый фрейм, который создается при вызове метода и уничтожается, когда метод завершает выполнение. Локальные переменные, включая параметры метода, хранятся в стеке. Важным свойством стека является его LIFO (Last In, First Out) принцип работы – последние данные, помещенные в стек, извлекаются первыми. Он ограничен по размеру, что делает его быстрым и эффективным, но малым по объему. Переполнение стека (StackOverflowError) происходит, когда превышен допустимый размер стека, например, при бесконечной рекурсии.
Куча используется для хранения объектов, которые создаются с помощью оператора `new`. В отличие от стека, куча имеет динамический размер и позволяет хранить объекты переменной длины, такие как массивы, строки и другие. Объекты в куче существуют до тех пор, пока на них есть ссылки. Когда на объект нет ссылок, система запускает сборщик мусора (Garbage Collector), который очищает память от неиспользуемых объектов. Это делает использование кучи более гибким, но и менее предсказуемым с точки зрения производительности, так как время работы сборщика мусора может варьироваться. Переполнение кучи (OutOfMemoryError) происходит, когда не хватает памяти для размещения новых объектов.
Основное различие между стеком и кучей заключается в области использования и управлении памятью. Стек работает с примитивными типами данных и ссылками на объекты, предоставляя быстрое выделение и освобождение памяти, но ограничен в объеме. Куча же используется для хранения самих объектов, она более гибка, но также требует управления через сборщик мусора.
Для эффективного использования памяти в Java важно правильно выбирать, где и какие данные хранить. Для небольших данных и локальных переменных лучше использовать стек, поскольку это более быстрое и эффективное решение. Для объектов, жизненный цикл которых зависит от других частей программы или которые требуют динамического выделения памяти, используется куча.
Как работает сборщик мусора в Java: что нужно знать разработчику
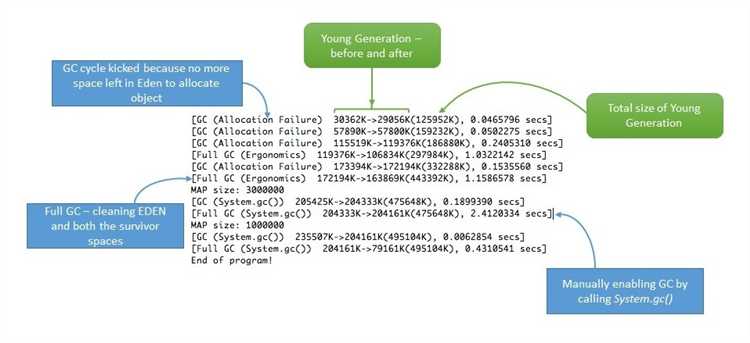
Сборщик мусора (Garbage Collector, GC) в Java отвечает за автоматическое управление памятью, удаляя объекты, которые больше не используются. Он освобождает разработчика от необходимости вручную управлять памятью, что снижает риск утечек памяти и других ошибок, связанных с её управлением.
В Java сборщик мусора работает в фоновом режиме, и его цель – минимизировать время, затрачиваемое на поиск и удаление ненужных объектов. Важно понимать основные моменты, которые могут повлиять на производительность и поведение GC:
- Поколения в куче: Куча (heap) в Java делится на несколько поколений: младшее (Young), старшее (Old), и иногда – постоянное (Permanent, Metaspace). Множество объектов появляется в молодом поколении, и сборщик мусора сначала работает именно с этим сегментом памяти.
- Типы сборщиков мусора: Java предлагает несколько сборщиков мусора, включая Serial, Parallel, CMS и G1. Каждый из них имеет свои особенности и применим в различных сценариях. Например, G1 предлагает хороший баланс между временем пауз и пропускной способностью, идеально подходя для больших приложений.
- Алгоритм сборки: Основной механизм работы – это метод отслеживания ссылок на объекты. Когда объект больше не имеет ссылок, он считается мусором и может быть удалён. В случае с молодым поколением используется алгоритм «Copying», где объекты копируются в новый участок памяти, а старые удаляются. В старшем поколении используется алгоритм «Mark-and-Sweep», который сначала маркирует все живые объекты, а затем удаляет мёртвые.
Основные этапы работы GC:
- Марк: Определение всех объектов, которые всё ещё используются (имеют ссылки).
- Сбор: Удаление объектов, на которые нет ссылок.
- Компактизация: Освобождённое место в куче может быть сжато, чтобы предотвратить фрагментацию памяти.
Для эффективного управления памятью и предотвращения ненужных пауз в работе приложения важно настроить GC в соответствии с задачами:
- Правильный выбор сборщика: Выберите сборщик, который оптимален для вашего приложения. Например, G1 подходит для приложений с большими объемами данных, где важна минимизация пауз.
- Мониторинг и настройка параметров: Используйте инструменты профилирования (например, VisualVM или JConsole) для мониторинга работы сборщика мусора. Вы можете настроить параметры, такие как размер молодых и старых поколений, чтобы сбалансировать производительность.
- Использование слабых ссылок: Если объект не должен удерживать память в куче, можно использовать слабые или финализируемые ссылки для того, чтобы GC мог освободить память быстрее.
Хорошее понимание работы сборщика мусора помогает избежать типичных проблем, таких как утечки памяти и длительные паузы, вызванные неэффективным управлением памятью. Оптимизация работы GC способствует улучшению производительности приложения.
Как избежать утечек памяти в Java: практические советы
Утечка памяти в Java может возникать, когда объект больше не используется, но всё ещё удерживается в памяти, из-за чего не освобождается ресурс. Такие утечки могут приводить к ухудшению производительности приложения или его краху. Рассмотрим несколько эффективных подходов для их предотвращения.
1. Использование слабых ссылок (WeakReferences)
Слабые ссылки полезны для объектов, которые не должны препятствовать сборщику мусора. Например, если объект хранится в кешe или используется в других ненадёжных контекстах, можно использовать WeakReference. Это позволяет системе своевременно освобождать память, когда объект больше не нужен, не создавая утечек.
2. Очистка коллекций
Коллекции, такие как List, Map или Set, могут быть причиной утечек памяти, если они содержат элементы, которые не используются, но не удаляются. Регулярно проверяйте и очищайте коллекции, особенно если храните в них ссылки на объекты, которые больше не нужны.
3. Использование try-with-resources для закрытия ресурсов
Если приложение работает с внешними ресурсами (файлы, соединения с базой данных, сокеты и т.д.), важно их закрывать после использования. Использование конструкции try-with-resources автоматически закрывает ресурсы, что предотвращает возможные утечки памяти, связанные с незакрытыми потоками и соединениями.
4. Минимизация использования статических полей
Статические поля могут привести к утечкам, если они хранят ссылки на объекты, которые должны быть освобождены. Эти объекты не могут быть собраны сборщиком мусора, пока существует ссылка на статическое поле. Избегайте хранения больших объектов в статических полях и всегда тщательно проверяйте их жизненный цикл.
5. Избегание циклических зависимостей
Циклические зависимости, когда два или более объекта ссылаются друг на друга, могут предотвратить сборку мусора, так как они остаются доступными, даже если больше не используются. Применяйте осторожность при проектировании и старайтесь минимизировать такие связи, или используйте WeakReference для разрыва цикла.
6. Профилирование и мониторинг памяти
Использование инструментов профилирования, таких как jvisualvm, jconsole, или YourKit, поможет вам выявить участки кода, где происходят утечки памяти. Регулярный мониторинг поможет оперативно обнаружить и устранить проблемы до того, как они станут критичными.
7. Очистка кэшей
Если в вашем приложении используется кеширование данных, важно правильно управлять его размером. Например, кеш, который растёт без контроля, может привести к утечкам памяти, особенно если не удалять устаревшие или неиспользуемые элементы. Используйте алгоритмы управления кешем, такие как LRU (Least Recently Used), чтобы своевременно очищать устаревшие данные.
8. Использование библиотеки для управления памятью
Некоторые библиотеки и фреймворки предоставляют механизмы для управления памятью, такие как Guava для кэширования, или Apache Commons для работы с коллекциями и объектами. Они помогают снизить риски утечек, предоставляя высокоуровневые абстракции для работы с памятью.
Какие типы данных занимают память в Java и как это учитывать

В Java память, выделяемая для данных, зависит от типа данных и способа их использования. Знание, сколько памяти занимает тот или иной тип данных, позволяет оптимизировать использование памяти и избежать лишних затрат. Рассмотрим основные типы данных и их влияние на память.
Типы данных в Java можно разделить на примитивные и ссылочные. Примитивные типы имеют фиксированный размер, в то время как ссылки на объекты могут занимать разное количество памяти в зависимости от конкретного объекта.
Примитивные типы данных
- byte: 1 байт. Используется для хранения целых чисел от -128 до 127.
- short: 2 байта. Диапазон значений – от -32,768 до 32,767.
- int: 4 байта. Диапазон от -2,147,483,648 до 2,147,483,647.
- long: 8 байт. Диапазон от -9,223,372,036,854,775,808 до 9,223,372,036,854,775,807.
- float: 4 байта. Представляет числа с плавающей запятой одинарной точности.
- double: 8 байт. Числа с плавающей запятой двойной точности.
- char: 2 байта. Используется для хранения одного символа в кодировке Unicode.
- boolean: 1 бит. Обычно используется для хранения значений true или false, однако JVM может выделять больше памяти в зависимости от реализации.
Ссылочные типы данных
Ссылочные типы данных включают все объекты и массивы. Размер памяти, занятой ссылочным типом, зависит от структуры объекта и типа данных, которые он содержит.
- Объекты: Размер объекта зависит от его полей. В JVM каждый объект имеет внутреннюю структуру, включающую заголовок объекта (обычно 8 байт), а также размер полей. Например, объект с двумя полями типа int займет 12 байт (8 байт для заголовка + 4 байта для каждого поля). Однако за счет выравнивания памяти размер объекта может быть больше.
- Массивы: Массивы в Java также являются объектами, поэтому для них также выделяется дополнительная память для заголовка. Размер массива определяется типом элементов и его длиной. Например, массив из 10 элементов типа int займет 40 байт для данных и дополнительно 12-16 байт для заголовка массива.
Как учитывать память при работе с данными

- Оптимизация использования памяти для примитивных типов: Когда необходимо работать с большим количеством данных, следует выбирать наиболее компактные типы. Например, если можно обойтись без использования диапазона, который предоставляет тип int, лучше использовать byte или short.
- Использование строк (String): Объекты типа String в Java хранятся в пуле строк, что позволяет экономить память. Однако строка может занять значительно больше памяти, если она длинная. Для часто изменяющихся строк лучше использовать StringBuilder или StringBuffer, так как они позволяют избежать создания множества временных объектов.
- Избегание ненужных объектов: Создание новых объектов требует значительных ресурсов. Можно использовать примитивные типы или коллекции с меньшими затратами памяти. Также следует следить за количеством объектов, которые остаются в памяти, используя механизмы сборщика мусора (garbage collector).
- Использование слабых ссылок: Для объектов, которые не нужно удерживать в памяти длительное время, можно использовать слабые или финализированные ссылки (WeakReference, SoftReference). Это поможет снизить нагрузку на память и улучшить производительность.
Знание того, какие типы данных и как они распределяются по памяти, позволяет более эффективно управлять ресурсами в Java-программах и избегать излишних затрат памяти, особенно в системах с ограниченными ресурсами.
Вопрос-ответ:
Как Java управляет памятью?
Java использует автоматическое управление памятью, что значительно упрощает разработку. Это достигается благодаря сборщику мусора, который автоматически очищает память от объектов, которые больше не используются. Сборщик мусора находит объекты, ссылки на которые были уничтожены, и освобождает память, выделенную для них. Это позволяет программистам не беспокоиться о ручной очистке памяти, как это требуется в других языках программирования.
Что такое куча и стек в Java?
В Java память делится на несколько частей, среди которых выделяются стек и куча. Стек используется для хранения локальных переменных и вызовов методов. Каждый метод, при вызове, добавляется в стек, а после завершения его работы, память освобождается. Куча же используется для динамического выделения памяти, то есть для объектов, создаваемых с помощью оператора `new`. Все объекты, живущие в куче, управляются сборщиком мусора, который очищает память, когда объекты становятся ненужными.
Как работает сборщик мусора в Java?
Сборщик мусора (Garbage Collector) в Java автоматически управляет памятью. Он обнаруживает объекты, которые больше не используются программой, и освобождает их память. Существует несколько алгоритмов работы сборщика мусора, включая марк- и-сweep, поколенный сборщик и другие. Каждый из них имеет свои особенности, но цель остается одной: освободить память от ненужных объектов, чтобы предотвратить утечку памяти и улучшить производительность приложения.
Как управляется память для объектов в Java?
Когда объект создается в Java, память для него выделяется в куче. Эта память остается занята до тех пор, пока объект не станет недоступным для программы, то есть на него не останется ссылок. Когда это происходит, сборщик мусора автоматически очищает память, освобождая ресурсы, занятые объектом. Важно понимать, что сборщик мусора не может быть явно вызван разработчиком, но его работа критически важна для поддержания эффективного использования памяти в приложении.
Можно ли контролировать работу сборщика мусора в Java?
Программисты не могут напрямую управлять работой сборщика мусора в Java, так как его задача – это автоматическое управление памятью. Однако, существуют способы влияния на его поведение, например, с помощью настроек JVM (Java Virtual Machine). Можно задавать параметры для сборщика мусора, такие как размер кучи или частота сборки мусора. Некоторые оптимизации могут помочь улучшить производительность программы, особенно в больших и сложных приложениях, но в целом сборщик мусора работает автоматически и не требует вмешательства.