Работа с текстовыми данными в программировании часто требует манипуляций с регистром символов. Одной из таких задач является преобразование всех букв строки в нижний регистр. Это может быть полезно при сравнении строк, анализе пользовательского ввода или при обработке данных в приложениях, где важно учитывать только текстовое содержание, без учета регистра символов.
Метод .lower() в Python – это наиболее популярный способ преобразования текста в нижний регистр. Встроенная функция lower() применяет изменения ко всей строке, не затрагивая другие символы, такие как цифры или знаки препинания. Использование этого метода не вызывает сложностей и идеально подходит для большинства задач, где требуется стандартное преобразование текста.
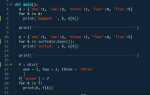
Пример кода, который конвертирует строку в нижний регистр, выглядит следующим образом:
text = "Пример Текста"
result = text.lower()
print(result)В этом примере строка «Пример Текста» будет преобразована в «пример текста». Это один из простых и эффективных способов привести текст к единому формату.
Кроме того, в некоторых случаях может быть полезным применение регулярных выражений для замены только букв, оставляя все остальные символы нетронутыми. Однако для большинства стандартных задач достаточно использования метода lower(). Важно помнить, что преобразование в нижний регистр не изменяет исходную строку, а возвращает новую строку с нужными изменениями.
Основные преимущества такого подхода заключаются в простоте и эффективности. В большинстве случаев, когда необходимо игнорировать различия в регистре, метод lower() решает задачу без дополнительных усилий и сложных операций.
Использование метода lower() в Python для преобразования строки

Применение метода lower() особенно полезно при обработке текстов, где важно игнорировать регистр символов, например, при сравнении строк или анализе данных, поступающих от пользователя.
Пример использования метода lower():
text = "Привет, МИР!"
lower_text = text.lower()
В этом примере строка "Привет, МИР!" преобразуется в строку "привет, мир!". Метод lower() затрагивает только буквы, оставляя другие символы (например, знаки препинания) неизменными.
Для обеспечения корректной работы с разными языками метод автоматически учитывает локализацию системы, поэтому его можно использовать не только для английских, но и для других языков, поддерживающих регистрозависимость.
Следует помнить, что метод lower() не изменяет исходную строку. Строки в Python являются неизменяемыми объектами, и вызов lower() всегда возвращает новый объект.
Метод lower() эффективен в ситуациях, когда необходимо привести данные в единую форму, например, при проверке правильности ввода или при анализе больших объемов текстовой информации, где регистр не имеет значения.
Как привести строку к нижнему регистру с помощью метода casefold()
Метод casefold() в Python используется для преобразования строки в нижний регистр с учётом особенностей локализации и корректной обработки символов, которые могут вести себя по-разному в разных языках (например, буквы с диакритическими знаками). Этот метод полезен в ситуациях, когда необходимо нормализовать строки для дальнейших сравнений, особенно если строки могут содержать символы в разных регистрах.
Основное отличие casefold() от стандартного метода lower() заключается в том, что casefold() более агрессивно нормализует строку, обеспечивая правильное преобразование символов, специфичных для некоторых языков. Например, в немецком языке буква «ß» преобразуется в «ss», что не происходит при использовании lower().
Пример использования метода casefold():
text = "Straße"
normalized_text = text.casefold()
print(normalized_text) # Выведет "strasse"Метод casefold() может быть полезен в следующих случаях:
- Для корректного сравнения строк, содержащих символы с особыми регистрами.
- При обработке пользовательского ввода, где важно игнорировать различия в регистре и локализации.
- В задачах, связанных с поиском или анализом текста, где требуется игнорировать влияние регистра.
Метод возвращает новую строку, а оригинальная строка остаётся неизменной. Это важно учитывать при работе с большими объёмами данных или когда необходимо сохранить исходные данные для дальнейшей обработки.
Несмотря на широкие возможности, метод casefold() может быть неэффективен для всех языков и символов, и в некоторых случаях предпочтительнее использовать другие методы нормализации, такие как lower() или сторонние библиотеки для работы с текстом в специфических локалях.
Преобразование строки в нижний регистр с учётом кодировки

Для строк в кодировке UTF-8 преобразование в нижний регистр обычно не вызывает проблем. Однако в некоторых случаях могут возникнуть сложности при работе с кодировками, не поддерживающими все символы. Например, при обработке строк в кодировке Windows-1251, содержащих символы, которые не существуют в стандартном латинском алфавите, функция преобразования может давать некорректный результат. В таких случаях необходимо сначала привести строку к единой кодировке (например, UTF-8), а затем выполнять преобразование.
Для корректной работы с кодировками важно использовать библиотеку, которая поддерживает работу с различными системами кодирования. В Python для этого можно использовать модуль chardet или функции из библиотеки codecs, чтобы определить кодировку исходной строки перед её преобразованием. В JavaScript при необходимости можно воспользоваться TextDecoder для работы с кодировками, отличными от UTF-8.
Важно: при работе с многоязычными текстами или текстами с особыми символами (например, кириллицей, акцентированными буквами или символами, принадлежащими различным языковым группам), важно учитывать влияние кодировки на визуальное представление и правильность преобразования символов. Для минимизации ошибок рекомендуется использовать UTF-8 как универсальную кодировку, поддерживающую все популярные языки.
Кроме того, при разработке веб-приложений важно учитывать, что браузеры по умолчанию используют UTF-8, что позволяет избежать большинства проблем с кодировками при обработке строк. Но если исходные данные получаются от пользователя или из внешних источников, всегда стоит проверять и, при необходимости, преобразовывать кодировку перед преобразованием строки в нижний регистр.
Оптимизация работы с большими строками при изменении регистра

При изменении регистра в строках больших размеров важно учитывать как время выполнения операции, так и потребление памяти. Обычные подходы, такие как использование метода toLowerCase() или toUpperCase(), могут быть неэффективны для массивов данных, содержащих миллионы символов. В таких случаях необходимо применять стратегии для минимизации накладных расходов.
1. Использование буферизации
При работе с большими строками эффективнее использовать буферизацию для постепенной обработки данных. Вместо того чтобы создавать новые строки на каждом шаге (что приводит к большому количеству временных объектов), можно использовать буфер, куда будет записываться результат. Для этого в JavaScript можно использовать объекты типа StringBuilder или просто массивы, в которые поочередно добавляются символы в нужном регистре. Это позволяет избежать постоянного выделения памяти для промежуточных строк и ускоряет процесс.
2. Итеративный подход вместо рекурсивного
Рекурсивные методы изменения регистра в строках могут привести к переполнению стека при обработке больших данных. Итеративный подход с использованием циклов, например for или while, значительно уменьшает нагрузку на память и ускоряет выполнение.
3. Обработка строк по частям
При очень длинных строках полезно разделить данные на блоки и изменять регистр частями. Это может существенно снизить время обработки, особенно в случаях, когда строка содержит несколько одинаковых частей или шаблонов. Это также может быть полезно при параллельной обработке данных в многозадачных средах.
4. Профилирование и выбор алгоритма
Перед применением алгоритмов важно провести профилирование кода с помощью инструментов для анализа производительности. Разные движки JavaScript могут по-разному оптимизировать работу с большими строками. Иногда использование собственных алгоритмов для преобразования регистра может дать лучшие результаты, чем стандартные функции языка.
5. Учет кодировки
При обработке строк, содержащих символы за пределами стандартной ASCII-таблицы (например, символы кириллицы или юникод), важно учитывать особенности кодировки. Операции преобразования регистра могут быть ресурсозатратными, если не учитывать правильное использование кодировки символов, особенно в многобайтовых языках.
Оптимизация работы с большими строками при изменении регистра требует внимательного подхода к выбору инструментов и алгоритмов. Важно учитывать как время выполнения, так и потребление памяти, чтобы обеспечить максимальную эффективность обработки данных в реальных условиях работы с большими объемами информации.
Как преобразовать строку в нижний регистр с учётом локали
Python предоставляет функцию str.lower() для преобразования строки в нижний регистр, но она не учитывает локаль по умолчанию. Для корректного преобразования необходимо использовать функцию, которая учитывает локализацию.
Для этого можно использовать модуль locale в Python. Он позволяет установить локаль, и функция str.lower() будет работать с учетом установленных локальных особенностей.
Пример:
import locale
Устанавливаем локаль для Турции
locale.setlocale(locale.LC_ALL, 'tr_TR.UTF-8')
text = "İstanbul"
lower_text = text.lower() # Преобразование с учётом локали
print(lower_text) # Выведет "istanbul"
Если не учитывать локаль, буква «İ» будет преобразована в «i», что не соответствует правилам турецкой локализации. Установка локали гарантирует, что такие особенности будут учтены.
Для других языков также существует возможность настроить локаль. Например, для Русского или Английского языков локаль по умолчанию работает корректно, но важно проверять поведение с особенными символами, как, например, буквы с диакритическими знаками в языках с расширенными алфавитами.
В случае, если необходимо обработать строку в многопользовательской среде, рекомендуется проверять локаль каждого пользователя, чтобы гарантировать правильность преобразования символов, особенно если приложение работает с разными языковыми группами.
Преобразование строки в нижний регистр в других языках программирования
В различных языках программирования существуют свои способы преобразования строк в нижний регистр. Рассмотрим, как это можно сделать в популярных языках.
Python предоставляет метод lower() для объектов типа str. Это наиболее простой и прямой способ преобразования всей строки в нижний регистр:
text = "Пример Строки"
text_lower = text.lower() # результат: 'пример строки'JavaScript использует метод toLowerCase() для строк:
let text = "Пример Строки";
let textLower = text.toLowerCase(); // результат: 'пример строки'Java предлагает метод toLowerCase() в классе String:
String text = "Пример Строки";
String textLower = text.toLowerCase(); // результат: 'пример строки'C# также имеет метод ToLower() для работы с строками:
string text = "Пример Строки";
string textLower = text.ToLower(); // результат: 'пример строки'C++ не предоставляет встроенной функции для преобразования строки в нижний регистр, но можно использовать стандартные библиотеки. Например, с помощью функции transform из algorithm:
#include
#include
#include
using namespace std;
int main() {
string text = "Пример Строки";
transform(text.begin(), text.end(), text.begin(), ::tolower);
cout << text; // результат: 'пример строки'
return 0;
} PHP предоставляет функцию strtolower() для преобразования строки в нижний регистр:
$text = "Пример Строки";
$textLower = strtolower($text); // результат: 'пример строки'Ruby использует метод downcase для объектов типа String:
text = "Пример Строки"
text_lower = text.downcase # результат: 'пример строки'Эти методы универсальны и работают с различными алфавитами и символами, поддерживающими Unicode. Важно помнить, что для некоторых языков могут существовать дополнительные нюансы работы с локалями, особенно для языков с особыми правилами преобразования регистра, как турецкий или немецкий.
Обработка ошибок при преобразовании строки в нижний регистр
При преобразовании строки в нижний регистр важно учитывать возможные ошибки, которые могут возникнуть в процессе. Основные ошибки, с которыми можно столкнуться, связаны с типами данных и неправильным использованием метода. Рассмотрим основные сценарии и способы их обработки.
Тип данных – метод lower() работает только с объектами типа str. Попытка вызвать его для другого типа данных (например, int или None) приведет к ошибке типа. Чтобы избежать этого, перед применением метода стоит убедиться, что объект является строкой. Например, можно использовать конструкцию isinstance(variable, str).
Пример обработки ошибки:
if isinstance(variable, str):
result = variable.lower()
else:
raise TypeError("Ожидалась строка, получен другой тип данных")
Наличие пустой строки также может вызывать определенные трудности, если обработка таких случаев не предусмотрена. В некоторых приложениях важно избежать дальнейших действий с пустыми строками. Проверка на пустоту строки может быть выполнена с помощью условного оператора: if variable == "".
Кодировка – при работе со строками важно учитывать кодировку символов. Если строка содержит символы, которые не поддерживаются текущей кодировкой, это может вызвать ошибку при преобразовании. Для решения этой проблемы необходимо убедиться, что строка использует стандартную кодировку UTF-8 перед её обработкой.
Пример исправления кодировки:
if isinstance(variable, str):
variable = variable.encode('utf-8').decode('utf-8')
result = variable.lower()
else:
raise ValueError("Строка не поддерживает необходимую кодировку")
Логирование ошибок поможет отлавливать ошибки на этапе разработки. В случае возникновения исключения полезно вести журнал ошибок, чтобы быстро идентифицировать и устранить проблемы. Например, при использовании модуля logging можно зафиксировать тип ошибки и исходную строку.
Пример логирования:
import logging
try:
result = variable.lower()
except Exception as e:
logging.error(f"Ошибка при преобразовании строки: {e}, строка: {variable}")
raise
Обработка ошибок при преобразовании строки в нижний регистр требует внимательности к типам данных, кодировкам и особенностям работы с пустыми строками. Четкая проверка входных данных и логирование ошибок помогут предотвратить сбои и упростят отладку программы.