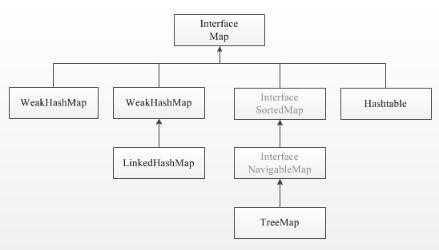
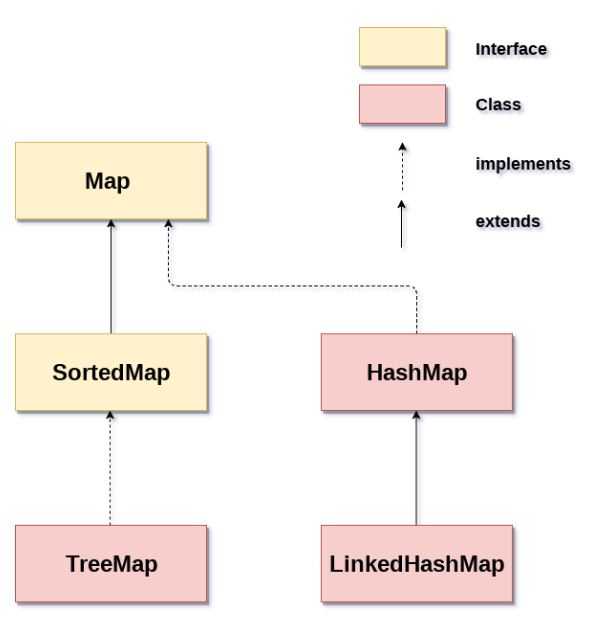
Интерфейс Map в Java предназначен для хранения пар «ключ–значение». В отличие от коллекций, реализующих Collection, объекты Map не допускают дублирование ключей: каждый ключ уникален, но значения могут повторяться. Основные реализации – HashMap, LinkedHashMap, TreeMap и ConcurrentHashMap.
HashMap основан на хешировании и обеспечивает быстрый доступ к элементам, но не гарантирует порядок хранения. В LinkedHashMap сохраняется порядок добавления, что полезно при последовательной обработке данных. TreeMap поддерживает отсортированный по ключам порядок и реализует интерфейс SortedMap. ConcurrentHashMap предназначен для многопоточного доступа, избегая блокировки всей структуры при изменениях.
При использовании Map важно учитывать, что ключи должны корректно реализовывать методы equals() и hashCode(). Нарушение этого правила приводит к неожиданным результатам при поиске и удалении элементов. Также не рекомендуется использовать изменяемые объекты в качестве ключей.
Для перебора содержимого можно использовать методы entrySet(), keySet() и values(). Первый предпочтительнее при необходимости доступа и к ключу, и к значению одновременно, так как он избегает лишних обращений к Map по ключу.
Начиная с Java 8, в интерфейс Map добавлены методы forEach(), computeIfAbsent(), merge(), getOrDefault(). Эти методы позволяют сократить объем кода и повысить читаемость при работе с ассоциативными данными.
Когда использовать HashMap и чем он отличается от других реализаций
- Время доступа к элементу в среднем – O(1). При плохом распределении хешей – до O(n).
- Не гарантирует порядок элементов. Вызов
entrySet()илиkeySet()может вернуть элементы в произвольном порядке. - Разрешает использование
nullв качестве ключа и значения (только одинnull-ключ).
Используйте HashMap, когда:
- Порядок вставки не имеет значения.
- Нужна быстрая вставка, удаление и доступ по ключу.
- Ключи уникальны, и важно обеспечить высокую производительность при большом объёме данных.
Отличия от других реализаций Map:
- LinkedHashMap сохраняет порядок вставки. Используется, если важно сохранить последовательность добавления.
- TreeMap хранит элементы отсортированными по ключу. Работает медленнее (O(log n)), но позволяет делать диапазонные запросы.
- Hashtable синхронизирован, но морально устарел. HashMap быстрее и предпочтительнее при отсутствии многопоточности.
- ConcurrentHashMap используется в многопоточной среде. Обеспечивает конкурентный доступ без блокировки всей структуры.
Выбор HashMap оправдан в большинстве однопоточных задач, где не требуется сортировка или порядок элементов.
Как работает сравнение ключей в Map и что учитывать при переопределении equals и hashCode
В реализациях Map, основанных на хешировании (например, HashMap), ключи сравниваются с использованием методов equals() и hashCode(). При добавлении пары ключ-значение сначала вычисляется хеш-код ключа, затем по нему определяется бакет. Если в этом бакете уже есть элементы, Map использует equals() для поиска совпадения по ключу.
Нарушение контракта между equals() и hashCode() приводит к непредсказуемому поведению: объект может не находиться в Map, даже если он логически равен существующему ключу. Контракт требует, чтобы если obj1.equals(obj2) == true, то obj1.hashCode() == obj2.hashCode().
При переопределении equals() необходимо обеспечивать симметричность, рефлексивность и транзитивность. В hashCode() следует использовать те же поля, что и в equals(). Несогласованность приводит к ошибкам при поиске, удалении и замене значений по ключу.
Нельзя изменять поля, участвующие в equals() и hashCode(), после добавления объекта в Map. Например, если в качестве ключа используется объект с изменяемым полем id, и hashCode() зависит от него, после изменения id ключ станет недоступен для Map.
Для классов-ключей рекомендуется делать поля, задействованные в сравнении, финальными. Это исключает ошибки, связанные с мутацией состояния объекта после помещения в Map.
Если используется TreeMap, сравнение ключей осуществляется через compareTo() или Comparator. В этом случае equals() может не использоваться, и важно, чтобы сравнение не противоречило equals(), иначе Map может содержать дубликаты с точки зрения equals(), но не compareTo().
При использовании нестандартных ключей всегда пишите юнит-тесты, проверяющие корректность поиска, удаления и замены значений в Map. Это помогает выявить ошибки в реализации equals() и hashCode().
Особенности итерации по Map: способы обхода и их влияние на производительность
Наиболее производительный способ итерации – через entrySet(). Этот подход позволяет получить сразу ключ и значение без дополнительных вызовов, что снижает накладные расходы. Пример:
for (Map.Entry<K, V> entry : map.entrySet()) {
K key = entry.getKey();
V value = entry.getValue();
}Этот способ быстрее, чем итерация по keySet() с последующим вызовом get(key), так как get() в HashMap требует повторного хеширования и поиска элемента в корзине:
for (K key : map.keySet()) {
V value = map.get(key); // менее эффективно
}Если необходимо только перебрать ключи, а значения не используются, keySet() предпочтительнее, поскольку не создаются объекты Entry. Однако при необходимости доступа к значениям стоит использовать entrySet() – производительность выше за счёт избежания дополнительных обращений.
При использовании forEach() с лямбда-выражением возникает незначительное снижение скорости по сравнению с классическим циклом из-за дополнительных абстракций:
map.forEach((key, value) -> {
// обработка
});В TreeMap итерация осуществляется в отсортированном порядке, что увеличивает затраты из-за логарифмической сложности доступа. В LinkedHashMap итерация сохраняет порядок вставки, при этом скорость обхода сопоставима с HashMap, но требует чуть больше памяти.
Для многопоточного обхода ConcurrentHashMap следует использовать forEach(), так как entrySet() не гарантирует консистентность при изменении содержимого во время итерации.
Рекомендация: при наличии доступа к обоим – ключу и значению – используйте entrySet(); для ключей – keySet(); избегайте get() внутри цикла. Это даёт прирост производительности до 30% в больших Map-коллекциях.
Что происходит при добавлении null в различные реализации Map
В реализации HashMap допускается один null в качестве ключа. Это значение хранится в отдельной ячейке, не связанной с хеш-таблицей. Значения null могут быть любыми и в любом количестве. Добавление пары null – значение приведёт к перезаписи существующего значения, если ключ null уже присутствует.
LinkedHashMap наследует поведение HashMap, поэтому также разрешает один null-ключ и произвольное количество null-значений. Порядок вставки сохраняется, и это не влияет на обработку null.
TreeMap не допускает null в качестве ключа, если используется естественный порядок (Comparable). При попытке вставить такой ключ выбрасывается NullPointerException. При использовании пользовательского Comparator, допускающего null, поведение зависит от его реализации. Значения null допустимы без ограничений.
Hashtable не допускает null ни в качестве ключей, ни в качестве значений. Любая попытка вставки вызывает NullPointerException.
ConcurrentHashMap полностью запрещает null как ключи, так и значения. Это связано с невозможностью отличить отсутствие значения от null в условиях многопоточности.
При проектировании следует учитывать поведение конкретной реализации при работе с null. Для многопоточной среды и критически важных структур null лучше избегать, даже если он допускается.
Как синхронизировать Map в многопоточном контексте: от Collections.synchronizedMap до ConcurrentHashMap

При использовании коллекций типа Map в многопоточном окружении важно обеспечить корректную синхронизацию доступа. В противном случае возможны гонки данных и непредсказуемое поведение программы. В Java предусмотрено несколько способов решения этой задачи.
Collections.synchronizedMap(Map<K,V> map) – обёртка, добавляющая синхронизацию на каждый метод исходной карты. Все вызовы блокируются на общем мониторе, что означает: пока один поток читает или пишет, остальные ждут. Такая синхронизация создаёт узкое место при высокой конкуренции. Дополнительно требуется внешняя синхронизация при итерации:
Map<K,V> syncMap = Collections.synchronizedMap(new HashMap<>());
synchronized(syncMap) {
for (Map.Entry<K,V> entry : syncMap.entrySet()) {
// работа с элементами
}
}
ConcurrentHashMap решает проблему блокировок более эффективно. В версиях до Java 8 использовалась сегментная блокировка – карта делилась на части, доступ к которым синхронизировался независимо. С Java 8 структура изменилась: используется CAS (compare-and-swap), локальные блокировки узлов и оптимизированные операции, такие как computeIfAbsent, putIfAbsent, merge.
ConcurrentHashMap не допускает null ключей и значений – попытка вставки вызывает NullPointerException. Метод forEach этой реализации не требует внешней синхронизации при обходе элементов и допускает модификацию во время итерации. Однако для атомарных операций над несколькими элементами придётся использовать внешние механизмы синхронизации или StampedLock.
Сравнение подходов:
| Подход | Механизм | Плюсы | Минусы |
|---|---|---|---|
| Collections.synchronizedMap | Монитор на весь объект | Простота, совместимость с любой Map | Медленно при высокой конкуренции, нужна синхронизация при итерации |
| ConcurrentHashMap | Частичная блокировка, CAS | Высокая производительность, потокобезопасная итерация | Запрещены null, не поддерживает полную атомарность для нескольких операций |
Для большинства многопоточных задач рекомендуется использовать ConcurrentHashMap. Обёртка через synchronizedMap оправдана только при необходимости использовать нестандартные реализации Map, не имеющие потокобезопасных аналогов.
Где и как применяется TreeMap для сортировки по ключам
TreeMap в Java используется, когда необходимо хранить данные в отсортированном порядке по ключам. Это класс, реализующий интерфейс Map и базируется на структуре данных красно-черного дерева, что обеспечивает логарифмическую сложность операций вставки, удаления и поиска.
Применение TreeMap идеально подходит в следующих ситуациях:
- Поиск элементов по диапазону ключей: TreeMap поддерживает методы
subMap,headMapиtailMap, которые позволяют эффективно извлекать подмножества данных в зависимости от диапазона ключей. Это полезно, например, при работе с временными метками или диапазонами чисел. - Автоматическая сортировка: Если требуется, чтобы ключи всегда оставались отсортированными, TreeMap станет отличным выбором. Например, при ведении статистики по каким-либо данным, где важно, чтобы элементы коллекции всегда шли по возрастанию или убыванию.
- Нужна сортировка с использованием собственного компаратора: TreeMap позволяет задать собственный
Comparatorдля сортировки, что делает его гибким инструментом в случае, когда стандартная сортировка по естественному порядку не подходит. Это применимо, например, при работе с пользовательскими объектами.
Типичные случаи использования TreeMap:
- Реализация справочников и индексов: TreeMap идеально подходит для задач, где ключи представляют собой строки или числа, а их упорядоченность имеет значение, как в случае с поисковыми индексами.
- Работа с финансовыми данными: Когда необходимо хранить и обрабатывать финансовые записи, например, котировки акций, с возможностью быстрого поиска и сортировки по времени, TreeMap будет удобным решением.
- Автоматическая сортировка для отображения данных: В приложениях, где важно отобразить информацию в отсортированном виде (например, список пользователей по алфавиту или отценке), TreeMap автоматически позаботится о правильной сортировке ключей.
Однако стоит учитывать, что TreeMap имеет более высокую стоимость по сравнению с другими коллекциями, такими как HashMap, особенно при операциях вставки и удаления элементов, из-за необходимости поддержания структуры дерева. Важно выбирать этот класс, когда сортировка и эффективность поиска по ключам являются приоритетными.
Вопрос-ответ:
Что такое коллекция Map в Java?
Коллекция Map в Java представляет собой структуру данных, которая хранит элементы в виде пар «ключ-значение». Каждый ключ уникален, и каждый ключ связан с определенным значением. Основные реализации Map включают HashMap, TreeMap и LinkedHashMap. Map используется для быстрого поиска, вставки и удаления элементов по ключу.
Как работает HashMap в Java и в чем его особенности?
HashMap — это реализация интерфейса Map, которая использует хеширование для хранения элементов. Он обеспечивает быстрые операции добавления, удаления и поиска, так как использует хеш-функцию для определения местоположения элементов в хеш-таблице. Основной особенностью HashMap является отсутствие гарантии порядка элементов. Это означает, что порядок хранения элементов может меняться при различных операциях, например, при перезапуске программы.
Что такое TreeMap и чем он отличается от HashMap?
TreeMap также реализует интерфейс Map, но вместо хеширования использует структуру данных «дерево» (обычно красно-черное дерево). Это дает ему преимущество в том, что элементы всегда хранятся в отсортированном порядке по ключу. Однако из-за использования дерева операции вставки и удаления могут быть несколько медленнее, чем в HashMap. TreeMap также не позволяет использовать null в качестве ключа, в отличие от HashMap, который допускает это.
Как связаны LinkedHashMap и HashMap в Java?
LinkedHashMap — это еще одна реализация Map, которая основывается на HashMap, но с дополнительным элементом: порядок элементов в LinkedHashMap сохраняется в том порядке, в котором они были добавлены, или в порядке последнего доступа к элементу (в зависимости от настроек). Это делает LinkedHashMap полезным, когда нужно сохранить порядок вставки или порядок использования элементов, при этом сохраняя преимущества быстрого доступа, как в HashMap.