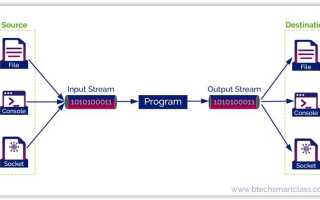
Стримы в Java – это мощный инструмент для работы с коллекциями данных, представленный в рамках API Java 8. Они позволяют эффективно обрабатывать данные, избегая явных циклов и улучшая читаемость кода. Однако для полноценного понимания их работы важно разобрать, как они реализованы и в каких случаях их использование имеет смысл.
Стримы представляют собой последовательности элементов, которые могут быть обработаны параллельно или последовательно. Главное преимущество – это декларативный стиль обработки данных, где операции выполняются через цепочку вызовов методов, что значительно упрощает написание кода. В отличие от традиционного подхода с циклами, стримы используют функциональный стиль, что позволяет минимизировать ошибки и делать код более понятным и компактным.
Основные виды стримов делятся на два типа: потоки данных и параллельные потоки. В первом случае операции выполняются последовательно, что является стандартом для большинства задач. Во втором случае данные обрабатываются параллельно, что значительно ускоряет обработку больших объемов данных при использовании многопроцессорных систем. Для параллельных потоков Java автоматически управляет разделением задач, что позволяет избежать явного использования многозадачности и синхронизации потоков.
Каждый стрим начинается с источника данных – это может быть коллекция, массив, файл или даже генератор случайных чисел. Для выполнения операций над потоком используется множество промежуточных и терминальных операций. Промежуточные операции, такие как map, filter, flatMap, не выполняются сразу, а возвращают новый стрим, что позволяет строить цепочки операций. Терминальные операции, такие как collect, reduce или forEach, завершают обработку и инициируют выполнение всех промежуточных операций.
Использование стримов помогает оптимизировать производительность в случае работы с большими объемами данных. Однако важно помнить, что для малых объемов данных использование стримов может быть менее эффективным из-за дополнительной нагрузки на систему при создании и управлении потоком.
Создание потока данных с использованием Stream API
Stream API в Java предоставляет мощный инструмент для работы с коллекциями данных, позволяя создавать потоки данных, которые могут быть обработаны различными методами функционального стиля. Потоки позволяют обрабатывать данные параллельно и лениво, что повышает производительность при работе с большими объемами информации.
Для создания потока данных достаточно вызвать метод stream() у коллекции, например, у списка или множества. Этот метод возвращает объект типа Stream, с которым можно работать. Важно понимать, что потоки не хранят данные, а лишь представляют собой последовательность операций, которые выполняются над исходными данными.
Пример создания потока из списка:
List numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream numberStream = numbers.stream(); После создания потока можно применить к нему различные операции. Операции делятся на два типа: промежуточные и терминальные. Промежуточные операции, такие как filter(), map(), sorted(), возвращают новый поток и позволяют цепочку операций. Терминальные операции, такие как forEach(), collect(), выполняют реальную обработку данных.
Пример использования фильтрации и преобразования данных:
List names = Arrays.asList("Alice", "Bob", "Charlie", "David");
names.stream()
.filter(name -> name.startsWith("A"))
.map(String::toUpperCase)
.forEach(System.out::println); При работе с большими объемами данных или при необходимости параллельной обработки можно использовать parallelStream(), что позволит задействовать несколько потоков для выполнения операций:
List largeNumbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
largeNumbers.parallelStream()
.map(n -> n * 2)
.forEach(System.out::println); Однако следует помнить, что использование параллельных потоков не всегда дает выигрыш в производительности, особенно для небольших коллекций, где накладные расходы на управление потоками могут превышать выгоды от параллельной обработки.
Использование операций фильтрации и преобразования данных
Стримы в Java предоставляют мощные инструменты для фильтрации и преобразования коллекций данных, что делает код более читаемым и лаконичным. Операции фильтрации позволяют отбирать элементы, которые соответствуют заданному условию, а преобразования изменяют элементы на основе конкретной логики.
Операция фильтрации осуществляется с помощью метода filter. Он принимает в качестве аргумента предикат (условие), который возвращает true или false. Например, для отбора чисел больше 10 из списка можно использовать следующий код:
List numbers = Arrays.asList(5, 12, 8, 20, 15);
List filteredNumbers = numbers.stream()
.filter(n -> n > 10)
.collect(Collectors.toList()); Здесь метод filter отбирает элементы, которые удовлетворяют условию n > 10, и результат сохраняется в новый список. Важно, что filter не изменяет исходный поток, а создает новый.
Для преобразования данных используется метод map, который позволяет изменить элементы потока, применяя к ним функцию. Например, можно преобразовать все строки в верхний регистр:
List words = Arrays.asList("java", "stream", "example");
List upperCaseWords = words.stream()
.map(String::toUpperCase)
.collect(Collectors.toList()); Метод map принимает функцию и применяет её к каждому элементу потока. Результат этой операции – новый поток с преобразованными элементами.
Для сочетания фильтрации и преобразования можно применять эти операции последовательно. Например, чтобы отфильтровать положительные числа, умножить их на два и вывести результат, можно использовать следующую цепочку операций:
List numbers = Arrays.asList(-1, 5, 12, 8, -3, 7);
List transformedNumbers = numbers.stream()
.filter(n -> n > 0)
.map(n -> n * 2)
.collect(Collectors.toList()); Здесь сначала фильтруются только положительные числа, затем каждый из них умножается на два. Эта комбинация позволяет эффективно работать с данными, уменьшив количество промежуточных коллекций.
Важно помнить, что операции filter и map ленивы, то есть они не выполняются до тех пор, пока не будет вызван терминальный оператор, например, collect или forEach. Это позволяет значительно улучшить производительность при обработке больших объемов данных.
Параллельные стримы: как ускорить обработку данных
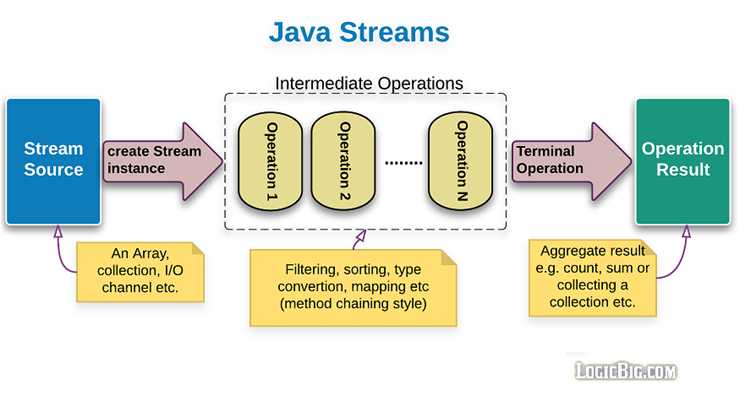
Параллельные стримы в Java позволяют значительно ускорить обработку данных, особенно когда речь идет о крупных объемах информации, например, при работе с коллекциями или массивами. Важно понимать, как правильно использовать параллельные потоки для достижения максимальной производительности.
Для включения параллельной обработки достаточно вызвать метод parallelStream() вместо обычного stream(). При этом данные будут разделены на несколько частей, которые обрабатываются одновременно на разных ядрах процессора. Это может существенно снизить время обработки, особенно в многозадачных системах с несколькими процессорами.
Однако, использование параллельных стримов не всегда оправдано. Прежде чем применять параллельные потоки, стоит учитывать следующие аспекты:
- Размер данных: параллельная обработка эффективна при больших объемах данных. Для небольших коллекций накладные расходы на создание потоков могут перевесить выигрыш по времени.
- Задачи с высокой степенью независимости: параллельные потоки работают быстрее, когда элементы коллекции можно обрабатывать независимо, без зависимости друг от друга.
- Тип операции: операции, которые требуют многократных преобразований (например, сортировка или комбинирование), могут не дать ожидаемого ускорения из-за дополнительных накладных расходов на синхронизацию потоков.
Пример параллельного стрима:
List numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
numbers.parallelStream()
.map(n -> n * 2)
.forEach(System.out::println);
Когда стоит избегать параллельных стримов:
- Когда операция зависит от порядка обработки данных (например, сортировка с сохранением порядка).
- При работе с потоками, которые имеют небольшие размеры или сложные зависимости между элементами.
- Когда операция включает в себя частые блокировки или синхронизацию, что может снизить эффективность многозадачности.
Для тестирования эффективности параллельных стримов полезно использовать System.nanoTime() для измерения времени выполнения до и после применения параллельных потоков.
Обработка исключений при работе со стримами

Лямбда-выражения в стримах не позволяют напрямую выбрасывать проверяемые исключения. Это ограничение требует обходных решений при работе с методами, которые могут их генерировать.
Если метод внутри map, filter или forEach выбрасывает проверяемое исключение, стандартный подход – обернуть вызов в try-catch внутри лямбды. Однако такой код быстро становится громоздким:
list.stream()
.map(item -> {
try {
return someMethod(item);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
})
.collect(Collectors.toList());Для checked-исключений нередко создают вспомогательные обёртки:
@FunctionalInterface
interface CheckedFunction<T, R> {
R apply(T t) throws Exception;
}
static <T, R> Function<T, R> wrap(CheckedFunction<T, R> function) {
return t -> {
try {
return function.apply(t);
} catch (Exception e) {
throw new RuntimeException(e);
}
};
}С этой обёрткой код упрощается:
list.stream()
.map(wrap(item -> someMethod(item)))
.collect(Collectors.toList());Если важно сохранить оригинальное исключение, рекомендуется использовать UncheckedIOException или собственные обёртки вместо RuntimeException для повышения читаемости трассировки.
Для непроверяемых исключений (например, NullPointerException или IllegalArgumentException) обработка стандартная – внутри try-catch блока, если нужно продолжать поток после ошибки. В противном случае они прерывают выполнение стрима.
При использовании parallelStream исключения собираются в CompletionException. Чтобы получить исходную причину, нужно вызвать getCause() после перехвата:
try {
list.parallelStream().forEach(item -> someMethod(item));
} catch (CompletionException e) {
Throwable cause = e.getCause();
// обработка
}Обработка исключений в стримах требует явного управления и часто вынесения логики в отдельные методы для сохранения читаемости.
Генерация и агрегация данных с помощью стримов

Для генерации последовательностей в Java используется метод Stream.generate или Stream.iterate. Первый подходит для создания бесконечных потоков, например, случайных чисел: Stream.generate(Math::random). Второй используется для построения числовых или логических последовательностей: Stream.iterate(0, n -> n + 2) создаёт поток чётных чисел.
Чтобы ограничить бесконечный поток, применяется limit(n). Например, Stream.generate(Math::random).limit(10) создаёт поток из 10 случайных чисел.
Для агрегации данных стрим предоставляет методы reduce, collect, count, sum, average, min, max. Метод reduce позволяет свести поток к одному значению: Stream.of(1, 2, 3).reduce(0, Integer::sum) возвращает 6. Вариант без начального значения возвращает Optional.
Метод collect используется для сбора элементов в коллекции или для группировки. Для простого сбора: collect(Collectors.toList()). Для подсчёта: collect(Collectors.counting()). Для суммирования: collect(Collectors.summingInt(x -> x)). Для группировки: collect(Collectors.groupingBy(String::length)) – группирует строки по длине.
Метод count() возвращает количество элементов в потоке. Для числовых стримов (IntStream, LongStream, DoubleStream) доступны методы sum(), average(), min(), max(). Пример: IntStream.range(1, 5).sum() возвращает 10.
Смешивание операций генерации и агрегации позволяет избежать промежуточных структур. Например, Stream.iterate(1, n -> n + 1).limit(100).map(n -> n * n).reduce(Integer::sum) вычисляет сумму квадратов первых 100 чисел без создания промежуточного списка.
Как избежать утечек памяти при работе с большими объемами данных

При работе с Java Stream и крупными наборами данных важно контролировать потребление памяти. Стримы ленивы, но не освобождают ресурсы автоматически, если ссылаются на внешние объекты или обрабатываются в долго живущих структурах.
- Не сохраняйте Stream в переменные, если он используется один раз. Создание промежуточных переменных может продлить срок жизни объектов внутри стрима.
- Избегайте ссылок на крупные коллекции внутри лямбда-выражений. Такие ссылки не позволяют сборщику мусора освободить память даже после завершения работы стрима.
- Используйте
Stream::closeпри работе сStreamизFiles.linesили других источников, реализующихAutoCloseable. Желательно применятьtry-with-resources. - Не вызывайте
collect(Collectors.toList())без необходимости. Это создаёт полный список в памяти, что нецелесообразно при обработке гигабайтных файлов. - При необходимости сбора результатов в список – используйте ограничения:
limit(),filter()илиdropWhile()доcollect(), чтобы уменьшить размер создаваемой коллекции. - Старайтесь не использовать бесконечные стримы без явного ограничения – они не освобождают ресурсы и приводят к утечкам при неправильной обработке.
- Не вкладывайте стримы в кэшируемые структуры или поля долгоживущих объектов. Это приводит к удержанию всей цепочки объектов.
Для отладки используйте профилировщики памяти, такие как VisualVM, YourKit или JProfiler. Они помогают выявить места, где стримы или связанные с ними объекты не освобождаются сборщиком мусора.
Вопрос-ответ:
Чем стримы отличаются от коллекций в Java?
Главное отличие стримов от коллекций — в способе обработки данных. Коллекции хранят элементы в памяти и позволяют напрямую обращаться к каждому из них. Стримы не хранят данные, а представляют собой последовательность операций над элементами, которые берутся из источника — например, списка или массива. Кроме того, стримы могут быть ленивыми — они откладывают выполнение операций до тех пор, пока не потребуется результат. Это позволяет, например, отфильтровать и отсортировать данные, не проходя по всей коллекции полностью, если это не нужно.
Можно ли использовать один и тот же стрим несколько раз?
Нет, нельзя. Стрим можно использовать только один раз. После того как терминальная операция выполнена (например, `collect`, `count`, `forEach`), стрим считается закрытым. Попытка использовать его повторно приведёт к `IllegalStateException`. Если нужно выполнить несколько разных операций с одними и теми же данными, следует создать новый стрим из исходного источника. Например, можно дважды вызвать `list.stream()`, если работа идёт с коллекцией `list`.
Как работают промежуточные операции в стримах?
Промежуточные операции, такие как `filter`, `map`, `sorted`, не запускаются сразу. Они откладываются до тех пор, пока не будет вызвана терминальная операция. Это называется ленивым выполнением. При этом стрим формирует цепочку, но ничего не делает до тех пор, пока не появится запрос на результат. Благодаря такому подходу можно избежать лишних вычислений — например, если после фильтрации остаётся только один элемент, а требуется, скажем, первый из них, остальные даже не будут обрабатываться.
Что происходит при использовании `parallelStream()`?
`parallelStream()` создаёт параллельный стрим, который разбивает задачи на подзадачи и распределяет их между несколькими потоками. Это может ускорить обработку больших объёмов данных, особенно если операции над элементами независимы друг от друга и не требуют синхронизации. Однако параллельные стримы не всегда быстрее — накладные расходы на создание и управление потоками могут перекрыть выигрыш. Стоит проверять, даёт ли параллельное выполнение реальное преимущество в конкретной ситуации.
Можно ли изменить данные исходной коллекции внутри стрима?
Это не запрещено, но такой подход не рекомендуется. Стримы предполагают, что операции с ними не имеют побочных эффектов. Если внутри `forEach` или `map` изменить данные в коллекции, из которой создавался стрим, результат может быть непредсказуемым. Особенно это опасно при параллельной обработке. Лучше не изменять структуру коллекции в процессе работы стрима, а использовать такие операции, как `map`, `filter`, `collect`, чтобы получить новый результат без изменения исходных данных.