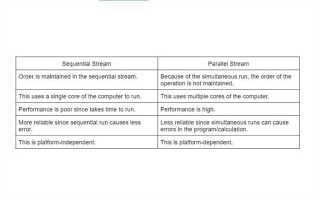
В Java параллельные потоки позволяют эффективно использовать многозадачность и многопоточность, что является ключевым элементом для создания высокопроизводительных приложений. Система потоков в Java включает два основных типа: параллельные и последовательные, и именно параллельная обработка данных является одной из самых эффективных методик для ускорения вычислений в многозадачных приложениях. Для их реализации Java предлагает как низкоуровневые механизмы, такие как Thread, так и более высокоуровневые абстракции через Executor и Stream API.
Особенности параллельных потоков заключаются в эффективном управлении несколькими задачами одновременно, что позволяет значительно ускорить обработку больших объемов данных, особенно на многопроцессорных системах. Однако для правильной реализации параллельных потоков важно учитывать вопросы синхронизации, управления состоянием потоков и предотвращения состояния гонки. Важную роль в этом процессе играет использование java.util.concurrent, который предоставляет классы для безопасного взаимодействия между потоками, такие как ReentrantLock и Semaphore.
Как создать и запустить параллельный поток в Java
В Java параллельные потоки создаются с использованием классов и интерфейсов, предоставляемых стандартной библиотекой. Основные способы создания потока – через наследование от класса Thread и через реализацию интерфейса Runnable.
Для создания потока с помощью класса Thread, необходимо создать подкласс от Thread и переопределить метод run(). Этот метод содержит код, который будет выполняться в отдельном потоке. После этого поток запускается с помощью метода start().
class MyThread extends Thread {
@Override
public void run() {
System.out.println("Параллельный поток запущен");
}
}
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start(); // Запуск потока
}
}
Другой подход – использовать интерфейс Runnable. Это дает возможность избежать наследования от Thread и позволяет реализовывать многозадачность в уже существующих классах. Для этого создается объект, реализующий интерфейс Runnable, и передается в конструктор объекта Thread. Затем вызывается метод start().
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Параллельный поток с Runnable запущен");
}
}
public class Main {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start(); // Запуск потока
}
}
Важно помнить, что метод start() инициирует асинхронное выполнение потока. В случае вызова метода run() напрямую, поток будет выполняться в том же потоке, что и основной поток программы, что не приведет к созданию нового потока.
Для управления параллельными потоками и их синхронизации часто используют такие механизмы, как блокировки (synchronized), а также инструменты из пакета java.util.concurrent (например, ExecutorService). Это позволяет более гибко управлять потоками, их приоритетами и состоянием, а также избегать проблем, связанных с доступом к разделяемым ресурсам.
Особенности работы с потоками через ExecutorService
Основные преимущества использования ExecutorService заключаются в управлении жизненным циклом потоков, возможности масштабирования и оптимизации ресурсов. Через ExecutorService можно организовать выполнение задач параллельно, не заботясь о создании или завершении потоков вручную, что снижает вероятность ошибок и повышает производительность.
При использовании ExecutorService важно учитывать несколько особенностей:
- Пул потоков. ExecutorService создает пул потоков, который может быть настроен с помощью различных реализаций, таких как FixedThreadPool или CachedThreadPool. Выбор пула зависит от типа задачи и требований к производительности. Например,
FixedThreadPoolподходит для задач с ограниченными ресурсами, тогда какCachedThreadPoolэффективен для задач, которые появляются динамически и не требуют постоянного числа потоков. - Шаблон обработки задач. Задачи, передаваемые в ExecutorService, реализуют интерфейс
RunnableилиCallable.Runnableне возвращает результат, в то время какCallableможет вернуть значение или выбросить исключение. Для получения результата выполнения задачи сCallableследует использовать методsubmit(), который возвращает объект типаFuture, позволяющий получить результат или обработать исключения. - Закрытие ExecutorService. После завершения работы с ExecutorService необходимо вызвать метод
shutdown()илиshutdownNow()для корректного завершения работы пула потоков. Методshutdown()завершает работу потока после того, как все задачи будут выполнены, тогда какshutdownNow()пытается немедленно остановить все активные потоки. - Обработка исключений. При работе с потоками через ExecutorService важно тщательно обрабатывать исключения.
Runnableне поддерживает обработку исключений, но сCallableможно обрабатывать исключения через объектFuture, что позволяет избежать незамеченных ошибок в потоке. - Особенности масштабируемости. ExecutorService позволяет динамически управлять количеством потоков в пуле в зависимости от нагрузки. Однако при увеличении числа потоков необходимо учитывать системные ресурсы, такие как память и процессорное время, чтобы избежать перегрузки.
cssEdit
Для эффективной работы с ExecutorService важно правильно выбирать тип пула, оценивать количество доступных системных ресурсов и грамотно обрабатывать исключения. Таким образом, использование ExecutorService позволяет значительно упростить и ускорить параллельное выполнение задач в Java.
Обработка исключений в многозадачном программировании с потоками
В многозадачном программировании с использованием потоков обработка исключений приобретает особое значение. Ошибки, возникшие в одном потоке, могут повлиять на работу других потоков или привести к непредсказуемым результатам. Важно учитывать, что каждый поток работает независимо, и исключения, возникшие в одном потоке, не перехватываются другим потоком. Поэтому для эффективного управления ошибками требуется грамотная стратегия обработки исключений.
Основной подход в обработке исключений в многозадачном программировании – это использование блока try-catch внутри каждого потока. Однако на этом возможности не заканчиваются. Важно помнить, что исключение в одном потоке не останавливает выполнение остальных потоков. Для того чтобы корректно завершить программу или обработать ошибку, может понадобиться использование общих механизмов синхронизации, таких как блокировки, для контроля доступа к общим ресурсам при возникновении исключений.
Для перехвата исключений в потоках в Java можно использовать конструкцию Thread.setUncaughtExceptionHandler(), которая позволяет задать обработчик необработанных исключений. Этот метод полезен, когда исключение не обрабатывается в теле потока, и можно централизованно управлять ошибками, которые возникают в любых потоках. Тем не менее, следует помнить, что этот подход не решает все проблемы, связанные с потоковой безопасностью.
При использовании многозадачности важно учитывать, что исключения, возникшие в одном потоке, могут повлиять на состояние других потоков, если они работают с общими данными. Для безопасного взаимодействия между потоками следует использовать синхронизацию через synchronized или другие механизмы управления доступом, такие как ReentrantLock.
Также важно учитывать ситуацию, когда исключения могут быть выброшены в методах, выполняемых в параллельных потоках, таких как ExecutorService. В этом случае нужно использовать Future.get() для корректной обработки исключений, произошедших в задачах. Метод get() выбрасывает ExecutionException, которая обертывает оригинальное исключение, произошедшее в потоке, что позволяет извлечь и обработать его.
Итак, в многозадачных приложениях ключевыми принципами при обработке исключений являются:
- Постоянная обработка исключений в каждом потоке для предотвращения их распространения.
- Использование обработчиков необработанных исключений для централизованного управления ошибками.
- Грамотное использование синхронизации для защиты общих данных.
- Логирование ошибок для облегчения диагностики и отладки.
- Правильное использование механизмов обработки ошибок в рамках таких конструкций, как
ExecutorService.
При соблюдении этих принципов можно существенно повысить стабильность и предсказуемость многозадачных приложений, минимизируя риски, связанные с возникновением непредвиденных ошибок в отдельных потоках.
Использование синхронизации для предотвращения гонок данных
Гонки данных возникают, когда несколько потоков одновременно обращаются к общим данным, и хотя операции с ними могут быть атомарными, порядок выполнения этих операций непредсказуем. Это может привести к некорректным результатам. Чтобы предотвратить гонки данных, Java предоставляет механизмы синхронизации, позволяющие контролировать доступ потоков к общим ресурсам.
Основной инструмент для синхронизации в Java – это ключевое слово synchronized, которое используется для обеспечения эксклюзивного доступа к критической секции кода. Когда метод или блок кода помечены как синхронизированные, они выполняются только одним потоком в момент времени, что исключает одновременный доступ к общим данным.
Синхронизация может быть реализована на уровне методов или блоков. В первом случае весь метод становится эксклюзивным для одного потока, во втором – только та часть кода, которая заключена в блок synchronized. Блоки синхронизации позволяют более гибко управлять доступом, например, синхронизируя только доступ к конкретной переменной, а не ко всему методу.
Для синхронизации важно правильно выбрать объект, на котором будет происходить блокировка. Для этого обычно используют объект, который является общим для всех потоков. Например, это может быть экземпляр класса, статическая переменная или класс. При использовании блокировки на уровне объекта важно избегать блокировки объектов, которые не могут быть изменены в ходе выполнения программы.
Кроме того, для предотвращения гонок данных и обеспечения целостности данных могут использоваться другие инструменты синхронизации, такие как ReentrantLock из пакета java.util.concurrent.locks. Этот класс предоставляет более гибкие механизмы блокировки, позволяя, например, при необходимости попытаться захватить блокировку без блокировки потока, или контролировать порядок захвата блокировки через условия.
В ситуациях с высокой конкурентностью блокировки могут вызвать значительные потери производительности из-за блокировок и ожидания ресурсов. Для повышения эффективности можно использовать механизмы, такие как volatile для переменных, требующих минимальной синхронизации, или атомарные классы, такие как AtomicInteger и AtomicReference, которые предоставляют атомарные операции над переменными.
Правильное использование синхронизации требует понимания всех возможных ситуаций, в которых потоки могут обращаться к данным. Ключевыми моментами являются правильный выбор блокировок, минимизация времени удержания блокировки и применение более легковесных синхронизационных примитивов, когда это возможно. Это поможет не только избежать гонок данных, но и минимизировать возможные потери производительности в многозадачной среде.
Как избежать блокировок при работе с параллельными потоками
Блокировки возникают при одновременном доступе потоков к разделяемым ресурсам. Это снижает производительность и может привести к взаимоблокировке. Ниже перечислены подходы, которые позволяют минимизировать или исключить блокировки.
- Избегать синхронизации, когда это возможно. Использование неизменяемых объектов и локальных переменных внутри потока исключает необходимость синхронизации. Пример – передача данных через параметры методов вместо доступа к общим полям.
- Применять неблокирующие структуры. Классы из пакета
java.util.concurrent, такие какConcurrentHashMap,ConcurrentLinkedQueue, обеспечивают потокобезопасность без жёстких блокировок. Их реализация использует сегментную или CAS-синхронизацию. - Использовать атомарные переменные. Классы
AtomicInteger,AtomicReferenceи другие изjava.util.concurrent.atomicреализованы на основе низкоуровневых атомарных операций и не требуют явной синхронизации. - Минимизировать область блокировки. Если блокировка необходима, следует ограничить защищаемый участок кода минимально возможным фрагментом. Это снижает вероятность конкуренции между потоками.
- Избегать вложенных блокировок. Не следует захватывать несколько мониторов последовательно без строгого порядка. Отсутствие упорядочивания приводит к deadlock. Все потоки должны захватывать блокировки в одном и том же порядке.
- Рассматривать альтернативы блокировкам. Для координации потоков стоит использовать
Lock-freeиWait-freeалгоритмы, например очередь МСР (Michael-Scott Queue). - Обрабатывать прерывания и таймауты. Методы
tryLockиз интерфейсаLockпозволяют задать ограничение по времени и избежать зависания потока при невозможности получения блокировки.
Практика проектирования многопоточных систем требует предварительного анализа точек синхронизации и отказа от глобального состояния. Это снижает риски блокировок и упрощает отладку.
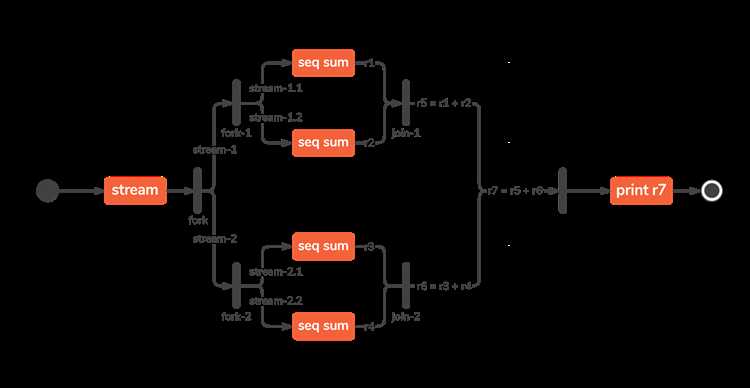
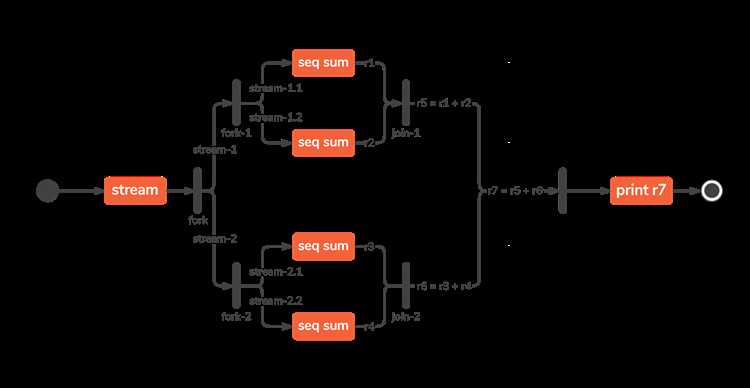
Параллельные потоки в Java 8 и их интеграция с потоками данных (Streams)

В Java 8 интерфейс Stream получил возможность обрабатывать данные параллельно с помощью метода parallel() или parallelStream(). Это позволяет разделить обработку на несколько потоков, используя общий пул ForkJoinPool.
parallelStream()доступен у коллекций и запускает обработку в ForkJoinPool.commonPool().stream().parallel()имеет идентичное поведение, но позволяет переключаться между режимами в рамках одного выражения.
Параллельные потоки уместны при следующих условиях:
- Объём данных достаточен для заметного выигрыша по времени.
- Операции не зависят от порядка выполнения и не содержат состояния.
- Каждый элемент обрабатывается изолированно.
Примеры операций, которые не следует использовать в параллельных потоках:
forEachOrdered()снижает производительность за счёт сохранения порядка.- Модификация внешних переменных может привести к гонкам данных.
- Использование
collect()с небезопасными коллекциями.
Рекомендуемые приёмы:
- Использовать
Collectors.toConcurrentMap()илиtoConcurrentList()при сборе результатов. - Проверять производительность параллельного выполнения с учётом затрат на распараллеливание и объединение.
- Избегать вложенных параллельных потоков – это приводит к деградации производительности и проблемам с ForkJoinPool.
Переопределение общего ForkJoinPool через System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "N") может быть полезно при контроле уровня параллелизма, но требует внимательного подхода в многомодульных приложениях.