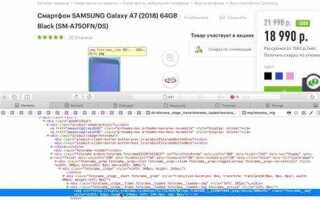
Парсинг данных с веб-страниц с использованием Java часто необходим для извлечения информации из динамичных и часто обновляемых источников. С помощью правильных инструментов можно автоматизировать процесс получения данных для анализа, мониторинга цен или получения сведений для других приложений. Java предоставляет несколько мощных библиотек для решения этой задачи, таких как Jsoup, HtmlUnit и Selenium.
Jsoup – одна из самых популярных библиотек для парсинга HTML. Она предоставляет простой API для извлечения данных, манипулирования документами и их очистки. Библиотека удобна для парсинга статических страниц. Пример кода с использованием Jsoup:
Document doc = Jsoup.connect("https://example.com").get();
Elements titles = doc.select("h1");
for (Element title : titles) {
System.out.println(title.text());
}
Для сложных сценариев, когда требуется имитировать действия пользователя, например, нажимать кнопки или заполнять формы, можно использовать HtmlUnit или Selenium. Эти библиотеки способны взаимодействовать с динамическим контентом, который подгружается с помощью JavaScript.
HtmlUnit позволяет работать с веб-страницами без необходимости в браузере, выполняя JavaScript непосредственно внутри JVM. Однако она имеет ограничения по рендерингу, что делает её менее подходящей для сложных страниц.
Selenium подходит для тестирования и автоматизации веб-приложений, но также отлично справляется с парсингом. В отличие от HtmlUnit, Selenium запускает реальный браузер (например, Chrome или Firefox), что позволяет более точно имитировать поведение пользователя и работать с динамическими страницами, на которых выполняются сложные скрипты.
Как подключить библиотеку Jsoup для парсинга HTML
Для начала работы с библиотекой Jsoup необходимо подключить её к проекту. Существует несколько способов этого сделать, в зависимости от используемой среды разработки.
Если вы используете систему сборки Maven, добавьте следующий фрагмент в файл pom.xml:
org.jsoup jsoup 1.15.3
Для пользователей Gradle добавьте в файл build.gradle следующую строку:
implementation 'org.jsoup:jsoup:1.15.3'
Если вы не используете систему сборки, то можно скачать JAR-файл библиотеки с официального сайта Jsoup и добавить его в проект вручную. Для этого скачайте архив, распакуйте его и добавьте JAR-файл в зависимости проекта через IDE или командную строку.
После подключения библиотеки, можно начать её использовать для парсинга HTML-документов. Пример простого кода для загрузки и парсинга HTML-страницы:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Main {
public static void main(String[] args) {
try {
Document doc = Jsoup.connect("https://example.com").get();
System.out.println(doc.title());
} catch (Exception e) {
e.printStackTrace();
}
}
}
После успешного подключения и настройки библиотеки Jsoup можно приступать к более сложному парсингу, использующему различные методы поиска и обработки элементов HTML.
Получение и обработка HTML-страницы через HTTP-запросы

Для получения данных с веб-сайтов в Java используют HTTP-запросы. Обычно для этого применяют библиотеки, такие как HttpURLConnection или сторонние решения, например, Jsoup. Основной процесс включает отправку запроса на сервер и обработку полученного ответа.
Чтобы отправить запрос, сначала необходимо создать объект HttpURLConnection или использовать библиотеку, которая скрывает детали HTTP-запросов. Важно установить правильный метод запроса, например, GET или POST, в зависимости от требуемых действий.
Пример с использованием HttpURLConnection

import java.net.*;
import java.io.*;
public class HttpExample {
public static void main(String[] args) throws Exception {
URL url = new URL("http://example.com");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String inputLine;
StringBuffer content = new StringBuffer();
while ((inputLine = in.readLine()) != null) {
content.append(inputLine);
}
in.close();
System.out.println(content.toString());
}
}
Использование библиотеки Jsoup
Для более удобной обработки HTML-страниц можно использовать библиотеку Jsoup, которая упрощает парсинг. Jsoup позволяет не только получать страницу, но и эффективно извлекать данные из HTML-документа.
Для добавления библиотеки в проект необходимо подключить зависимость в pom.xml (если используется Maven):
org.jsoup jsoup 1.14.3
Пример получения и обработки HTML-страницы с использованием Jsoup:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class JsoupExample {
public static void main(String[] args) throws Exception {
String url = "http://example.com";
Document doc = Jsoup.connect(url).get();
String title = doc.title();
System.out.println("Title: " + title);
Element body = doc.body();
System.out.println("Body content: " + body.text());
}
}
Здесь Jsoup выполняет запрос на сайт и получает HTML-контент в виде объекта Document. Затем можно извлекать информацию, например, заголовок страницы с помощью метода title() или весь текст тела документа через body().
Обработка ошибок и задержки
При работе с HTTP-запросами важно учитывать возможные ошибки, такие как тайм-ауты, ошибки соединения или неверные ответы от сервера. Для управления этим можно настроить параметры тайм-аутов или использовать блоки try-catch для перехвата исключений, таких как IOException.
- Использование метода
setConnectTimeout()позволяет задать время ожидания подключения. setReadTimeout()регулирует время ожидания ответа после установления соединения.- Рекомендуется также проверять статус ответа сервера, например, через
getResponseCode(), чтобы убедиться в успешности запроса.
Пример обработки ошибок с тайм-аутами:
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setConnectTimeout(5000);
connection.setReadTimeout(5000);
try {
int status = connection.getResponseCode();
if (status == 200) {
// Обработка успешного ответа
} else {
// Обработка ошибок
}
} catch (IOException e) {
System.out.println("Ошибка запроса: " + e.getMessage());
}
Для обработки медленных запросов или отказа сервера можно также настроить политику повторных попыток.
Заключение

Правильное использование HTTP-запросов в Java позволяет эффективно получать и обрабатывать данные с веб-сайтов. Независимо от того, используется ли HttpURLConnection или более высокоуровневая библиотека Jsoup, важно учитывать особенности подключения, обработку ошибок и настройки для оптимизации работы с сетью.
Парсинг данных с помощью CSS-селекторов в Jsoup
Jsoup предоставляет мощные возможности для парсинга HTML-документов, включая поддержку CSS-селекторов для выборки элементов. Это позволяет извлекать данные с веб-страниц, используя привычный синтаксис, аналогичный тому, что применяется в CSS для стилизации элементов.
Для начала необходимо подключить библиотеку Jsoup в проект. Добавьте зависимость в файл pom.xml, если используете Maven:
org.jsoup jsoup 1.15.3
После этого можно приступить к парсингу. Основной метод для работы с CSS-селекторами в Jsoup – select(). Он позволяет выбрать элементы на странице, используя стандартный синтаксис CSS.
Пример парсинга:
Document doc = Jsoup.connect("https://example.com").get();
Elements elements = doc.select(".classname"); // Выбирает все элементы с классом "classname"
Можно использовать различные виды CSS-селекторов, такие как:
element.classname– для выбора элементов по классу.element#id– для выбора элемента по id.element > child– для выбора дочерних элементов.element + next– для выбора следующего соседнего элемента.
Для извлечения текста или атрибутов из элементов можно использовать методы text() и attr(). Например:
String text = elements.text(); // Извлекает текст из выбранных элементов
String link = elements.attr("href"); // Извлекает значение атрибута "href"
Если необходимо выполнить более сложный парсинг, можно комбинировать CSS-селекторы. Например, чтобы выбрать все ссылки в блоке с определённым классом, используйте:
Elements links = doc.select(".block-class a"); // Все ссылки в блоке с классом "block-class"
Jsoup также поддерживает использование псевдоклассов, таких как :first, :last, :nth-child(), что даёт дополнительные возможности для фильтрации элементов:
Element firstLink = doc.select("a:first-of-type").first(); // Первая ссылка на странице
Использование CSS-селекторов в Jsoup делает код более читаемым и компактным, позволяя гибко манипулировать элементами HTML-документа без необходимости писать сложные циклы или регулярные выражения.
Обработка ошибок при парсинге HTML-документов
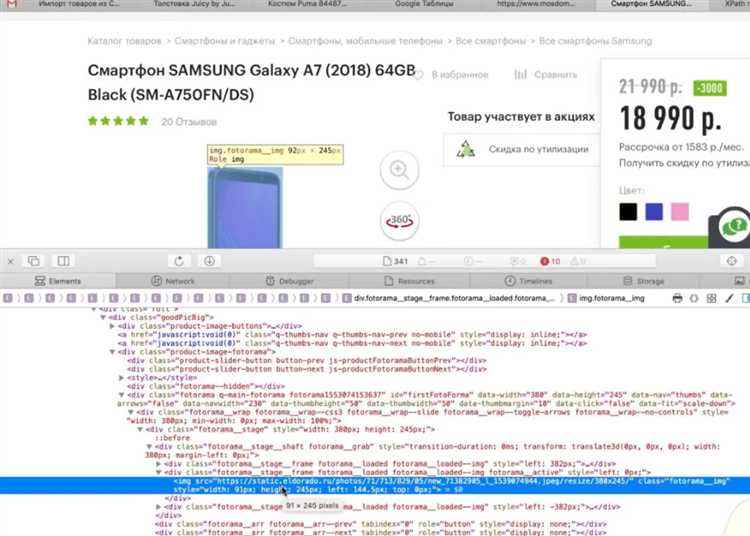
При парсинге HTML-документов на Java важно учитывать различные ошибки, которые могут возникнуть на разных этапах работы с данными. Эти ошибки могут быть связаны с некорректным содержимым документа, проблемами сети, ограничениями ресурсов или ошибками в коде парсера.
Ниже представлены основные подходы к обработке ошибок в процессе парсинга:
- Ошибки сети: Часто при парсинге данных с удаленных ресурсов возникают проблемы с подключением. Это могут быть тайм-ауты, отказ в доступе или проблемы с DNS. Чтобы обработать такие ошибки, можно использовать конструкцию try-catch и задать обработку исключений, например, через
SocketTimeoutExceptionилиUnknownHostException. - Невалидный HTML: HTML-документы могут содержать некорректный синтаксис, который парсер не может обработать. Использование библиотеки Jsoup позволяет минимизировать такие проблемы, так как она автоматически исправляет большинство ошибок в структуре документа. Важно следить за тем, чтобы парсер не остановился при встрече с некорректным тегом, для этого можно использовать настройки для игнорирования ошибок в парсере.
- Неудачные XPath или CSS-селекторы: При использовании XPath или CSS-селекторов могут возникать ошибки, если элемент не найден или структура документа изменилась. Чтобы избежать таких ситуаций, всегда проверяйте, что выбранный элемент существует, прежде чем работать с ним. В случае отсутствия элемента можно использовать
Optionalдля обработки такого случая. - Проблемы с кодировкой: Ошибки могут возникнуть при неправильном распознавании кодировки страницы. Если кодировка не указана явно в мета-тегах HTML, рекомендуется использовать библиотеки для автоматического определения кодировки, например,
CharsetDetector. - Отсутствие или повреждение данных: Если HTML-документ не содержит необходимых элементов, важно предусмотреть соответствующую обработку ошибок. Например, можно возвращать пустые значения или сообщения о ненахождении данных, чтобы не нарушать процесс обработки в дальнейшем.
Важным аспектом является использование логирования ошибок. Регулярно логируйте ошибки с детальной информацией о том, что произошло, включая URL документа, дату и время, тип ошибки и стек вызовов. Это поможет при отладке и поддержке кода в будущем.
Пример обработки ошибок в коде парсинга:
try {
Document doc = Jsoup.connect("http://example.com").get();
Element element = doc.select("div#content").first();
if (element != null) {
// Обработка элемента
} else {
// Логирование отсутствующего элемента
}
} catch (IOException e) {
// Логирование ошибок при сетевых проблемах
e.printStackTrace();
} catch (Exception e) {
// Логирование других ошибок
e.printStackTrace();
}
Как извлекать данные из таблиц и списков на веб-странице
Для парсинга данных из таблиц и списков на веб-странице часто используют библиотеку JSoup. Эта библиотека позволяет легко работать с HTML-кодом, извлекая нужные данные с минимальными усилиями.
Для начала нужно получить HTML-страницу. Если она доступна по URL, можно использовать метод Jsoup.connect(url).get() для загрузки документа. После этого данные из таблиц и списков извлекаются с помощью CSS-селекторов.
Чтобы извлечь данные из таблицы, необходимо найти сам элемент <table>. Например, чтобы выбрать все строки таблицы, используйте селектор table tr. Для получения данных из ячеек строки (например, <td>) применяйте такой подход:
Elements rows = document.select("table tr");
for (Element row : rows) {
Elements cols = row.select("td");
for (Element col : cols) {
System.out.println(col.text());
}
}Если таблица содержит заголовки, можно использовать селектор th для их извлечения. Чтобы получить конкретную ячейку, можно использовать индекс в select.
Извлечение данных из списков происходит аналогично. Для <ul> или <ol> используйте селектор ul li или ol li, чтобы пройти по всем элементам списка. Код для извлечения элементов списка:
Elements listItems = document.select("ul li");
for (Element item : listItems) {
System.out.println(item.text());
}Если необходимо извлечь атрибуты, например, ссылок (<a href>), можно обратиться к атрибутам с помощью метода attr():
Elements links = document.select("a");
for (Element link : links) {
System.out.println(link.attr("href"));
}Для более сложных структур можно комбинировать селекторы. Например, для извлечения данных из таблицы внутри определённого <div> используйте div table tr.
Используя эти методы, можно эффективно извлекать данные из различных структур HTML, таких как таблицы и списки, минимизируя код и избегая излишних вычислений.
Извлечение и обработка ссылок с сайта с помощью Java
Для парсинга ссылок с веб-страниц в Java используется библиотека Jsoup, которая позволяет эффективно извлекать данные из HTML-документов. Эта библиотека поддерживает работу с HTML-документами, а также предоставляет инструменты для поиска и обработки элементов.
Чтобы извлечь все ссылки с веб-страницы, необходимо загрузить HTML-контент с помощью Jsoup и затем найти все теги , которые содержат атрибут href. Пример кода:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class LinkExtractor {
public static void main(String[] args) {
try {
String url = "https://example.com";
Document doc = Jsoup.connect(url).get();
Elements links = doc.select("a[href]");
for (Element link : links) {
String linkHref = link.attr("href");
System.out.println(linkHref);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Для корректной обработки ссылок, нужно учитывать их тип. Например, если ссылка относительная, необходимо преобразовать ее в абсолютный путь, используя базовый URL страницы. Это можно сделать с помощью метода URL из пакета java.net:
import java.net.URL;
public class URLResolver {
public static String resolveURL(String baseUrl, String relativeUrl) {
try {
URL base = new URL(baseUrl);
URL resolved = new URL(base, relativeUrl);
return resolved.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
В данном примере метод resolveURL преобразует относительную ссылку в абсолютную, используя базовый URL страницы.
Если необходимо отфильтровать ссылки, можно использовать регулярные выражения или методы фильтрации из библиотеки Jsoup. Например, чтобы извлечь только те ссылки, которые ведут на страницы с определенным расширением (.pdf, .jpg и т.д.), можно применить фильтрацию по атрибуту href:
Elements pdfLinks = doc.select("a[href$=.pdf]");
for (Element link : pdfLinks) {
System.out.println(link.attr("href"));
}
Это позволяет точечно извлекать нужные данные, исключая ненужные ссылки.
Также стоит обратить внимание на обработку исключений и ошибок. В процессе парсинга могут возникать различные проблемы: несуществующие страницы, неправильные URL, ошибки соединения. Для устойчивой работы программы рекомендуется использовать обработку ошибок с помощью блоков try-catch.
После извлечения ссылок их можно обработать: например, сохранить в базу данных, выполнить дополнительную фильтрацию или использовать в других частях программы для дальнейшего анализа.
Автоматизация парсинга с использованием многозадачности
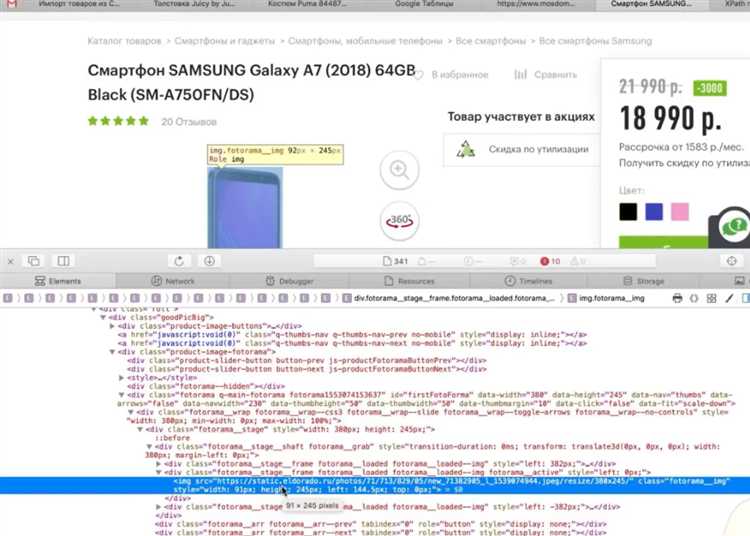
Многозадачность в парсинге позволяет значительно ускорить процесс сбора данных с сайтов, эффективно используя ресурсы компьютера. В Java для реализации многозадачности часто применяют потоки и пулы потоков. Это позволяет параллельно выполнять несколько задач, что особенно важно при работе с большим объемом информации.
Основной принцип заключается в том, чтобы каждую задачу – например, запрос данных с отдельной страницы или раздела сайта – выполнять в отдельном потоке. Это позволяет избежать блокировок и минимизировать время ожидания между запросами. Для этого часто используют ExecutorService – интерфейс, который упрощает управление потоками. С его помощью можно создать пул потоков, контролировать их количество и эффективно распределять задачи.
Пример реализации многозадачного парсинга с использованием ExecutorService:
ExecutorService executor = Executors.newFixedThreadPool(10); // Создаем пул с 10 потоками
for (String url : urls) {
executor.submit(() -> {
// Логика парсинга данных с URL
parseData(url);
});
}
executor.shutdown(); // Завершаем работу пула
Ключевое внимание стоит уделить балансировке нагрузки. Чем больше потоков в пуле, тем быстрее будет проходить обработка, но важно не перегрузить систему. Для большинства случаев оптимальным будет использование пула из 10-20 потоков, что обеспечивает хорошую производительность без значительных потерь на управление потоками.
Важным моментом является синхронизация доступа к общим ресурсам. При работе с многозадачностью необходимо учесть, что несколько потоков могут одновременно пытаться изменить одни и те же данные. Для этого используют различные механизмы синхронизации, такие как synchronized блоки или ReentrantLock.
Также для увеличения производительности стоит использовать асинхронные запросы (например, с использованием библиотеки AsyncHttpClient или HttpURLConnection) для одновременного получения данных с нескольких URL. Это избавляет от задержек, связанных с ожиданием ответа от сервера, и позволяет работать с данными быстрее.
Для повышения надежности стоит внедрить механизмы обработки ошибок и повторных попыток в случае неудачи запроса. Это обеспечит стабильную работу даже при нестабильности сети или проблемах на стороне сервера.
Вопрос-ответ:
Какие библиотеки на Java подходят для парсинга HTML?
Самая популярная библиотека — Jsoup. Она проста в использовании, поддерживает выбор элементов с помощью CSS-селекторов и не требует внешних зависимостей. Для более сложных случаев, когда нужно обрабатывать JavaScript, используется Selenium WebDriver. Он запускает полноценный браузер и позволяет получить финальную версию страницы, включая загруженный скриптами контент.