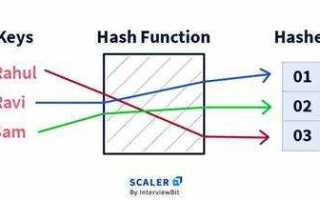
В Java метод hashCode() используется для преобразования объекта в уникальное числовое значение, которое служит для эффективного поиска и сравнения объектов в коллекциях, таких как HashMap, HashSet и других структурах данных на основе хеширования. Этот процесс критически важен для быстродействия и оптимизации работы с большими объемами данных, поскольку правильная реализация hashCode() напрямую влияет на производительность и корректность работы коллекций.
Алгоритм вычисления хеш-кода должен быть таким, чтобы объекты с одинаковыми значениями (сравниваемые через equals()) всегда имели одинаковый хеш-код, но при этом разные объекты должны иметь, в идеале, различные хеш-коды. Когда метод hashCode() реализован неправильно, это может привести к чрезмерному количеству коллизий, что в свою очередь замедляет операции поиска, вставки и удаления элементов в коллекциях.
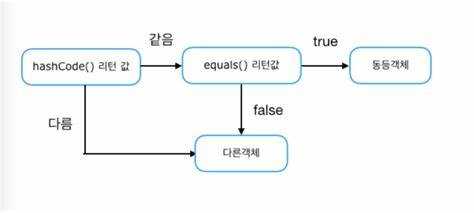
Важное значение имеет соблюдение контрактов между hashCode() и equals(). Если два объекта равны (то есть метод equals() возвращает true), то их хеш-коды обязаны быть одинаковыми. Однако хеш-коды не обязаны быть одинаковыми для неравных объектов. Это позволяет коллекциям, основанным на хешировании, эффективно группировать элементы и минимизировать число столкновений в хеш-таблицах.
Что такое hashcode и как его вычисляет Java?
В Java метод hashCode() используется для генерации уникального целочисленного значения, которое представляет объект. Это значение помогает эффективно организовывать данные в коллекциях, таких как HashMap и HashSet. Правильная реализация hashCode() критична для производительности этих структур данных, поскольку она влияет на распределение объектов по корзинам (buckets).
Метод hashCode() возвращает целое число, основанное на содержимом объекта. Важное правило заключается в том, что два равных объекта, согласно методу equals(), должны иметь одинаковые значения hashCode(). В противном случае коллекции, использующие хеширование, могут работать некорректно.
Как Java вычисляет hashCode() для объектов? В случае стандартных классов, таких как String, Integer и других, метод вычисляется на основе значений полей объекта. Для пользовательских классов hashCode() обычно реализуется вручную, но рекомендуется следовать стандартному алгоритму, который используют стандартные классы Java. Рассмотрим типичный пример вычисления хеш-кода.
Алгоритм для вычисления hashCode() выглядит следующим образом:
int result = 1; result = 31 * result + field1; result = 31 * result + field2; result = 31 * result + field3; ...
Здесь 31 – это простое число, которое используется для усиления распределения хеш-кодов. В каждой итерации результат умножается на 31 и добавляется хеш-код соответствующего поля объекта. Чем больше полей в объекте, тем сложнее хеш-код.
Важное замечание: при переопределении метода hashCode() необходимо также переопределять equals(). Несоответствие этих методов может привести к некорректной работе коллекций, таких как HashMap, что в свою очередь замедлит выполнение операций поиска, вставки и удаления элементов.
Роль hashcode в структуре данных HashMap
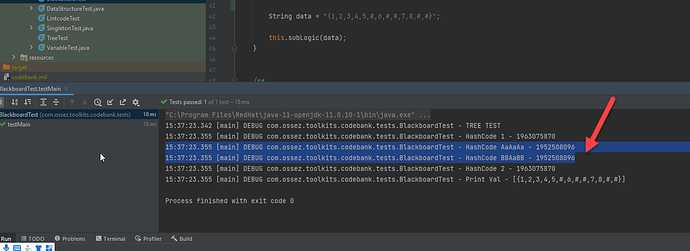
При добавлении пары ключ-значение в HashMap Java вычисляет хеш-код ключа с помощью метода hashCode(). Этот хеш-код используется для выбора корзины, в которую будет помещён элемент. Если два разных ключа имеют одинаковые хеш-коды, происходит коллизия, и оба элемента будут храниться в одной корзине, но с использованием связанного списка или другой структуры для разрешения коллизий.
Важно отметить, что хеш-код должен быть стабилен: он должен оставаться одинаковым в течение всего времени жизни объекта, если объект не изменяется. Это критично, так как изменение хеш-кода после добавления элемента в коллекцию может привести к нарушению целостности структуры данных, а, следовательно, к ошибкам в поиске и удалении элементов.
Кроме того, хеш-код не должен сильно зависеть от значений полей объекта, чтобы избежать чрезмерных коллизий. Хороший хеш-код должен равномерно распределять ключи по корзинам, минимизируя количество элементов в каждой корзине и, как следствие, повышая производительность операций.
При реализации метода hashCode() следует учитывать несколько аспектов. Он должен быть быстро вычисляемым и обеспечивать низкое количество коллизий. Один из популярных способов генерации хеш-кодов – это комбинирование хеш-кодов всех полей объекта, что уменьшает вероятность коллизий, особенно для сложных объектов с несколькими полями.
Для оптимизации работы HashMap важно использовать хороший хеш-функции, минимизирующие количество коллизий и равномерно распределяющие элементы по корзинам. Если в коллекции наблюдается много коллизий, это может привести к ухудшению производительности, так как время поиска, добавления и удаления элементов увеличится из-за необходимости обхода цепочек.
Почему переопределение метода hashCode важно для коллекций
Переопределение метода hashCode критически важно для правильной работы коллекций в Java, таких как HashMap, HashSet и других, основанных на хешировании. Этот метод отвечает за вычисление хеш-кода объекта, который используется для распределения объектов по хеш-таблицам. В случае неправильного или отсутствующего переопределения hashCode, может нарушиться логика работы этих коллекций, что приведет к непредсказуемым результатам, таким как неправильная идентификация объектов или их потеря.
Когда объект добавляется в коллекцию, основанную на хешировании, его хеш-код используется для определения «позиций» в структуре данных, где он будет храниться. Если hashCode не переопределен, то объекты с одинаковым содержимым могут оказаться в разных местах, или, наоборот, один и тот же объект может попасть в несколько мест, создавая конфликты. Это значительно ухудшает производительность поиска, вставки и удаления элементов.
Особенности переопределения hashCode: Для правильного функционирования коллекций, метод hashCode должен соблюдать два важных контракта:
- Если два объекта равны по методу
equals, то их хеш-коды должны быть одинаковыми. - Если два объекта не равны по методу
equals, их хеш-коды могут быть разными, но желательно, чтобы они равномерно распределялись по хеш-таблице.
Невыполнение этих требований может привести к потере производительности, так как в худшем случае все элементы коллекции окажутся в одном «корзинке», и поиск будет происходить за линейное время. Это значительно ухудшает эффективность работы алгоритмов, использующих хеш-таблицы. Рекомендуется также избегать использования полей, которые часто меняются (например, уникальные идентификаторы), в вычислении хеш-кода, так как это может привести к ошибкам при поиске или удалении объектов.
В общем, правильное переопределение метода hashCode позволяет не только обеспечивать корректную работу коллекций, но и существенно повышать производительность операций с ними, минимизируя коллизии и обеспечивая правильное распределение объектов.
Как связаны hashcode и equals при работе с коллекциями
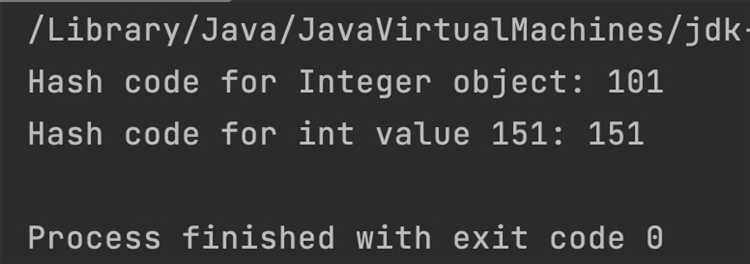
Методы hashCode и equals в Java играют ключевую роль при работе с коллекциями, такими как HashMap, HashSet и другие, использующие хеширование для организации данных. Правильная реализация этих методов обеспечит корректную работу этих коллекций, особенно в контексте поиска и хранения объектов.
Метод hashCode генерирует числовой код для объекта, который используется для быстрого поиска объектов в коллекциях, основанных на хеш-таблицах. Когда объект добавляется в коллекцию, его hashCode вычисляется и используется для определения «группы» или «корзины», в которую он попадет. Однако hashCode сам по себе не обеспечивает уникальности объекта, и два разных объекта могут иметь одинаковые hashCode значения.
Метод equals выполняет сравнение объектов на уровне значений. Когда два объекта имеют одинаковый hashCode, метод equals используется для проверки, являются ли эти объекты идентичными. Это особенно важно в HashSet и HashMap, где поиск и добавление объектов зависит от правильного сравнения объектов. Если equals не переопределен, стандартная версия этого метода из класса Object сравнивает объекты по ссылке, что может привести к неправильным результатам при работе с коллекциями.
Связь между hashCode и equals критична: если два объекта равны с точки зрения метода equals, их hashCode должен быть одинаковым. Нарушение этого правила может привести к ошибкам в поведении коллекций, таких как неправильное нахождение или добавление элементов. Например, если equals возвращает true для двух объектов, а их hashCode различен, то эти объекты могут быть неправильно обработаны в коллекциях, использующих хеширование, таких как HashSet или HashMap.
Рекомендуется всегда переопределять оба метода одновременно. Если equals возвращает true, то hashCode должен быть одинаковым, иначе это нарушит контракт между этими методами и приведет к непредсказуемым результатам. В то же время, если два объекта имеют разные hashCode, метод equals не будет вызываться, что обеспечивает большую производительность.
При проектировании классов, которые будут использоваться в коллекциях, важно соблюдать эту зависимость, чтобы избежать логических ошибок и потери производительности. Для повышения производительности можно использовать более сложные алгоритмы вычисления hashCode, например, комбинировать поля, которые участвуют в определении равенства объектов.
Что происходит при коллизиях в хеш-таблицах Java?
Коллизия в хеш-таблице происходит, когда два разных объекта имеют одинаковое значение хеш-кода, то есть оба объекта попадают в одну и ту же ячейку массива. Это стандартная ситуация для хеш-таблиц, и Java использует несколько подходов для решения этой проблемы.
Основные методы обработки коллизий в хеш-таблицах Java:
- Цепочки (Chaining): В случае коллизии каждый элемент в ячейке массива хранит ссылку на связанный список (или другую коллекцию). Это позволяет нескольким элементам с одинаковым хеш-кодом находиться в одной ячейке. При этом доступ к элементам по хеш-коду будет требовать обхода связанного списка, что может снизить производительность, если в ячейке много элементов.
- Открытая адресация: Если в ячейке возникает коллизия, то ищется следующая свободная ячейка в массиве с использованием различных стратегий. Наиболее распространенные методы:
- Линейное пробирование: В случае коллизии производится проверка следующей ячейки в массиве. Если она занята, поиск продолжается, пока не будет найдена пустая ячейка.
- Квадратичное пробирование: Вместо того чтобы двигаться по ячейкам линейно, используется квадратное увеличение шага (например, i^2), что снижает вероятность возникновения длинных цепочек проб, улучшая распределение значений в массиве.
- Двунаправленное пробирование: При возникновении коллизии элементы ищутся как в направлении вперед, так и назад по массиву. Этот метод позволяет уменьшить количество проб, особенно при высоких нагрузках.
- Реорганизация массива: В случае частых коллизий может быть полезно увеличить размер массива хеш-таблицы и перераспределить элементы с новым хешированием. Это делается автоматически, например, при использовании класса
HashMapв Java, который начинает реорганизацию при достижении определенной нагрузки.
Решение коллизий напрямую влияет на производительность хеш-таблицы. В цепочках время поиска может увеличиваться при большом количестве коллизий, а в методах с открытой адресацией – при плотном заполнении таблицы. Однако подходы, такие как реорганизация массива или использование более сложных методов пробирования, помогают поддерживать стабильную производительность.
Для уменьшения вероятности коллизий важно правильно выбирать хеш-функцию, которая обеспечит равномерное распределение элементов по таблице. В Java хеш-код по умолчанию (метод hashCode()) может быть не оптимален для некоторых типов объектов, поэтому рекомендуется переопределить его для классов, используемых в хеш-таблицах.
Как правильно реализовать метод hashCode для собственных классов
1. Соблюдение контракта hashCode
Контракт метода hashCode предписывает, что два равных объекта (по методу equals) должны иметь одинаковые хеш-коды. Это правило необходимо соблюдать при реализации метода, иначе могут возникнуть проблемы при работе с коллекциями, которые полагаются на этот принцип для корректной работы. Нарушение этого контракта может привести к неожиданным результатам, например, потерям данных при добавлении в HashSet.
2. Расчет хеш-кода на основе значимых полей
Для вычисления хеш-кода следует использовать все важные поля, которые участвуют в сравнении объектов в методе equals. Например, если класс имеет два поля, name и age, которые определяют равенство объектов, то хеш-код должен быть основан на этих полях. Рекомендуется комбинировать их с использованием простых арифметических операций (например, умножение и сложение), чтобы минимизировать количество коллизий.
3. Использование констант для улучшения распределения
Одним из популярных способов вычисления хеш-кода является использование фиксированных констант, таких как 31, для повышения равномерности распределения хеш-кодов. Пример:
@Override
public int hashCode() {
int result = 17; // начальное значение
result = 31 * result + (name != null ? name.hashCode() : 0);
result = 31 * result + age;
return result;
}
Константа 31 была выбрана благодаря своей простоте и хорошей производительности при вычислениях, так как она является простым числом и позволяет эффективно распространять значения по диапазону хеш-кодов.
4. Обработка null значений
Необходимо учитывать возможность null-значений в полях. При их наличии важно предусмотреть защиту от NullPointerException. Например, для строковых полей можно использовать конструкцию name != null ? name.hashCode() : 0, что позволит вернуть нулевой хеш-код для null.
5. Оценка производительности и уникальности
При проектировании метода hashCode важно найти баланс между сложностью вычислений и количеством коллизий. Переусложнение алгоритма может ухудшить производительность при работе с большими коллекциями. Важно, чтобы хеш-коды равномерно распределялись по возможному диапазону значений, иначе коллекции, основанные на хешах, могут деградировать до линейного поиска.
6. Использование стандартных библиотечных решений
Если ваш класс не является сложным и не требует особой логики для генерации хеш-кодов, можно воспользоваться готовыми решениями из стандартной библиотеки. Например, Objects.hash(Object... values) или Objects.hashCode(Object o) обеспечивают простое и корректное вычисление хеш-кодов для обычных классов.
Однако, если ваш класс имеет специфичные требования, важно следовать описанным рекомендациям для правильной реализации hashCode, что поможет избежать ошибок и повысит эффективность работы с коллекциями.
Как выбрать подходящий тип коллекции для объектов с переопределённым hashCode
Выбор правильной коллекции для объектов с переопределённым методом hashCode зависит от особенностей алгоритмов, которые эти коллекции используют для хранения и поиска элементов. В Java коллекции с хешированием, такие как HashMap, HashSet, и другие, значительно выигрывают по производительности, но требуют особого внимания к правильности реализации hashCode и equals. Рассмотрим, как выбрать наиболее подходящий тип коллекции для таких объектов.
Основные факторы, которые влияют на выбор коллекции:
- Равенство объектов (equals): Если объекты, которые вы планируете хранить, одинаковы по содержимому, но имеют разные хеш-коды, это приведет к созданию дополнительных записей в коллекции и замедлит операции поиска.
- Распределение хеш-кодов: Если хеш-коды объектов плохо распределены, например, множество элементов имеет одинаковые значения хеш-кодов, это приведет к возникновению коллизий, что снизит производительность.
- Тип операций с коллекцией: Коллекции, которые чаще всего используются для вставки и удаления элементов, могут иметь разные характеристики производительности в зависимости от количества коллизий в хеш-таблице.
Типы коллекций:
- HashSet: Эту коллекцию следует выбирать, если вам нужно хранить уникальные элементы, и вы хотите обеспечить быстрые операции добавления, удаления и проверки на присутствие. Важно, чтобы метод hashCode был хорошо распределен, чтобы избежать чрезмерных коллизий.
- HashMap: Если ключи в карте имеют переопределенный hashCode, важно убедиться, что их хеш-коды эффективно распределяются по корзинам. Плохое распределение может привести к деградации производительности на O(n), где n – количество элементов в коллекции.
- LinkedHashSet: Подходит для сохранения порядка добавления элементов, при этом элементы должны иметь корректно переопределённый hashCode и equals. Используется, когда важен порядок, но не так критична производительность, как в HashSet.
- TreeSet: Этот тип коллекции использует красно-черное дерево для хранения элементов, и хеш-коды не играют роли. Однако если элементы должны быть отсортированы, а не просто уникальны, TreeSet будет лучшим выбором.
- ConcurrentHashMap: Подходит для многопоточных приложений. Если ваш объект с переопределённым hashCode используется в таких условиях, важно минимизировать количество коллизий, так как это улучшит производительность в многозадачной среде.
При выборе коллекции для объектов с переопределённым hashCode важно учитывать не только правильность реализации методов hashCode и equals, но и требования к производительности. Например, если вам нужно часто искать элементы по ключу, HashMap будет хорошим выбором, но если важно поддерживать порядок элементов, лучше использовать LinkedHashSet или TreeSet.
Как улучшить производительность поиска в коллекциях с хешированием
Первым шагом является правильная реализация хеш-функции. Чем более равномерно распределены значения хешей, тем меньше коллизий происходит. Использование стандартных хеш-функций, таких как Objects.hash(), может привести к неэффективному распределению для специфичных типов данных. Для улучшения производительности важно создавать хеш-функцию, которая минимизирует возможность коллизий. В случае сложных объектов, рекомендуется комбинировать хеши ключевых полей с использованием простых математических операций, например, умножение на простые числа.
Кроме того, выбор размера начальной ёмкости коллекции влияет на количество коллизий и производительность. При создании коллекции с хешированием, таких как HashMap, важно правильно установить начальную ёмкость и коэффициент загрузки. Например, установка начальной ёмкости в 16 и коэффициента загрузки 0.75 является стандартом, но в некоторых случаях имеет смысл увеличить ёмкость, если предполагается большое количество элементов. Это снизит количество перераспределений при добавлении новых элементов.
Важным моментом является выбор правильной структуры данных для хранения хешированных элементов. Если в коллекции часто возникают коллизии, где элементы имеют одинаковые хеши, использование связанных списков для хранения таких элементов может замедлить поиск. В этом случае полезно рассмотреть возможность использования сбалансированных деревьев или других структур, которые обеспечат более быстрое нахождение элемента при коллизиях.
Также важно учитывать работу с параллельными коллекциями. Для многопоточных приложений стоит использовать ConcurrentHashMap, так как она эффективно распределяет нагрузку и минимизирует блокировки, что может существенно повысить производительность при одновременном доступе к коллекции.
Наконец, регулярное использование методов resize() и rehash() для корректной работы коллекций также способствует улучшению производительности. Определение оптимального времени для их использования важно для предотвращения излишних перераспределений при добавлении элементов в коллекцию.