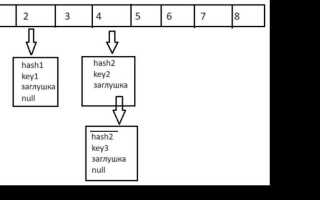
HashSet – это коллекция в Java, которая реализует интерфейс Set и предоставляет уникальные элементы в произвольном порядке. Основной особенностью является отсутствие дублирующихся значений. При добавлении элемента в HashSet, если элемент уже существует в коллекции, он не будет добавлен повторно. Это достигается благодаря использованию хэш-таблицы для хранения объектов.
При добавлении элементов в HashSet важно понимать, что для корректной работы коллекции объекты должны правильно переопределять методы hashCode() и equals(). Эти методы используются для вычисления хэш-кодов и проверки эквивалентности объектов, что позволяет эффективно выполнять операции добавления, удаления и поиска элементов.
Особенность HashSet заключается в его производительности. Операции вставки, удаления и проверки на присутствие элемента имеют временную сложность O(1) в среднем случае. Это объясняется тем, что коллекция использует хэш-таблицу для быстрого доступа к элементам. Однако, в худшем случае, например, когда все элементы имеют одинаковые хэш-коды, производительность может снизиться до O(n).
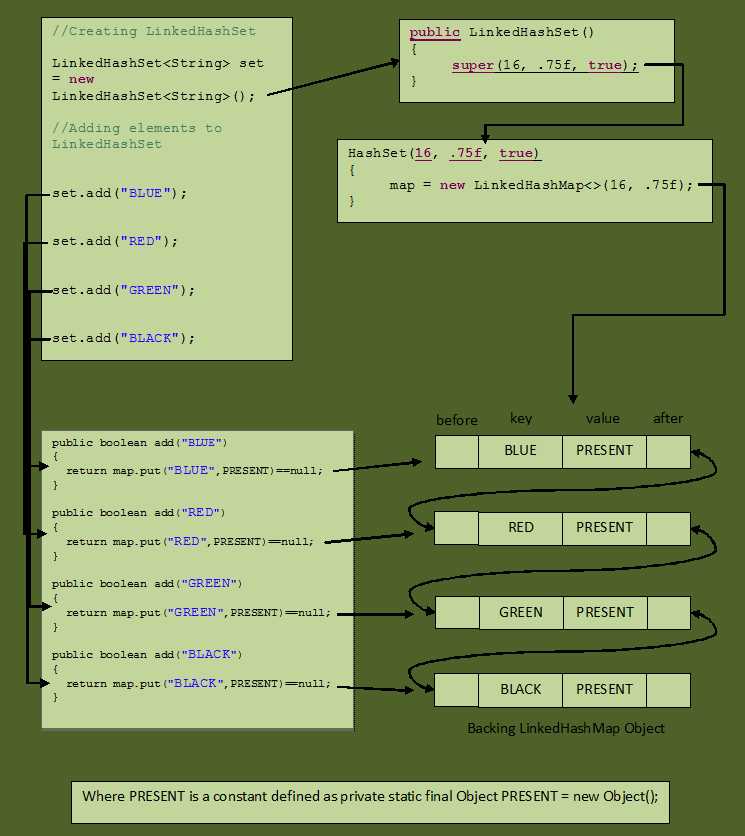
Важно отметить, что порядок элементов в HashSet не гарантируется. Если требуется поддержание порядка, лучше использовать другие коллекции, такие как LinkedHashSet, который сохраняет порядок вставки. HashSet предназначен в первую очередь для ситуаций, когда важна уникальность элементов, а не их последовательность.
Основные принципы работы HashSet в Java
Когда объект добавляется в HashSet, его хеш-код вычисляется через метод hashCode(), который определяет, в какой корзине (или бакете) будет храниться этот элемент. Если в данной корзине уже существует элемент с таким же хеш-кодом, выполняется дополнительная проверка на равенство через метод equals(). Только если оба метода (hashCode и equals) подтверждают уникальность объекта, он будет добавлен в коллекцию.
Чтобы минимизировать количество коллизий (ситуаций, когда два объекта имеют одинаковый хеш-код), HashSet использует динамическую перераспределенность корзин, автоматически увеличивая их количество по мере роста коллекции. Это обеспечивает быструю работу с элементами, так как доступ к данным осуществляется за амортизированное время O(1) для большинства операций (добавление, поиск, удаление).
Особенностью HashSet является то, что порядок элементов не сохраняется. При итерации по коллекции элементы могут быть возвращены в произвольном порядке, что важно учитывать при использовании этой структуры данных.
Для повышения производительности стоит использовать правильные хеш-функции и заранее настроить начальный размер и коэффициент загрузки коллекции. При высоком коэффициенте загрузки и малом числе корзин увеличивается вероятность коллизий, что может ухудшить время выполнения операций. В идеале начальный размер должен быть пропорционален количеству элементов, которое предполагается хранить в коллекции.
Как HashSet обеспечивает уникальность элементов
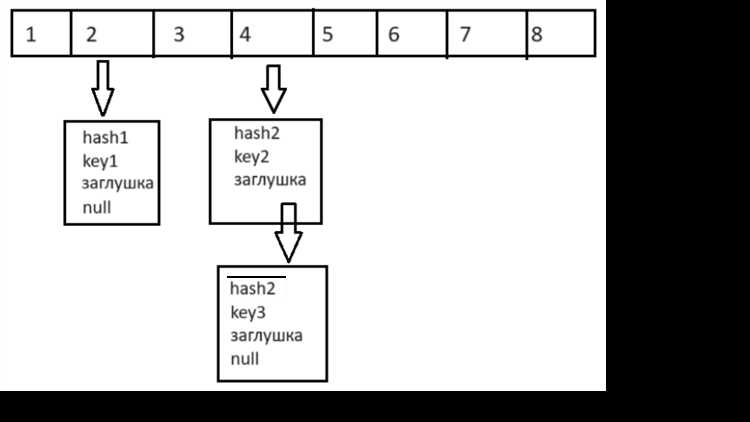
HashSet использует структуру данных под названием хеш-таблица для хранения элементов. Каждый объект, добавляемый в HashSet, сначала проходит через процесс хеширования, в ходе которого вычисляется его хеш-код. Этот хеш-код позволяет HashSet быстро определить, существует ли уже такой элемент в наборе, так как хеширование помогает эффективно искать элементы по их хешу, а не проверять каждый элемент последовательно.
Для проверки уникальности элемента HashSet использует метод equals(), который сравнивает объекты на равенство. Если хеш-коды элементов совпадают, происходит дополнительная проверка с помощью equals(), чтобы убедиться, что два объекта действительно одинаковы. Это важно, так как два объекта с одинаковым хеш-кодом не всегда идентичны. Например, если два разных объекта имеют одинаковые значения в полях, но это разные объекты, метод equals() их различит.
Кроме того, хеш-таблица HashSet оптимизирует процесс поиска благодаря использованию цепочек или других методов для обработки коллизий (когда два элемента имеют одинаковый хеш-код). Эти методы позволяют HashSet поддерживать быстродействие операций вставки, удаления и поиска даже при наличии коллизий.
В результате, уникальность элементов в HashSet гарантируется за счет двух этапов: хеширования и сравнения объектов методом equals(). Этот подход позволяет набору эффективно хранить и управлять коллекцией уникальных объектов, минимизируя затраты на проверки при добавлении новых элементов.
Влияние хеш-функций на производительность HashSet
Хеш-функции играют ключевую роль в эффективности работы HashSet в Java, определяя, как элементы будут распределяться по внутренним корзинам. Чем лучше распределение, тем меньше вероятность возникновения коллизий, что напрямую влияет на время выполнения операций поиска, вставки и удаления элементов.
Основной метрикой, которой оценивается хеш-функция, является её способность минимизировать количество коллизий. Коллизия происходит, когда два разных объекта имеют одинаковые хеш-значения. В случае частых коллизий время выполнения операций может значительно возрасти, так как потребуется дополнительная обработка, например, проверка всех элементов в корзине с одинаковым хеш-значением.
Для оптимальной производительности важно, чтобы хеш-функция обеспечивала равномерное распределение элементов по корзинам. Если элементы с одинаковыми хеш-значениями оказываются в одной корзине, производительность HashSet может упасть до O(n) вместо O(1), где n – количество элементов в корзине. В таких случаях увеличение объема памяти (например, увеличение размера корзин) не всегда решает проблему, поскольку сама хеш-функция остаётся неэффективной.
Одной из рекомендаций для улучшения работы с HashSet является использование собственной хеш-функции, если стандартная не удовлетворяет требования. Важно учитывать, что хорошая хеш-функция должна быть быстрой и создавать максимально разнообразное распределение хеш-значений.
Также стоит обратить внимание на способность хеш-функции эффективно работать с типами данных, которые содержат изменяемые поля. Например, если хеш-функция зависит от изменяемых свойств объекта, это может привести к нестабильности хеш-значений и неправильному распределению элементов, что нарушает основную логику работы HashSet.
В некоторых случаях для значительных улучшений производительности можно использовать специализированные хеш-функции, например, хеширование на основе строк или чисел, подходящих для конкретных типов данных. Важно также не забывать о перераспределении корзин при достижении определенной плотности элементов, чтобы поддерживать хорошую производительность.
Как добавить и удалить элементы в HashSet

HashSet в Java предоставляет эффективные методы для добавления и удаления элементов. Он использует хеширование для хранения данных, что позволяет выполнять операции добавления и удаления с примерно постоянным временем выполнения, O(1), в среднем.
Добавление элементов
Для добавления элемента в HashSet используется метод add(). Если элемент уже существует в коллекции, он не будет добавлен повторно.
add(E e)– добавляет элементeв набор. Возвращаетtrue, если элемент был успешно добавлен, иfalse, если элемент уже присутствует.- Важно помнить, что порядок добавления элементов не гарантируется, так как HashSet не сохраняет порядок элементов.
Пример:
HashSetset = new HashSet<>(); set.add("Apple"); set.add("Banana"); set.add("Apple"); // Не будет добавлено System.out.println(set); // Выведет [Apple, Banana]
Удаление элементов
Удаление элементов из HashSet осуществляется с помощью метода remove(). Метод возвращает true, если элемент был удален, и false, если элемент не найден в наборе.
remove(Object o)– удаляет элементoиз набора.clear()– удаляет все элементы из набора, очищая коллекцию.removeAll(Collection c)– удаляет все элементы, присутствующие в переданной коллекцииc.
Пример:
HashSetset = new HashSet<>(); set.add("Apple"); set.add("Banana"); set.remove("Apple"); System.out.println(set); // Выведет [Banana] set.clear(); System.out.println(set); // Выведет []
Для удаления всех элементов, которые присутствуют в другой коллекции, можно использовать метод removeAll().
Работа с HashSet предполагает, что операции добавления и удаления будут выполняться быстро, если только не происходит значительных коллизий хешей. Важно помнить, что в HashSet не допускаются дубликаты, и порядок элементов не сохраняется.
Особенности итерации по элементам HashSet
Итерация по элементам HashSet в Java имеет несколько важных особенностей, которые необходимо учитывать при работе с этим классом.
- Отсутствие порядка элементов: HashSet не гарантирует сохранение порядка добавления элементов. Итерация может привести к обходу элементов в любом порядке, что зависит от хеш-функции и внутренних структур данных. Это важно учитывать, если порядок элементов имеет значение.
- Использование Iterator: Основной способ итерации по элементам HashSet – это использование интерфейса
Iterator. Методiterator()возвращает итератор, который позволяет перебирать элементы с помощью методовhasNext()иnext(). - Для каждого элемента: При переборе с помощью итератора важно помнить, что коллекция не поддерживает модификацию во время итерации (за исключением использования
Iterator.remove()). Изменение структуры коллекции может привести к исключениюConcurrentModificationException. - Использование enhanced for-loop: В Java можно использовать цикл «расширенной» формы (
foreach) для итерации по элементам HashSet. Этот способ удобен для чтения данных, но не подходит для удаления элементов во время обхода. - Неэффективность в случае частых удалений: При удалении элементов из HashSet в процессе итерации с помощью
Iterator.remove()производительность может ухудшаться, так как коллекция должна поддерживать внутреннюю структуру данных в актуальном состоянии. Для больших коллекций это может привести к заметным задержкам. - Влияние хеш-функции: Порядок обхода элементов HashSet зависит от хеш-функции, используемой для вычисления хеш-кодов объектов. Если хеш-функция не сбалансирована, это может привести к неравномерному распределению элементов по бакетам и, как следствие, изменению порядка их обхода.
Сравнение HashSet с другими коллекциями Java
HashSet в Java предоставляет уникальные возможности для работы с коллекциями, но его особенности делают его не всегда оптимальным выбором по сравнению с другими коллекциями, такими как TreeSet, LinkedHashSet и HashMap. Рассмотрим ключевые различия и моменты, которые стоит учитывать при выборе коллекции для решения конкретной задачи.
HashSet использует хеширование для хранения элементов, что позволяет обеспечивать быстрый доступ к данным с временем поиска O(1) в среднем случае. Это делает HashSet эффективным при работе с большим количеством данных, когда требуется быстрый доступ, но порядок элементов не имеет значения. Однако, в отличие от TreeSet, HashSet не сохраняет порядок добавления элементов.
TreeSet, с другой стороны, поддерживает элементы в отсортированном порядке, используя красно-черное дерево. Он требует больше времени для операций вставки и удаления элементов – O(log n) – по сравнению с HashSet, но при этом обеспечивает доступ к данным в отсортированном виде, что может быть критично для некоторых задач.
LinkedHashSet, в отличие от HashSet, сохраняет порядок добавления элементов. Это делает его хорошим выбором, когда важно сохранять последовательность элементов, но без излишней сложности, как в случае с TreeSet. Однако, вставка и удаление элементов в LinkedHashSet могут быть немного медленнее по сравнению с обычным HashSet из-за необходимости поддержания порядка.
HashMap представляет собой коллекцию пар «ключ-значение», и хотя это не напрямую коллекция для хранения множества элементов, она может быть полезна, когда нужно сопоставить каждый элемент с уникальным ключом. В отличие от HashSet, который хранит только элементы без их ассоциации с ключами, HashMap предоставляет больше гибкости при работе с данными, но использование памяти и время доступа могут быть немного выше из-за хранения и поиска ключей и значений.
Выбор между этими коллекциями зависит от конкретных требований задачи. Если порядок элементов не важен, а критична скорость доступа – HashSet будет оптимальным вариантом. Если необходим порядок или сортировка – TreeSet или LinkedHashSet окажутся более подходящими. Если же важно работать с ассоциированными данными, HashMap будет предпочтительным выбором.
Проблемы и ограничения при использовании HashSet в многозадачных приложениях

Основная проблема заключается в том, что операция добавления, удаления и проверки существования элементов в HashSet не является атомарной. Например, если два потока одновременно пытаются добавить одинаковый элемент в коллекцию, оба могут успешно пройти проверку наличия элемента и добавить его, несмотря на то, что элемент уже присутствует в наборе. Это приводит к непредсказуемым результатам в многозадачных приложениях.
Для предотвращения таких проблем можно использовать коллекцию CopyOnWriteArraySet или явную синхронизацию с помощью synchronized или ReentrantLock. Однако использование синхронизации снижает производительность и усложняет код, поэтому важно тщательно оценить необходимость потокобезопасности для конкретного случая.
Кроме того, HashSet использует хэш-функцию для распределения элементов, что делает его чувствительным к изменению состояния объектов, которые используются в качестве элементов. Если объект, добавленный в HashSet, изменяется в процессе работы приложения, это может привести к некорректному поведению, так как хэш-код объекта будет изменяться, и элемент может быть потерян в наборе. Чтобы избежать этой проблемы, объекты, добавляемые в HashSet, должны быть неизменяемыми (immutable).
Одним из решений для потокобезопасной работы с коллекциями является использование Collections.synchronizedSet, который оборачивает HashSet и делает его потокобезопасным. Однако важно помнить, что даже с синхронизацией такой подход может не обеспечить должной производительности в случае высокой конкуренции между потоками.
Таким образом, при использовании HashSet в многозадачных приложениях необходимо тщательно учитывать потребности в потокобезопасности и выбирать подходящие стратегии синхронизации для минимизации возможных проблем.
Вопрос-ответ:
Как работает HashSet в Java?
HashSet в Java является реализацией интерфейса Set, которая использует хеш-таблицу для хранения элементов. Каждый элемент в HashSet уникален, то есть дублирование значений не допускается. При добавлении нового элемента, его хеш-код вычисляется и используется для определения места в хеш-таблице. Это позволяет быстро проверять наличие элемента и добавлять его в коллекцию.
Почему HashSet не сохраняет порядок элементов?
HashSet не сохраняет порядок элементов, потому что его внутренняя структура основана на хеш-таблице, которая не гарантирует упорядоченное расположение элементов. Порядок добавления элементов может быть нарушен из-за хеширования, которое зависит от хеш-кода объектов. Если вам нужен порядок, лучше использовать другие коллекции, такие как TreeSet.
Как проверяется наличие элемента в HashSet?
Для проверки наличия элемента в HashSet используется метод contains(). Он ищет элемент с помощью его хеш-кода. Если элемент присутствует в коллекции, метод вернет true, иначе — false. Этот процесс происходит достаточно быстро, так как поиск осуществляется через хеширование, что делает его эффективным даже для больших коллекций.
Можно ли в HashSet хранить элементы с одинаковым хеш-кодом?
Да, в HashSet могут храниться элементы с одинаковым хеш-кодом, но важным условием является то, что они должны быть различными по значению. Когда два объекта имеют одинаковый хеш-код, HashSet использует метод equals() для их сравнения. Если объекты равны (equals() возвращает true), то второй элемент не будет добавлен, даже если хеш-коды у них одинаковые.
Что происходит при попытке добавить дубликат в HashSet?
Если вы пытаетесь добавить элемент, который уже существует в HashSet, он не будет добавлен. HashSet проверяет наличие элемента с помощью метода equals(), и если такой элемент уже есть, добавление не происходит, а метод add() вернет false. Это поведение обеспечивает уникальность элементов в коллекции.