HashMap в Java представляет собой структуру данных, которая реализует интерфейс Map и использует хеширование для хранения элементов. Он состоит из пар «ключ-значение», где ключ используется для поиска значения в коллекции. Эта структура данных обеспечивает быстрый доступ к элементам по ключу, что делает её одним из самых популярных решений для хранения и извлечения данных.
Основной принцип работы HashMap заключается в использовании хеш-функции для преобразования ключа в индекс в массиве. Когда элемент добавляется в HashMap, хеш-функция рассчитывает индекс, и элемент помещается в соответствующую ячейку массива. Если два ключа имеют одинаковый хеш, они будут храниться в одной и той же ячейке в виде связанного списка или дерева, что позволяет избежать потерь данных.
Одним из важнейших факторов, который влияет на производительность HashMap, является выбор хеш-функции. Плохая хеш-функция может привести к чрезмерным коллизиям, что в свою очередь замедляет операции вставки и поиска. Именно поэтому для эффективной работы важно, чтобы хеш-функция равномерно распределяла ключи по возможным индексам.
Кроме того, HashMap не гарантирует порядка элементов. В отличие от LinkedHashMap, который сохраняет порядок вставки, HashMap может менять порядок элементов. Поэтому, если порядок имеет значение, стоит использовать другие реализации интерфейса Map.
Принципы работы HashMap в Java: Основы
Когда элемент добавляется в HashMap, ключ передается через хеш-функцию, которая вычисляет его хеш-код. Хеш-код определяет, в какой корзине (bucket) будет храниться соответствующая пара ключ-значение. Если два разных ключа имеют одинаковый хеш-код, то возникает коллизия. Для решения этой проблемы HashMap использует метод цепочек – в одной корзине могут храниться несколько элементов, которые разрешаются через список.
При поиске значения по ключу HashMap снова применяет хеш-функцию, чтобы определить корзину, а затем по очереди проверяет элементы в этой корзине. Если элемент найден, возвращается его значение. Это позволяет достигать времени поиска в среднем O(1), при условии, что хеш-функция распределяет элементы равномерно.
Размер HashMap увеличивается автоматически, когда число элементов достигает определенного порога. Это связано с тем, что с увеличением количества элементов вероятность коллизий растет, что снижает производительность. По умолчанию HashMap удваивает размер своей внутренней структуры, чтобы поддерживать эффективность работы.
Реализация хеширования в HashMap: Как работает ключ
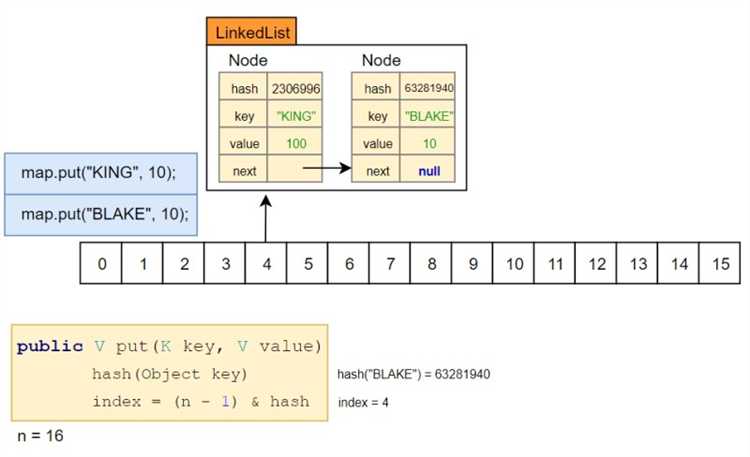
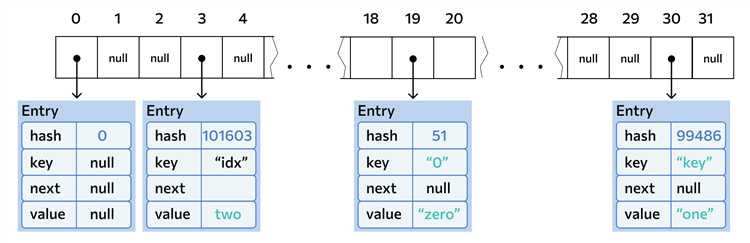
HashMap использует принцип хеширования для организации и быстрого поиска данных. Когда объект добавляется в коллекцию, его ключ сначала преобразуется в хеш-код с помощью метода hashCode(). Этот хеш-код определяет, в какой «корзине» (или бакете) будет храниться соответствующая пара ключ-значение.
Процесс хеширования в HashMap начинается с вычисления хеш-кода ключа. Этот код затем используется для определения индекса в массиве бакетов. Однако хеш-код сам по себе не всегда уникален, что может привести к коллизиям, когда два разных ключа имеют одинаковый хеш-код. В таких случаях HashMap использует цепочки (списки) для хранения всех элементов с одинаковым хеш-кодом в одном бакете.
Для вычисления индекса используется формула: index = hashCode % array.length. Здесь hashCode – это хеш-код ключа, а array.length – размер массива бакетов. Для обеспечения равномерного распределения ключей по бакетам важно, чтобы метод hashCode() был правильно реализован. Некачественная реализация может привести к высокой частоте коллизий, что снизит эффективность работы HashMap.
Важным моментом является то, что HashMap не только использует хеш-код для определения индекса, но и применяет дополнительные операции, чтобы минимизировать коллизии. Например, применяется маскировка значений хеш-кодов, чтобы равномерно распределять элементы по всем бакетам.
Еще одним ключевым моментом является процесс поиска элементов. Когда нужно найти значение по ключу, алгоритм сначала рассчитывает хеш-код и индекс в массиве, затем проходит по цепочке, если в бакете находятся несколько элементов с одинаковым хеш-кодом. Этот процесс может быть оптимизирован, если длина цепочки мала.
При изменении размера HashMap, например, при увеличении количества элементов, происходит перераспределение бакетов. Это требует повторного вычисления индексов для всех существующих элементов, что важно учитывать при использовании HashMap в условиях динамических данных.
Как обрабатываются коллизии в HashMap: Методы разрешения
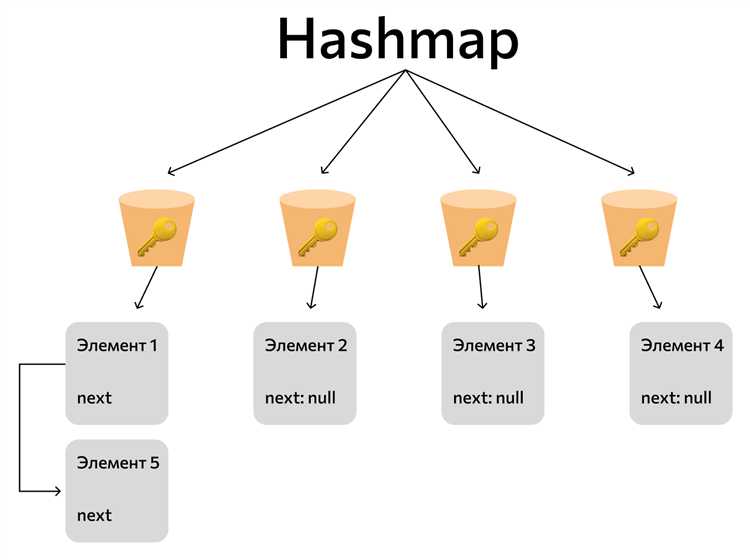
В HashMap коллизия возникает, когда два разных ключа хешируются в один и тот же индекс таблицы. Для эффективной работы структуры данных важно правильно обработать такие ситуации, чтобы избежать потери данных и уменьшить время поиска.
Java HashMap использует два основных метода разрешения коллизий: цепочки (chaining) и открытая адресация (open addressing).
Цепочки (Chaining) – это метод, при котором все элементы, попавшие в одну ячейку массива, хранятся в виде связанного списка или другой структуры данных (например, деревьев). Когда происходит коллизия, новый элемент добавляется в этот список. При этом поиск по ключу происходит через обход всех элементов в цепочке, что снижает эффективность при большом количестве коллизий. В случае, когда длина цепочки превышает определённый порог, HashMap может преобразовать её в сбалансированное дерево для улучшения производительности поиска.
Открытая адресация (Open Addressing) – это метод, при котором элементы, попавшие в коллизию, пытаются разместиться в другом индексе таблицы, основываясь на некоторой стратегии поиска. В Java HashMap используется модификация открытой адресации, которая называется «линейное пробирование» (linear probing) для разрешения коллизий. Когда ячейка занята, система пытается найти следующую свободную ячейку в таблице и размещает элемент там.
Открытая адресация имеет некоторые ограничения. Например, при увеличении нагрузки на HashMap (например, при увеличении числа элементов) вероятность коллизий возрастает, что может привести к ухудшению производительности. Однако для небольших коллекций данных и при правильном управлении размерами таблицы этот метод может быть достаточно эффективным.
В современном Java HashMap коллизии обычно обрабатываются с помощью цепочек, где для хранения цепочек используется сбалансированное дерево (если длина цепочки становится слишком большой). Такой подход обеспечивает более равномерное распределение элементов, что улучшает производительность при большом количестве данных.
Влияние емкости и коэффициента загрузки на производительность
Емкость HashMap в Java определяет количество слотов (бакетов), которые используются для хранения элементов. Когда емкость недостаточна для хранения всех элементов, происходит ресайзинг (увеличение емкости). Этот процесс требует перераспределения элементов по новым слотам, что может существенно замедлить выполнение программы, если операции вставки происходят часто.
Коэффициент загрузки (load factor) определяет, при каком уровне заполненности HashMap нужно увеличивать емкость. Обычно он равен 0.75, что означает, что когда количество элементов в коллекции достигает 75% от текущей емкости, происходит увеличение емкости. Слишком высокий коэффициент загрузки может привести к большему количеству коллизий, замедляя операции поиска и вставки. С другой стороны, слишком низкий коэффициент увеличивает частоту ресайзинга, что также оказывает негативное влияние на производительность.
Для оптимизации производительности важно правильно настроить емкость и коэффициент загрузки в зависимости от конкретных условий. Если операции вставки происходят редко, а чтение данных происходит часто, можно выбрать более высокий коэффициент загрузки, чтобы минимизировать частоту расширений. Если же операции вставки и удаления преобладают, лучше установить более низкий коэффициент загрузки, чтобы избежать сильных деградаций производительности из-за перераспределения данных.
Таким образом, для эффективной работы HashMap нужно учитывать баланс между емкостью, коэффициентом загрузки и частотой операций вставки, чтобы избежать излишней перераспределенности данных и минимизировать затраты на перераспределение памяти.
Как работает метод put() в HashMap: Добавление пар «ключ-значение»
При вызове метода put() происходит несколько операций:
- Метод вычисляет хеш-код ключа с помощью метода
hashCode()и затем применяет его к алгоритму для определения позиции (индекса) в массиве бакетов. - Если на вычисленном индексе уже существует элемент, происходит сравнение ключа с ключом существующей пары. Для этого используется метод
equals(). - Если ключи совпадают, значение обновляется, иначе создается новая пара «ключ-значение».
- Если в бакете несколько элементов (коллизии), они хранятся в виде связанного списка или дерева (в зависимости от реализации).
- В случае, если количество элементов в бакете превышает определенный порог, HashMap может преобразовать связанный список в сбалансированное дерево для улучшения производительности.
Пример использования метода put():
HashMap map = new HashMap<>();
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
Важно помнить, что put() возвращает старое значение, если оно существовало для данного ключа, или null, если ключ новый.
Несмотря на кажущуюся простоту, метод put() может быть неэффективен при высоком количестве коллизий или при большом размере данных. Для повышения производительности важно правильно настраивать размер начальной емкости и коэффициент загрузки HashMap, чтобы минимизировать необходимость перераспределения элементов.
Реализация метода get() в HashMap: Поиск значений по ключу

Метод get() в классе HashMap используется для получения значения, связанного с указанным ключом. Внутри этого метода выполняется несколько шагов для эффективного поиска нужной пары «ключ-значение».
Процесс поиска начинается с вычисления хеш-кода ключа, который служит основой для поиска в массиве бакетов (корзин). Хеш-код делится на несколько частей с использованием алгоритма хеширования, что позволяет более равномерно распределять данные по корзинам. Когда хеш-код получен, определяется индекс в массиве бакетов, куда должен быть помещен ключ. Далее метод ищет соответствующий ключ в том числе в случае коллизий, когда несколько ключей могут попасть в одну корзину.
В случае коллизий используется метод цепочек (или связанных списков), при котором элементы, попавшие в одну корзину, сохраняются в виде списка. Для поиска нужного элемента метод get() проходит по списку, сравнивая ключи. Если ключ найден, возвращается его значение. Если ключа нет, метод возвращает null.
Алгоритм работы get() эффективен и выполняется за амортизированное время O(1), если количество коллизий минимально. Однако в случае большого числа коллизий (например, если все ключи имеют одинаковый хеш-код) время поиска может увеличиться до O(n), где n – количество элементов в корзине.
Для оптимизации работы HashMap рекомендуется использовать хорошие хеш-функции, которые обеспечат равномерное распределение ключей по корзинам и снизят количество коллизий.
Какие ограничения имеет HashMap при многозадачности и многопоточности
Основная проблема заключается в том, что операции, такие как put() и get(), не синхронизированы. Если один поток изменяет структуру карты (например, вставляет новый элемент), а другой поток одновременно читает данные, результат может быть непредсказуемым. Это особенно важно при работе с большими объемами данных, где вероятность одновременного доступа повышается.
В случае записи нескольких потоков в HashMap возможна ситуация, когда один поток перезапишет данные, изменяя состояние коллекции, а другой поток при этом не увидит актуальную информацию. Это приводит к несогласованности и ошибкам, связанным с чтением и записью.
Для решения этих проблем Java предоставляет несколько альтернатив. Например, для синхронизации доступа к HashMap можно использовать Collections.synchronizedMap(), который обеспечивает блокировку при каждом доступе. Однако такой подход снижает производительность из-за накладных расходов на блокировки.
Другим решением является использование ConcurrentHashMap, который оптимизирован для многозадачности. Он разделяет данные на сегменты и позволяет потокам работать с разными сегментами одновременно, минимизируя блокировки и повышая производительность в многопоточной среде.
Если HashMap всё же необходимо использовать в многозадачной среде, важно контролировать синхронизацию внешними средствами или рассмотреть возможность применения других коллекций, таких как ConcurrentHashMap или CopyOnWriteMap, в зависимости от специфики задач.
Сравнение HashMap с другими коллекциями Java: HashMap vs TreeMap
HashMap и TreeMap – две часто используемые коллекции в Java для хранения пар «ключ-значение», но они имеют важные различия, влияющие на выбор подходящего решения для конкретных задач.
Основное отличие заключается в способе хранения данных. HashMap использует хеширование для поиска элементов, в то время как TreeMap основан на структуре данных красно-черного дерева. Это влечет за собой различные характеристики и поведение обеих коллекций.
- Производительность: HashMap обеспечивает операции добавления, удаления и поиска за время O(1) в среднем, благодаря хешированию. TreeMap, в свою очередь, выполняет все операции за время O(log n), поскольку элементы хранятся в отсортированном виде.
- Порядок элементов: HashMap не гарантирует порядок элементов, так как порядок зависит от хеш-функции. TreeMap всегда поддерживает порядок ключей, согласно их естественному порядку или заданному компаратору.
- Использование памяти: HashMap требует меньше памяти, так как не использует дополнительные данные для поддержания порядка элементов, в отличие от TreeMap, где каждый элемент содержит ссылки для организации дерева.
- Производительность при сортировке: Если требуется периодическая сортировка ключей, TreeMap будет быстрее, поскольку данные уже упорядочены. В HashMap для этого потребуется дополнительная операция сортировки, которая требует времени O(n log n).
- Параллельные операции: HashMap не синхронизирован, что может быть проблемой в многопоточной среде. Для синхронизации необходимо использовать Collections.synchronizedMap или ConcurrentHashMap. TreeMap также не синхронизирован, но для многопоточной работы его лучше использовать с внешней синхронизацией.
Выбор между HashMap и TreeMap зависит от конкретной задачи. Если важна скорость работы с данными и порядок не имеет значения, предпочтительнее использовать HashMap. Если требуется поддержка отсортированного порядка ключей, или нужно делать операции с упорядочиванием, тогда стоит выбрать TreeMap.
Вопрос-ответ:
Что такое HashMap в Java и как она работает?
HashMap в Java — это структура данных, которая позволяет хранить пары «ключ-значение». Каждое значение связано с уникальным ключом, который используется для быстрого доступа к данным. Работает это так: когда добавляется новая пара, ключ проходит через хеш-функцию, которая вычисляет индекс в массиве. Этот индекс указывает на место хранения значения. Если два разных ключа дают одинаковый индекс, происходит коллизия, и в этом случае элементы хранятся в списке или дереве. Это обеспечивает быструю операцию вставки и поиска.
Как работает хеш-функция в HashMap и зачем она нужна?
Хеш-функция играет ключевую роль в работе HashMap, она вычисляет индекс в массиве, где будет храниться значение. Хеш-функция преобразует ключ в число (хеш), которое затем используется для вычисления индекса. Этот индекс помогает быстро найти нужное значение. Хорошая хеш-функция минимизирует коллизии, когда два разных ключа могут привести к одному и тому же индексу. Если коллизии происходят, то элементы в том же месте массива хранятся в виде списка или дерева, что также обеспечивает быстрый доступ к данным.
Что такое коллизии в HashMap и как их обрабатывают?
Коллизия возникает, когда два разных ключа в HashMap дают одинаковый хеш-код и, соответственно, приводят к одному и тому же индексу в массиве. Чтобы избежать потери данных, в таких случаях используется цепочка (связанный список) или дерево. Когда коллизия происходит, элементы в одном месте хранятся последовательно, и при поиске по индексу перебираются все элементы, пока не будет найден нужный ключ. В новых версиях Java для больших коллекций используется дерево, что улучшает производительность, поскольку поиск в дереве работает быстрее, чем в списке.
Какие ограничения и особенности у HashMap в Java?
HashMap имеет несколько особенностей и ограничений. Во-первых, она не синхронизирована, что значит, что если несколько потоков будут изменять одну и ту же коллекцию, могут возникнуть проблемы. Для безопасной работы в многопоточном окружении лучше использовать `ConcurrentHashMap`. Во-вторых, HashMap не сохраняет порядок вставки элементов. Если вам нужно, чтобы элементы оставались в том порядке, в котором они были добавлены, можно использовать `LinkedHashMap`. Кроме того, ключи и значения в HashMap могут быть равными `null`, но стоит быть осторожным с этим, так как использование `null` в качестве ключа может привести к путанице при работе с коллекцией.
В чем разница между HashMap и TreeMap в Java?
Основное отличие между HashMap и TreeMap заключается в том, как они хранят элементы. HashMap не сохраняет порядок элементов, а TreeMap упорядочивает ключи по их естественному порядку или по компаратору, если он задан. Это означает, что в TreeMap элементы всегда будут отсортированы. Также стоит отметить, что HashMap работает быстрее для большинства операций (например, поиска), так как использует хеширование, в то время как TreeMap использует структуру данных, основанную на красно-черном дереве, что делает его несколько медленнее, но зато дает возможность работать с отсортированными данными.
Как работает HashMap в Java и почему он так важен?
HashMap в Java представляет собой структуру данных, которая позволяет хранить пары «ключ-значение». Каждому ключу соответствует определённое значение, и для доступа к этому значению используется хеш-функция, которая преобразует ключ в индекс, по которому данные можно найти в массиве. Благодаря этому доступ к элементам в HashMap происходит очень быстро. Он является неупорядоченным, то есть порядок вставки элементов не сохраняется. Одной из ключевых особенностей HashMap является возможность хранить любые объекты в качестве ключей и значений, при этом каждый ключ должен быть уникальным.